RayPE: Ray-Space Positional Encoding for 3D-Aware Video Generation
Pith reviewed 2026-06-29 04:31 UTC · model grok-4.3
The pith
RayPE injects 6D Plucker ray coordinates into video diffusion transformer attention to capture scene geometry that standard RoPE misses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
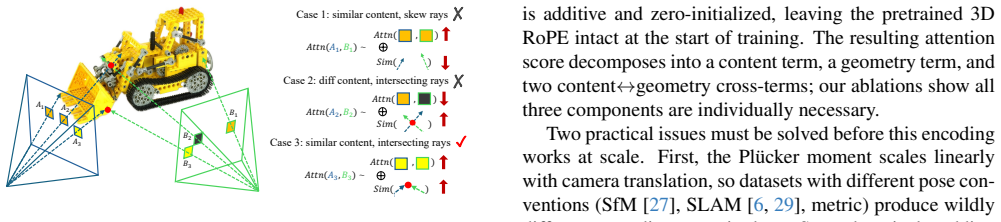
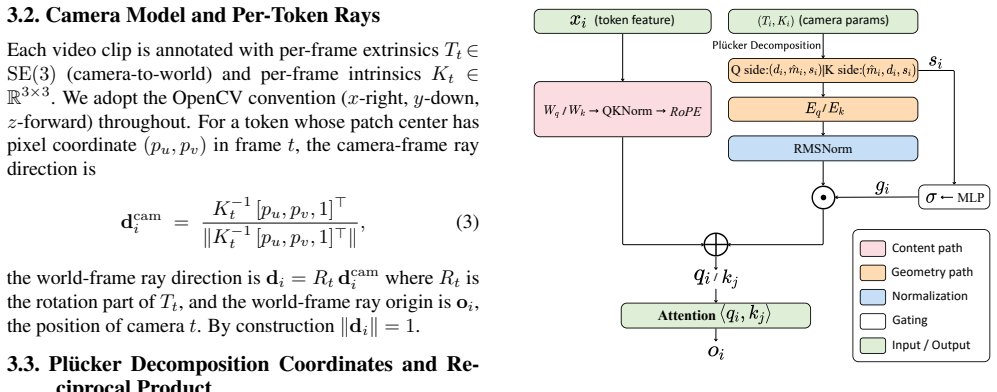
RayPE injects per-token 6D Plucker coordinates additively into the queries and keys of self-attention, with a query/key flip arrangement under which the symmetric identity configuration coincides exactly with the reciprocal product. The attention score therefore decomposes into a content term, a geometry term, and two content-geometry cross-terms, all of which prove individually necessary. Direction is decoupled from moment magnitude, the geometry contribution is gated by a learned function of log-magnitude, and RMSNorm aligns it with the content branch.
What carries the argument
RayPE: additive injection of 6D Plucker coordinates into attention queries and keys so the reciprocal-product bilinear form appears directly in the attention score.
If this is right
- The full module adds less than 0.1 percent parameters to a pretrained video DiT.
- Zero initialization allows training to begin from the original pretrained weights.
- Camera controllability improves on generated videos.
- Cross-frame 3D consistency improves on the training mixture.
- Overall video quality improves on the same four-dataset mixture.
Where Pith is reading between the lines
- The clean separation of geometry and content terms suggests the same bilinear injection could be tried on other attention-based spatial models without redesigning the backbone.
- Decoupling ray direction from moment magnitude may let the same encoding handle both normalized and metric camera data in future video or image generators.
- Because the change is additive and zero-initialized, it offers a low-risk route for adding geometric awareness to any existing DiT checkpoint.
Load-bearing premise
The bilinear reciprocal-product term, when added to content-based attention and gated by a learned function of log-magnitude, produces measurable gains in 3D consistency rather than being absorbed into the existing content pathway.
What would settle it
Ablating only the geometry term while keeping the rest of RayPE and measuring whether cross-frame 3D consistency metrics on the four-dataset mixture drop back to the RoPE baseline level.
Figures






read the original abstract
Modern video diffusion transformers position their tokens through RoPE on the (u,v,t) axes -- a description of the camera's sampling grid that says nothing about the 3D structure of the scene. We observe that the geometric relation between two camera rays is captured by the Plucker reciprocal product, which is bilinear in the two rays -- the same algebraic form as the dot product in Transformer attention. Building on this analogy, we propose RayPE, a positional-encoding extension that injects per-token 6D Plucker coordinates additively into the queries and keys of self-attention, with a query/key flip arrangement under which the symmetric identity configuration coincides exactly with the reciprocal product. The injection is additive, the resulting attention score decomposes into a content term, a geometry term, and two content and geometry cross-terms -- all of which our experiments find individually necessary. To make the encoding stable across video data with heterogeneous camera-translation scales (SfM, deep SLAM, metric), we further decouple ray direction from moment magnitude, gate the encoding by a learned function of the log-magnitude, and apply RMSNorm to align it with the QKNorm-normalized content branch. The full module adds less than 0.1% parameters to a pretrained video DiT, is zero-initialized to start from the pretrained weights, and improves camera controllability, cross-frame 3D consistency, and overall video quality on a four-dataset training mixture.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes RayPE, an extension to positional encodings in video diffusion transformers (DiTs). It injects per-token 6D Plucker coordinates of camera rays additively into the queries and keys of self-attention via a query/key flip arrangement so that the attention score includes the Plucker reciprocal product as its geometry term. The resulting score decomposes into content, geometry, and two cross terms; a learned gate on log-magnitude plus RMSNorm stabilizes the encoding across heterogeneous camera scales. The module adds <0.1% parameters, is zero-initialized from a pretrained video DiT, and is claimed to improve camera controllability, cross-frame 3D consistency, and video quality on a four-dataset mixture, with experiments asserting that all four terms are individually necessary.
Significance. If the experimental claims are substantiated, the work supplies a lightweight, algebraically motivated way to embed ray-space geometry directly into the attention mechanism of video generators. This could improve controllability and consistency without retraining from scratch or adding substantial capacity, and the bilinear decomposition plus gating strategy may generalize to other geometric priors in diffusion models.
major comments (2)
- [Abstract] Abstract: the central claim that 'our experiments find [the four terms] individually necessary' and that the module improves camera controllability, 3D consistency, and video quality rests on an assertion with no accompanying quantitative tables, ablation numbers, error bars, or controls (e.g., random-vector replacement or magnitude-agnostic baseline). Without these data the necessity of the specific Plucker reciprocal-product term versus generic additive capacity cannot be assessed.
- [Method (RayPE formulation)] The geometric term is derived from the external Plucker identity rather than optimized against the video-quality metric; the learned gate is a small additional parameter. The manuscript must demonstrate that this algebraic form (rather than any low-parameter additive branch) is responsible for the reported gains, e.g., via an ablation that replaces the reciprocal product with an unstructured modulation of identical dimensionality.
minor comments (2)
- [Implementation details] Clarify the exact initialization and training schedule for the learned gate function of log-magnitude so that readers can reproduce the zero-initialized starting point.
- [Experiments] The four-dataset mixture is mentioned but its composition, camera-scale statistics, and per-dataset metric breakdowns are not summarized; a table would help evaluate robustness across SfM, deep SLAM, and metric regimes.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. The comments highlight the need for stronger quantitative substantiation of our experimental claims, which we will address through targeted revisions and additional ablations. Below we respond point by point.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'our experiments find [the four terms] individually necessary' and that the module improves camera controllability, 3D consistency, and video quality rests on an assertion with no accompanying quantitative tables, ablation numbers, error bars, or controls (e.g., random-vector replacement or magnitude-agnostic baseline). Without these data the necessity of the specific Plucker reciprocal-product term versus generic additive capacity cannot be assessed.
Authors: We agree that the abstract's summary of the experimental findings would be strengthened by explicit reference to quantitative results. The current manuscript presents ablation studies on the four terms, but we acknowledge the absence of consolidated tables with error bars and controls such as random-vector replacements in the provided sections. In the revision we will add these tables to the main text (and update the abstract to reference them), enabling direct assessment of whether the Plucker term outperforms generic additive capacity. revision: yes
-
Referee: [Method (RayPE formulation)] The geometric term is derived from the external Plucker identity rather than optimized against the video-quality metric; the learned gate is a small additional parameter. The manuscript must demonstrate that this algebraic form (rather than any low-parameter additive branch) is responsible for the reported gains, e.g., via an ablation that replaces the reciprocal product with an unstructured modulation of identical dimensionality.
Authors: We accept that an ablation isolating the algebraic form of the reciprocal product is necessary to rule out generic low-parameter effects. While the Plucker identity supplies the bilinear geometry term that aligns with attention, we will implement the suggested control—replacing the reciprocal product with an unstructured modulation of matching dimensionality—and report the comparative results (including effects on controllability and consistency metrics) in the revised manuscript. revision: yes
Circularity Check
No circularity: geometric term derived from external Plucker identity; attention decomposition follows directly from additive injection
full rationale
The paper's core construction starts from the external algebraic fact that the Plucker reciprocal product is bilinear in ray coordinates (identical in form to the dot product), then defines an additive Q/K injection with a flip symmetry so the geometry term appears explicitly in the decomposed attention score. This decomposition is a direct algebraic consequence of the chosen injection and does not presuppose the target video-quality metric or any fitted result. The log-magnitude gate and RMSNorm are additional learned components whose necessity is asserted via experiment rather than by definition. No self-citation is load-bearing for the central claim, no parameter is fitted to the evaluation metric and then relabeled as a prediction, and no uniqueness theorem or ansatz is smuggled from prior author work. The reported gains therefore rest on empirical verification rather than reducing to the inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- learned gate function of log-magnitude
axioms (2)
- standard math The Plucker reciprocal product is bilinear in the two rays and therefore compatible with the algebraic form of scaled dot-product attention.
- domain assumption Heterogeneous camera-translation scales in SfM, deep SLAM, and metric data require explicit decoupling of direction from moment magnitude.
Reference graph
Works this paper leans on
-
[1]
Ac3d: Analyzing and improving 3d camera control in video diffusion trans- formers
Sherwin Bahmani, Ivan Skorokhodov, Guocheng Qian, Ali- aksandr Siarohin, Willi Menapace, Andrea Tagliasacchi, David B Lindell, and Sergey Tulyakov. Ac3d: Analyzing and improving 3d camera control in video diffusion trans- formers. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 22875–22889, 2025. 3
2025
-
[2]
Vd3d: Taming large video diffusion transformers for 3d camera control
Sherwin Bahmani, Ivan Skorokhodov, Aliaksandr Siaro- hin, Willi Menapace, Guocheng Qian, Michael Vasilkovsky, Hsin-Ying Lee, Chaoyang Wang, Jiaxu Zou, Andrea Tagliasacchi, et al. Vd3d: Taming large video diffusion transformers for 3d camera control. InInternational Con- ference on Learning Representations, pages 66712–66737,
-
[3]
ReCamMaster: Camera-controlled gen- erative rendering from a single video
Jianhong Bai, Menghan Xia, Xiao Fu, Xintao Wang, Lianrui Mu, Jinwen Cao, Zuozhu Liu, Haoji Hu, Xiang Bai, Pengfei Wan, and Di Zhang. ReCamMaster: Camera-controlled gen- erative rendering from a single video. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025. arXiv:2503.11647. 2, 3, 6, 7, 8, 9, 14
-
[4]
Weikang Bian, Zhaoyang Huang, Xiaoyu Shi, Yijin Li, Fu- Yun Wang, and Hongsheng Li. GS-DiT: Advancing video generation with pseudo 4D gaussian fields through efficient dense 3D point tracking. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025. arXiv:2501.02690. 3
-
[5]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023. 1, 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Simultaneous local- ization and mapping: part i.IEEE robotics & automation magazine, 13(2):99–110, 2006
Hugh Durrant-Whyte and Tim Bailey. Simultaneous local- ization and mapping: part i.IEEE robotics & automation magazine, 13(2):99–110, 2006. 2, 5
2006
-
[7]
Scaling rectified flow trans- formers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas M ¨uller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, Dustin Podell, Tim Dockhorn, Zion English, Kyle Lacey, Alex Goodwin, Yannik Marek, and Robin Rombach. Scaling rectified flow trans- formers for high-resolution image synthesis. InProceed- ings of the Internati...
2024
-
[8]
Diffusion as shader: 3d-aware video diffusion for ver- satile video generation control
Zekai Gu, Rui Yan, Jiahao Lu, Peng Li, Zhiyang Dou, Chenyang Si, Zhen Dong, Qifeng Liu, Cheng Lin, Ziwei Liu, et al. Diffusion as shader: 3d-aware video diffusion for ver- satile video generation control. InProceedings of the Special Interest Group on Computer Graphics and Interactive Tech- niques Conference Conference Papers, pages 1–12, 2025. 3
2025
-
[9]
Cambridge University Press, 2 edition, 2004
Richard Hartley and Andrew Zisserman.Multiple View Ge- ometry in Computer Vision. Cambridge University Press, 2 edition, 2004. 4, 13
2004
-
[10]
Cameractrl: En- abling camera control for video diffusion models
Hao He, Yinghao Xu, Yuwei Guo, Gordon Wetzstein, Bo Dai, Hongsheng Li, and Ceyuan Yang. Cameractrl: En- abling camera control for video diffusion models. InThe Thirteenth International Conference on Learning Represen- tations, 2025. 2, 3, 6, 7
2025
-
[11]
Query-key normalization for transformers
Alex Henry, Prudhvi Raj Dachapally, Shubham Shantaram Pawar, and Yuxuan Chen. Query-key normalization for transformers. InFindings of the Association for Computa- tional Linguistics: EMNLP 2020, 2020. 2, 3
2020
-
[12]
Rotary position embedding for vision transformer
Byeongho Heo, Song Park, Dongyoon Han, and Sangdoo Yun. Rotary position embedding for vision transformer. In European Conference on Computer Vision (ECCV), 2024. 1, 3
2024
-
[13]
Denoising dif- fusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising dif- fusion probabilistic models. InAdvances in Neural Informa- tion Processing Systems (NeurIPS), 2020. 3
2020
-
[14]
Jonathan Ho, Tim Salimans, Alexey Gritsenko, William Chan, Mohammad Norouzi, and David J. Fleet. Video diffu- sion models. InAdvances in Neural Information Processing Systems (NeurIPS), 2022. 1
2022
-
[15]
ViPE: Video Pose Engine for 3D Geometric Perception
Jiahui Huang, Qunjie Zhou, Hesam Rabeti, Aleksandr Ko- rovko, Huan Ling, Xuanchi Ren, Tianchang Shen, Jun Gao, Dmitry Slepichev, Chen-Hsuan Lin, et al. Vipe: Video pose engine for 3d geometric perception.arXiv preprint arXiv:2508.10934, 2025. 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, et al. Hunyuan- Video: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603, 2024. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
ReRoPE: Repurposing RoPE for relative camera control.arXiv preprint arXiv:2602.08068, 2026
Chunyang Li, Yuanbo Yang, Jiahao Shao, Hongyu Zhou, Katja Schwarz, and Yiyi Liao. ReRoPE: Repurpos- ing RoPE for relative camera control.arXiv preprint arXiv:2602.08068, 2026. 2, 3, 6, 7, 14
-
[18]
Cameras as relative positional encoding.arXiv preprint arXiv:2507.10496, 2025
Ruilong Li, Brent Yi, Junchen Liu, Hang Gao, Yi Ma, and Angjoo Kanazawa. Cameras as relative positional encod- ing. InAdvances in Neural Information Processing Systems (NeurIPS), 2025. Introduces PROPE (Projective Positional Encoding) for multi-view transformers; arXiv:2507.10496. 2, 3, 6
-
[19]
Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision
Lu Ling, Yichen Sheng, Zhi Tu, Wentian Zhao, Cheng Xin, Kun Wan, Lantao Yu, Qianyu Guo, Zixun Yu, Yawen Lu, et al. Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition,
-
[20]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maxim- ilian Nickel, and Matthew Le. Flow matching for generative modeling. InInternational Conference on Learning Repre- sentations (ICLR), 2023. 3
2023
-
[21]
Jiahao Lu, Weitao Xiong, Jiacheng Deng, Peng Li, Tianyu Huang, Zhiyang Dou, Cheng Lin, Sai-Kit Yeung, and Yuan Liu. Trackingworld: World-centric monocular 3d tracking of almost all pixels.arXiv preprint arXiv:2512.08358, 2025. 3
-
[22]
Jiahao Lu, Jiayi Xu, Wenbo Hu, Ruijie Zhu, Chengfeng Zhao, Sai-Kit Yeung, Ying Shan, and Yuan Liu. Track4world: Feedforward world-centric dense 3d tracking of all pixels.arXiv preprint arXiv:2603.02573, 2026. 3
-
[23]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF Interna- tional Conference on Computer Vision (ICCV), 2023. 2 11
2023
-
[24]
Movie Gen: A Cast of Media Foundation Models
Adam Polyak, Amit Zohar, Andrew Brown, Andros Tjandra, Animesh Sinha, et al. Movie Gen: A cast of media founda- tion models.arXiv preprint arXiv:2410.13720, 2024. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Springer, 2001
Helmut Pottmann and Johannes Wallner.Computational Line Geometry. Springer, 2001. 4, 13
2001
-
[26]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022. 2
2022
-
[27]
Structure-from-motion revisited
Johannes Lutz Sch ¨onberger and Jan-Michael Frahm. Structure-from-motion revisited. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2016. 2, 5, 14
2016
-
[28]
RoFormer: Enhanced Transformer with Rotary Position Embedding
Jianlin Su, Yu Lu, Shengfeng Pan, Ahmed Murtadha, Bo Wen, and Yunfeng Liu. RoFormer: Enhanced trans- former with rotary position embedding.arXiv preprint arXiv:2104.09864, 2021. 1, 3
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[29]
DROID-SLAM: Deep visual SLAM for monocular, stereo, and RGB-D cameras
Zachary Teed and Jia Deng. DROID-SLAM: Deep visual SLAM for monocular, stereo, and RGB-D cameras. InAd- vances in Neural Information Processing Systems (NeurIPS),
-
[30]
FVD: A new metric for video generation
Thomas Unterthiner, Sjoerd van Steenkiste, Karol Kurach, Raphael Marinier, Marcin Michalski, and Sylvain Gelly. FVD: A new metric for video generation. InICLR Workshop on Deep Generative Models for Highly Structured Data,
-
[31]
Gomez, Łukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Information Processing Systems (NeurIPS), 2017. 3
2017
-
[32]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video gen- erative models.arXiv preprint arXiv:2503.20314, 2025. 1, 2, 3, 6, 15
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
MotionCtrl: A unified and flexible motion controller for video generation
Zhouxia Wang, Ziyang Yuan, Xintao Wang, Yaowei Li, Tianshui Chen, Menghan Xia, Ping Luo, and Ying Shan. MotionCtrl: A unified and flexible motion controller for video generation. InACM SIGGRAPH 2024 Conference Pa- pers, 2024. 2, 3
2024
-
[34]
Spatialtracker: Tracking any 2d pixels in 3d space
Yuxi Xiao, Qianqian Wang, Shangzhan Zhang, Nan Xue, Sida Peng, Yujun Shen, and Xiaowei Zhou. Spatialtracker: Tracking any 2d pixels in 3d space. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20406–20417, 2024. 3
2024
-
[35]
Spatialtrackerv2: 3d point tracking made easy.arXiv preprint arXiv:2507.12462, 2025
Yuxi Xiao, Jianyuan Wang, Nan Xue, Nikita Karaev, Yuri Makarov, Bingyi Kang, Xing Zhu, Hujun Bao, Yujun Shen, and Xiaowei Zhou. Spatialtrackerv2: 3d point tracking made easy.arXiv preprint arXiv:2507.12462, 2025. 3
-
[36]
CamCo: Camera-Controllable 3D-Consistent Image-to-Video Generation
Dejia Xu, Weili Nie, Chao Liu, Sifei Liu, Jan Kautz, Zhangyang Wang, and Arash Vahdat. CamCo: Camera- controllable 3D-consistent image-to-video generation.arXiv preprint arXiv:2406.02509, 2024. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
Cogvideox: Text-to-video diffusion models with an expert transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiao- han Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer. InInternational Conference on Learning Representations, 2025. 1, 2, 3
2025
-
[38]
ViewCrafter: Taming Video Diffusion Models for High-fidelity Novel View Synthesis
Wangbo Yu, Jinbo Xing, Li Yuan, Wenbo Hu, Xiaoyu Li, Zhiber Huang, Xiang Gao, Xiaogang Luo, Ying Shan, and Yonghong Tian. ViewCrafter: Taming video diffusion mod- els for high-fidelity novel view synthesis. InAdvances in Neural Information Processing Systems (NeurIPS), 2024. arXiv:2409.02048. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
Tra- jectoryCrafter: Redirecting camera trajectory for monoc- ular videos via diffusion models
Wangbo Yu, Wenbo Hu, Jinbo Xing, and Ying Shan. Tra- jectoryCrafter: Redirecting camera trajectory for monoc- ular videos via diffusion models. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025. 2, 3
2025
-
[40]
Root mean square layer nor- malization.Advances in neural information processing sys- tems, 32, 2019
Biao Zhang and Rico Sennrich. Root mean square layer nor- malization.Advances in neural information processing sys- tems, 32, 2019. 2
2019
-
[41]
Tapip3d: Tracking any point in persistent 3d geome- try.Advances in Neural Information Processing Systems, 38: 135284–135303, 2026
Bowei Zhang, Lei Ke, Adam Harley, and Katerina Fragki- adaki. Tapip3d: Tracking any point in persistent 3d geome- try.Advances in Neural Information Processing Systems, 38: 135284–135303, 2026. 3
2026
-
[42]
Uni- fied camera positional encoding for controlled video gen- eration
Cheng Zhang, Boying Li, Meng Wei, Yan-Pei Cao, Camilo Cruz Gambardella, Dinh Phung, and Jianfei Cai. Uni- fied camera positional encoding for controlled video gen- eration. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026. arXiv:2512.07237. 2, 3, 6, 7, 8, 9, 14
-
[43]
Stereo magnification: Learning view syn- thesis using multiplane images
Tinghui Zhou, Richard Tucker, John Flynn, Graham Fyffe, and Noah Snavely. Stereo magnification: Learning view syn- thesis using multiplane images. InACM SIGGRAPH, 2018. 2, 7, 14
2018
-
[44]
Yang Zhou, Yifan Wang, Jianjun Zhou, Wenzheng Chang, Haoyu Guo, Zizun Li, Kaijing Ma, Xinyue Li, Yating Wang, Haoyi Zhu, Mingyu Liu, Dingning Liu, Jiange Yang, Zhou- jie Fu, Junyi Chen, Chunhua Shen, Jiangmiao Pang, Kaipeng Zhang, and Tong He. Omniworld: A multi-domain and multi-modal dataset for 4d world modeling.arXiv preprint arXiv:2509.12201, 2025. 2,...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.