GitOfThoughts: Version-Controlled Reasoning and Agent Memory You Can Replay, Diff, and Merge
Pith reviewed 2026-06-27 04:46 UTC · model grok-4.3
The pith
Memory from past problems boosts agent accuracy only when new problems closely match stored examples, while git storage adds auditability without changing results.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
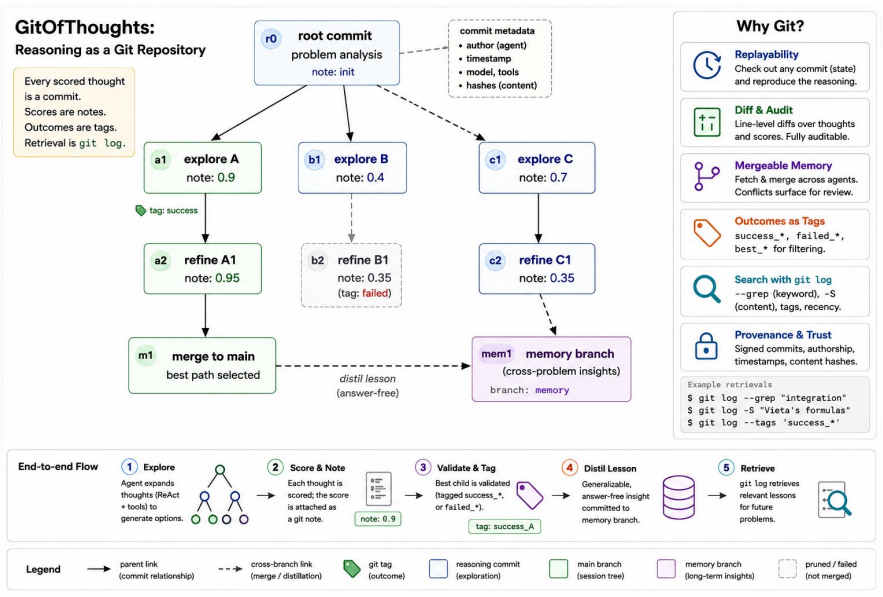
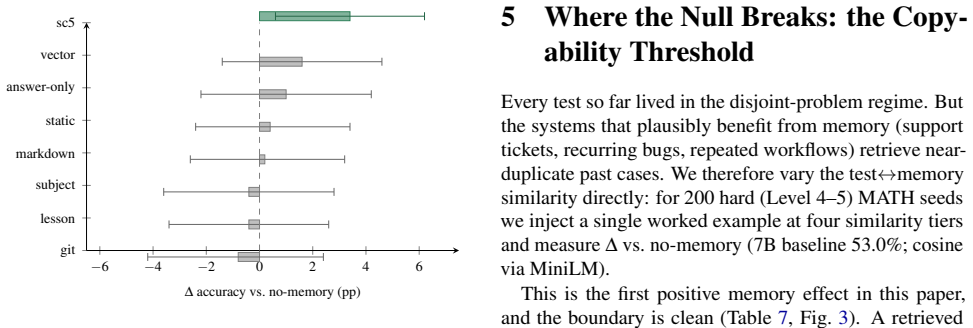
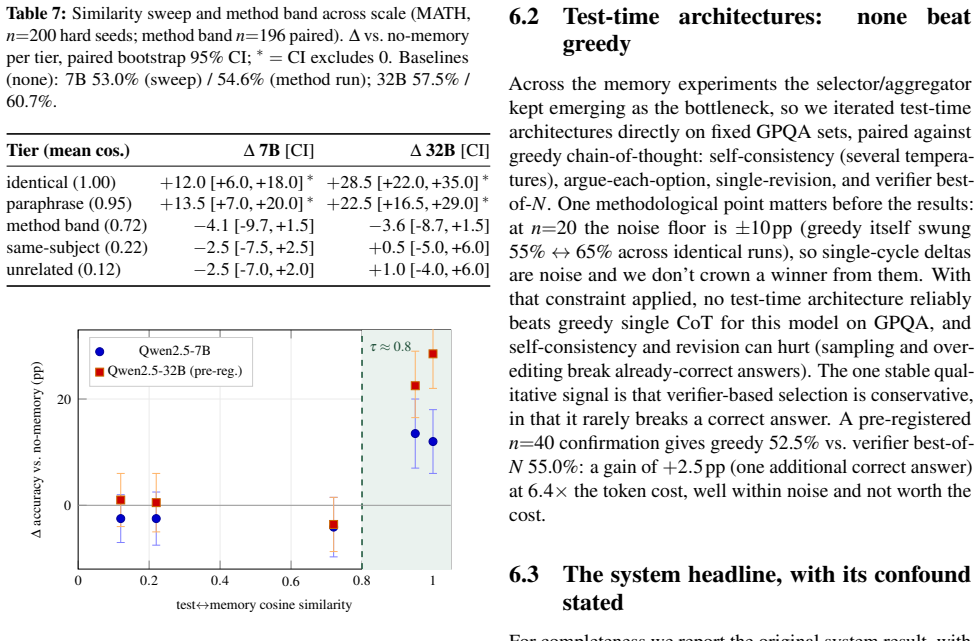
GitOfThoughts represents an agent's reasoning tree as a git repository in which each scored thought is a commit, outcomes are tags, and retrieval reduces to git log over the agent's own history. Across two benchmarks, two model sizes, and repeated trials, none of the five memory stores (including the git version) improved accuracy on new problems unless those problems were nearly identical to stored ones; even a 4.5-times-larger model extracted no reusable methods, only better near-copy detection. The sole consistent gain on novel problems came from self-consistency sampling.
What carries the argument
Git repository as memory store for reasoning trees, turning thoughts into commits and enabling standard version-control operations on the agent's history.
If this is right
- Self-consistency sampling improves accuracy on new problems while memory retrieval does not.
- Even substantially larger models still cannot derive reusable methods from dissimilar examples.
- All five memory stores produce statistically equivalent accuracy on dissimilar problems.
- Git storage supplies replay, diff, and merge capabilities without reducing accuracy relative to other stores.
Where Pith is reading between the lines
- Current models appear to solve reasoning tasks by surface matching rather than by internalizing general procedures.
- Version-controlled reasoning histories could support merging or auditing across multiple independent agents.
- Efforts to improve reasoning might shift from retrieval augmentation toward techniques that force extraction of methods across low-similarity cases.
Load-bearing premise
The benchmarks contain enough genuinely novel problems that are not near-duplicates of the stored memory, and the five memory implementations differ only in storage mechanism.
What would settle it
An experiment in which a model extracts and correctly applies a reasoning method from a worked example whose cosine similarity to the target problem is below 0.8.
Figures
read the original abstract
Large language model reasoning leaves no trace once it is done. The steps of a chain of thought disappear when the context window closes, a pruned search branch is just gone, and memory buffers cannot be diffed, merged, or audited. Code, infrastructure, and experiments are all version-controlled. Reasoning is not. GitOfThoughts stores an agent's reasoning tree as a git repository. Every scored thought becomes a commit, scores become notes, outcomes become tags, and retrieval is just git log over the agent's own history. We use this to test something simple. Does giving an agent memory from past problems actually make it more accurate? We tried five memory stores (none, a markdown file, a vector database, a graph, and git) across two benchmarks, two model sizes, and several pre-registered repeat experiments. The answer, on new problems, is no, including one promising early result that did not hold up when we repeated it. Memory only helps once the problem being solved is nearly identical to something already in memory (cosine similarity above about 0.8); below that, it does nothing. In other words, the model is finding the answer rather than learning the method. Even a model 4.5x larger still cannot pull a reusable method out of a worked example; it just gets better at spotting near-copies. The only thing that reliably helped on new problems was generating several answers and picking the most common one (self-consistency). So the case for using git as the memory store is not that it retrieves better. It is that it gives auditability, history, and the ability to merge two agents' memories, at no cost to accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GitOfThoughts, which represents an LLM agent's reasoning tree as a git repository so that thoughts become commits, scores become notes, and retrieval reduces to git log. It reports experiments across five memory stores (none, markdown, vector DB, graph, git), two benchmarks, two model sizes, and pre-registered repeats, finding that memory improves accuracy only when test problems have cosine similarity >0.8 to stored items; below that threshold memory confers no benefit, even for a 4.5 imes larger model. Self-consistency is the only intervention that reliably helps on novel problems. The authors conclude that models locate near-copies rather than extract reusable methods and that git's value is auditability and mergeability rather than retrieval performance.
Significance. If the empirical pattern holds, the result challenges the widespread assumption that retrieved memory improves reasoning on out-of-distribution problems and supplies concrete evidence that current LLMs do not reliably abstract methods from single worked examples. The pre-registered multi-condition design and explicit comparison of storage back-ends constitute a methodological strength that grounds the negative finding about memory transfer.
major comments (3)
- [Methods] Methods section: the claim that the five memory stores differ only in storage/retrieval backend requires explicit confirmation that prompting templates, top-k selection logic, context-injection format, and scoring procedures were held identical; without this, any divergence confounds the central result that memory confers no benefit below cosine 0.8.
- [Results] Results on similarity threshold: the 0.8 cosine cutoff is reported without naming the embedding model, the precise similarity formula, or verification that held-out problems contain no methodologically analogous but surface-dissimilar items; this detail is load-bearing for the interpretation that models extract no reusable methods.
- [Abstract] Abstract and experimental reporting: pre-registered repeats are mentioned, yet the manuscript supplies neither full methods, raw data, error bars, nor implementation artifacts; this absence prevents independent verification of the non-replicating early result and of the equivalence assumption.
minor comments (2)
- [Figures] Figure captions should state the exact embedding model and similarity metric used for the cosine analysis.
- [Tables] Notation for the five memory conditions is introduced inconsistently between text and tables; standardize the labels.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major comment below and indicate planned revisions to improve clarity and verifiability.
read point-by-point responses
-
Referee: [Methods] Methods section: the claim that the five memory stores differ only in storage/retrieval backend requires explicit confirmation that prompting templates, top-k selection logic, context-injection format, and scoring procedures were held identical; without this, any divergence confounds the central result that memory confers no benefit below cosine 0.8.
Authors: The experimental protocol held all elements other than the storage/retrieval backend constant: identical prompting templates, top-k=5 selection, context-injection format, and scoring procedures were used across conditions. We will insert an explicit confirmation paragraph in the Methods section documenting these controls. revision: yes
-
Referee: [Results] Results on similarity threshold: the 0.8 cosine cutoff is reported without naming the embedding model, the precise similarity formula, or verification that held-out problems contain no methodologically analogous but surface-dissimilar items; this detail is load-bearing for the interpretation that models extract no reusable methods.
Authors: We will name the embedding model (sentence-transformers/all-MiniLM-L6-v2), state that cosine similarity was computed on L2-normalized vectors, and add a note on manual verification that held-out problems contained no methodologically analogous but lexically dissimilar items. These details will be placed in the Results section. revision: yes
-
Referee: [Abstract] Abstract and experimental reporting: pre-registered repeats are mentioned, yet the manuscript supplies neither full methods, raw data, error bars, nor implementation artifacts; this absence prevents independent verification of the non-replicating early result and of the equivalence assumption.
Authors: We will expand the Methods section with additional pre-registration and procedural details and add error bars to all figures. The full code, prompts, and datasets will be released in a public repository upon acceptance to support verification; the current manuscript length constraints limit inclusion of raw data tables. revision: partial
Circularity Check
No circularity: purely empirical benchmark comparison with no derivations or self-referential reductions
full rationale
The paper presents an empirical study comparing five memory-store implementations (none, markdown, vector DB, graph, git) on two benchmarks across model sizes and pre-registered repeats. The central finding—that memory improves accuracy only for cosine similarity >0.8 and otherwise provides no benefit—is reported as a direct observation from the experiments, not derived from any equations, fitted parameters renamed as predictions, or self-citation chains. No mathematical derivation chain exists; the work contains no first-principles results, uniqueness theorems, or ansatzes that could reduce to inputs by construction. The assumptions flagged in the skeptic note (equivalence of stores and novelty of test problems) are methodological limitations but do not constitute circularity under the defined patterns, as there is no load-bearing step that equates a claimed result to its own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM reasoning steps can be generated, scored, and stored as discrete commits without altering core model behavior.
invented entities (1)
-
GitOfThoughts memory store
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. Mem0: Building production-ready AI agents with scalable long-term memory. arXiv:2504.19413, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Improving Factuality and Reasoning in Language Models through Multiagent Debate
Yilun Du, Shuang Li, Antonio Torralba, Joshua B. Tenen- baum, and Igor Mordatch. Improving factuality and rea- soning in language models through multiagent debate. arXiv:2305.14325, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Reasoning with language model is planning with world model
Shibo Hao, Yi Gu, Haodi Ma, Joshua Jiahua Hong, Zhen Wang, Daisy Zhe Wang, and Zhiting Hu. Reasoning with language model is planning with world model. InProceed- ings of EMNLP, 2023
2023
-
[4]
Hatchet: A distributed, durable task queue (soft- ware)
Hatchet. Hatchet: A distributed, durable task queue (soft- ware). https://github.com/hatchet-dev/hatchet, 2024
2024
-
[5]
Measuring mathematical problem solving with the MATH dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the MATH dataset. InNeurIPS Datasets and Benchmarks, 2021
2021
-
[6]
ReTreVal: Reasoning Tree with Validation and Cross-Problem Memory for Large Language Models
Abhishek HS, Pavan C. Shekar, Arpit Jain, and Aswanth Krishnan. ReTreVal: Reasoning tree with validation – a hybrid framework for enhanced LLM multi-step reasoning. arXiv:2601.02880, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[7]
Efficient memory management for large language model serving with PagedAttention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao 9 Zhang, and Ion Stoica. Efficient memory management for large language model serving with PagedAttention. InPro- ceedings of SOSP, 2023
2023
-
[8]
SwiftSage: A generative agent with fast and slow thinking for complex interactive tasks
Bill Yuchen Lin, Yicheng Fu, Karina Yang, Faeze Brah- man, Shiyu Huang, Chandra Bhagavatula, Prithviraj Am- manabrolu, Yejin Choi, and Xiang Ren. SwiftSage: A generative agent with fast and slow thinking for complex interactive tasks. InNeurIPS, 2023
2023
-
[9]
Self-refine: Iterative refinement with self-feedback
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Shashank Gupta, Bodhisattwa Prasad Majumder, Katherine Hermann, Sean Welleck, Amir Yazdanbakhsh, and Peter Clark. Self-refine: Iterative refinement with self-feedback. InNeurIPS, 2023
2023
-
[10]
CLIN: A continually learn- ing language agent for rapid task adaptation and generaliza- tion
Bodhisattwa Prasad Majumder, Bhavana Dalvi Mishra, Pe- ter Jansen, Oyvind Tafjord, Niket Tandon, Li Zhang, Chris Callison-Burch, and Peter Clark. CLIN: A continually learn- ing language agent for rapid task adaptation and generaliza- tion. arXiv:2310.10134, 2023
-
[11]
Re- thinking the role of demonstrations: What makes in-context learning work? InProceedings of EMNLP, 2022
Sewon Min, Xinxi Lyu, Ari Holtzman, Mikel Artetxe, Mike Lewis, Hannaneh Hajishirzi, and Luke Zettlemoyer. Re- thinking the role of demonstrations: What makes in-context learning work? InProceedings of EMNLP, 2022
2022
-
[12]
MemGPT: Towards LLMs as Operating Systems
Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonza- lez. MemGPT: Towards LLMs as operating systems. arXiv:2310.08560, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
O’Brien, Carrie J
Joon Sung Park, Joseph C. O’Brien, Carrie J. Cai, Mered- ith Ringel Morris, Percy Liang, and Michael S. Bernstein. Generative agents: Interactive simulacra of human behavior. InProceedings of UIST, 2023
2023
-
[14]
Sentence-BERT: Sen- tence embeddings using siamese BERT-networks
Nils Reimers and Iryna Gurevych. Sentence-BERT: Sen- tence embeddings using siamese BERT-networks. InPro- ceedings of EMNLP, 2019
2019
-
[15]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. GPQA: A graduate-level google- proof Q&A benchmark. arXiv:2311.12022, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
Reflexion: Language agents with verbal reinforcement learning
Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning. In NeurIPS, 2023
2023
-
[17]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling LLM test-time compute optimally can be more ef- fective than scaling model parameters. arXiv:2408.03314, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandku- mar. V oyager: An open-ended embodied agent with large language models. arXiv:2305.16291, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
ScienceWorld: Is your agent smarter than a 5th grader? InProceedings of EMNLP, 2022
Ruoyao Wang, Peter Jansen, Marc-Alexandre Côté, and Prithviraj Ammanabrolu. ScienceWorld: Is your agent smarter than a 5th grader? InProceedings of EMNLP, 2022
2022
-
[20]
Self-consistency improves chain of thought reasoning in language models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. InICLR, 2023
2023
-
[21]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. InNeurIPS, 2022
2022
-
[22]
A-MEM: Agentic Memory for LLM Agents
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang. A-MEM: Agentic memory for LLM agents. arXiv:2502.12110, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
An Yang, Baosong Yang, Beichen Zhang, et al. Qwen2.5 technical report. arXiv:2412.15115, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Griffiths, Yuan Cao, and Karthik Narasimhan
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models. InNeurIPS, 2023
2023
-
[25]
ReAct: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. ReAct: Synergizing reasoning and acting in language models. InICLR, 2023
2023
-
[26]
TextGrad: Automatic "Differentiation" via Text
Mert Yuksekgonul, Federico Bianchi, Joseph Boen, Sheng Liu, Zhi Huang, Carlos Guestrin, and James Zou. TextGrad: Automatic “differentiation” via text. arXiv:2406.07496, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Accelerating the machine learning lifecycle with MLflow.IEEE Data Engineering Bulletin, 41(4), 2018
Matei Zaharia, Andrew Chen, Aaron Davidson, Ali Gh- odsi, Sue Ann Hong, Andy Konwinski, Siddharth Murching, Tomas Nykodym, Paul Ogilvie, Mani Parkhe, Fen Xie, and Corey Zumar. Accelerating the machine learning lifecycle with MLflow.IEEE Data Engineering Bulletin, 41(4), 2018
2018
-
[28]
ExpeL: LLM agents are experiential learners
Andrew Zhao, Daniel Huang, Quentin Xu, Matthieu Lin, Yong-Jin Liu, and Gao Huang. ExpeL: LLM agents are experiential learners. InProceedings of AAAI, 2024
2024
-
[29]
MemoryBank: Enhancing large language models with long-term memory
Wanjun Zhong, Lianghong Guo, Qiqi Gao, He Ye, and Yanlin Wang. MemoryBank: Enhancing large language models with long-term memory. InProceedings of AAAI, 2024
2024
-
[30]
Language agent tree search unifies reasoning, acting, and planning in language models
Andy Zhou, Kai Yan, Michal Shlapentokh-Rothman, Hao- han Wang, and Yu-Xiong Wang. Language agent tree search unifies reasoning, acting, and planning in language models. InICML, 2024. 10
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.