Visuals Lie, Consistency Speaks: Disentangling Spatial Attention from Reliability in Vision-Language Models
Pith reviewed 2026-06-27 02:19 UTC · model grok-4.3
The pith
Spatial attention in vision-language models shows near-zero correlation with accuracy while self-consistency across reasoning paths predicts truth much better.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
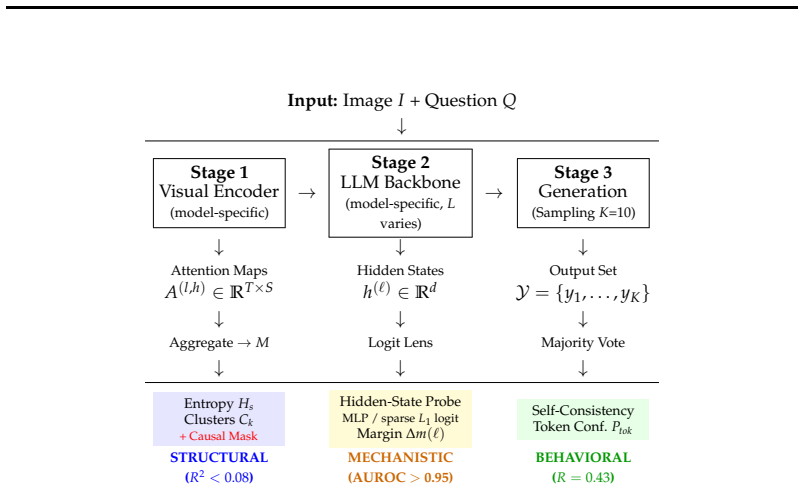
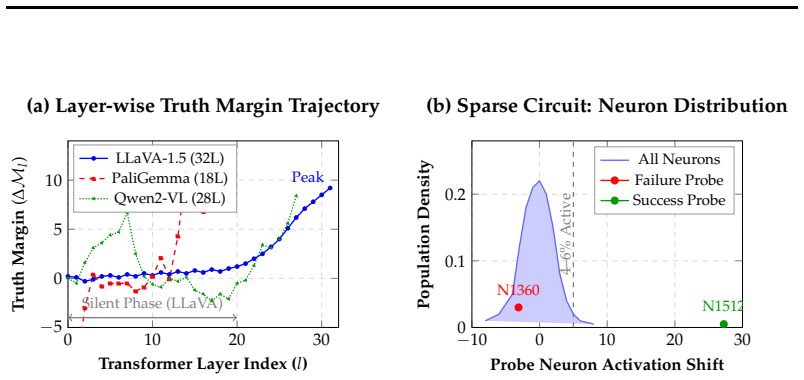
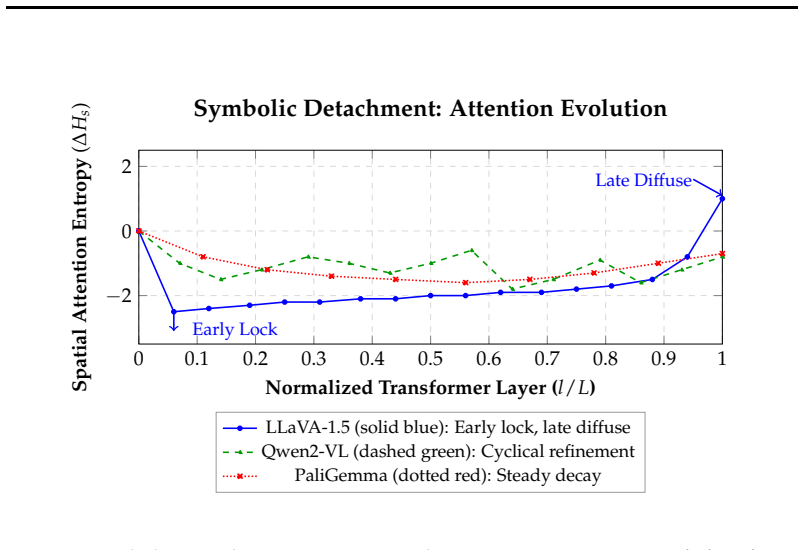
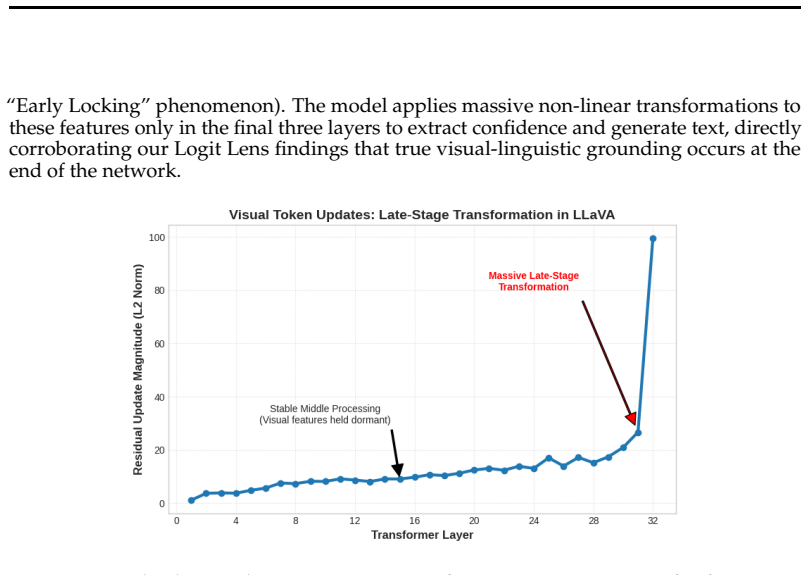
The paper claims that the Attention-Confidence Assumption does not hold. Spatial attention metrics such as cluster counts and spatial entropy correlate near zero with accuracy. Self-consistency, measured as the agreement rate across sampled reasoning paths, emerges as the strongest predictor of truth. Models exhibit symbolic detachment in which visual features are locked early but attention diffuses in later layers. Architectural differences appear when causal interventions destroy predictive layers: some models remain resilient while others collapse.
What carries the argument
The VLM Reliability Probe that quantifies visual encoder gaze via cluster counts C_k and spatial entropy H_s, then contrasts those metrics against self-consistency measured across multiple generation paths.
If this is right
- Models often early-lock visual features only to diffuse attention in later layers, severing perception from final output.
- LLaVA predictions depend on a fragile late-stage bottleneck while PaliGemma and Qwen2-VL keep reliability distributed across many layers.
- Destroying the most predictive layer leaves some models resilient even after fifty percent or more of that layer is removed.
- Generation-time dynamics and hidden-state distributions supply the main signals for estimating answer reliability.
- Attention maps from the visual encoder are not useful for deciding when to trust a VLM output.
Where Pith is reading between the lines
- Sampling several reasoning paths at inference time could serve as a lightweight reliability check without any attention visualization.
- Architectures that keep reliability distributed across layers may be preferable when robustness to internal disruption is required.
- Hidden-state consistency probes could be added as standard monitoring tools for deployed vision-language systems.
- The observed detachment between early visual processing and later generation suggests that reliability methods should focus on the language decoder rather than the vision encoder.
Load-bearing premise
The structural-attention metrics and their evolution across layers correctly measure the kind of visual perception that should indicate reliability under the Attention-Confidence Assumption.
What would settle it
A study that measures spatial attention cluster and entropy metrics on a wide range of VLMs and tasks and finds a strong positive correlation with accuracy would falsify the cluster failure result.
Figures

read the original abstract
Multimodal Foundation Models are increasingly used as reasoning agents, making reliability, knowing when a model may hallucinate, critical. A common intuition, which we call the Attention-Confidence Assumption, holds that reliability follows from "structural" visual perception: tight attention on relevant regions should signal a trustworthy answer, while scattered attention signals confusion. We challenge this through the VLM Reliability Probe (VRP), a systematic cross-family study of reliability signals in contemporary Vision-Language Models (VLMs). We introduce structural-attention metrics, cluster counts (C_k) and spatial entropy (H_s), to quantify the visual encoder's gaze, and track its evolution (Delta H_s) across layers. This reveals a "Symbolic Detachment": models often "Early Lock" visual features only to diffuse attention later, severing early perception from final generation. Contrary to the grounding hypothesis, we find a "Cluster Failure": spatial attention has near-zero correlation (R approx 0.001) with accuracy. Instead, reliability is a phenomenon of generation dynamics and internal-state distributions. Self-Consistency, the agreement rate across sampled reasoning paths, is the dominant predictor of truth (R = 0.429). Scaling causal interventions exposes a sharp architectural divergence: LLaVA locks its prediction in a fragile late-stage bottleneck, whereas PaliGemma and Qwen2-VL distribute reliability globally, staying resilient even when ~50% or more of their most predictive layer is destroyed. For current VLMs, reliability signals are detached from visual grounding maps and are best inferred from generation-time dynamics and hidden-state probes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that the Attention-Confidence Assumption is false for contemporary VLMs: structural-attention metrics (cluster counts C_k and spatial entropy H_s, plus their layer-wise evolution ΔH_s) exhibit near-zero correlation (R ≈ 0.001) with answer accuracy ('Cluster Failure'), while self-consistency across sampled reasoning paths is a stronger predictor (R = 0.429). It introduces the VLM Reliability Probe (VRP) for cross-family analysis, documents 'Symbolic Detachment' and 'Early Lock' phenomena, and reports architectural divergences under causal interventions (LLaVA shows a fragile late-stage bottleneck; PaliGemma and Qwen2-VL remain resilient after destroying ~50% of predictive layers).
Significance. If the central empirical findings hold after addressing metric validity, the work would provide a useful empirical counter-example to the grounding hypothesis and shift attention toward generation-time dynamics and hidden-state probes for reliability estimation. The cross-model causal interventions and the reported R values for self-consistency constitute concrete, falsifiable observations that could inform downstream evaluation protocols.
major comments (2)
- The structural-attention metrics are defined solely in terms of dispersion (C_k and H_s) with no term for overlap with ground-truth entities, saliency maps, or question-mentioned objects. Consequently the reported R ≈ 0.001 tests dispersion alone and does not falsify the Attention-Confidence Assumption, which requires attention on relevant regions (see the skeptic note on the weakest assumption and the definition of the metrics in the VRP section).
- The manuscript provides no details on dataset size, statistical controls, exact sampling procedure for self-consistency, or safeguards against post-hoc model selection. These omissions are load-bearing for the strength of the 'Cluster Failure' and R = 0.429 claims (reader's soundness assessment).
Simulated Author's Rebuttal
We thank the referee for these constructive comments, which help clarify the scope of our claims. We respond point-by-point below and will revise the manuscript to strengthen the presentation of our metrics and experimental details.
read point-by-point responses
-
Referee: The structural-attention metrics are defined solely in terms of dispersion (C_k and H_s) with no term for overlap with ground-truth entities, saliency maps, or question-mentioned objects. Consequently the reported R ≈ 0.001 tests dispersion alone and does not falsify the Attention-Confidence Assumption, which requires attention on relevant regions (see the skeptic note on the weakest assumption and the definition of the metrics in the VRP section).
Authors: We interpret the Attention-Confidence Assumption as including the structural claim that low-dispersion attention patterns (few clusters, low entropy) should correlate with reliability. Our metrics directly quantify this structural property, and the near-zero correlation demonstrates that dispersion alone is not predictive. We acknowledge, however, that an explicit overlap term with relevant regions would provide a more complete test of the full assumption. In revision we will add overlap-based variants of C_k and H_s (computed against question-mentioned objects and available saliency maps) to the VRP analysis, allowing readers to compare dispersion-only versus relevance-aware results. revision: partial
-
Referee: The manuscript provides no details on dataset size, statistical controls, exact sampling procedure for self-consistency, or safeguards against post-hoc model selection. These omissions are load-bearing for the strength of the 'Cluster Failure' and R = 0.429 claims (reader's soundness assessment).
Authors: We agree that these experimental details are necessary for assessing the robustness of the reported correlations. The revised manuscript will add a dedicated 'Experimental Setup' subsection that specifies: total sample counts per model and benchmark, statistical procedures (Pearson r with bootstrap confidence intervals and p-values), the precise self-consistency protocol (number of sampled paths, temperature, aggregation method), and safeguards (pre-specified metrics, held-out evaluation sets, no post-hoc metric selection). revision: yes
Circularity Check
No circularity: empirical correlations between defined metrics and accuracy
full rationale
The paper defines structural-attention metrics C_k and H_s explicitly, computes their correlations with accuracy on held-out data, and reports the resulting R values as observations. No derivation, equation, or self-citation reduces these reported correlations to the input definitions by construction; the central claim is a direct empirical measurement rather than a fitted or renamed quantity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The Attention-Confidence Assumption holds that reliability follows from structural visual perception via tight attention on relevant regions.
invented entities (2)
-
VLM Reliability Probe (VRP)
no independent evidence
-
structural-attention metrics (C_k, H_s, Delta H_s)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
PaliGemma: A versatile 3B VLM for transfer
Lucas Beyer, Andreas Steiner, Alejandro Pinto, et al. Paligemma: A versatile 3b vision- language model for transfer.arXiv preprint arXiv:2407.07726,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Chameleonbench: Quantifying alignment faking in large language models
9 Archie Chaudhury and Shikhar Shiromani. Chameleonbench: Quantifying alignment faking in large language models. InProceedings of Machine Learning Research (ACML 2025),
2025
-
[3]
MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models
Chaoyou Fu, Peixian Chen, Yunhang Shen, Yulei Qin, Mengdan Zhang, Xu Lin, Jinrui Yang, Xiawu Zheng, Ke Li, Xing Sun, Yunsheng Wu, Rongrong Ji, Caifeng Shan, and Ran He. Mme: A comprehensive evaluation benchmark for multimodal large language models. arXiv preprint arXiv:2306.13394,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
SEED-Bench: Benchmarking Multimodal LLMs with Generative Comprehension
Bohao Li, Rui Wang, Guangzhi Wang, Yuying Ge, Yixiao Ge, and Ying Shan. Seed- bench: Benchmarking multimodal llms with generative comprehension.arXiv preprint arXiv:2307.16125, 2023a. Junnan Li, Dongxu Li, Caiming Xiong, and Steven C. H. Hoi. Blip: Bootstrapping language- image pre-training for unified vision-language understanding and generation. InICML,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Yifan Liu, Zhen Chen, Rui Wang, and Wayne Xin Zhao. Seeing but not believing: Vision-language models can attend correctly yet reason incorrectly.arXiv preprint arXiv:2510.17771,
-
[6]
Lin Long, Changdae Oh, Seongheon Park, and Sharon Li. Understanding language prior of lvlms by contrasting chain-of-embedding.arXiv preprint arXiv:2509.23050,
-
[7]
The logit lens: Understanding hidden state dynamics in language models
Nostalgebraist. The logit lens: Understanding hidden state dynamics in language models. arXiv preprint arXiv:2012.08981,
-
[8]
Kenji Sahay, Snigdha Pandya, Rohan Nagale, Anna Lin, Shikhar Shiromani, Kevin Zhu, and Dev Sunishchal. Compass: Context-modulated pid attention steering system for hallucination mitigation.arXiv preprint arXiv:2511.14776,
-
[9]
Shikhar Shiromani, Archie Chaudhury, and Sri Pranav Kunda. The hypocrisy gap: Quan- tifying divergence between internal belief and chain-of-thought explanation via sparse autoencoders.arXiv preprint arXiv:2602.02496,
-
[10]
Rohan Subramanian Thomas, Shikhar Shiromani, Abdullah Chaudhry, Ruizhe Li, Vasu Sharma, Kevin Zhu, and Sunishchal Dev. Promoral-bench: Evaluating prompting strate- gies for moral reasoning and safety in llms.arXiv preprint arXiv:2602.13274,
-
[11]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Xue Li, et al. Qwen2-vl: Enhancing vision-language model perception of the world at any resolution.arXiv preprint arXiv:2409.12191,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning. arXiv preprint arXiv:2203.11171,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
MM-Vet: Evaluating Large Multimodal Models for Integrated Capabilities
Weihao Yu, Zhengyuan Yang, Linjie Li, Jianfeng Wang, Kevin Lin, Zicheng Liu, Xinchao Wang, and Lijuan Wang. Mm-vet: Evaluating large multimodal models for integrated capabilities.arXiv preprint arXiv:2308.02490,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Llava-bench: A benchmark for visual instruction following
Li Zhou, Wenhui Fu, Yujie Chen, Wei Liu, Zongjing Lin, Shuicheng Yan, and Weiyang Chen. Llava-bench: A benchmark for visual instruction following. InarXiv preprint arXiv:2308.13692,
-
[15]
(2023); Beyer et al
A Appendix A.1 Detailed Methodology and Metric Definitions A.2 Detailed Experimental Setup Models:We evaluate three VLM architectures: LLaVA-1.5-7B (32 layers, CLIP ViT-L/14 encoder), PaliGemma-3B (18 layers, SigLIP encoder), and Qwen2-VL-7B-Instruct (28 layers, native multimodal) Liu et al. (2023); Beyer et al. (2024); Wang et al. (2024). All experiments...
2023
-
[16]
Lie Detection
Neuron ID Type∆activation Functional Role 1512 Success +27.23 Answer confidence 1360 Failure−3.11 Failure detection 3839 Failure−3.08 Failure detection 2660 Failure−2.95 Failure detection A.11 Implementation and Hardware Details All experiments were conducted on compute clusters provided by RunPod and Lambda Labs, using NVIDIA A100 GPUs (80GB VRAM), AMD E...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.