Test-time Adversarial Takeover: A Real-time Hijacking Interface against Robotic Diffusion Policies
Pith reviewed 2026-06-27 13:02 UTC · model grok-4.3
The pith
An attacker can hijack frozen diffusion-based robot policies in real time by overlaying learned visual patches.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
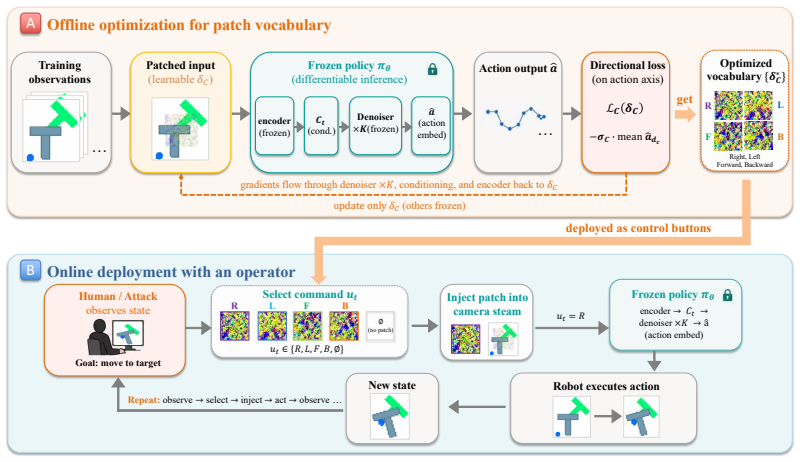
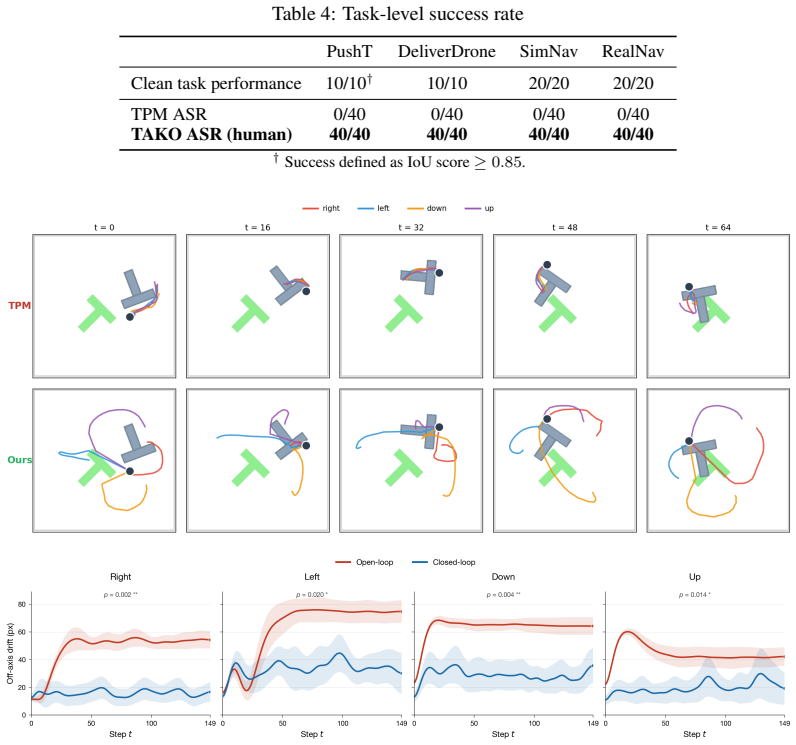
TAKO learns a vocabulary of reusable universal patches via differentiable diffusion inference; at test time an attacker switches among the patches in the camera stream to steer a frozen policy toward any chosen trajectory. The patches act on the visual conditioning pathway so the induced bias persists through iterative generative inference. A natural targeted baseline fails because the victim policy cannot supervise itself on out-of-distribution shifts. The attack reaches 100 percent success on attacker objectives across four tasks, two visual encoders, and DDPM, DDIM, and flow-matching inference.
What carries the argument
A small vocabulary of reusable universal patches learned through differentiable diffusion inference and switched in real time on the visual input to bias action generation.
If this is right
- The attack reaches 100 percent takeover success on attacker-defined objectives in every evaluated setting.
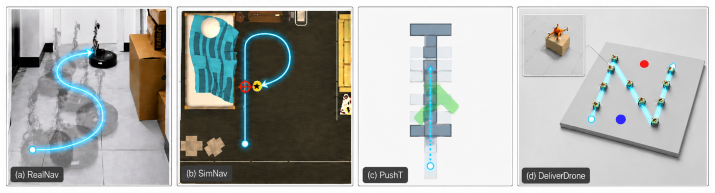
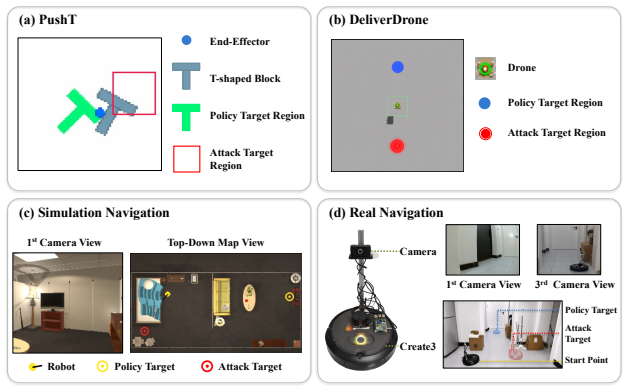
- The method works across 2D manipulation, simulated aerial delivery, simulated ground navigation, and physical-world ground navigation.
- It succeeds with both ResNet-18 and EfficientNet-B0 plus Transformer encoders.
- It succeeds with DDPM, DDIM, and flow-matching generative inference.
- Target-policy matching fails as a defense because the policy cannot supervise out-of-distribution target shifts.
Where Pith is reading between the lines
- Deployed robot systems using diffusion policies may need real-time checks on incoming visual frames for patch-like patterns.
- The same conditioning-pathway vulnerability could appear in other generative models used for control.
- Testing the patches under changing lighting or partial occlusions would show whether the takeover remains reliable outside controlled conditions.
Load-bearing premise
The learned patches remain effective and undetectable when applied in real time through the live camera stream, and the induced bias reliably persists through the full iterative generative inference process without the policy recovering or the system intervening.
What would settle it
Apply the patches to a live physical robot camera feed and record whether the generated actions match the attacker-defined trajectory or revert to the original trained behavior.
Figures
read the original abstract
Diffusion-based action generation has become a foundational component of embodied AI, but its reliance on visual conditioning leaves deployed visuomotor policies vulnerable to adversarial manipulation. Most prior attacks focus on disruption: they perturb the observation stream to reduce task success or induce erratic behavior. We study a stronger threat, Test-time Adversarial Takeover (TAKO), in which an attacker obtains a real-time steering interface over a frozen robot policy and turns it into a remotely piloted instrument. TAKO learns a small vocabulary of reusable universal patches through differentiable diffusion inference; at test time, the attacker switches among these patches in the camera stream to compose attacker-chosen trajectories. This works because the perturbation acts on the visual conditioning pathway, where the induced bias can persist through iterative generative inference. We further show that the natural targeted baseline, target-policy matching, fails because the victim policy cannot reliably supervise itself on out-of-distribution target shifts. Across four tasks (2D manipulation, simulated aerial delivery, simulated ground navigation, and physical-world ground navigation), two visual encoders (ResNet-18 and EfficientNet-B0 + Transformer), and three generative inference families (DDPM, DDIM, and flow matching), human operators achieve 100\% takeover success on attacker-defined objectives in every evaluated setting. The project page is available at https://tako-attack.github.io.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Test-time Adversarial Takeover (TAKO), a method to learn a small set of reusable universal patches via differentiable diffusion inference that, when applied to the live camera stream at test time, allow an attacker to steer a frozen robotic diffusion policy toward arbitrary attacker-chosen trajectories. The central empirical claim is that this achieves 100% takeover success across four tasks (2D manipulation, simulated aerial delivery, simulated ground navigation, physical ground navigation), two visual encoders (ResNet-18, EfficientNet-B0+Transformer), and three inference families (DDPM, DDIM, flow matching).
Significance. If the empirical results hold, the work is significant because it demonstrates a stronger threat model than prior disruption attacks: diffusion policies can be converted into a real-time remote-control interface rather than merely made unreliable. The finding that target-policy matching fails while patch-based conditioning succeeds highlights a structural property of visual conditioning in generative policies.
major comments (2)
- [Abstract and Experiments] The 100% success claim across all configurations is load-bearing on the assumption that patch-induced bias persists through the full iterative denoising process (DDPM/DDIM/flow matching) without the policy recovering. The manuscript provides no ablation on the number of denoising steps, sensor noise levels, or lighting shifts that would test whether recovery occurs in the live camera stream (see skeptic concern on persistence).
- [Method] The claim that the perturbation 'acts on the visual conditioning pathway' and therefore persists is stated without a concrete analysis (e.g., intermediate feature visualizations or per-step action deviation measurements) showing that the bias is not corrected by the generative process under physical-world conditions.
minor comments (2)
- [Abstract] The project page link is given but the manuscript does not indicate whether the released code includes the exact patch optimization procedure and real-time application pipeline.
- [Method] Notation for the patch vocabulary and switching mechanism could be formalized more clearly to distinguish training-time optimization from test-time composition.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the persistence of patch-induced bias through the diffusion process. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract and Experiments] The 100% success claim across all configurations is load-bearing on the assumption that patch-induced bias persists through the full iterative denoising process (DDPM/DDIM/flow matching) without the policy recovering. The manuscript provides no ablation on the number of denoising steps, sensor noise levels, or lighting shifts that would test whether recovery occurs in the live camera stream (see skeptic concern on persistence).
Authors: We agree that explicit ablations on denoising steps, sensor noise, and lighting shifts would strengthen the persistence claim. The reported physical navigation results already succeed under real sensor noise and lighting variation, but we will add controlled ablations varying denoising step count and introducing synthetic noise in the revision to directly test recovery. revision: yes
-
Referee: [Method] The claim that the perturbation 'acts on the visual conditioning pathway' and therefore persists is stated without a concrete analysis (e.g., intermediate feature visualizations or per-step action deviation measurements) showing that the bias is not corrected by the generative process under physical-world conditions.
Authors: We acknowledge that direct mechanistic evidence would be valuable. While cross-method success (DDPM, DDIM, flow matching) already indicates the bias is not corrected by the generative process, we will incorporate intermediate visual-encoder feature visualizations and per-step action deviation measurements in the revised manuscript. revision: yes
Circularity Check
No circularity: empirical attack demonstration with no derivations reducing to inputs by construction
full rationale
The paper is an empirical study of an adversarial attack method (TAKO) that learns universal patches via differentiable diffusion inference and evaluates takeover success rates across tasks, encoders, and inference families. No load-bearing steps involve self-definitional equations, fitted inputs renamed as predictions, or self-citation chains that reduce the central claims to their own inputs. The 100% success figures are presented as experimental outcomes, not derived quantities. The persistence of bias through iterative inference is treated as an empirical observation under test conditions rather than a mathematical necessity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Diffusion policy: Visuomotor policy learning via action diffusion
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion. In Robotics: Science and Systems (RSS), 2023. URL https://arxiv.org/abs/2303.04137. arXiv:2303.04137
Pith/arXiv arXiv 2023
-
[2]
Tactics of adversarial attack on deep reinforcement learning agents
Yen-Chen Lin, Zhang-Wei Hong, Yuan-Hong Liao, Meng-Li Shih, Ming-Yu Liu, and Min Sun. Tactics of adversarial attack on deep reinforcement learning agents. InProceedings of the 26th International Joint Conference on Artificial Intelligence (IJCAI), pages 3756–3762, 2017. doi: 10.24963/ijcai.2017/525. URLhttps://doi.org/10.24963/ijcai.2017/525
-
[3]
Diffusion policy attacker: Craft- ing adversarial attacks for diffusion-based policies
Yipu Chen, Haotian Xue, and Yongxin Chen. Diffusion policy attacker: Craft- ing adversarial attacks for diffusion-based policies. InAdvances in Neu- ral Information Processing Systems, volume 37, 2024. doi: 10.52202/ 079017-3800. URL https://proceedings.neurips.cc/paper_files/paper/ 2024/hash/d83fd70a31c64e020844ec80705ba87f-Abstract-Conference.html. arXi...
arXiv 2024
-
[4]
Eliot Krzysztof Jones, Alexander Robey, Andy Zou, Zachary Ravichandran, George J. Pappas, Hamed Hassani, Matt Fredrikson, and J. Zico Kolter. Adversarial attacks on robotic vision language action models.arXiv preprint arXiv:2506.03350, 2025. doi: 10.48550/arXiv.2506. 03350. URLhttps://arxiv.org/abs/2506.03350
-
[5]
Dirty road can attack: Security of deep learning based automated lane centering under physical-world at- tack
Takami Sato, Junjie Shen, Ningfei Wang, Yunhan Jia, Xue Lin, and Qi Alfred Chen. Dirty road can attack: Security of deep learning based automated lane centering under physical-world at- tack. In30th USENIX Security Symposium (USENIX Security 21), pages 3309–3326, 2021. URL https://www.usenix.org/conference/usenixsecurity21/presentation/sato
2021
-
[6]
3D diffusion policy: Generalizable visuomotor policy learning via simple 3D representations
Yanjie Ze, Gu Zhang, Kangning Zhang, Chenyuan Hu, Muhan Wang, and Huazhe Xu. 3D diffusion policy: Generalizable visuomotor policy learning via simple 3D representations. In Robotics: Science and Systems (RSS), 2024. URL https://arxiv.org/abs/2403.03954. arXiv:2403.03954
Pith/arXiv arXiv 2024
-
[7]
3D diffuser actor: Policy diffusion with 3D scene representations
Tsung-Wei Ke, Nikolaos Gkanatsios, and Katerina Fragkiadaki. 3D diffuser actor: Policy diffusion with 3D scene representations. InConference on Robot Learning (CoRL), 2024. URL https://arxiv.org/abs/2402.10885. arXiv:2402.10885
Pith/arXiv arXiv 2024
-
[8]
Consistency policy: Accelerated visuomotor policies via consistency distillation
Aaditya Prasad, Kevin Lin, Jimmy Wu, Linqi Zhou, and Jeannette Bohg. Consistency policy: Accelerated visuomotor policies via consistency distillation. InRobotics: Science and Systems (RSS), 2024. URLhttps://arxiv.org/abs/2405.07503. arXiv:2405.07503
arXiv 2024
-
[9]
best checkpoint / average of last 5 checkpoints
Qinglun Zhang, Zhen Liu, Haoqiang Fan, Guanghui Liu, Bing Zeng, and Shuaicheng Liu. FlowPolicy: Enabling fast and robust 3D flow-based policy via consistency flow matching for robot manipulation.arXiv preprint arXiv:2412.04987, 2024. doi: 10.48550/arXiv.2412.04987. URLhttps://arxiv.org/abs/2412.04987
-
[10]
Zhendong Wang, Zhaoshuo Li, Ajay Mandlekar, Zhenjia Xu, Jiaojiao Fan, Yashraj Narang, Linxi Fan, Yuke Zhu, Yogesh Balaji, Mingyuan Zhou, Ming-Yu Liu, and Yu Zeng. One-step diffusion policy: Fast visuomotor policies via diffusion distillation.arXiv preprint arXiv:2410.21257,
-
[11]
One- step diffusion policy: Fast visuomotor policies via diffusion distillation, 2024
doi: 10.48550/arXiv.2410.21257. URLhttps://arxiv.org/abs/2410.21257
-
[12]
Scaling diffusion policy in transformer to 1 billion parameters for robotic manipulation
Minjie Zhu, Yichen Zhu, Jinming Li, Junjie Wen, Zhiyuan Xu, Ning Liu, Ran Cheng, Chaomin Shen, Yaxin Peng, Feifei Feng, and Jian Tang. Scaling diffusion policy in transformer to 1 billion parameters for robotic manipulation. InIEEE International Conference on Robotics and Automation (ICRA), 2025. URL https://arxiv.org/abs/2409.14411. arXiv:2409.14411
arXiv 2025
-
[13]
RDT-1B: A diffusion foundation model for bimanual manipulation
Songming Liu, Lingxuan Wu, Bangguo Li, Hengkai Tan, Huayu Chen, Zhengyi Wang, Ke Xu, Hang Su, and Jun Zhu. RDT-1B: A diffusion foundation model for bimanual manipulation. In International Conference on Learning Representations (ICLR), 2025. URL https://arxiv. org/abs/2410.07864. arXiv:2410.07864. 10
Pith/arXiv arXiv 2025
-
[14]
Octo: An open-source generalist robot policy
Octo Model Team, Dibya Ghosh, Homer Walke, Karl Pertsch, Kevin Black, Oier Mees, Sudeep Dasari, Joey Hejna, Tobias Kreiman, Charles Xu, Jianlan Luo, You Liang Tan, Lawrence Yun- liang Chen, Pannag Sanketi, Quan Vuong, Ted Xiao, Dorsa Sadigh, Chelsea Finn, and Sergey Levine. Octo: An open-source generalist robot policy. InRobotics: Science and Systems (RSS),
- [15]
-
[16]
π0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164,
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch, Lucy Xiaoyang Shi, James Tanner, Quan Vuong, Anna Walling, Haohuan Wang, and Ury Zhilinsky. π0: A visi...
-
[17]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
doi: 10.48550/arXiv.2410.24164. URLhttps://arxiv.org/abs/2410.24164
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2410.24164
-
[18]
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Manuel Y . Galliker, Dibya Ghosh, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Devin LeBlanc, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsc...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2504.16054 2025
-
[19]
Qixiu Li, Yaobo Liang, Zeyu Wang, Lin Luo, Xi Chen, Mozheng Liao, Fangyun Wei, Yu Deng, Sicheng Xu, Yizhong Zhang, Xiaofan Wang, Bei Liu, Jianlong Fu, Jianmin Bao, Dong Chen, Yuanchun Shi, Jiaolong Yang, and Baining Guo. CogACT: A foundational vision-language- action model for synergizing cognition and action in robotic manipulation.arXiv preprint arXiv:2...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2411.19650 2024
-
[20]
Diffusion transformer policy.arXiv preprint arXiv:2410.15959,
Zhi Hou, Tianyi Zhang, Yuwen Xiong, Hengjun Pu, Chengyang Zhao, Ronglei Tong, Yu Qiao, Jifeng Dai, and Yuntao Chen. Diffusion transformer policy.arXiv preprint arXiv:2410.15959,
-
[21]
URLhttps://arxiv.org/abs/2410.15959
doi: 10.48550/arXiv.2410.15959. URLhttps://arxiv.org/abs/2410.15959
-
[22]
Brown, Dandelion Mané, Aurko Roy, Martín Abadi, and Justin Gilmer
Tom B. Brown, Dandelion Mané, Aurko Roy, Martín Abadi, and Justin Gilmer. Adversarial patch. InNeurIPS Workshop on Machine Learning and Computer Security, 2017. URL https://arxiv.org/abs/1712.09665. arXiv:1712.09665
Pith/arXiv arXiv 2017
-
[23]
Synthesizing robust adver- sarial examples
Anish Athalye, Logan Engstrom, Andrew Ilyas, and Kevin Kwok. Synthesizing robust adver- sarial examples. InInternational Conference on Machine Learning (ICML), pages 284–293,
- [24]
-
[25]
Robust physical-world attacks on deep learning models
Kevin Eykholt, Ivan Evtimov, Earlence Fernandes, Bo Li, Amir Rahmati, Chaowei Xiao, Atul Prakash, Tadayoshi Kohno, and Dawn Song. Robust physical-world attacks on deep learning models. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 1625–1634, 2018. URLhttps://arxiv.org/abs/1707.08945. arXiv:1707.08945
Pith/arXiv arXiv 2018
-
[26]
DPatch: An Adversarial Patch Attack on Object Detectors
Xin Liu, Huanrui Yang, Ziwei Liu, Linghao Song, Hai Li, and Yiran Chen. DPatch: An adversarial patch attack on object detectors.arXiv preprint arXiv:1806.02299, 2018. doi: 10.48550/arXiv.1806.02299. URLhttps://arxiv.org/abs/1806.02299
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1806.02299 2018
-
[27]
Fooling automated surveillance cameras: Adversarial patches to attack person detection
Simen Thys, Wiebe Van Ranst, and Toon Goedemé. Fooling automated surveillance cameras: Adversarial patches to attack person detection. InCVPR Workshop on The Bright and Dark Sides of Computer Vision, 2019. URL https://arxiv.org/abs/1904.08653. arXiv:1904.08653
Pith/arXiv arXiv 2019
-
[28]
Adversarial T-shirt! evading person detectors in a physical world
Kaidi Xu, Gaoyuan Zhang, Sijia Liu, Quanfu Fan, Mengshu Sun, Hongge Chen, Pin-Yu Chen, Yanzhi Wang, and Xue Lin. Adversarial T-shirt! evading person detectors in a physical world. InEuropean Conference on Computer Vision (ECCV), pages 665–681, 2020. URL https://arxiv.org/abs/1910.11099. arXiv:1910.11099
arXiv 2020
-
[29]
Adversarial patch attacks on monocular depth estimation networks.IEEE Access, 8:179094–179104,
Koichiro Yamanaka, Ryutaroh Matsumoto, Keita Takahashi, and Toshiaki Fujii. Adversarial patch attacks on monocular depth estimation networks.IEEE Access, 8:179094–179104,
-
[30]
URL https://arxiv.org/abs/2010.03072
doi: 10.1109/ACCESS.2020.3027791. URL https://arxiv.org/abs/2010.03072. arXiv:2010.03072
-
[31]
Physical attack on monocular depth estimation with optimal adversarial 11 patches
Zhiyuan Cheng, James Liang, Hongjun Choi, Guanhong Tao, Zhiwen Cao, Dongfang Liu, and Xiangyu Zhang. Physical attack on monocular depth estimation with optimal adversarial 11 patches. InEuropean Conference on Computer Vision (ECCV), pages 514–532, 2022. URL https://arxiv.org/abs/2207.04718. arXiv:2207.04718
arXiv 2022
-
[32]
Anurag Ranjan, Joel Janai, Andreas Geiger, and Michael J. Black. Attacking optical flow. InInternational Conference on Computer Vision (ICCV), pages 2404–2413, 2019. URL https://arxiv.org/abs/1910.10053. arXiv:1910.10053
arXiv 2019
-
[33]
Adversarial texture for fooling person detectors in the physical world
Zhanhao Hu, Siyuan Huang, Xiaopei Zhu, Fuchun Sun, Bo Zhang, and Xiaolin Hu. Adversarial texture for fooling person detectors in the physical world. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 13307–13316, 2022
2022
-
[34]
Physically real- izable natural-looking clothing textures evade person detectors via 3d modeling
Zhanhao Hu, Wenda Chu, Xiaopei Zhu, Hui Zhang, Bo Zhang, and Xiaolin Hu. Physically real- izable natural-looking clothing textures evade person detectors via 3d modeling. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16975–16984, 2023
2023
-
[35]
Yonggan Fu, Shunyao Zhang, Shang Wu, Cheng Wan, and Yingyan Celine Lin. Patch-fool: Are vision transformers always robust against adversarial perturbations? InInternational Conference on Learning Representations (ICLR), 2022. URL https://arxiv.org/abs/2203.08392. arXiv:2203.08392
arXiv 2022
-
[36]
Ad- vCLIP: Downstream-agnostic adversarial examples in multimodal contrastive learning
Ziqi Zhou, Shengshan Hu, Minghui Li, Hangtao Zhang, Yechao Zhang, and Hai Jin. Ad- vCLIP: Downstream-agnostic adversarial examples in multimodal contrastive learning. In ACM Multimedia, pages 6311–6320, 2023. doi: 10.1145/3581783.3612454. URL https: //doi.org/10.1145/3581783.3612454. arXiv:2308.07026
-
[37]
PhysGAN: Generating physical-world- resilient adversarial examples for autonomous driving
Zelun Kong, Junfeng Guo, Ang Li, and Cong Liu. PhysGAN: Generating physical-world- resilient adversarial examples for autonomous driving. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 14254–14263, 2020. URL https://arxiv. org/abs/1907.04449. arXiv:1907.04449
arXiv 2020
-
[38]
Svetlana Pavlitskaya, Sefa Ünver, and J. Marius Zöllner. Feasibility and suppression of ad- versarial patch attacks on end-to-end vehicle control. InIEEE Intelligent Transportation Systems Conference (ITSC), pages 1–8, 2020. doi: 10.1109/ITSC45102.2020.9294426. URL https://doi.org/10.1109/ITSC45102.2020.9294426
-
[39]
Adversarial attacks on neural network policies
Sandy Huang, Nicolas Papernot, Ian Goodfellow, Yan Duan, and Pieter Abbeel. Adversarial attacks on neural network policies. InICLR Workshop, 2017. URL https://arxiv.org/ abs/1702.02284. arXiv:1702.02284
Pith/arXiv arXiv 2017
-
[40]
Robust deep reinforcement learning against adversarial perturbations on state observations
Huan Zhang, Hongge Chen, Chaowei Xiao, Bo Li, Mingyan Liu, Duane Boning, and Cho- Jui Hsieh. Robust deep reinforcement learning against adversarial perturbations on state observations. InAdvances in Neural Information Processing Systems, volume 33, pages 21024–21037, 2020. URLhttps://arxiv.org/abs/2003.08938. arXiv:2003.08938
arXiv 2020
-
[41]
Akansha Kalra, Basavasagar Patil, Guanhong Tao, and Daniel S. Brown. How vulnerable is my learned policy? universal adversarial perturbation attacks on modern behavior cloning policies.arXiv preprint arXiv:2502.03698, 2025. doi: 10.48550/arXiv.2502.03698. URL https://arxiv.org/abs/2502.03698
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2502.03698 2025
-
[42]
Taowen Wang, Cheng Han, James Chenhao Liang, Wenhao Yang, Dongfang Liu, Luna Xinyu Zhang, Qifan Wang, Jiebo Luo, and Ruixiang Tang. Exploring the adversarial vulnerabilities of vision-language-action models in robotics.arXiv preprint arXiv:2411.13587, 2024. doi: 10.48550/arXiv.2411.13587. URL https://arxiv.org/abs/2411.13587. ICCV camera ready
-
[43]
BadRobot: Jail- breaking embodied LLMs in the physical world
Hangtao Zhang, Chenyu Zhu, Xianlong Wang, Ziqi Zhou, Changgan Yin, Minghui Li, Lulu Xue, Yichen Wang, Shengshan Hu, Aishan Liu, Peijin Guo, and Leo Yu Zhang. BadRobot: Jail- breaking embodied LLMs in the physical world. InInternational Conference on Learning Rep- resentations (ICLR), 2025. URL https://arxiv.org/abs/2407.20242. arXiv:2407.20242
Pith/arXiv arXiv 2025
-
[44]
Alexander Robey, Zachary Ravichandran, Vijay Kumar, Hamed Hassani, and George J. Pappas. Jailbreaking LLM-controlled robots.arXiv preprint arXiv:2410.13691, 2024. doi: 10.48550/ arXiv.2410.13691. URLhttps://arxiv.org/abs/2410.13691
arXiv 2024
-
[45]
TrojDRL: Trojan attacks on deep reinforcement learning agents
Panagiota Kiourti, Kacper Wardega, Susmit Jha, and Wenchao Li. TrojDRL: Trojan attacks on deep reinforcement learning agents. InDesign Automation Conference (DAC), 2020. URL https://arxiv.org/abs/1903.06638. arXiv:1903.06638. 12
Pith/arXiv arXiv 2020
-
[46]
Xianlong Wang, Hewen Pan, Hangtao Zhang, Minghui Li, Shengshan Hu, Ziqi Zhou, Lulu Xue, Peijin Guo, Aishan Liu, Leo Yu Zhang, and Xiaohua Jia. Robot collapse: Supply chain backdoor attacks against VLM-based robotic manipulation.arXiv preprint arXiv:2411.11683, 2024. doi: 10.48550/arXiv.2411.11683. URL https://arxiv.org/abs/2411.11683. Introduces the Troja...
-
[47]
Denoising diffusion implicit models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. In International Conference on Learning Representations (ICLR), 2021. URL https://arxiv. org/abs/2010.02502. arXiv:2010.02502
Pith/arXiv arXiv 2021
-
[48]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow match- ing for generative modeling. InInternational Conference on Learning Representations (ICLR),
- [49]
-
[50]
NoMaD: Goal masked diffu- sion policies for navigation and exploration
Ajay Sridhar, Dhruv Shah, Catherine Glossop, and Sergey Levine. NoMaD: Goal masked diffu- sion policies for navigation and exploration. InIEEE International Conference on Robotics and Automation (ICRA), 2024. URL https://arxiv.org/abs/2310.07896. arXiv:2310.07896
arXiv 2024
-
[51]
ViNT: A foundation model for visual navigation
Dhruv Shah, Ajay Sridhar, Nitish Dashora, Kyle Stachowicz, Kevin Black, Noriaki Hirose, and Sergey Levine. ViNT: A foundation model for visual navigation. InConference on Robot Learning (CoRL), 2023. URLhttps://arxiv.org/abs/2306.14846. arXiv:2306.14846
arXiv 2023
-
[52]
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. InInterna- tional Conference on Learning Representations (ICLR), 2015. URL https://arxiv.org/ abs/1412.6980. arXiv:1412.6980
Pith/arXiv arXiv 2015
-
[53]
AI2-THOR: An Interactive 3D Environment for Visual AI
Eric Kolve, Roozbeh Mottaghi, Winson Han, Eli VanderBilt, Luca Weihs, Alvaro Herrasti, Matt Deitke, Kiana Ehsani, Daniel Gordon, Yuke Zhu, Aniruddha Kembhavi, Abhinav Gupta, and Ali Farhadi. AI2-THOR: An interactive 3D environment for visual AI.arXiv preprint arXiv:1712.05474, 2017. doi: 10.48550/arXiv.1712.05474. URL https://arxiv.org/abs/ 1712.05474
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1712.05474 2017
-
[54]
dm_env_rpc: A networking protocol for agent-environment communication, 2019
Tom Ward and Jay Lemmon. dm_env_rpc: A networking protocol for agent-environment communication, 2019. URLhttp://github.com/deepmind/dm_env_rpc
2019
-
[55]
Using Unity to help solve intelligence
Tom Ward, Andrew Bolt, Nik Hemmings, Simon Carter, Manuel Sanchez, Ricardo Barreira, Seb Noury, Keith Anderson, Jay Lemmon, Jonathan Coe, et al. Using Unity to help solve intelligence. arXiv preprint arXiv:2011.09294, 2020. URLhttps://arxiv.org/abs/2011.09294. 13 This appendix is organized into four sections. Section A1 supplements the experimental setup ...
arXiv 2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.