PAR3D: A Unified 3D-MLLM with Part-Aware Representation for Scene Understanding
Pith reviewed 2026-06-28 02:15 UTC · model grok-4.3
The pith
PAR3D adds part-level awareness to 3D-MLLMs so models can ground both objects and their parts in scenes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
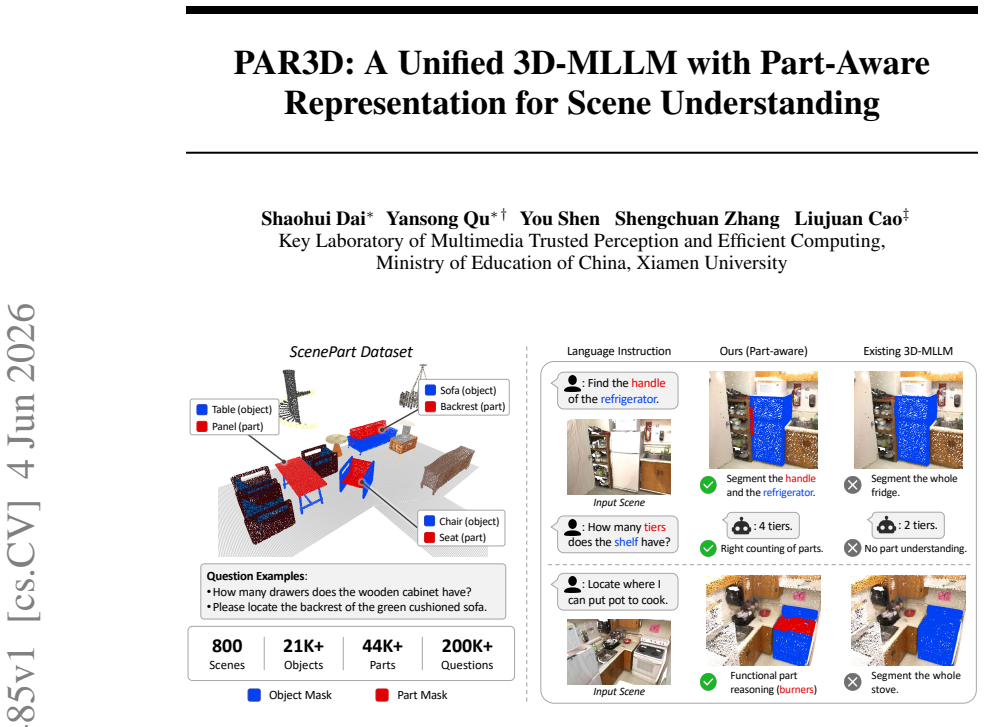
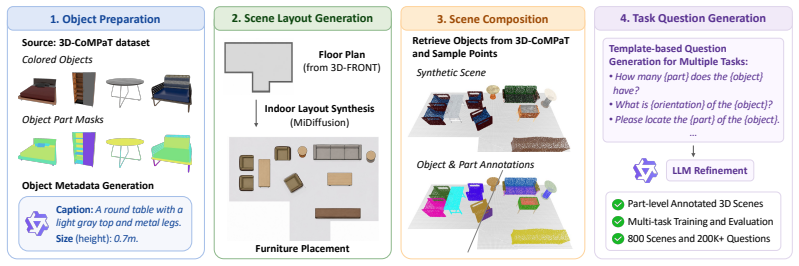
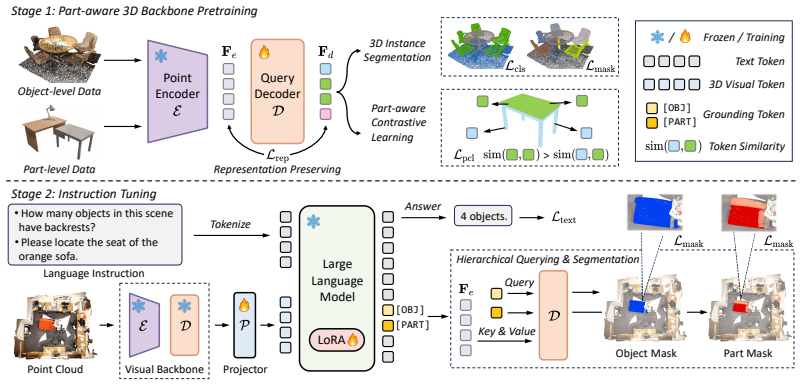
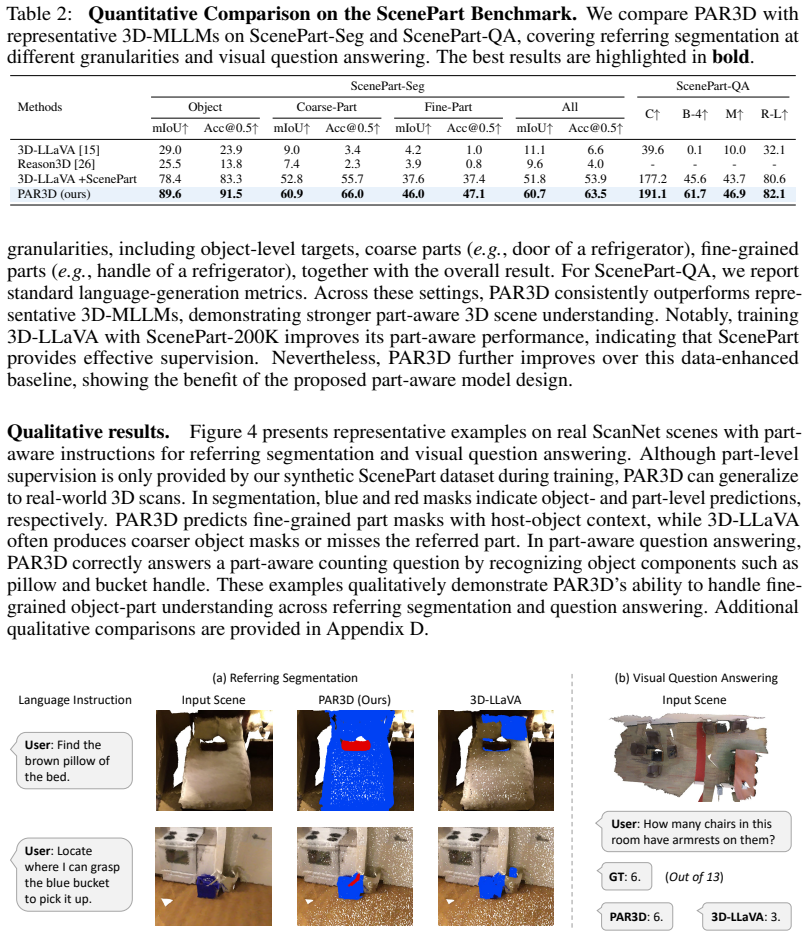
PAR3D is a unified part-aware 3D-MLLM framework that enables models to understand, reason about, and ground both objects and their parts in 3D scenes. Training and evaluation are supported by the introduced ScenePart synthetic dataset with part-level annotations and language instructions. Part-Aware 3D Representation Learning enriches 3D visual representations with fine-grained part-level semantics, while Hierarchical Segmentation Query Generation grounds part targets via hierarchical object-part queries. The result is substantial improvement on part-level question answering and referring segmentation alongside strong object-level performance.
What carries the argument
Part-Aware 3D Representation Learning that enriches 3D visual representations with fine-grained part-level semantics, paired with Hierarchical Segmentation Query Generation that produces hierarchical object-part queries for grounding.
If this is right
- Models gain the ability to answer part-level questions and perform part-level referring segmentation in 3D scenes.
- Object-level vision-language tasks such as captioning and VQA continue to perform strongly.
- A single framework handles both object-centric and part-centric 3D scene understanding tasks.
- Hierarchical queries allow grounding of parts relative to their parent objects.
Where Pith is reading between the lines
- Robotic systems could use the part-aware outputs for more precise manipulation of object components.
- The synthetic-to-real transfer approach may extend to other 3D perception tasks where part annotations are scarce.
- Hierarchical query mechanisms could be adapted for multi-scale reasoning in other multimodal settings.
Load-bearing premise
Training on the synthetic ScenePart dataset will transfer to enable part-aware understanding in real 3D scenes.
What would settle it
Running the trained PAR3D model on real-world 3D scene benchmarks and finding no measurable gain in part-level question answering or referring segmentation accuracy compared with prior object-centric 3D-MLLMs would falsify the central claim.
Figures


read the original abstract
Recent advances in 3D multimodal large language models (3D-MLLMs) have enabled unified solutions for 3D scene understanding tasks, including visual question answering, captioning, and referring segmentation. However, existing 3D-MLLMs remain largely object-centric, limiting their ability to model fine-grained part structures that are essential for embodied interaction with 3D environments. In this work, we present PAR3D, a unified part-aware 3D-MLLM framework that enables models to understand, reason about, and ground both objects and their parts in 3D scenes. To enable training and evaluation of part-aware 3D scene understanding, we introduce ScenePart, a synthetic 3D scene dataset with part-level annotations and language instructions. We further develop Part-Aware 3D Representation Learning to enrich 3D visual representations with fine-grained part-level semantics, and propose Hierarchical Segmentation Query Generation to ground part targets via hierarchical object-part queries. Extensive experiments show that our method substantially improves part-level question answering and referring segmentation, while also achieving strong performance across object-level vision-language tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PAR3D, a unified part-aware 3D-MLLM, along with the synthetic ScenePart dataset containing part-level annotations and language instructions. It proposes Part-Aware 3D Representation Learning to enrich 3D visual features with fine-grained part semantics and Hierarchical Segmentation Query Generation to produce hierarchical object-part queries for grounding. The central claim is that these components enable models to understand, reason about, and ground both objects and parts, yielding substantial gains on part-level VQA and referring segmentation while preserving strong object-level performance.
Significance. If the synthetic-to-real transfer holds, the work would meaningfully extend 3D-MLLMs beyond object-centric limitations and support finer-grained embodied interaction. The creation of ScenePart is a constructive step toward part-level supervision, but the overall significance hinges on whether the reported gains generalize outside the synthetic distribution.
major comments (1)
- [Abstract] Abstract: The claim that PAR3D enables part-aware understanding and grounding 'in 3D scenes' for embodied interaction is load-bearing on sim-to-real transfer, yet the abstract introduces ScenePart solely for training/evaluation and reports improvements without any reference to real-world 3D datasets (ScanNet, 3RScan, etc.) or domain-randomization metrics.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for precision in the abstract regarding the scope of our claims. We agree that the current wording could overstate generalization and will revise accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that PAR3D enables part-aware understanding and grounding 'in 3D scenes' for embodied interaction is load-bearing on sim-to-real transfer, yet the abstract introduces ScenePart solely for training/evaluation and reports improvements without any reference to real-world 3D datasets (ScanNet, 3RScan, etc.) or domain-randomization metrics.
Authors: We agree the abstract phrasing is imprecise. The manuscript evaluates exclusively on the synthetic ScenePart dataset; no experiments on ScanNet, 3RScan or other real-world 3D datasets are reported, and no domain-randomization or sim-to-real metrics are provided. The framework is motivated by embodied interaction needs, but we do not claim or demonstrate transfer. We will revise the abstract to state that gains are shown on synthetic part-level data and note the absence of real-world validation as a limitation, with sim-to-real transfer left for future work. revision: yes
Circularity Check
No circularity; standard empirical proposal with independent dataset and modules
full rationale
The paper introduces a new synthetic dataset (ScenePart) and two new modules (Part-Aware 3D Representation Learning and Hierarchical Segmentation Query Generation) as contributions, then reports empirical gains on part-level and object-level tasks. No equations, derivations, or claims reduce a 'prediction' or result to a fitted input by construction, nor does any load-bearing premise rest on a self-citation chain or imported uniqueness theorem. The central claims rest on external evaluation metrics rather than self-referential definitions, so the derivation chain is self-contained.
Axiom & Free-Parameter Ledger
invented entities (2)
-
PAR3D
no independent evidence
-
ScenePart
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Achlioptas, A
P. Achlioptas, A. Abdelreheem, F. Xia, M. Elhoseiny, and L. Guibas. Referit3d: Neural listeners for fine-grained 3d object identification in real-world scenes. InEuropean conference on computer vision, pages 422–440. Springer, 2020
2020
-
[2]
Azuma, T
D. Azuma, T. Miyanishi, S. Kurita, and M. Kawanabe. Scanqa: 3d question answering for spatial scene understanding. Inproceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 19129–19139, 2022
2022
-
[3]
S. Bai, Y . Cai, R. Chen, K. Chen, X. Chen, Z. Cheng, L. Deng, W. Ding, C. Gao, C. Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Banerjee and A
S. Banerjee and A. Lavie. Meteor: An automatic metric for mt evaluation with improved correlation with human judgments. InProceedings of the acl workshop on intrinsic and extrinsic evaluation measures for machine translation and/or summarization, pages 65–72, 2005
2005
-
[5]
ARKitScenes: A Diverse Real-World Dataset For 3D Indoor Scene Understanding Using Mobile RGB-D Data
G. Baruch, Z. Chen, A. Dehghan, T. Dimry, Y . Feigin, P. Fu, T. Gebauer, B. Joffe, D. Kurz, A. Schwartz, et al. Arkitscenes: A diverse real-world dataset for 3d indoor scene understanding using mobile rgb-d data. arXiv preprint arXiv:2111.08897, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
A. X. Chang, T. Funkhouser, L. Guibas, P. Hanrahan, Q. Huang, Z. Li, S. Savarese, M. Savva, S. Song, H. Su, et al. Shapenet: An information-rich 3d model repository.arXiv preprint arXiv:1512.03012, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[7]
D. Z. Chen, A. X. Chang, and M. Nießner. Scanrefer: 3d object localization in rgb-d scans using natural language. InEuropean conference on computer vision, pages 202–221. Springer, 2020
2020
-
[8]
S. Chen, H. Zhu, X. Chen, Y . Lei, G. Yu, and T. Chen. End-to-end 3d dense captioning with vote2cap- detr. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11124–11133, 2023. 10
2023
-
[9]
S. Chen, X. Chen, C. Zhang, M. Li, G. Yu, H. Fei, H. Zhu, J. Fan, and T. Chen. Ll3da: Visual interactive instruction tuning for omni-3d understanding reasoning and planning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 26428–26438, 2024
2024
- [10]
-
[11]
Z. Chen, A. Gholami, M. Nießner, and A. X. Chang. Scan2cap: Context-aware dense captioning in rgb-d scans. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3193–3203, 2021
2021
-
[12]
Z. Chen, R. Hu, X. Chen, M. Nießner, and A. X. Chang. Unit3d: A unified transformer for 3d dense captioning and visual grounding. InProceedings of the IEEE/CVF international conference on computer vision, pages 18109–18119, 2023
2023
-
[13]
A. Dai, A. X. Chang, M. Savva, M. Halber, T. Funkhouser, and M. Nießner. Scannet: Richly-annotated 3d reconstructions of indoor scenes. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 5828–5839, 2017
2017
-
[14]
S. Dai, Y . Qu, Z. Li, X. Li, S. Zhang, and L. Cao. Training-free hierarchical scene understanding for gaussian splatting with superpoint graphs. InProceedings of the 33rd ACM International Conference on Multimedia, pages 3673–3682, 2025
2025
-
[15]
J. Deng, T. He, L. Jiang, T. Wang, F. Dayoub, and I. Reid. 3d-llava: Towards generalist 3d lmms with omni superpoint transformer. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 3772–3782, 2025
2025
-
[16]
H. Fu, B. Cai, L. Gao, L.-X. Zhang, J. Wang, C. Li, Q. Zeng, C. Sun, R. Jia, B. Zhao, et al. 3d-front: 3d furnished rooms with layouts and semantics. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 10933–10942, 2021
2021
-
[17]
H. Fu, R. Jia, L. Gao, M. Gong, B. Zhao, S. Maybank, and D. Tao. 3d-future: 3d furniture shape with texture.International Journal of Computer Vision, 129(12):3313–3337, 2021
2021
- [18]
-
[19]
H. Geng, H. Xu, C. Zhao, C. Xu, L. Yi, S. Huang, and H. Wang. Gapartnet: Cross-category domain- generalizable object perception and manipulation via generalizable and actionable parts. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7081–7091, 2023
2023
-
[20]
S. He, H. Ding, X. Jiang, and B. Wen. Segpoint: Segment any point cloud via large language model. In European Conference on Computer Vision, pages 349–367. Springer, 2024
2024
-
[21]
Y . Hong, H. Zhen, P. Chen, S. Zheng, Y . Du, Z. Chen, and C. Gan. 3d-llm: Injecting the 3d world into large language models.Advances in Neural Information Processing Systems, 36:20482–20494, 2023
2023
-
[22]
S. Hu, D. M. Arroyo, S. Debats, F. Manhardt, L. Carlone, and F. Tombari. Mixed diffusion for 3d indoor scene synthesis. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 1262–1272, 2026
2026
-
[23]
Huang, Y
H. Huang, Y . Chen, Z. Wang, R. Huang, R. Xu, T. Wang, L. Liu, X. Cheng, Y . Zhao, J. Pang, et al. Chat-scene: Bridging 3d scene and large language models with object identifiers.Advances in Neural Information Processing Systems, 37:113991–114017, 2024
2024
-
[24]
An Embodied Generalist Agent in 3D World
J. Huang, S. Yong, X. Ma, X. Linghu, P. Li, Y . Wang, Q. Li, S.-C. Zhu, B. Jia, and S. Huang. An embodied generalist agent in 3d world.arXiv preprint arXiv:2311.12871, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [25]
-
[26]
Huang, X
K.-C. Huang, X. Li, L. Qi, S. Yan, and M.-H. Yang. Reason3d: Searching and reasoning 3d segmentation via large language model. In2025 International Conference on 3D Vision (3DV), pages 1177–1186. IEEE, 2025
2025
-
[27]
J. Kerr, C. M. Kim, K. Goldberg, A. Kanazawa, and M. Tancik. LERF: language embedded radiance fields. InIEEE/CVF International Conference on Computer Vision, ICCV 2023, Paris, France, October 1-6, 2023, pages 19672–19682. IEEE, 2023. doi: 10.1109/ICCV51070.2023.01807. URL https: //doi.org/10.1109/ICCV51070.2023.01807. 11
-
[28]
Y . Li, R. Bu, M. Sun, W. Wu, X. Di, and B. Chen. Pointcnn: Convolution on x-transformed points. Advances in neural information processing systems, 31, 2018
2018
-
[29]
Y . Li, U. Upadhyay, H. Slim, A. Abdelreheem, A. Prajapati, S. Pothigara, P. Wonka, and M. Elhoseiny. 3d compat: Composition of materials on parts of 3d things. InEuropean conference on computer vision, pages 110–127. Springer, 2022
2022
-
[30]
C.-Y . Lin. Rouge: A package for automatic evaluation of summaries. InText summarization branches out, pages 74–81, 2004
2004
-
[31]
H. Liu, C. Li, Y . Li, and Y . J. Lee. Improved baselines with visual instruction tuning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 26296–26306, 2024
2024
-
[32]
M. Liu, Y . Zhu, H. Cai, S. Han, Z. Ling, F. Porikli, and H. Su. Partslip: Low-shot part segmentation for 3d point clouds via pretrained image-language models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 21736–21746, 2023
2023
- [33]
- [34]
- [35]
-
[36]
Z. Ma, Y . Yue, and G. Gkioxari. Find any part in 3d. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 7818–7827, 2025
2025
-
[37]
K. Mo, S. Zhu, A. X. Chang, L. Yi, S. Tripathi, L. J. Guibas, and H. Su. Partnet: A large-scale benchmark for fine-grained and hierarchical part-level 3d object understanding. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 909–918, 2019
2019
-
[38]
K. Mo, L. J. Guibas, M. Mukadam, A. Gupta, and S. Tulsiani. Where2act: From pixels to actions for articulated 3d objects. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 6813–6823, 2021
2021
-
[39]
Papineni, S
K. Papineni, S. Roukos, T. Ward, and W.-J. Zhu. Bleu: a method for automatic evaluation of machine translation. InProceedings of the 40th annual meeting of the Association for Computational Linguistics, pages 311–318, 2002
2002
-
[40]
A. V . Phan, M. Le Nguyen, Y . L. H. Nguyen, and L. T. Bui. Dgcnn: A convolutional neural network over large-scale labeled graphs.Neural Networks, 108:533–543, 2018
2018
-
[41]
C. R. Qi, L. Yi, H. Su, and L. J. Guibas. Pointnet++: Deep hierarchical feature learning on point sets in a metric space.Advances in neural information processing systems, 30, 2017
2017
-
[42]
Z. Qi, Y . Fang, Z. Sun, X. Wu, T. Wu, J. Wang, D. Lin, and H. Zhao. Gpt4point: A unified framework for point-language understanding and generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 26417–26427, 2024
2024
-
[43]
M. Qin, W. Li, J. Zhou, H. Wang, and H. Pfister. Langsplat: 3d language gaussian splatting. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024, pages 20051–20060. IEEE, 2024. doi: 10.1109/CVPR52733.2024.01895. URL https://doi.org/10.1109/CVPR52733.2024.01895
-
[44]
Y . Qu, Y . Wang, and Y . Qi. Sg-nerf: Semantic-guided point-based neural radiance fields. In2023 IEEE International Conference on Multimedia and Expo (ICME), pages 570–575. IEEE, 2023
2023
-
[45]
Y . Qu, S. Dai, X. Li, J. Lin, L. Cao, S. Zhang, and R. Ji. Goi: Find 3d gaussians of interest with an optimizable open-vocabulary semantic-space hyperplane. InProceedings of the 32nd ACM International Conference on Multimedia, pages 5328–5337, 2024
2024
- [46]
-
[47]
H. Slim, X. Li, Y . Li, M. Ahmed, M. Ayman, U. Upadhyay, A. Abdelreheem, A. Prajapati, S. Pothigara, P. Wonka, et al. 3dcompat++: An improved large-scale 3d vision dataset for compositional recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2025
-
[48]
Y . Tang, X. Han, X. Li, Q. Yu, Y . Hao, L. Hu, and M. Chen. Minigpt-3d: Efficiently aligning 3d point clouds with large language models using 2d priors. InProceedings of the 32nd ACM International Conference on Multimedia, pages 6617–6626, 2024
2024
-
[49]
Umam, C.-K
A. Umam, C.-K. Yang, M.-H. Chen, J.-H. Chuang, and Y .-Y . Lin. Partdistill: 3d shape part segmentation by vision-language model distillation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3470–3479, 2024
2024
-
[50]
Vedantam, C
R. Vedantam, C. Lawrence Zitnick, and D. Parikh. Cider: Consensus-based image description evaluation. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 4566–4575, 2015
2015
-
[51]
J. Wald, A. Avetisyan, N. Navab, F. Tombari, and M. Nießner. Rio: 3d object instance re-localization in changing indoor environments. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 7658–7667, 2019
2019
- [52]
- [53]
-
[54]
Y . Wang, J. Wang, Y . Qu, and Y . Qi. Rip-nerf: learning rotation-invariant point-based neural radiance field for fine-grained editing and compositing. InProceedings of the 2023 ACM International Conference on Multimedia Retrieval, pages 125–134, 2023
2023
-
[55]
Y . Wang, J. Wang, R. Gao, Y . Qu, W. Duan, S. Yang, and Y . Qi. Look at the sky: Sky-aware efficient 3d gaussian splatting in the wild.IEEE Transactions on Visualization and Computer Graphics, 2025
2025
-
[56]
C. Wu, Y . Ma, Q. Chen, H. Wang, G. Luo, J. Ji, and X. Sun. 3d-stmn: Dependency-driven superpoint-text matching network for end-to-end 3d referring expression segmentation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 5940–5948, 2024
2024
-
[57]
X. Wu, L. Jiang, P.-S. Wang, Z. Liu, X. Liu, Y . Qiao, W. Ouyang, T. He, and H. Zhao. Point transformer v3: Simpler faster stronger. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4840–4851, 2024
2024
-
[58]
X. Wu, D. DeTone, D. Frost, T. Shen, C. Xie, N. Yang, J. Engel, R. Newcombe, H. Zhao, and J. Straub. Sonata: Self-supervised learning of reliable point representations. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 22193–22204, 2025
2025
-
[59]
Xiang, Y
F. Xiang, Y . Qin, K. Mo, Y . Xia, H. Zhu, F. Liu, M. Liu, H. Jiang, Y . Yuan, H. Wang, et al. Sapien: A simulated part-based interactive environment. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11097–11107, 2020
2020
-
[60]
R. Xu, X. Wang, T. Wang, Y . Chen, J. Pang, and D. Lin. Pointllm: Empowering large language models to understand point clouds. InEuropean Conference on Computer Vision, pages 131–147. Springer, 2024
2024
- [61]
-
[62]
L. Yi, V . G. Kim, D. Ceylan, I.-C. Shen, M. Yan, H. Su, C. Lu, Q. Huang, A. Sheffer, and L. Guibas. A scalable active framework for region annotation in 3d shape collections.ACM Transactions on Graphics (ToG), 35(6):1–12, 2016
2016
-
[63]
Zemskova and D
T. Zemskova and D. Yudin. 3dgraphllm: Combining semantic graphs and large language models for 3d scene understanding. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 8885–8895, 2025
2025
- [64]
-
[65]
Zhang, Z
Y . Zhang, Z. Gong, and A. X. Chang. Multi3drefer: Grounding text description to multiple 3d objects. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 15225–15236, 2023. 13
2023
-
[66]
arXiv preprint arXiv:2510.23607 (2025)
Y . Zhang, X. Wu, Y . Lao, C. Wang, Z. Tian, N. Wang, and H. Zhao. Concerto: Joint 2d-3d self-supervised learning emerges spatial representations.arXiv preprint arXiv:2510.23607, 2025
- [67]
-
[68]
H. Zhao, L. Jiang, J. Jia, P. H. Torr, and V . Koltun. Point transformer. InProceedings of the IEEE/CVF international conference on computer vision, pages 16259–16268, 2021
2021
-
[69]
Zheng, S
D. Zheng, S. Huang, and L. Wang. Video-3d llm: Learning position-aware video representation for 3d scene understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8995–9006, 2025
2025
- [70]
-
[71]
C. Zhu, T. Wang, W. Zhang, K. Chen, and X. Liu. Scanreason: Empowering 3d visual grounding with reasoning capabilities. InEuropean Conference on Computer Vision, pages 151–168. Springer, 2024
2024
-
[72]
C. Zhu, T. Wang, W. Zhang, J. Pang, and X. Liu. Llava-3d: A simple yet effective pathway to empowering lmms with 3d capabilities. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 4295–4305, 2025
2025
-
[73]
Z. Zhu, X. Ma, Y . Chen, Z. Deng, S. Huang, and Q. Li. 3d-vista: Pre-trained transformer for 3d vision and text alignment. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 2911–2921, 2023. 14 A Evaluation Metrics We evaluate PAR3D with existing approaches on referring segmentation, visual question answering, and dense capti...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.