Iterative Visual Thinking: Teaching Vision-Language Models Spatial Self-Correction through Visual Feedback
Pith reviewed 2026-06-27 07:15 UTC · model grok-4.3
The pith
Vision-language models can learn to iteratively correct their own bounding-box predictions by observing rendered visual feedback.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
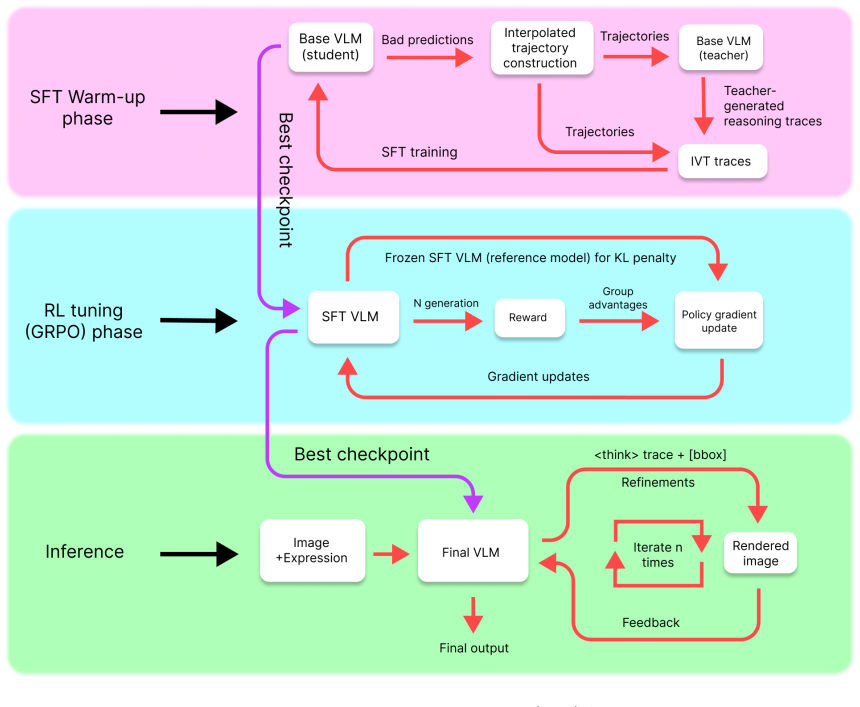
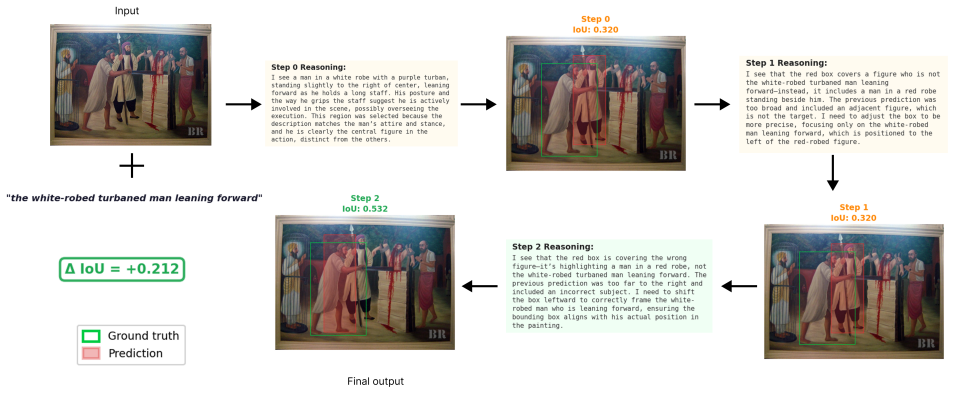
Iterative Visual Thinking supplies the missing self-correction mechanism by letting the model observe its own bounding-box prediction as an image overlay and then generate the next refinement from that visual state. The two-phase recipe first converts the base model's realistic errors into supervised corrective reasoning traces via a teacher VLM, then applies Group Relative Policy Optimization with an IoU reward to keep the multi-step trajectory stable and improving.
What carries the argument
The Iterative Visual Thinking closed-loop framework that renders each bounding-box prediction onto the input image as visual feedback for the next refinement step.
If this is right
- Supervised fine-tuning with IVT raises Acc@0.5 by 2.4 points, Acc@0.7 by 3.2 points and Acc@0.9 by 2.8 points over the single-shot baseline on the mixed RefCOCOg, Ref-Adv and Ref-L4 benchmark.
- Group Relative Policy Optimization reduces per-step IoU degradation by a factor of five compared with the supervised-only trajectory.
- Spatial self-correction becomes a learnable capability that can be instilled using only 2400 training examples on one GPU.
- The same pipeline works across three distinct referring-expression test distributions without task-specific human annotations.
Where Pith is reading between the lines
- The approach could be tested on tasks that require iterative correction of other spatial outputs such as segmentation masks or keypoint sets.
- If teacher quality proves critical, future work could explore whether weaker teachers still suffice when the reinforcement stage is made stronger.
- The small data requirement suggests the method might be applied to domain-specific VLMs where only a few hundred labeled images are available.
Load-bearing premise
A teacher vision-language model can produce high-quality corrective reasoning traces directly from the base model's erroneous predictions without any human-written examples.
What would settle it
Measure whether accuracy gains disappear when the teacher model is replaced by one that produces low-quality or inconsistent corrective traces on the same base-model errors.
Figures


read the original abstract
Vision-language models (VLMs) achieve strong singleshot spatial grounding, yet lack any mechanism to observe and correct their own predictions. We find that naively prompting a VLM to iterate over rendered visualizations of its predictions causes catastrophic failure: Acc@0.5 on referring expression comprehension collapses from 79.6% to 48.7% (a 31 percentage point drop), revealing a fundamental gap between grounding capability and self-correction ability. We propose Iterative Visual Thinking (IVT), a closed-loop framework in which the model predicts a bounding box, observes the prediction rendered on the image, and iteratively refines through visual feedback. A two-phase training recipe closes the self-correction gap: first, we exploit the base model's own predictions as realistic errors and prompt a teacher VLM to generate corrective reasoning traces, yielding supervised data without human annotation; second, we apply Group Relative Policy Optimization (GRPO) with a simple IoU reward to stabilize multi-step refinement. On a mixed benchmark spanning RefCOCOg, Ref-Adv, and Ref-L4 (505 test samples), SFT warm-up with IVT surpasses the single-shot base model on every metric: Acc@0.5 rises to 82.0% (+2.4pp), Acc@0.7 to 74.1% (+3.2pp), and Acc@0.9 to 48.3% (+2.8pp). GRPO further reduces per-step IoU degradation by 5x, stabilizing the refinement trajectory. All training uses only 2,400 samples on a single GPU, demonstrating that spatial self-correction is a learnable capability that can be instilled at modest scale.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that VLMs exhibit strong single-shot spatial grounding but fail at self-correction, as naive iterative prompting on rendered predictions causes catastrophic collapse (Acc@0.5 drops 31pp from 79.6% to 48.7%). It introduces Iterative Visual Thinking (IVT), a closed-loop framework where the model predicts a box, observes the rendered visualization, and refines iteratively. A two-phase recipe addresses the gap: (1) SFT on corrective reasoning traces generated by a teacher VLM from the base model's own (imperfect) predictions, requiring no human annotation; (2) GRPO with a simple IoU reward to stabilize multi-step trajectories. On a 505-sample mixed benchmark (RefCOCOg + Ref-Adv + Ref-L4), SFT+IVT improves over the base single-shot model (Acc@0.5 to 82.0% (+2.4pp), Acc@0.7 to 74.1% (+3.2pp), Acc@0.9 to 48.3% (+2.8pp)), while GRPO reduces per-step IoU degradation by 5x. All training uses 2400 samples on one GPU.
Significance. If the results hold under scrutiny, the work is significant for establishing that spatial self-correction is a learnable capability that can be instilled in VLMs at modest scale without human-annotated corrective data. The explicit quantification of the naive-iteration failure mode, the use of the model's own errors to bootstrap SFT data, and the stabilization effect of GRPO constitute concrete, falsifiable contributions. The single-GPU, 2400-sample regime is a notable strength supporting reproducibility and accessibility.
major comments (2)
- [Abstract] The SFT phase constructs its training signal by prompting a teacher VLM to generate corrective reasoning traces from the base model's predictions, yet no quality validation (human ratings, consistency metrics, or ablation isolating trace quality) is reported. This is load-bearing for the central claim that annotation-free SFT yields reliable gains, as unverified trace errors or hallucinations could render the +2.4pp Acc@0.5 improvement spurious (Abstract and the SFT data construction description).
- [Evaluation] The evaluation reports improvements on a mixed benchmark of only 505 test samples with no error bars, variance estimates, or statistical significance tests for the metric deltas (+2.4pp Acc@0.5, +3.2pp Acc@0.7, +2.8pp Acc@0.9). This undermines confidence that the gains over the single-shot base model are robust rather than noise (results on the 505-sample benchmark).
minor comments (2)
- The exact composition of the 505-sample test set (sample counts per constituent benchmark) is not broken down, which would aid interpretation of the mixed-benchmark results.
- The GRPO reward formulation and per-step IoU degradation metric could be stated more explicitly with equations to facilitate replication.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for validation of the SFT traces and greater statistical rigor in evaluation. We address each major comment below and will revise the manuscript accordingly to strengthen these aspects.
read point-by-point responses
-
Referee: [Abstract] The SFT phase constructs its training signal by prompting a teacher VLM to generate corrective reasoning traces from the base model's predictions, yet no quality validation (human ratings, consistency metrics, or ablation isolating trace quality) is reported. This is load-bearing for the central claim that annotation-free SFT yields reliable gains, as unverified trace errors or hallucinations could render the +2.4pp Acc@0.5 improvement spurious (Abstract and the SFT data construction description).
Authors: We agree that explicit validation of the teacher-generated corrective traces would provide stronger support for the annotation-free SFT claim. While the consistent gains across multiple metrics and benchmarks offer indirect evidence that the traces are effective, we will add an appendix with trace quality analysis, including inter-prompt consistency metrics on a sample of traces and a small human rating study on correctness of a subset. This will be incorporated in the revised version. revision: yes
-
Referee: [Evaluation] The evaluation reports improvements on a mixed benchmark of only 505 test samples with no error bars, variance estimates, or statistical significance tests for the metric deltas (+2.4pp Acc@0.5, +3.2pp Acc@0.7, +2.8pp Acc@0.9). This undermines confidence that the gains over the single-shot base model are robust rather than noise (results on the 505-sample benchmark).
Authors: We acknowledge that reporting variance and statistical tests is important for small test sets. In the revision, we will add bootstrap-derived confidence intervals and variance estimates for all reported metrics, along with appropriate significance testing for the deltas relative to the single-shot baseline. This will be included in the results section and tables. revision: yes
Circularity Check
No circularity; empirical results on external benchmarks
full rationale
The paper reports standard supervised fine-tuning followed by RL on 2400 training samples, with performance measured on a separate 505-sample test mix drawn from RefCOCOg, Ref-Adv and Ref-L4. All headline numbers (Acc@0.5 = 82.0 %, etc.) are direct comparisons against the base model's single-shot outputs on the same held-out data; none are obtained by re-using fitted parameters, re-labeling the training signal, or invoking self-citations as uniqueness theorems. The teacher-trace generation step is an unverified modeling choice but does not mathematically force the reported test-set deltas.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The base VLM possesses sufficient initial grounding capability to generate realistic errors that can be used to create supervised corrective data.
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-VL technical report.arXiv preprint arXiv:2511.21631, 2025. 1, 2, 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
arXiv preprint arXiv:2505.14231 , year=
SuleBai, MingxingLi, YongLiu, JingTang, HaojiZhang, Lei Sun, Xiangxiang Chu, and Yansong Tang. UniVG- R1: Reasoning guided universal visual grounding with reinforcement learning.arXiv preprint arXiv:2505.14231,
-
[3]
Ground-R1: Incentiviz- ing grounded visual reasoning via reinforcement learning
Meng Cao, Haoze Zhao, Can Zhang, Xiaojun Chang, Ian Reid, and Xiaodan Liang. Ground-R1: Incentiviz- ing grounded visual reasoning via reinforcement learning. arXiv preprint arXiv:2505.20272, 2025. 3
-
[4]
Gary Chan, and Hongyang Zhang
Jierun Chen, Fangyun Wei, Jinjing Zhao, Sizhe Song, Bohuai Wu, Zhuoxuan Peng, S.-H. Gary Chan, and Hongyang Zhang. Revisiting Referring Expression Com- prehension Evaluation in the Era of Large Multimodal Models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 513– 524, 2025. 2, 6
2025
-
[5]
Shikra: Unleashing Multimodal LLM's Referential Dialogue Magic
Keqin Chen, Zhao Zhang, Weili Zeng, Richong Zhang, Feng Zhu, and Rui Zhao. Shikra: Unleashing multi- modal LLM’s referential dialogue magic.arXiv preprint arXiv:2306.15195, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Yang Chen, Yufan Shen, Wenxuan Huang, Sheng Zhou, Qunshu Lin, Xinyu Cai, Zhi Yu, Jiajun Bu, Botian Shi, and Yu Qiao. Learning only with images: Visual rein- forcement learning with reasoning, rendering, and visual feedback.arXiv preprint arXiv:2507.20766, 2025. 3
-
[7]
QLoRA: Efficient finetuning of quan- tized language models.Advances in Neural Information Processing Systems, 36, 2023
Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. QLoRA: Efficient finetuning of quan- tized language models.Advances in Neural Information Processing Systems, 36, 2023. 2, 6
2023
-
[8]
Ref-adv: Exploring MLLM visual reasoning in refer- ring expression tasks
Qihua Dong, Kuo Yang, Lin Ju, Handong Zhao, Yitian Zhang, YizhouWang, HuiminZeng, JianglinLu, andYun Fu. Ref-adv: Exploring MLLM visual reasoning in refer- ring expression tasks. InThe Fourteenth International Conference on Learning Representations, 2026. 2, 5
2026
-
[9]
GRIT: Teaching MLLMs to think with images
Yue Fan, Xuehai He, Diji Yang, Kaizhi Zheng, Ching- Chen Kuo, Yuting Zheng, Sravana Jyothi Narayanaraju, Xinze Guan, and Xin Eric Wang. GRIT: Teaching MLLMs to think with images. InNeurIPS, 2025. 3
2025
-
[10]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, He Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025. 1, 2, 3, 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
LoRA: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Sheng Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. InICLR, 2022. 2, 6
2022
-
[12]
Large language models cannot self-correct reasoning yet
Jie Huang, Xinyun Chen, Swaroop Mishra, Huaixiu Steven Zheng, Adams Wei Yu, Xinying Song, and Denny Zhou. Large language models cannot self-correct reasoning yet. InICLR, 2024. 1, 2
2024
-
[13]
Vision-R1: Incentivizing reasoning capabil- ity in multimodal large language models
Wenxuan Huang, Bohan Jia, Zijie Zhai, Shaosheng Cao, Zheyu Ye, Fei Zhao, Zhe Xu, Xu Tang, Yao Hu, and Shaohui Lin. Vision-R1: Incentivizing reasoning capabil- ity in multimodal large language models. InICLR, 2026. 3
2026
-
[14]
MDETR – modulated detection for end-to-end multi-modal under- standing
Aishwarya Kamath, Mannat Singh, Yann LeCun, Gabriel Synnaeve, Ishan Misra, and Nicolas Carion. MDETR – modulated detection for end-to-end multi-modal under- standing. InICCV, 2021. 2 8
2021
-
[15]
Can large vision-language models correct semantic grounding errors by themselves? InCVPR,
Yuan-Hong Liao, Rafid Mahmood, Sanja Fidler, and David Acuna. Can large vision-language models correct semantic grounding errors by themselves? InCVPR,
-
[16]
Microsoft COCO: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft COCO: Common objects in context. InECCV, 2014. 5
2014
-
[17]
Grounding DINO: Marrying DINO with grounded pre-training for open-set object detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, et al. Grounding DINO: Marrying DINO with grounded pre-training for open-set object detection. In ECCV, 2024. 2
2024
-
[18]
Self- refine: Iterative refinement with self-feedback.Advances in Neural Information Processing Systems, 36, 2023
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, et al. Self- refine: Iterative refinement with self-feedback.Advances in Neural Information Processing Systems, 36, 2023. 2
2023
-
[19]
Generation and comprehension of unambiguous object descriptions
Junhua Mao, Jonathan Huang, Alexander Toshev, Oana Camburu, Alan Yuille, and Kevin Murphy. Generation and comprehension of unambiguous object descriptions. InCVPR, 2016. 2, 5
2016
-
[20]
Training language models to follow instructions with hu- man feedback.Advances in Neural Information Process- ing Systems, 35:27730–27744, 2022
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with hu- man feedback.Advances in Neural Information Process- ing Systems, 35:27730–27744, 2022. 3
2022
-
[21]
Grounding multimodal large language models to the world
Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shao- han Huang, Shuming Ma, Qixiang Ye, and Furu Wei. Grounding multimodal large language models to the world. InICLR, 2024. 2
2024
-
[22]
CogCoM: A visual language model with chain-of-manipulations reasoning
Ji Qi, Ming Ding, Weihan Wang, Yushi Bai, Qingsong Lv, Wenyi Hong, Bin Xu, Lei Hou, Juanzi Li, Yuxiao Dong, and Jie Tang. CogCoM: A visual language model with chain-of-manipulations reasoning. InICLR, 2025. 2
2025
-
[23]
Grounded Reinforcement Learning for Visual Reasoning
Gabriel Sarch, Snigdha Saha, Naitik Khandelwal, Ayush Jain, Michael J. Tarr, Aviral Kumar, and Katerina Fragkiadaki. Grounded reinforcement learning for visual reasoning.arXiv preprint arXiv:2505.23678, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Ob- jects365: A large-scale, high-quality dataset for object detection
Shuai Shao, Zeming Li, Tianyuan Zhang, Chao Peng, Gang Yu, Xiangyu Zhang, Jing Li, and Jian Sun. Ob- jects365: A large-scale, high-quality dataset for object detection. InICCV, 2019. 6
2019
-
[25]
ZhihongShao, PeiyiWang, QihaoZhu, RunxinXu, Junx- iao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y.K. Li, Y. Wu, and Daya Guo. DeepSeekMath: Push- ing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024. 2, 3, 4
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
VLM-R1: A Stable and Generalizable R1-style Large Vision-Language Model
Haozhan Shen, Peng Liu, Jingcheng Li, Chunxin Fang, Yibo Ma, Jiajia Liao, Qiaoli Shen, Zilun Zhang, Kangjia Zhao, Qianqian Zhang, Ruochen Xu, and Tiancheng Zhao. VLM-R1: A stable and generalizable R1-style large vision-language model.arXiv preprint arXiv:2504.07615,
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Reflexion: Lan- guage agents with verbal reinforcement learning.Ad- vances in Neural Information Processing Systems, 36,
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Lan- guage agents with verbal reinforcement learning.Ad- vances in Neural Information Processing Systems, 36,
-
[28]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-VL: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
Chain-of-thought prompting elicits reason- ing in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc V Le, and Denny Zhou. Chain-of-thought prompting elicits reason- ing in large language models. InNeurIPS, 2022. 3
2022
-
[30]
Visual planning: Let’s think only with images
Yi Xu, Chengzu Li, Han Zhou, Xingchen Wan, Caiqi Zhang, Anna Korhonen, and Ivan Vulić. Visual planning: Let’s think only with images. InICLR, 2026. 3
2026
-
[31]
Ferret: Refer and ground any- thing anywhere at any granularity
Haoxuan You, Haotian Zhang, Zhe Gan, Xianzhi Du, Bowen Zhang, Zirui Wang, Liangliang Cao, Shih-Fu Chang, and Yinfei Yang. Ferret: Refer and ground any- thing anywhere at any granularity. InICLR, 2024. 1, 2
2024
-
[32]
Critic-V: VLM critics help catch VLM errors in multimodal reasoning
Di Zhang, Jingdi Lei, Junxian Li, Xunzhi Wang, Yujie Liu, Zonglin Yang, Jiatong Li, Weida Wang, Suorong Yang, Jianbo Wu, Peng Ye, Wanli Ouyang, and Dongzhan Zhou. Critic-V: VLM critics help catch VLM errors in multimodal reasoning. InCVPR, 2025. 2
2025
-
[33]
R1-VL: Learning to reason with multimodal large language mod- els via step-wise group relative policy optimization
Jingyi Zhang, Jiaxing Huang, Huanjin Yao, Shunyu Liu, Xikun Zhang, Shijian Lu, and Dacheng Tao. R1-VL: Learning to reason with multimodal large language mod- els via step-wise group relative policy optimization. In ICCV, 2025. 3 9
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.