Tree-of-Experience: A Structured Experience-Management Solution for Self-Evolving Agents under Low-Repetition and Implicit-Reward Environments
Pith reviewed 2026-06-27 22:22 UTC · model grok-4.3
The pith
A tree-structured experience system lets LLM agents improve where tasks rarely repeat and feedback is delayed and noisy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In low-repetition implicit-reward environments, general-purpose experience mechanisms do not consistently outperform no-experience baselines, while Tree-of-Experience achieves stronger overall performance by organizing, retrieving, validating, and updating agent experience.
What carries the argument
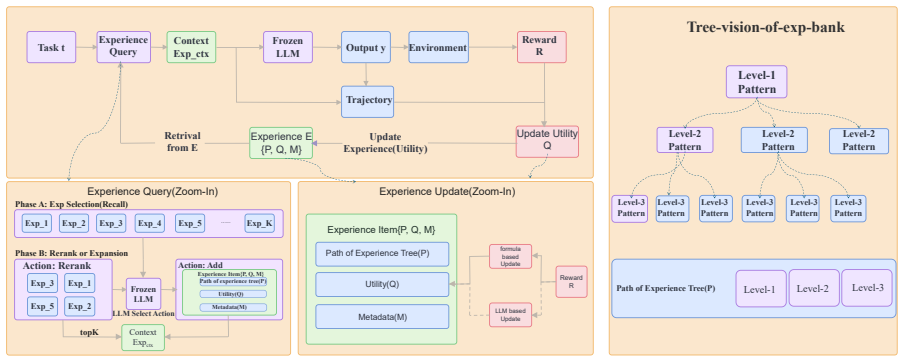
Tree-of-Experience (ToE), a structured method that organizes, retrieves, validates, and updates agent experience inside a tree.
If this is right
- General-purpose experience mechanisms often match or fall below no-experience performance in the studied setting.
- Tree-of-Experience delivers measurably stronger results on the financial sentiment benchmark.
- Structured organization of experience becomes necessary once tasks do not repeat and rewards stay implicit.
- Without such structure, simply accumulating experience provides little or no advantage to self-evolving agents.
Where Pith is reading between the lines
- The same tree organization could be tested on non-financial tasks such as medical decision sequences or adaptive planning where repetition is low.
- Agents using Tree-of-Experience might maintain useful memory over longer horizons without explicit reward signals.
- Combining the tree with retrieval-augmented generation could further reduce the impact of noisy outcome feedback.
Load-bearing premise
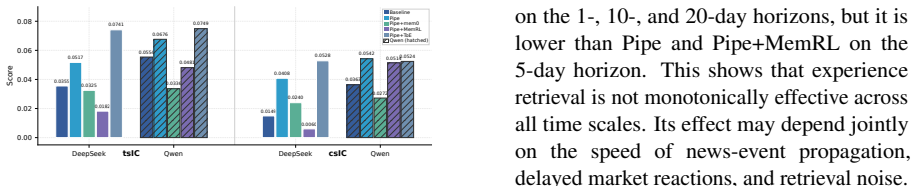
FinEvolveBench, which scores news-based predictions by later excess returns, is a valid general model of low-repetition implicit-reward environments.
What would settle it
An experiment in which Tree-of-Experience fails to outperform both no-experience and generic experience baselines on a second low-repetition implicit-reward task outside finance.
Figures


read the original abstract
Experience-based self-evolution is crucial for LLM agents, but existing benchmarks often assume explicit goals, stable task patterns, and clear feedback. We study a more challenging setting: low-repetition tasks with implicit rewards, where past experience is difficult to reuse and feedback is delayed, noisy, and outcome-level. We introduce \textsc{FinEvolveBench}, a temporally controlled benchmark for financial sentiment prediction that links daily news-driven predictions to future excess returns. We further propose Tree-of-Experience (ToE), a structured experience-management method that organizes, retrieves, validates, and updates agent experience. Experiments show that general-purpose experience mechanisms do not consistently outperform no-experience baselines, while ToE achieves stronger overall performance. These results highlight the importance of structured experience management for self-evolving agents in implicit-reward environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FinEvolveBench, a temporally controlled benchmark linking daily news-driven financial sentiment predictions to future excess returns, to study LLM agent self-evolution in low-repetition tasks with implicit, delayed, and noisy rewards. It proposes Tree-of-Experience (ToE), a structured experience-management approach that organizes, retrieves, validates, and updates experiences, and reports experiments showing that general-purpose experience mechanisms do not consistently outperform no-experience baselines while ToE achieves stronger overall performance.
Significance. If the experimental results hold under a benchmark that genuinely enforces low repetition and implicit rewards, the work provides concrete evidence that unstructured experience mechanisms are insufficient in such regimes and that structured management yields measurable gains. This could inform the design of self-evolving agents for domains like finance where task patterns do not repeat and feedback is outcome-level only.
major comments (2)
- [§3, §4] §4 (Experiments) and §3 (FinEvolveBench): the central claim that general experience mechanisms fail to beat no-experience baselines while ToE succeeds rests on the benchmark enforcing minimal transferable patterns across days and purely outcome-level rewards. The manuscript must include explicit analysis (e.g., overlap statistics on news features or reward-signal leakage checks) demonstrating that daily tasks remain low-repetition and that excess-return computation introduces no intermediate explicit signals; without this, the performance gap could be an artifact of a standard prediction task rather than evidence for the stated regime.
- [§4] §4.1–4.3: the abstract and experimental summary state that ToE outperforms baselines, yet no information is supplied on number of runs, statistical tests, variance across seeds, or precise baseline implementations (e.g., how retrieval-augmented or memory-augmented agents are instantiated). These omissions prevent verification that the reported superiority is robust and load-bearing for the claim.
minor comments (1)
- [§2] Notation for experience nodes and validation steps in the ToE description could be formalized with pseudocode or a diagram to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the requirements for validating our benchmark and experimental claims. We address each major point below and will revise the manuscript to incorporate the requested analyses and details.
read point-by-point responses
-
Referee: [§3, §4] §4 (Experiments) and §3 (FinEvolveBench): the central claim that general experience mechanisms fail to beat no-experience baselines while ToE succeeds rests on the benchmark enforcing minimal transferable patterns across days and purely outcome-level rewards. The manuscript must include explicit analysis (e.g., overlap statistics on news features or reward-signal leakage checks) demonstrating that daily tasks remain low-repetition and that excess-return computation introduces no intermediate explicit signals; without this, the performance gap could be an artifact of a standard prediction task rather than evidence for the stated regime.
Authors: We agree that explicit validation of the benchmark's low-repetition and implicit-reward properties is necessary to support the central claim. In the revised version, we will add overlap statistics (e.g., average cosine similarity and Jaccard index on daily news embeddings and entity features across consecutive days) and explicit checks confirming that excess-return labels provide no intermediate signals or leakage. These additions will be placed in §3 and referenced in §4 to demonstrate that transferable patterns are minimal. revision: yes
-
Referee: [§4] §4.1–4.3: the abstract and experimental summary state that ToE outperforms baselines, yet no information is supplied on number of runs, statistical tests, variance across seeds, or precise baseline implementations (e.g., how retrieval-augmented or memory-augmented agents are instantiated). These omissions prevent verification that the reported superiority is robust and load-bearing for the claim.
Authors: We acknowledge these omissions limit verifiability. The revised manuscript will expand §4.1–4.3 with: (i) number of independent runs (5 random seeds), (ii) statistical tests (paired t-tests with p-values and effect sizes), (iii) variance/std across seeds for all metrics, and (iv) precise baseline instantiations, including retrieval parameters, memory buffer sizes, and update rules for the retrieval-augmented and memory-augmented agents. This will be summarized in a new experimental-details subsection. revision: yes
Circularity Check
No circularity; claims rest on external experimental comparisons
full rationale
The paper introduces FinEvolveBench and the ToE method, then reports experimental results comparing experience mechanisms against no-experience baselines. No equations, derivations, or first-principles results are presented that reduce to fitted parameters, self-definitions, or self-citation chains. Performance claims are grounded in benchmark outcomes rather than quantities defined in terms of themselves. The benchmark construction and method are described independently of the reported metrics, satisfying the criteria for a self-contained experimental contribution.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Experience from past tasks can be structured to improve future performance in low-repetition implicit-reward environments
invented entities (1)
-
Tree-of-Experience
no independent evidence
Reference graph
Works this paper leans on
-
[1]
FinBERT: Financial Sentiment Analysis with Pre-trained Language Models
FinBERT: Financial sentiment analy- sis with pre-trained language models.arXiv preprint arXiv:1908.10063. Victor Barres and 1 others
work page internal anchor Pith review Pith/arXiv arXiv 1908
-
[2]
$\tau^2$-Bench: Evaluating Conversational Agents in a Dual-Control Environment
τ 2-bench: Evaluating conversational agents in a dual-control setting.arXiv preprint arXiv:2506.07982. Kaiyuan Chen and 1 others. 2025a. Xbench: Track- ing agents productivity scaling with profession- aligned real-world evaluations.arXiv preprint arXiv:2506.13651. Yanxu Chen, Zijun Yao, Yantao Liu, Amy Xin, Jin Ye, Jianing Yu, Lei Hou, and Juanzi Li. 2025...
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
Mem0: Building production-ready ai agents with scalable long-term memory.Preprint, arXiv:2504.19413. Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
SWE-bench: Can language mod- els resolve real-world github issues?arXiv preprint arXiv:2310.06770. Alejandro Lopez-Lira and Yuehua Tang
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
arXiv preprint arXiv:2304.07619 , year=
Can ChatGPT forecast stock price movements? return pre- dictability and large language models.arXiv preprint arXiv:2304.07619. Grégoire Mialon, Clémentine Fourrier, Craig Swift, Thomas Wolf, Yann LeCun, and Thomas Scialom
-
[6]
GAIA: a benchmark for General AI Assistants
GAIA: A benchmark for general ai assistants. arXiv preprint arXiv:2311.12983. Saloni Mohan, Sahitya Mullapudi, Sudheer Sammeta, Parag Vijayvergia, and David C. Anastasiu
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Humanity’s last exam.arXiv preprint arXiv:2501.14249. Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
ALFWorld: Aligning Text and Embodied Environments for Interactive Learning
Alfworld: Aligning text and em- bodied environments for interactive learning.arXiv preprint arXiv:2010.03768. David Silver and Richard S. Sutton
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[9]
Evo-Memory: Benchmarking LLM Agent Test-time Learning with Self-Evolving Memory
Evo-memory: Benchmarking llm agent test-time learning with self-evolving memory.arXiv preprint arXiv:2511.20857. Qianqian Xie and 1 others
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
arXiv preprint arXiv:2306.06031 (2023)
FinGPT: Open-source financial large language models.arXiv preprint arXiv:2306.06031. Shengtao Zhang, Jiaqian Wang, Ruiwen Zhou, Junwei Liao, Yuchen Feng, and 1 others
-
[11]
MemRL: Self-Evolving Agents via Runtime Reinforcement Learning on Episodic Memory
MemRL: Self-evolving agents via runtime reinforcement learning on episodic memory.arXiv preprint arXiv:2601.03192. Junhao Zheng, Xidi Cai, Qiuke Li, Duzhen Zhang, ZhongZhi Li, Yingying Zhang, Le Song, and Qianli Ma
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
arXiv preprint arXiv:2505.11942 , year=
Lifelongagentbench: Evalu- ating llm agents as lifelong learners.Preprint, arXiv:2505.11942. Fengbin Zhu, Wenqiang Lei, Youcheng Huang, Chao Wang, Shuo Zhang, Jiancheng Lv, Fuli Feng, and Tat- Seng Chua
-
[13]
InInternational Conference on Learning Representations, volume 2025, pages 66602–66656
Bigcodebench: Benchmarking code generation with diverse function calls and complex in- structions. InInternational Conference on Learning Representations, volume 2025, pages 66602–66656. 10 8 Appendix 8.1 Details of FinEvolveBench This section supplements the main text with addi- tional construction details of FINEVOLVEBENCH, including the investment univ...
2025
-
[14]
news / day 254.78 Avg
The Statistic Value Market universe 31 SW first-level industry indices Processed span 2024-01-01 to 2026-05-03 Online evaluation span 2025-01-01 to 2026-03-31 Trading days in evaluation 300 Training split None News articles 177,324 Active news days 696 Avg. news / day 254.78 Avg. news / industry / day 6.08 Prediction horizons 1, 5, 10, 20 trading days Tab...
2024
-
[15]
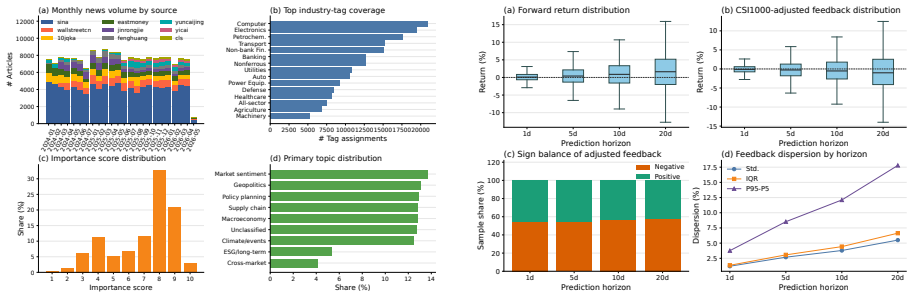
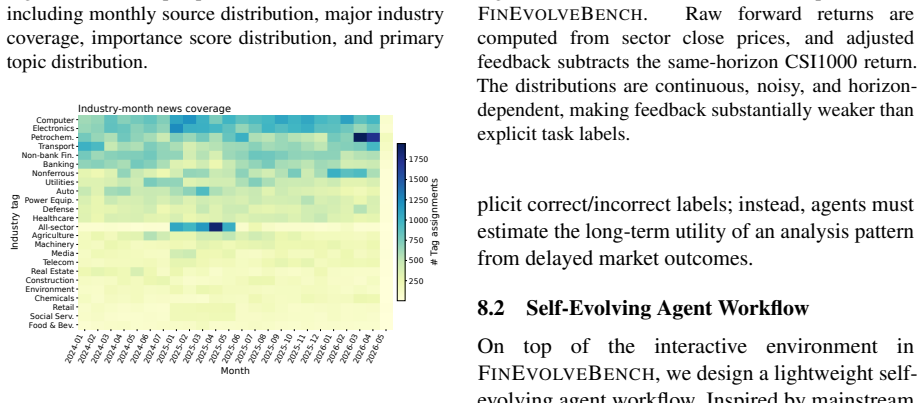
Figure 6 further shows the monthly industry ex- posure intensity
The topic distribution covers macroeconomics, pol- icy planning, industrial and supply chains, geopol- itics, market sentiment behavior, natural climate, and other event categories. Figure 6 further shows the monthly industry ex- posure intensity. The coverage shifts across in- dustries over time, indicating that the environment is non-stationary and not ...
2024
-
[16]
Step 4: Validation and Reflection.After task execution, the environment records the prediction trajectory but does not reveal feedback immedi- ately
and FinGPT (Yang et al., 2023), the agent gener- ates a continuous sentiment score in the range of [−1,1]for the target under analysis. Step 4: Validation and Reflection.After task execution, the environment records the prediction trajectory but does not reveal feedback immedi- ately. Once the price corresponding to the predic- tion horizon becomes observ...
2023
-
[17]
Each structured experience de- composes prior market reasoning into a reusable factor, a concreteanalysis direction, horizon- specific utility estimates, and non-semantic meta- data such as recall counts, hit counts, and experi- ence identifiers. Thefactorandanalysis direction fields form reusable paradigm paths, theimpact horizonscorrespond to task-relat...
2024
-
[18]
The online evaluation window is fixed to January 1, 2025–March 31, 2026, covering 300 trading days. Data before the evaluation window is used only as the left temporal buffer for cold start, experience initialization, and historical calibration, while data after the evaluation window is used only as the right temporal buffer for delayed feedback computati...
2025
-
[19]
for experience management. It re- trieves relevant experience using the MemRL retrieval policy, passes the retrieved expe- rience and aggregated news to the predic- tion module, and updates experience with the MemRL update mechanism after the corre- sponding feedback becomes observable. • Pipe+ToE (ours): After obtaining the ag- gregated news, this method...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.