Counsel: A Meta-Evaluation Dataset for Agentic Tasks
Pith reviewed 2026-06-26 14:06 UTC · model grok-4.3
The pith
Counsel is the first public dataset of human meta-evaluations for LLM judge critiques on agent trajectories, reaching 0.78 Krippendorff alpha.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
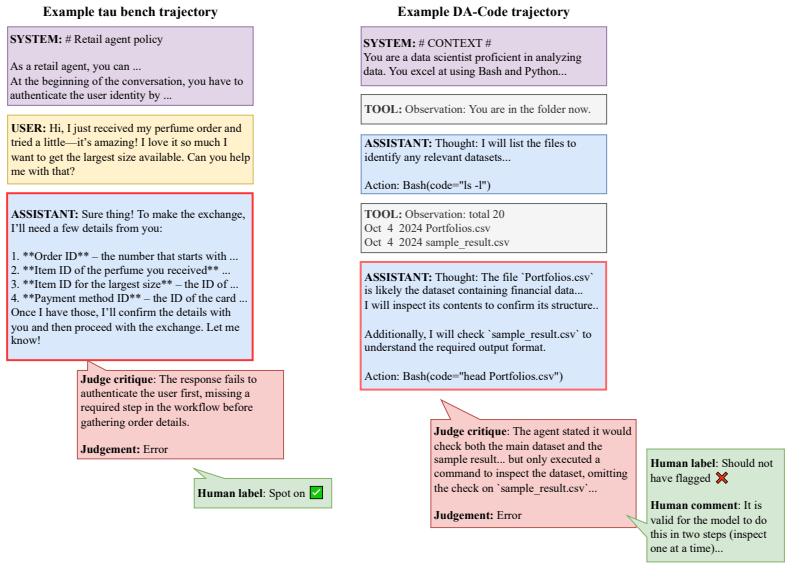
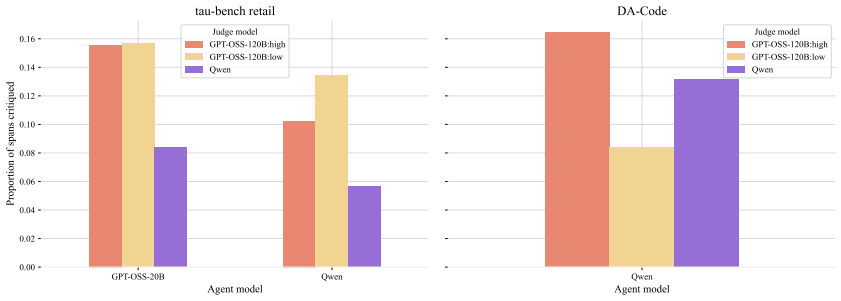
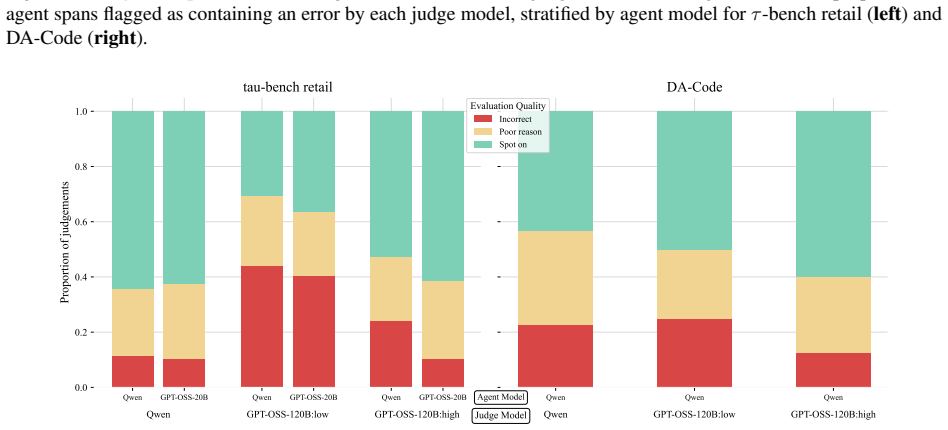
Counsel consists of process-level critiques from open-weight LLMJs on tau-bench and DA-Code paired with human meta-evaluations of these critiques. Human annotators label critiques on each flagged error as spot on, correct location but poor reasoning, or should not have flagged, achieving reliable inter-annotator agreement (Krippendorff's alpha of 0.78). The resulting dataset stratifies LLMJ critiques by human alignment across both error location within a trajectory and reasoning quality, serving as valuable data to calibrate, improve, or train LLMJs for agents. Comparing open-weight judges, more capable judge models and more reasoning effort both enabled improved human agreement, with the st
What carries the argument
Human meta-evaluation labels that classify each LLMJ critique as spot on, correct location but poor reasoning, or should not have flagged, thereby measuring alignment on both error location and reasoning quality.
If this is right
- The dataset supplies training and calibration data for improving LLM judges on agent trajectories.
- Stronger open-weight models combined with greater reasoning effort produce measurably higher human alignment.
- Process-level critiques can be stratified by location accuracy and reasoning quality for targeted judge improvement.
- Permissively licensed open-weight generation enables community reuse for agent evaluator development.
- The approach directly addresses the hours-long human annotation cost that currently limits scaling of agent evaluations.
Where Pith is reading between the lines
- The same meta-evaluation protocol could be applied to additional agent benchmarks to test whether alignment patterns hold more broadly.
- Labels distinguishing location from reasoning quality could guide prompt engineering that separately targets each aspect of judge performance.
- The dataset opens a route to building reward models or self-critique loops that improve agents using meta-evaluation signals.
- If agreement remains high, hybrid pipelines that use LLM judges for most work and humans only for low-alignment cases become feasible.
Load-bearing premise
Human meta-evaluations collected on tau-bench and DA-Code provide a reliable and generalizable signal for calibrating LLM judges across the broader space of agentic tasks and error types.
What would settle it
A large drop in agreement rates when the same LLM judges are tested on a new agent benchmark with substantially different task structure or error distribution would undermine the dataset's claimed utility.
Figures


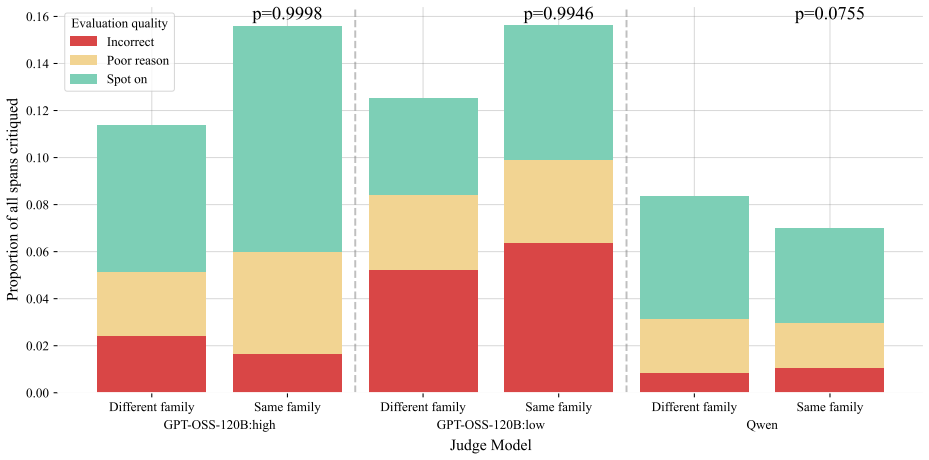
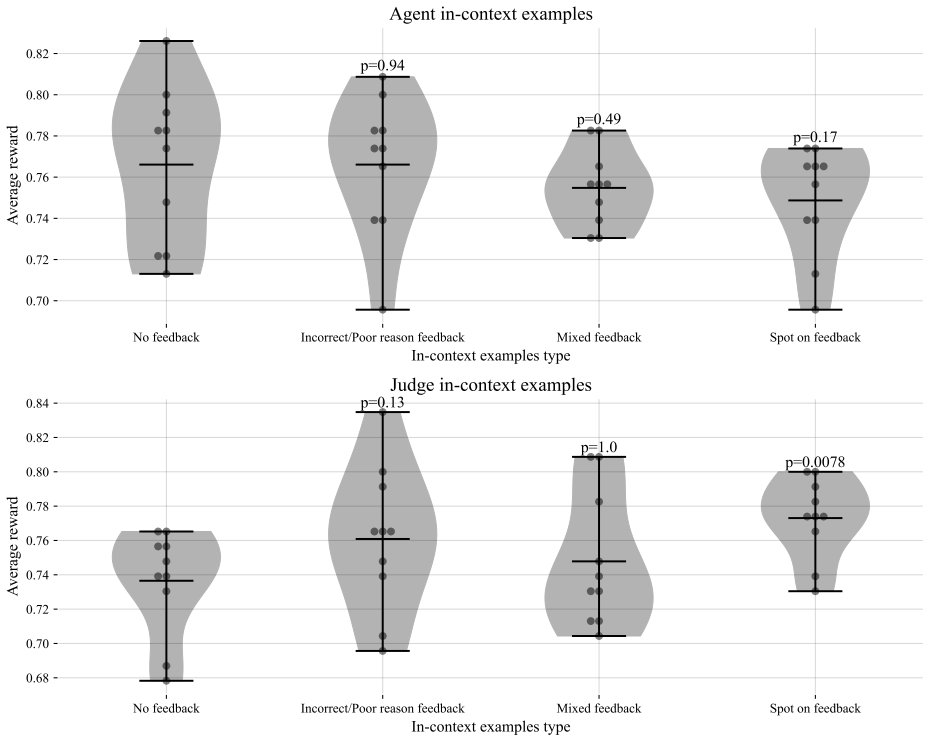

read the original abstract
As agentic systems tackle increasingly complex multi-step tasks, evaluating their trajectories presents a major bottleneck - human annotation of a single trajectory on popular agentic benchmarks can take hours, making it difficult to scale evaluations for measuring performance or curating training data. This has driven widespread reliance on automated approaches such as LLM-as-a-judge (LLMJ) to critique agents at the process and outcome-levels at scale, however, the soundness of LLMJ critiques often goes unmeasured. Here, we introduce Counsel, the first public dataset of meta-evaluations for agentic tasks. Counsel consists of process-level critiques from open-weight LLMJs on two agent benchmarks: tau-bench (customer support agents) and DA-Code (coding agents), and human meta-evaluations of these critiques. Human annotators label critiques on each flagged error as "spot on", "correct location but poor reasoning", or "should not have flagged", achieving reliable inter-annotator agreement (Krippendorff's alpha of 0.78). The resulting dataset stratifies LLMJ critiques by human alignment across both error location within a trajectory and reasoning quality, serving as valuable data to calibrate, improve, or train LLMJs for agents. Comparing open-weight judges, we find that more capable judge models and more reasoning effort both enabled improved human agreement, with the strongest judge reaching ~88% agreement on location and ~65% on reasoning. Counsel is generated using open-weight models and is permissively licensed for broad community use, which we hope will enable rigorous study and improved alignment of LLM-based evaluators for agentic systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Counsel, the first public dataset of meta-evaluations for agentic tasks. It consists of process-level critiques generated by open-weight LLM judges on trajectories from tau-bench (customer-support dialogues) and DA-Code (coding trajectories), paired with human meta-evaluations of those critiques using three labels (spot on, correct location but poor reasoning, should not have flagged). The dataset reports Krippendorff's alpha of 0.78 for inter-annotator agreement and finds that more capable judges with greater reasoning effort achieve higher human agreement (~88% on location, ~65% on reasoning). The authors position Counsel as calibration data for improving LLM judges on agentic systems and release it under a permissive license using open-weight models.
Significance. If the reported human alignment holds and the dataset is adopted, it would provide a concrete, open resource for studying and improving LLM-as-a-judge reliability on multi-step agent trajectories, directly addressing the scaling bottleneck noted in the abstract. The use of open-weight models and permissive licensing strengthens its potential for community follow-on work on calibration and training.
major comments (2)
- [Abstract] Abstract: the central utility claim that Counsel supplies 'valuable data to calibrate, improve, or train LLMJs for agents' broadly is load-bearing for the paper's contribution but rests only on human meta-evaluations collected exclusively from tau-bench and DA-Code; no cross-domain hold-out, error-type taxonomy coverage, or third benchmark is reported, so domain-specific alignment patterns cannot be ruled out.
- [Abstract] Abstract (dataset construction paragraph): the soundness of the reported Krippendorff's alpha of 0.78 and the location/reasoning agreement figures is only partially supported because the manuscript provides no details on annotation guidelines, sampling of critiques, or controls for annotator bias.
minor comments (1)
- The abstract would benefit from stating the total number of critiques, trajectories, and annotators to give readers immediate scale context.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the scope of our claims and the transparency of our annotation process. We address each major comment below and will revise the manuscript to strengthen these aspects while preserving the core contribution of releasing the first public meta-evaluation dataset for agentic tasks.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central utility claim that Counsel supplies 'valuable data to calibrate, improve, or train LLMJs for agents' broadly is load-bearing for the paper's contribution but rests only on human meta-evaluations collected exclusively from tau-bench and DA-Code; no cross-domain hold-out, error-type taxonomy coverage, or third benchmark is reported, so domain-specific alignment patterns cannot be ruled out.
Authors: We acknowledge that the human alignment results are derived from only two benchmarks and that no cross-domain hold-out or third benchmark is included. Tau-bench and DA-Code do represent meaningfully different agentic settings (multi-turn customer support dialogues versus coding trajectories), but this does not fully address the risk of domain-specific patterns. We will revise the abstract to qualify the utility claim, add an explicit limitations paragraph discussing the absence of broader domain coverage, and note that Counsel is intended as an initial calibration resource rather than a definitive cross-domain benchmark. No new experiments are feasible within the current scope. revision: partial
-
Referee: [Abstract] Abstract (dataset construction paragraph): the soundness of the reported Krippendorff's alpha of 0.78 and the location/reasoning agreement figures is only partially supported because the manuscript provides no details on annotation guidelines, sampling of critiques, or controls for annotator bias.
Authors: We agree that the main text should contain more explicit details on the annotation protocol. The full manuscript includes a human annotation section, but we will expand it in revision to include the full annotation guidelines, the sampling strategy used to select critiques for labeling, and the specific procedures employed to mitigate annotator bias (e.g., training, adjudication process, and demographic considerations). These additions will directly support the reported agreement statistics. revision: yes
Circularity Check
Empirical dataset release with no derivations or self-referential predictions
full rationale
The paper is a dataset release describing collection of human meta-evaluations on LLM critiques from two fixed benchmarks (tau-bench and DA-Code). No equations, fitted parameters, predictions, or derivation chains appear; reported statistics (Krippendorff α=0.78, location/reasoning agreement rates) are direct measurements from the human annotations rather than quantities derived from the dataset itself or from self-citations. The central claim is the dataset's existence and permissively licensed availability for downstream use, which is self-contained and externally verifiable without circular reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human annotations on critique quality provide a reliable signal for improving LLM-as-a-judge systems
Reference graph
Works this paper leans on
-
[1]
Ziegler, Elizabeth Barnes, and Lawrence Chan
Measuring ai ability to complete long tasks , author=. arXiv preprint arXiv:2503.14499 , year=
-
[2]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Swe-bench: Can language models resolve real-world github issues? , author=. arXiv preprint arXiv:2310.06770 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
and Yang, John and Ho, Leyton and Patwardhan, Tejal and Liu, Kevin and Madry, Aleksander , year=
Chowdhury, Neil and Aung, James and Shern, Chan Jun and Jaffe, Oliver and Sherburn, Dane and Starace, Giulio and Mays, Evan and Dias, Rachel and Aljubeh, Marwan and Glaese, Mia and Jimenez, Carlos E. and Yang, John and Ho, Leyton and Patwardhan, Tejal and Liu, Kevin and Madry, Aleksander , year=. Introducing
-
[4]
arXiv preprint arXiv:2505.08638 , year=
TRAIL: Trace Reasoning and Agentic Issue Localization , author=. arXiv preprint arXiv:2505.08638 , year=
-
[5]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Kimi K2: Open Agentic Intelligence
Kimi k2: Open agentic intelligence , author=. arXiv preprint arXiv:2507.20534 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
arXiv preprint arXiv:2504.15253 , year=
Evaluating judges as evaluators: The jetts benchmark of llm-as-judges as test-time scaling evaluators , author=. arXiv preprint arXiv:2504.15253 , year=
-
[8]
2026 , month = jan, day =
Demystifying evals for AI agents , author =. 2026 , month = jan, day =
2026
-
[9]
2025 , month = oct, day =
What works (and what doesn’t) when automating error analysis , author =. 2025 , month = oct, day =
2025
-
[10]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: System Demonstrations , pages=
AgentDiagnose: An Open Toolkit for Diagnosing LLM Agent Trajectories , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: System Demonstrations , pages=
2025
-
[11]
-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains , url =
Shunyu Yao and Noah Shinn and Pedram Razavi and Karthik Narasimhan , isbn =. -bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains , url =. 13th International Conference on Learning Representations, ICLR 2025 , month =
2025
-
[12]
DA-Code: Agent Data Science Code Generation Benchmark for Large Language Models , url =
Yiming Huang and Jianwen Luo and Yan Yu and Yitong Zhang and Fangyu Lei and Yifan Wei and Shizhu He and Lifu Huang and Xiao Liu and Jun Zhao and Kang Liu , doi =. DA-Code: Agent Data Science Code Generation Benchmark for Large Language Models , url =. EMNLP 2024 - 2024 Conference on Empirical Methods in Natural Language Processing, Proceedings of the Conf...
2024
-
[13]
Self-Preference Bias in LLM-as-a-Judge , url =
Koki Wataoka and Tsubasa Takahashi and Ryokan Ri , keywords =. Self-Preference Bias in LLM-as-a-Judge , url =. arXiv , year =
-
[14]
OpenAI and : and Sandhini Agarwal and Lama Ahmad and Jason Ai and Sam Altman and Andy Applebaum and Edwin Arbus and Rahul K. Arora and Yu Bai and Bowen Baker and Haiming Bao and Boaz Barak and Ally Bennett and Tyler Bertao and Nivedita Brett and Eugene Brevdo and Greg Brockman and Sebastien Bubeck and Che Chang and Kai Chen and Mark Chen and Enoch Cheung ...
-
[15]
Qwen3 Technical Report , journal =
An Yang and Anfeng Li and Baosong Yang and Beichen Zhang and Binyuan Hui and Bo Zheng and Bowen Yu and Chang Gao and Chengen Huang and Chenxu Lv and Chujie Zheng and Dayiheng Liu and Fan Zhou and Fei Huang and Feng Hu and Hao Ge and Haoran Wei and Huan Lin and Jialong Tang and Jian Yang and Jianhong Tu and Jianwei Zhang and Jianxin Yang and Jiaxi Yang and...
-
[16]
OffsetBias: Leveraging Debiased Data for Tuning Evaluators , url =
Junsoo Park and Seungyeon Jwa and Meiying Ren and Daeyoung Kim and Sanghyuk Choi , doi =. OffsetBias: Leveraging Debiased Data for Tuning Evaluators , url =. EMNLP 2024 - 2024 Conference on Empirical Methods in Natural Language Processing, Findings of EMNLP 2024 , month =
2024
-
[17]
arXiv preprint arXiv:2504.08942 , year=
Agentrewardbench: Evaluating automatic evaluations of web agent trajectories , author=. arXiv preprint arXiv:2504.08942 , year=
-
[18]
JudgeBench: A Benchmark for Evaluating LLM-based Judges
Judgebench: A benchmark for evaluating llm-based judges , author=. arXiv preprint arXiv:2410.12784 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Why Do Multi-Agent LLM Systems Fail?
Why do multi-agent llm systems fail? , author=. arXiv preprint arXiv:2503.13657 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Agent-as-a-Judge: Evaluate Agents with Agents, October 2024
Agent-as-a-judge: Evaluate agents with agents , author=. arXiv preprint arXiv:2410.10934 , year=
-
[21]
RewardBench 2: Advancing Reward Model Evaluation
RewardBench 2: Advancing Reward Model Evaluation , author=. arXiv preprint arXiv:2506.01937 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Direct judgement preference optimization , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[23]
arXiv preprint arXiv:2501.17195 , year=
Atla selene mini: A general purpose evaluation model , author=. arXiv preprint arXiv:2501.17195 , year=
-
[24]
J1: Incentivizing Thinking in LLM-as-a-Judge via Reinforcement Learning, October 2025
J1: Incentivizing thinking in llm-as-a-judge via reinforcement learning , author=. arXiv preprint arXiv:2505.10320 , year=
-
[25]
arXiv preprint arXiv:2505.02387 , year=
Rm-r1: Reward modeling as reasoning , author=. arXiv preprint arXiv:2505.02387 , year=
-
[26]
arXiv preprint arXiv:2505.14674 , year=
Reward reasoning model , author=. arXiv preprint arXiv:2505.14674 , year=
-
[27]
arXiv preprint arXiv:2312.09241 , year=
Tinygsm: achieving> 80\ author=. arXiv preprint arXiv:2312.09241 , year=
-
[28]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Meta-rewarding language models: Self-improving alignment with llm-as-a-meta-judge , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[29]
arXiv preprint arXiv:2504.17087 , year=
Leveraging llms as meta-judges: A multi-agent framework for evaluating llm judgments , author=. arXiv preprint arXiv:2504.17087 , year=
-
[30]
The role of agentic AI in shaping a smart future: A systematic review , volume =
Soodeh Hosseini and Hossein Seilani , doi =. The role of agentic AI in shaping a smart future: A systematic review , volume =. Array , keywords =
-
[31]
^2 -Bench: Evaluating Conversational Agents in a Dual-Control Environment , url =
Victor Barres and Honghua Dong and Soham Ray Sierra soham and sierraai Xujie Si and Karthik Narasimhan Sierra , keywords =. ^2 -Bench: Evaluating Conversational Agents in a Dual-Control Environment , url =
-
[32]
Gemini 3: Introducing the latest Gemini AI model from Google , url =
Google , keywords =. Gemini 3: Introducing the latest Gemini AI model from Google , url =
-
[33]
2004 , publisher=
Content analysis: An introduction to its methodology , author=. 2004 , publisher=
2004
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.