InSight: Self-Guided Skill Acquisition via Steerable VLAs
Pith reviewed 2026-06-26 00:09 UTC · model grok-4.3
The pith
InSight renders vision-language-action models steerable at the primitive-action level to enable autonomous skill acquisition.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that rendering VLAs steerable at the primitive-action level, through an automated segmentation pipeline that partitions demonstrations into labeled primitives via VLM plan decomposition and end-effector poses, plus a VLM-guided data flywheel that identifies missing primitives, autonomously attempts demonstrations with VLM-proposed low-level controls, and integrates successful ones, provides a practical foundation for continual skill acquisition, as shown by learning tasks such as block flipping, drawer closing, sweeping, twisting, and pouring with no human demonstrations of the target skills.
What carries the argument
Primitive steerability, achieved by automated segmentation of demonstrations into labeled primitives and VLM-guided generation of new demonstrations for missing primitives.
Load-bearing premise
The automated segmentation pipeline reliably partitions demonstrations into accurate, labeled primitives and the VLM can propose low-level controls that produce successful, automatically labelable demonstrations for missing primitives.
What would settle it
Running the full pipeline on a target task such as pouring and finding that either segmentation produces inaccurate primitive labels or the generated demonstrations consistently fail to succeed and receive labels, so that the VLA never acquires the new primitive.
Figures




read the original abstract
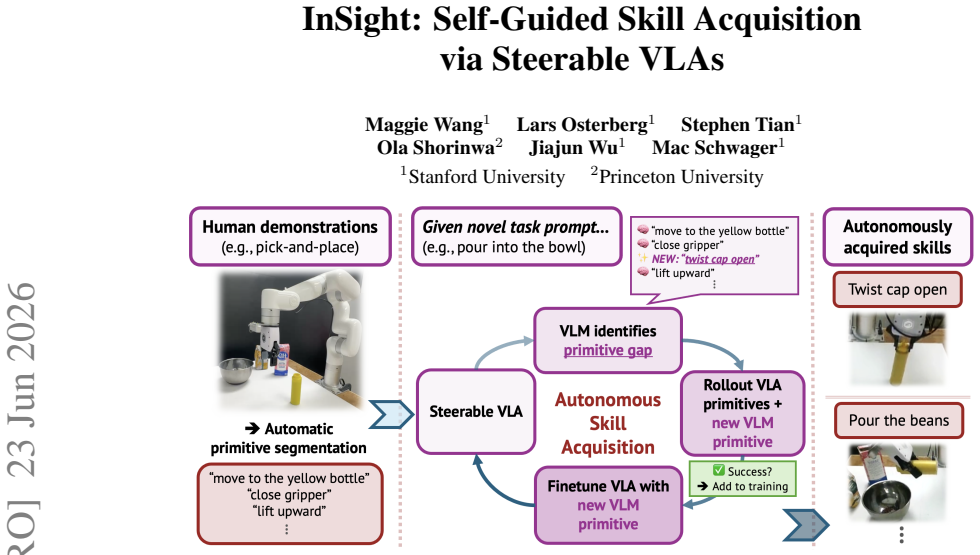
Vision-language-action (VLA) models can learn manipulation skills from demonstrations, but their capabilities are bounded by the skills in the training data. We present InSight, a framework that unlocks autonomous skill acquisition by rendering VLAs steerable at the primitive-action level (e.g., "move gripper to the bowl", "lift upward", "pour the bottle"). InSight consists of two primary stages: (1) an automated segmentation pipeline that partitions demonstrations into labeled primitives via VLM plan decomposition and end-effector poses to enable VLA primitive steerability, and (2) a VLM-guided data flywheel that identifies missing primitives required to accomplish a novel task, autonomously attempts demonstrations of the missing primitives with VLM-proposed low-level control, and automatically labels, stores, and integrates successful demonstrations into the VLA training set. We evaluate InSight across simulation and real-world manipulation tasks, including block flipping, drawer closing, sweeping, twisting, and pouring, without any human demonstrations of these target skills. Once learned, these primitives can be composed to execute novel, long-horizon tasks without additional human demonstrations. Our findings demonstrate that primitive steerability provides a practical foundation for continual skill acquisition in VLA policies. Project website: https://insight-vla.github.io.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents InSight, a framework for autonomous skill acquisition in Vision-Language-Action (VLA) policies. It consists of an automated segmentation pipeline that partitions demonstrations into labeled primitives using VLM plan decomposition and end-effector poses, and a VLM-guided data flywheel that identifies missing primitives for novel tasks, generates demonstrations autonomously with VLM-proposed controls, and integrates successful ones into the training set. The paper claims evaluations on simulation and real-world tasks such as block flipping, drawer closing, sweeping, twisting, and pouring without human demonstrations of the target skills, enabling composition for long-horizon tasks.
Significance. If the central claims hold, the work could offer a practical mechanism for continual, self-guided skill acquisition in VLAs by leveraging primitive-level steerability, potentially reducing the need for extensive human demonstrations in robotic manipulation. This addresses a key limitation in current VLA models where capabilities are bounded by training data.
major comments (3)
- [Abstract] Abstract: The abstract states that evaluations were performed across simulation and real-world tasks but supplies no quantitative results, success rates, baselines, or error analysis. This absence makes it impossible to assess whether the VLM-guided flywheel reliably produces successful and automatically labelable demonstrations.
- [Abstract] Abstract and flywheel description: The central claim that primitive steerability enables autonomous acquisition without human demonstrations rests on the unverified assumption that the VLM can propose low-level controls yielding trajectories that are both task-successful and correctly segmented by the same pipeline; no attempt-success fractions, failure-mode analysis, or autonomous success-scoring procedure are reported.
- [Method (segmentation pipeline)] Segmentation pipeline description: No evidence or analysis is provided on whether the automated segmentation (VLM plan decomposition plus end-effector poses) remains accurate on novel VLM-generated trajectories rather than the original human demonstrations, which is load-bearing for the flywheel to close without external supervision.
minor comments (1)
- The project website is referenced but the manuscript does not indicate whether it supplies videos, code, or additional quantitative results that would aid reproducibility assessment.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract states that evaluations were performed across simulation and real-world tasks but supplies no quantitative results, success rates, baselines, or error analysis. This absence makes it impossible to assess whether the VLM-guided flywheel reliably produces successful and automatically labelable demonstrations.
Authors: We agree that the abstract would be strengthened by including key quantitative results. In the revised manuscript we will update the abstract to report representative success rates from the simulation and real-world evaluations (e.g., for pouring and sweeping) and note the baseline comparisons performed. The full quantitative results, baselines, and error analysis already appear in the experimental section; the abstract revision will simply surface these numbers at the summary level. revision: yes
-
Referee: [Abstract] Abstract and flywheel description: The central claim that primitive steerability enables autonomous acquisition without human demonstrations rests on the unverified assumption that the VLM can propose low-level controls yielding trajectories that are both task-successful and correctly segmented by the same pipeline; no attempt-success fractions, failure-mode analysis, or autonomous success-scoring procedure are reported.
Authors: The manuscript reports overall task success after flywheel integration but does not provide granular attempt-success fractions or a dedicated failure-mode breakdown for the autonomous generation step. We will add a concise subsection (or expanded paragraph) that reports these fractions, describes the observed failure modes, and clarifies the automatic success-scoring procedure used to accept demonstrations into the training set. This addition will directly support the central claim. revision: yes
-
Referee: [Method (segmentation pipeline)] Segmentation pipeline description: No evidence or analysis is provided on whether the automated segmentation (VLM plan decomposition plus end-effector poses) remains accurate on novel VLM-generated trajectories rather than the original human demonstrations, which is load-bearing for the flywheel to close without external supervision.
Authors: We acknowledge that the current manuscript validates the segmentation pipeline primarily on the initial human demonstrations and does not include an explicit accuracy comparison on VLM-generated trajectories. This is a substantive gap for the self-supervised claim. We will add targeted analysis (either quantitative metrics or qualitative examples) demonstrating segmentation performance on the autonomously generated trajectories, thereby confirming that the flywheel can operate without external labeling. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper presents an empirical framework relying on external VLM and VLA components whose performance is treated as given inputs rather than quantities derived within the work. No mathematical derivations, fitted parameters renamed as predictions, self-citations as load-bearing premises, or ansatzes smuggled via prior author work appear in the provided text. The central claim rests on experimental outcomes across tasks rather than any self-referential reduction of outputs to inputs by construction, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption VLMs can reliably decompose demonstrations into labeled primitives and propose low-level controls that succeed often enough for the flywheel to improve the VLA.
Reference graph
Works this paper leans on
-
[1]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, Q. Vuong, T. Kollar, B. Burchfiel, R. Tedrake, D. Sadigh, S. Levine, P. Liang, and C. Finn. OpenVLA: An Open-Source Vision-Language-Action Model, June
- [2]
-
[3]
P. Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, M. Y . Galliker, D. Ghosh, L. Groom, K. Hausman, B. Ichter, S. Jakubczak, T. Jones, L. Ke, D. LeBlanc, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, A. Z. Ren, L. X. Shi, L. Smith, J. T. Springenberg, K. Stachowicz, J. Tanner, Q. V...
Pith/arXiv arXiv 2025
-
[4]
J. Bjorck, F. Castañeda, N. Cherniadev, X. Da, R. Ding, L. J. Fan, Y . Fang, D. Fox, F. Hu, S. Huang, J. Jang, Z. Jiang, J. Kautz, K. Kundalia, L. Lao, Z. Li, Z. Lin, K. Lin, G. Liu, E. Llontop, L. Magne, A. Mandlekar, A. Narayan, S. Nasiriany, S. Reed, Y . L. Tan, G. Wang, Z. Wang, J. Wang, Q. Wang, J. Xiang, Y . Xie, Y . Xu, Z. Xu, S. Ye, Z. Yu, A. Zhan...
Pith/arXiv arXiv 2025
-
[5]
NASA’s InSight Waits Out Dust Storm - NASA, Oct. 2022. URLhttps://www.nasa.gov/ missions/insight/nasas-insight-waits-out-dust-storm/. Section: InSight (Inte- rior Exploration using Seismic Investigations, Geodesy and Heat Transport)
2022
-
[6]
D. Kalashnikov, A. Irpan, P. Pastor, J. Ibarz, A. Herzog, E. Jang, D. Quillen, E. Holly, M. Kalakrishnan, V . Vanhoucke, and S. Levine. Qt-opt: Scalable deep reinforcement learning for vision-based robotic manipulation, 2018. URLhttps://arxiv.org/abs/1806.10293
Pith/arXiv arXiv 2018
-
[7]
Wagenmaker, M
A. Wagenmaker, M. Nakamoto, Y . Zhang, S. Park, W. Yagoub, A. Nagabandi, A. Gupta, and S. Levine. Steering Your Diffusion Policy with Latent Space Reinforcement Learning, June
-
[8]
URLhttps://arxiv.org/abs/2506.15799v2
-
[9]
Z. Gu, M. Yang, D. Zou, and D. Xu. Learning Diffusion Policy from Primitive Skills for Robot Manipulation, Jan. 2026. URLhttp://arxiv.org/abs/2601.01948. arXiv:2601.01948 [cs]
arXiv 2026
-
[10]
C. R. Garrett, R. Chitnis, R. Holladay, B. Kim, T. Silver, L. P. Kaelbling, and T. Lozano- Pérez. Integrated Task and Motion Planning, Oct. 2020. URLhttp://arxiv.org/abs/ 2010.01083. arXiv:2010.01083 [cs.RO]
arXiv 2020
-
[11]
W. Chen, J. S. Bhatia, C. Glossop, N. Mathihalli, R. Doshi, A. Tang, D. Driess, K. Pertsch, and S. Levine. Steerable Vision-Language-Action Policies for Embodied Reasoning and Hierar- chical Control, Feb. 2026. URLhttp://arxiv.org/abs/2602.13193. arXiv:2602.13193 [cs]
Pith/arXiv arXiv 2026
-
[12]
In: 2025 IEEE International Conference on Robotics and Automation (ICRA)
L. Smith, A. Irpan, M. G. Arenas, S. Kirmani, D. Kalashnikov, D. Shah, and T. Xiao. STEER: Flexible Robotic Manipulation via Dense Language Grounding. In2025 IEEE Interna- tional Conference on Robotics and Automation (ICRA), pages 16517–16524, May 2025. doi: 10.1109/ICRA55743.2025.11127404. URLhttps://ieeexplore.ieee.org/document/ 11127404/
-
[13]
J. Liang, W. Huang, F. Xia, P. Xu, K. Hausman, B. Ichter, P. Florence, and A. Zeng. Code as Policies: Language Model Programs for Embodied Control, May 2023. URLhttp://arxiv. org/abs/2209.07753. arXiv:2209.07753 [cs]
Pith/arXiv arXiv 2023
-
[14]
M. Ahn, A. Brohan, N. Brown, Y . Chebotar, O. Cortes, B. David, C. Finn, C. Fu, K. Gopalakr- ishnan, K. Hausman, A. Herzog, D. Ho, J. Hsu, J. Ibarz, B. Ichter, A. Irpan, E. Jang, R. J. 10 Ruano, K. Jeffrey, S. Jesmonth, N. J. Joshi, R. Julian, D. Kalashnikov, Y . Kuang, K.-H. Lee, S. Levine, Y . Lu, L. Luu, C. Parada, P. Pastor, J. Quiambao, K. Rao, J. Re...
-
[15]
URLhttps://arxiv.org/abs/2204.01691v2
-
[16]
W. Huang, C. Wang, R. Zhang, Y . Li, J. Wu, and L. Fei-Fei. V oxPoser: Composable 3D Value Maps for Robotic Manipulation with Language Models, Nov. 2023. URLhttp://arxiv. org/abs/2307.05973. arXiv:2307.05973 [cs.RO]
Pith/arXiv arXiv 2023
-
[17]
M. Fu, J. Yu, K. El-Refai, E. Kou, H. Xue, H. Huang, W. Xiao, G. Wang, F.-F. Li, G. Shi, J. Wu, S. Sastry, Y . Zhu, K. Goldberg, and L. J. Fan. CaP-X: A Framework for Benchmarking and Improving Coding Agents for Robot Manipulation, Mar. 2026. URLhttp://arxiv. org/abs/2603.22435. arXiv:2603.22435 [cs]
arXiv 2026
-
[18]
P. Intelligence, B. Ai, A. Amin, R. Aniceto, A. Balakrishna, G. Balke, K. Black, G. Bokin- sky, S. Cao, T. Charbonnier, V . Choudhary, F. Collins, K. Conley, G. Connors, J. Darpinian, K. Dhabalia, M. Dhaka, J. DiCarlo, D. Driess, M. Equi, A. Esmail, Y . Fang, C. Finn, C. Glos- sop, T. Godden, I. Goryachev, L. Groom, H. Habeeb, H. Hancock, K. Hausman, G. H...
Pith/arXiv arXiv 2026
-
[19]
S. Liu, I. S. Singh, Y . Xu, J. Duan, and R. Krishna. VLS: Steering Pretrained Robot Poli- cies via Vision-Language Models, Feb. 2026. URLhttp://arxiv.org/abs/2602.03973. arXiv:2602.03973 [cs]
arXiv 2026
-
[20]
N. B. Gutierrez, J. M. Cloud, and W. J. Beksi. Movement primitives in robotics: A compre- hensive survey, 2026. URLhttps://arxiv.org/abs/2601.02379
Pith/arXiv arXiv 2026
-
[21]
B. Lee, Y . Lee, S. Kim, M. Son, and F. C. Park. Equivariant Motion Manifold Primitives. In Proceedings of The 7th Conference on Robot Learning, pages 1199–1221. PMLR, Dec. 2023. URLhttps://proceedings.mlr.press/v229/lee23a.html
2023
-
[22]
W. Liu, N. Nie, R. Zhang, J. Mao, and J. Wu. Learning Compositional Behaviors from Demon- stration and Language, 2025. URLhttps://arxiv.org/abs/2505.21981. Version Num- ber: 1
arXiv 2025
-
[23]
Y . Zhu, P. Stone, and Y . Zhu. Bottom-Up Skill Discovery from Unsegmented Demonstrations for Long-Horizon Robot Manipulation, Jan. 2022. URLhttp://arxiv.org/abs/2109. 13841. arXiv:2109.13841 [cs]
arXiv 2022
-
[24]
A. Adeniji. Learning Representations for Unsupervised Skill Discovery. 2024. URLhttps: //purl.stanford.edu/sb108vw6601
2024
-
[25]
Cathomen, M
R. Cathomen, M. Mittal, M. Vlastelica, and M. Hutter. Divide, Discover, Deploy: Factorized Skill Learning with Symmetry and Style Priors. 2025
2025
-
[26]
N. Nie, W. Huang, J. Mao, L. Fei-Fei, W. Liu, and J. Wu. Learning composable skills by discovering spatial and temporal structure with foundation models. InIEEE International Conference on Robotics and Automation (ICRA), 2026
2026
-
[27]
L. X. Shi, B. Ichter, M. Equi, L. Ke, K. Pertsch, Q. Vuong, J. Tanner, A. Walling, H. Wang, N. Fusai, A. Li-Bell, D. Driess, L. Groom, S. Levine, and C. Finn. Hi Robot: Open-Ended Instruction Following with Hierarchical Vision-Language-Action Models, Feb. 2025. URL https://arxiv.org/abs/2502.19417v2
Pith/arXiv arXiv 2025
-
[28]
C. Xu, Q. Li, J. Luo, and S. Levine. RLDG: Robotic Generalist Policy Distillation via Rein- forcement Learning, Dec. 2024. URLhttps://arxiv.org/abs/2412.09858v1. 11
arXiv 2024
- [29]
-
[30]
Y . J. Ma, W. Liang, G. Wang, D.-A. Huang, O. Bastani, D. Jayaraman, Y . Zhu, L. Fan, and A. Anandkumar. Eureka: Human-Level Reward Design via Coding Large Language Models, Apr. 2024. URLhttp://arxiv.org/abs/2310.12931. arXiv:2310.12931 [cs]
Pith/arXiv arXiv 2024
-
[31]
X. Zhao, C. Weber, and S. Wermter. Agentic Skill Discovery, Aug. 2024. URLhttp:// arxiv.org/abs/2405.15019. arXiv:2405.15019 [cs]
arXiv 2024
-
[32]
Mandlekar, S
A. Mandlekar, S. Nasiriany, B. Wen, I. Akinola, Y . Narang, L. Fan, Y . Zhu, and D. Fox. Mim- icGen: A Data Generation System for Scalable Robot Learning using Human Demonstrations. 2023
2023
-
[33]
J. Duan, W. Yuan, W. Pumacay, Y . R. Wang, K. Ehsani, D. Fox, and R. Krishna. Manipulate- Anything: Automating Real-World Robots using Vision-Language Models, Aug. 2024. URL http://arxiv.org/abs/2406.18915. arXiv:2406.18915 [cs.RO]
arXiv 2024
-
[34]
H. Ha, P. Florence, and S. Song. Scaling Up and Distilling Down: Language- Guided Robot Skill Acquisition, Oct. 2023. URLhttp://arxiv.org/abs/2307.14535. arXiv:2307.14535 [cs]
arXiv 2023
-
[35]
Cheng, Z
S. Cheng, Z. Li, K. Yu, and D. Xu. Continual Robot Learning via Language-Guided Skill Acquisition. 2025
2025
-
[36]
Y . Wu, G. Wang, Z. Yang, M. Yao, B. Sheil, and H. Wang. Continually Evolving Skill Knowledge in Vision Language Action Model, 2025. URLhttps://arxiv.org/abs/2511. 18085. Version Number: 2
2025
-
[37]
X. Wang, Z. Han, Z. Liu, G. Li, J. Dong, B. Liu, L. Liu, and Z. Han. Lifelong Language- Conditioned Robotic Manipulation Learning, Mar. 2026. URLhttp://arxiv.org/abs/ 2603.05160. arXiv:2603.05160 [cs.RO]
arXiv 2026
-
[38]
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen. Lora: Low- rank adaptation of large language models, 2021. URLhttps://arxiv.org/abs/2106. 09685
2021
-
[39]
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone. LIBERO: Benchmarking Knowledge Transfer for Lifelong Robot Learning, Oct. 2023. URLhttp://arxiv.org/ abs/2306.03310. arXiv:2306.03310 [cs]
Pith/arXiv arXiv 2023
-
[40]
T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine. Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor, Jan. 2018. URLhttps: //arxiv.org/abs/1801.01290v2
Pith/arXiv arXiv 2018
-
[41]
S. Zhai, Q. Zhang, T. Zhang, F. Huang, H. Zhang, M. Zhou, S. Zhang, L. Liu, S. Lin, and J. Pang. A Vision-Language-Action-Critic Model for Robotic Real-World Reinforcement Learning, Sept. 2025. URLhttps://arxiv.org/abs/2509.15937v1
arXiv 2025
-
[42]
S. Ye, Y . Ge, K. Zheng, S. Gao, S. Yu, G. Kurian, S. Indupuru, Y . L. Tan, C. Zhu, J. Xiang, A. Malik, K. Lee, W. Liang, N. Ranawaka, J. Gu, Y . Xu, G. Wang, F. Hu, A. Narayan, J. Bjorck, J. Wang, G. Kim, D. Niu, R. Zheng, Y . Xie, J. Wu, Q. Wang, R. Julian, D. Xu, Y . Du, Y . Cheb- otar, S. Reed, J. Kautz, Y . Zhu, L. J. Fan, and J. Jang. World Action M...
Pith/arXiv arXiv 2026
-
[43]
B. Hou, G. Li, J. Jia, T. An, X. Guo, S. Leng, H. Geng, Y . Ze, T. Harada, P. Torr, O. Mees, M. Pollefeys, Z. Liu, J. Wu, P. Abbeel, J. Malik, Y . Du, and J. Yang. World Model for Robot Learning: A Comprehensive Survey, Apr. 2026. URLhttp://arxiv.org/abs/ 2605.00080. arXiv:2605.00080 [cs]
Pith/arXiv arXiv 2026
-
[44]
Gemini 3: Advancing multimodal intelligence, agentic workflows, and deep reasoning
Gemini Team, Google DeepMind. Gemini 3: Advancing multimodal intelligence, agentic workflows, and deep reasoning. Technical report, Google DeepMind, 2025. URLhttps: //deepmind.google/technologies/gemini. 12 A Implementation Details We use theπ 0.5 VLA [2] in our experiments, although INSIGHTis agnostic to the underlying VLA. We fine-tune with LoRA [35] (G...
2025
-
[45]
Use existing primitives for every sub-step they cover -- a skill gap should only be the novel part, not a bundle of existing + novel actions
Break the goal into fine-grained steps. Use existing primitives for every sub-step they cover -- a skill gap should only be the novel part, not a bundle of existing + novel actions
-
[46]
If an existing primitive could achieve the same result (even if executed differently), use it and put execution details in step_notes instead
Only create a skill gap when the desired outcome is fundamentally different from what any existing primitive produces. If an existing primitive could achieve the same result (even if executed differently), use it and put execution details in step_notes instead
-
[47]
Every step goes in primitive_sequence -- including new ones
-
[48]
New primitives also go in skill_gaps (must appear in BOTH lists)
-
[49]
Name new primitives by their desired EFFECT, not the robot motion
-
[50]
For each step, add a note on execution (approach, grasp, how it enables the next step)
-
[51]
Each step should make a distinguishable contribution to the goal -- avoid adding a final step whose only effect is repositioning the gripper
After the final step, the runtime returns the gripper to a safe home pose, so the gripper does not need to be cleared from the workspace by a final step in the plan. Each step should make a distinguishable contribution to the goal -- avoid adding a final step whose only effect is repositioning the gripper
-
[52]
move gripper to the red lego block
Each skill gap is one single-axis motion (one translation OR one rotation along one axis, in one direction). If the goal involves multiple distinct motions, create a separate skill gap for each. Example 1 -- pick and place (all existing, no skill gaps): primitive_sequence: ["move gripper to the red lego block", "close gripper", "lift upward", "move grippe...
-
[53]
Never select drz for any motion that requires an object to tip over, invert, or pivot its top towards a target; drz only spins the object on its own axis
-
[54]
current_state
The wrist camera moves with the gripper; its local axes are independent of the global room frame. Never select an axis based on where a target appears to sit (left, right, up, down) in IMAGE 1. Map the required tilt strictly to the local structure of the gripper fingers in IMAGE 2. BE AW ARE: Depth and gripper biases may exist due to the close-up wrist vi...
-
[55]
KNOWN move gripper above the yellow bottle cap— Move the gripper into a top-down approach position centered over the yellow cap
-
[56]
KNOWN close gripper— Close the gripper to secure a firm grasp on the cap
-
[57]
KNOWN twist open the cap— Perform a 180-degree counterclockwise rotation to unscrew the cap from the bottle
-
[58]
KNOWN lift upward— Lift the cap vertically to ensure it is completely detached from the bottle threads
-
[59]
KNOWN open gripper— Open the gripper to drop the detached cap onto the workspace
-
[60]
KNOWN return to home— Execute the mandatory hardware reset to return the robot to its canon- ical home pose
-
[61]
KNOWN move gripper to the side of the yellow bottle body— Move the gripper to a side- approach position relative to the bottle body
-
[62]
KNOWN close gripper— Close the gripper to perform a side grasp on the now-uncapped bottle
-
[63]
KNOWN lift upward— Lift the bottle upward to clear the table for movement
-
[64]
KNOWN move gripper to the side of the bowl— Transport the bottle to the side of the bowl in preparation for pouring
-
[65]
KNOWN tilt bottle forward to pour— Tilt the bottle forward over the bowl to empty its contents
-
[66]
KNOWN tilt bottle back upright— Rotate the bottle back to a vertical, upright orientation
-
[67]
KNOWN lower gripper— Lower the bottle back down to the table surface
-
[68]
KNOWN open gripper— Open the gripper to release the bottle. 19
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.