SEVA: Self-Evolving Verification Agent with Process Reward for Fact Attribution
Pith reviewed 2026-06-30 06:37 UTC · model grok-4.3
The pith
Process rewards matching output granularity let a 3B model match GPT-4o-mini on fact attribution while producing auditable chains.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
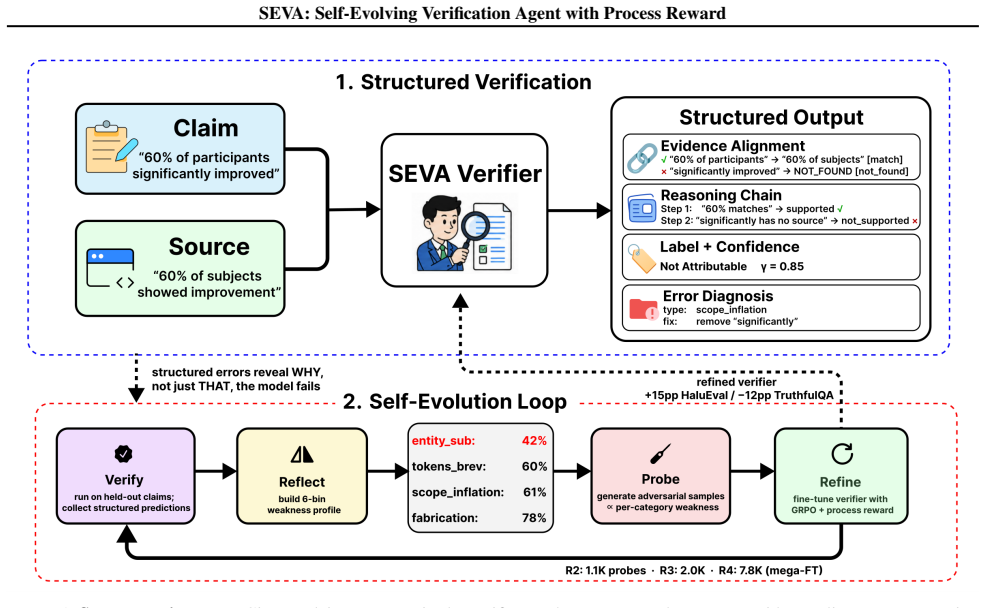
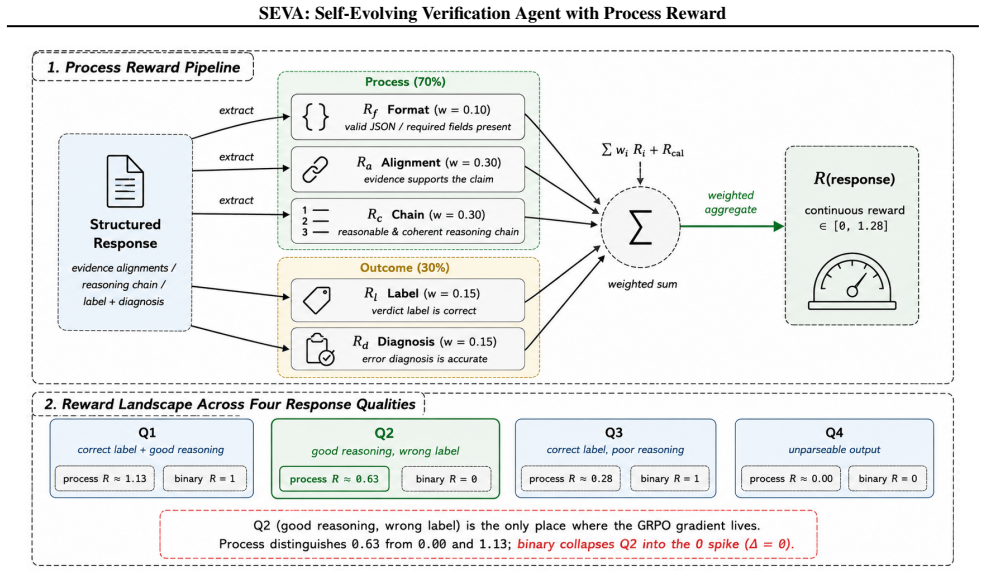
SEVA trains a verification agent with a process reward that decomposes quality into five components weighted 70/30 toward process signals. This prevents advantage collapse, induces a curriculum where behavior is mastered before outcomes, and powers four rounds of self-evolution that turn the model into a benchmark specialist. The 3B SEVA reaches 69.0 F1 on ClearFacts while matching GPT-4o-mini accuracy and emitting evidence alignments, reasoning chains, calibrated confidence, and six-category error diagnoses with fixes.
What carries the argument
The process reward that decomposes verification quality into five independent components weighted 70/30 toward process signals.
If this is right
- The agent first masters verification behavior such as alignment and format before outcome accuracy improves.
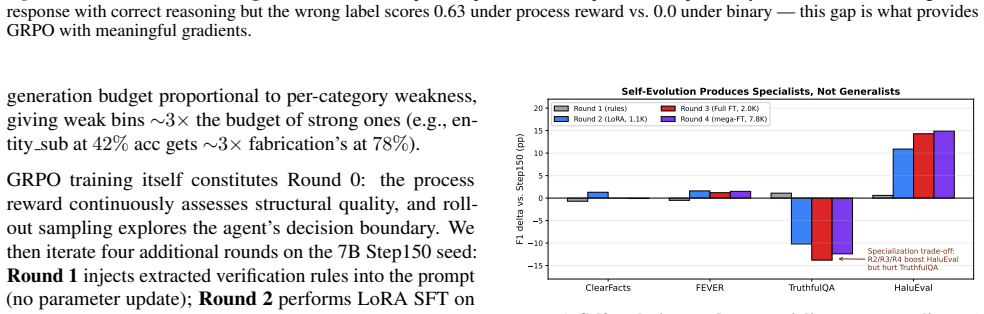
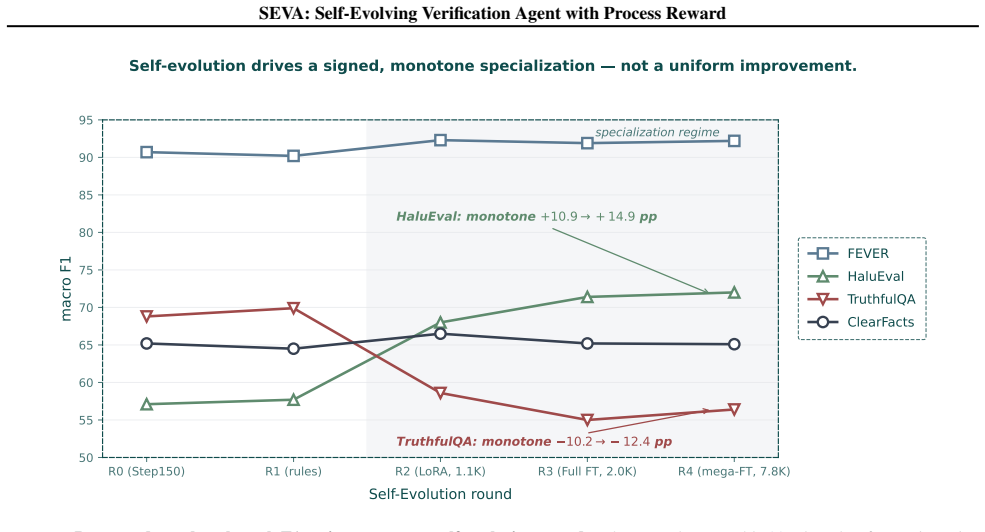
- Four rounds of self-evolution produce a benchmark specialist rather than a generalist, with large gains on one dataset and losses on others.
- Structured output enables the Verify-Reflect-Probe-Refine loop that drives further gains without external data.
- SEVA-3B matches GPT-4o-mini F1 on ClearFacts while emitting substantially richer and auditable attributions.
Where Pith is reading between the lines
- The same requirement that reward granularity match output granularity could apply to RL training of other multi-component generation tasks such as step-by-step reasoning or planning.
- Persistent specialization across data scales suggests that mixing benchmarks during the evolution loop may be required for broader generalization.
- The five-component breakdown may identify which verification skills are hardest to acquire and therefore most in need of targeted process signals.
Load-bearing premise
Verification quality decomposes into five independent components whose specific weighting does not itself produce the curriculum or benchmark specialization.
What would settle it
Retraining SEVA with a changed weighting ratio or fewer components and finding that the curriculum order, specialist pattern, or final F1 shifts exactly in line with the new weights rather than verification quality would falsify the claim.
Figures


read the original abstract
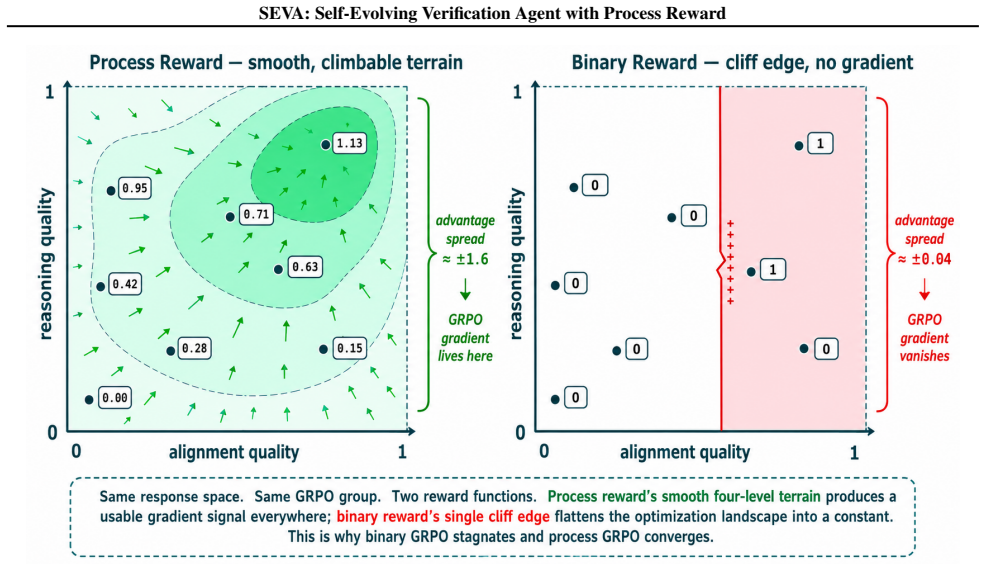
Hallucination is the reliability bottleneck for LLM-based agents, and fact attribution verifiers are the last line of defense -- yet today's verifiers emit only opaque binary labels, leaving agents unable to self-correct and operators unable to audit. We present SEVA, a structured verification agent that emits evidence alignments, step-by-step reasoning chains, calibrated confidence, and a six-category error diagnosis with actionable fixes. Training such an agent with RL is non-trivial: standard binary reward on multi-component output triggers advantage collapse -- within-group reward variance vanishes and the GRPO gradient disappears. We resolve this with a process reward that decomposes verification quality into five independent components weighted 70/30 toward process signals, restoring the gradient and inducing an implicit curriculum -- the agent first masters verification behavior (alignment 0.917 -> 0.997, format 72% -> 100%), then outcomes (F1 64.9 -> 69.0). Structured output further enables a Verify -> Reflect -> Probe -> Refine self-evolution loop, which over four rounds on a 7B model surfaces an unexpected structural finding: each round produces a benchmark-specialist, not a generalist (+15 pp on HaluEval, -10 to -14 pp on TruthfulQA in the same model, persistent at 4x data). On ClearFacts, SEVA-3B matches GPT-4o-mini (69.0 vs. 69.8 F1) while producing substantially richer, auditable output -- confirming a principle that should generalize: for any RL task with multi-component generation, reward granularity must match output granularity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SEVA, a structured fact-attribution verification agent that outputs evidence alignments, reasoning chains, confidence scores, and error diagnoses. It argues that binary outcome rewards on multi-component outputs cause advantage collapse under GRPO, which is resolved by a five-component process reward weighted 70/30 toward process signals; this restores gradients, produces an implicit curriculum (process metrics improve before outcomes), and enables a Verify-Reflect-Probe-Refine self-evolution loop. Over four rounds the loop yields benchmark-specialist models rather than generalists, with SEVA-3B matching GPT-4o-mini (69.0 vs. 69.8 F1) on ClearFacts while providing richer, auditable output. The authors conclude that reward granularity must match output granularity for any multi-component RL generation task.
Significance. If the empirical results and the claimed causal role of the process reward hold after proper controls, the work would supply a concrete training recipe for auditable verification agents and a general design principle for RL on structured outputs. The self-evolution loop and the observed specialization effect are potentially high-impact observations for agent reliability research.
major comments (3)
- [Abstract] Abstract: the claim that the five verification components are independent and that the fixed 70/30 process weighting (rather than the decomposition itself) restores the GRPO gradient and induces the observed curriculum is load-bearing for the central methodological contribution, yet no ablation on alternative weightings, on a binary-reward control beyond the initial statement, or on component interdependence is reported.
- [Abstract] Abstract: performance numbers (SEVA-3B at 69.0 F1 matching GPT-4o-mini at 69.8 F1 on ClearFacts; +15 pp on HaluEval and -10 to -14 pp on TruthfulQA after self-evolution) are presented without any description of baselines, number of runs, statistical tests, data splits, or variance, rendering the quantitative claims unverifiable from the given text.
- [Abstract] Abstract: the assertion that binary outcome reward triggers advantage collapse while the process reward restores it is central to the motivation, but the manuscript provides no quantitative evidence (e.g., gradient norms, advantage variance before/after) that the collapse is avoided specifically by the 70/30 weighting rather than by other training choices.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments on the abstract. We address each major point below. Where the current manuscript lacks reported ablations or quantitative diagnostics, we agree that revisions are needed to strengthen the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the five verification components are independent and that the fixed 70/30 process weighting (rather than the decomposition itself) restores the GRPO gradient and induces the observed curriculum is load-bearing for the central methodological contribution, yet no ablation on alternative weightings, on a binary-reward control beyond the initial statement, or on component interdependence is reported.
Authors: We agree that the independence of the five components and the specific 70/30 weighting are central claims that require stronger empirical support. The manuscript currently relies on the observed training dynamics and the final performance but does not report systematic ablations on alternative weightings or component correlations. In the revised version we will add an ablation section comparing the 70/30 weighting against uniform weighting, 50/50, and 90/10 variants, plus a direct binary-reward control with the same decomposition, reporting effects on advantage variance, gradient norms, and the process-vs-outcome learning order. revision: yes
-
Referee: [Abstract] Abstract: performance numbers (SEVA-3B at 69.0 F1 matching GPT-4o-mini at 69.8 F1 on ClearFacts; +15 pp on HaluEval and -10 to -14 pp on TruthfulQA after self-evolution) are presented without any description of baselines, number of runs, statistical tests, data splits, or variance, rendering the quantitative claims unverifiable from the given text.
Authors: The experimental section provides the full evaluation protocol, including the ClearFacts, HaluEval, and TruthfulQA splits, the GPT-4o-mini baseline, and the self-evolution procedure. However, the abstract itself omits this context. We will revise the abstract to include a concise statement of the evaluation setup (single reported run per model size, standard data splits, and reference to variance reported in the main text) while keeping the abstract length appropriate. revision: partial
-
Referee: [Abstract] Abstract: the assertion that binary outcome reward triggers advantage collapse while the process reward restores it is central to the motivation, but the manuscript provides no quantitative evidence (e.g., gradient norms, advantage variance before/after) that the collapse is avoided specifically by the 70/30 weighting rather than by other training choices.
Authors: The advantage-collapse observation is based on training runs in which binary rewards produced near-zero within-group advantage variance, causing the GRPO policy gradient to vanish. The current manuscript describes this qualitatively but does not include the requested diagnostic plots. We will add a new figure and accompanying analysis in the methods or experiments section showing advantage variance and gradient-norm trajectories for the binary-reward baseline versus the 70/30 process-reward setting, thereby providing the quantitative evidence requested. revision: yes
Circularity Check
No circularity: empirical RL results with design choices, no derivations or self-referential reductions.
full rationale
The paper presents an empirical RL training procedure for a verification agent using a hand-designed process reward (five components, 70/30 weighting) and reports benchmark outcomes on ClearFacts, HaluEval, and TruthfulQA. No equations, derivations, or mathematical claims appear in the provided text. The central results are direct performance measurements after training; they do not reduce to fitted parameters renamed as predictions, self-citations that bear the load of uniqueness, or any self-definitional loop. The weighting and component decomposition are explicit design decisions whose effects are measured externally on held-out benchmarks, satisfying the criterion for a self-contained empirical study.
Axiom & Free-Parameter Ledger
free parameters (1)
- process reward weighting =
70/30
Reference graph
Works this paper leans on
-
[1]
Quantifying the Carbon Emissions of Machine Learning
Lacoste, A., Luccioni, A., Schmidt, V ., and Dandres, T. Quantifying the carbon emissions of machine learning. arXiv preprint arXiv:1910.09700,
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[2]
MARCH: Multi-agent reinforced self-check for LLM hallucination
Li, Z., Zhang, Y ., Cheng, P., Song, J., Zhou, M., Li, H., Hu, S., Qin, Y ., Zhao, E., Jiang, X., and Jiang, G. MARCH: Multi-agent reinforced self-check for LLM hallucination. arXiv preprint arXiv:2603.24579,
-
[3]
Qwen Team. Qwen2.5 technical report.arXiv preprint arXiv:2412.15115,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
arXiv preprint arXiv:2506.13342. Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y ., Wu, Y ., and Guo, D. DeepSeek- Math: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
-
[5]
HybridFlow: A Flexible and Efficient RLHF Framework
arXiv preprint arXiv:2409.19256. Strubell, E., Ganesh, A., and McCallum, A. Energy and policy considerations for deep learning in NLP. InPro- ceedings of ACL,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Thorne, J., Vlachos, A., Christodoulopoulos, C., and Mittal, A
arXiv preprint arXiv:2404.10774. Thorne, J., Vlachos, A., Christodoulopoulos, C., and Mittal, A. FEVER: A large-scale dataset for fact extraction and VERification. InProceedings of NAACL-HLT,
- [7]
-
[8]
Zha, Y ., Yang, Y ., Li, R., and Hu, Z
arXiv preprint arXiv:2505.15034. Zha, Y ., Yang, Y ., Li, R., and Hu, Z. AlignScore: Evaluating factual consistency with a unified alignment function. In Proceedings of ACL,
-
[9]
GRPO Hyperparameters A.4
Algorithm GRPO Base model SEVA-SFT (3B) Group size (G) 8 Temperature 1.2 Top-p0.95 Max prompt length 768 tokens Max response length 512 tokens Train batch size 64 Learning rate 2e-6 KL coefficient (β) 0.001 Epochs 5 (∼350 steps) Parallelism FSDP (tp=1, dp=2) Reward functionseva reward.py A.3. GRPO Hyperparameters A.4. Inference Configuration Table 10.Infe...
2025
-
[10]
Not Attributable
The contrast is geometric: process reward is climbable, binary reward is a constant punctuated by a cliff. F. Adversarial Data Generation The self-evolution loop (§2.5) uses six targeted perturba- tion strategies to generate adversarial examples. Each strat- egy creates “Not Attributable” examples from “Attributable” pairs by applying controlled modificat...
2007
-
[11]
reduced mortality by 30%
— advantage spread ≈ ±0.04, the GRPO gradient vanishes almost everywhere. GRPO output (complete structured) Same input as above. evidence alignment: [{claim: "reduced mortality by 30%", source: "decreased death rates by approximately one-third", status: "match"}] reasoning chain: [{part: "reduced mortality by 30%", evidence: "decreased death rates by appr...
2004
-
[12]
The policy was implemented to reduce emissions
The asymmetry is therefore not a calibration drift that more data corrects; it is a stable property of the probe distribution itself. Second, the per-round winners differ: Round 2 dominates CF and FEVER, Round 4 dominates HE, while Step150 (no specialization) wins TQA. No single round Pareto-dominates the others on every benchmark — a precondition for any...
1928
-
[13]
flat” rather than “small win
is far larger than the seed standard deviation, so the asymmetry holds under all three seeds we tested. Round-to-round movement on CF/FEVER (within ±2 pp) sits closer to the seed noise band and should be read as “flat” rather than “small win.” P. Ethics, Bias, and Broader Impact A verifier is, by construction, a power that decides which model outputs the ...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.