PPLLaVA: Varied Video Sequence Understanding With Prompt Guidance
Pith reviewed 2026-05-23 17:29 UTC · model grok-4.3
The pith
PPLLaVA reduces video tokens by up to 18 times using prompt-guided pooling while achieving state-of-the-art results on video understanding benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
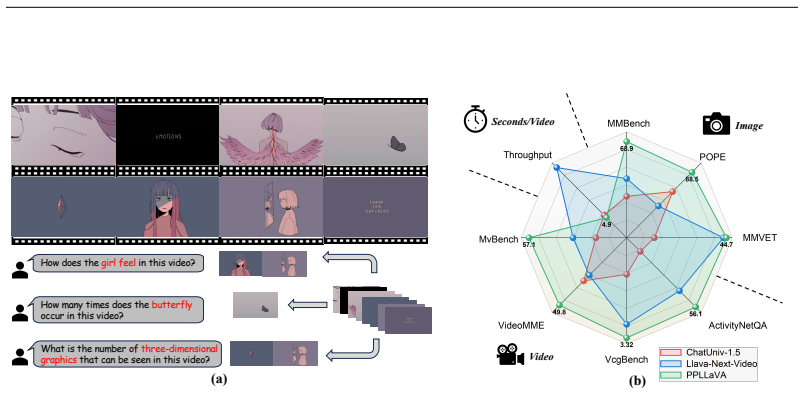
PPLLaVA proposes a novel pooling strategy for video LLMs that employs a CLIP-based visual-prompt alignment module to identify regions of interest from user instructions, followed by a prompt-guided pooling mechanism that adaptively compresses the visual sequence using convolution-style pooling, plus a clip context extension module for complex prompts; this yields up to 18x token reduction while maintaining strong performance and setting new state-of-the-art results across captioning, QA, and long-form reasoning benchmarks.
What carries the argument
Prompt-guided pooling mechanism that adaptively compresses visual tokens via convolution-style operations after CLIP-based alignment to user instructions.
If this is right
- Video LLMs become practical for longer sequences without proportional increases in compute.
- Inference speed improves substantially due to fewer visual tokens processed.
- The same compression works across image-to-video and long video reasoning tasks without task-specific retraining.
- Complex multi-turn visual dialogues remain feasible because the context extension module handles extended prompts.
Where Pith is reading between the lines
- The alignment-plus-pooling pattern could transfer to other sequence-heavy multimodal tasks such as audio or 3D data.
- If the CLIP alignment step is replaced with a stronger vision encoder, compression ratios might increase further without accuracy trade-offs.
- Downstream applications like real-time video chat would see the largest latency gains from the throughput improvement.
Load-bearing premise
The CLIP-based alignment module correctly identifies instruction-relevant regions and the subsequent pooling retains those semantics without critical loss even at high compression rates.
What would settle it
A direct comparison on a standard video QA benchmark where performance at 18x token reduction falls measurably below an uncompressed baseline model on the same architecture.
Figures





read the original abstract
In the past year, video-based large language models (Video LLMs) have achieved impressive progress, particularly in their ability to process long videos through extremely extended context lengths. However, this comes at the cost of significantly increased computational overhead due to the massive number of visual tokens, making efficiency a major bottleneck. In this paper, we identify the root of this inefficiency as the high redundancy in video content. To address this, we propose a novel pooling strategy that enables aggressive token compression while retaining instruction-relevant visual semantics. Our model, Prompt-guided Pooling LLaVA (PPLLaVA), introduces three key components: a CLIP-based visual-prompt alignment module that identifies regions of interest based on user instructions, a prompt-guided pooling mechanism that adaptively compresses the visual sequence using convolution-style pooling, and a clip context extension module tailored for processing long and complex prompts in visual dialogues. With up to 18x token reduction, PPLLaVA maintains strong performance across tasks, achieving state-of-the-art results on diverse video understanding benchmarks-ranging from image-to-video tasks such as captioning and QA to long-form video reasoning-while significantly improving inference throughput. Codes have been available at https://github.com/farewellthree/PPLLaVA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PPLLaVA, a video LLM architecture that adds three components to address visual token redundancy: a CLIP-based visual-prompt alignment module to identify instruction-relevant regions, a prompt-guided pooling mechanism (convolution-style) for adaptive compression of the visual sequence, and a clip context extension module for long prompts. It reports up to 18x token reduction while preserving performance, achieving SOTA results on image-to-video captioning/QA and long-form video reasoning benchmarks, plus higher inference throughput. Code is released.
Significance. If the reported results hold, the work provides a practical, instruction-aware compression technique that directly mitigates the quadratic cost of long video contexts in Video LLMs without requiring architectural overhauls. The public code and ablation studies on compression ratios, throughput, and task performance are concrete strengths that support reproducibility and allow direct verification of the central efficiency claim.
minor comments (3)
- §4 (Experiments): the main results tables would benefit from explicit column headers indicating whether reported numbers are zero-shot or fine-tuned, and from a single consolidated baseline row that includes the unmodified LLaVA-Video or Video-LLaMA numbers for direct comparison.
- §3.2 (Prompt-guided Pooling): the description of the convolution-style pooling kernel size and stride selection is given only in the implementation details; moving a short equation or pseudocode to the main text would clarify how the adaptive compression ratio is computed from the alignment scores.
- Figure 3 (qualitative examples): the prompt tokens shown in the visualization are truncated; including the full user instruction alongside the highlighted regions would make the alignment behavior easier to inspect.
Simulated Author's Rebuttal
We thank the referee for the positive summary of our work, the recognition of its practical significance for efficient video LLMs, and the recommendation for minor revision. We are pleased that the reproducibility aspects (public code and ablations) were noted as strengths.
Circularity Check
No significant circularity detected
full rationale
The paper presents an empirical architecture (PPLLaVA) consisting of a CLIP-based alignment module, prompt-guided pooling via convolution-style operations, and a context extension module. No mathematical derivations, equations, or parameter-fitting steps are described that reduce to self-definition or fitted inputs called predictions. Claims rest on benchmark tables, ablation studies, and throughput measurements rather than any load-bearing self-citation chain or uniqueness theorem. The contribution is therefore self-contained against external benchmarks and public code.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption CLIP model embeddings can reliably align textual prompts with relevant visual regions in video frames
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we propose a novel pooling strategy that enables aggressive token compression while retaining instruction-relevant visual semantics... CLIP-based visual-prompt alignment module that identifies regions of interest based on user instructions, a prompt-guided pooling mechanism that adaptively compresses the visual sequence using convolution-style pooling
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the attention score of the (tth, wth, hth) video token relative to the text feature is then calculated as: s(t,w,h) = exp(tau c · fclipv(v(t,w,h))) / sum exp(...)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 6 Pith papers
-
VISD: Enhancing Video Reasoning via Structured Self-Distillation
VISD improves VideoLLM reasoning performance and training efficiency by combining structured multi-dimensional self-distillation feedback with RL via direction-magnitude decoupling, curriculum scheduling, and EMA stab...
-
Thinking with Geometry: Active Geometry Integration for Spatial Reasoning
GeoThinker enables active, task-conditioned geometry integration in MLLMs via spatial-grounded fusion and importance gating, reaching 72.6 on VSI-Bench.
-
One Trajectory, One Token: Grounded Video Tokenization via Panoptic Sub-object Trajectory
TrajViT tokenizes videos via panoptic sub-object trajectories, achieving 10x token reduction and outperforming ViT3D by 6% on retrieval and 5.2% on VideoQA tasks with faster training and inference.
-
VISD: Enhancing Video Reasoning via Structured Self-Distillation
VISD improves VideoLLM reasoning by adding multi-dimensional diagnostic self-distillation and RL decoupling, yielding higher accuracy, better grounding, and nearly 2x faster training convergence.
-
VISD: Enhancing Video Reasoning via Structured Self-Distillation
VISD adds structured privileged feedback from a judge model and a direction-magnitude decoupling trick to let VideoLLMs learn token-level credit assignment while keeping RL stable, yielding higher accuracy and roughly...
-
VISD: Enhancing Video Reasoning via Structured Self-Distillation
VISD proposes structured self-distillation with a multi-dimensional judge model and direction-magnitude decoupling to improve token-level credit assignment and convergence speed in VideoLLM reasoning training.
Reference graph
Works this paper leans on
-
[1]
Tuning large multimodal models for videos using reinforcement learning from ai feedback
Daechul Ahn, Yura Choi, Youngjae Yu, Dongyeop Kang, and Jonghyun Choi. Tuning large multimodal models for videos using reinforcement learning from ai feedback. arXiv preprint arXiv:2402.03746,
-
[2]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A frontier large vision-language model with versatile abilities. arXiv preprint arXiv:2308.12966,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
How Far Are We to GPT-4V? Closing the Gap to Commercial Multimodal Models with Open-Source Suites
Zhe Chen, Weiyun Wang, Hao Tian, Shenglong Ye, Zhangwei Gao, Erfei Cui, Wenwen Tong, Kongzhi Hu, Jiapeng Luo, Zheng Ma, et al. How far are we to gpt-4v? closing the gap to commercial multimodal models with open-source suites. arXiv preprint arXiv:2404.16821,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Instructblip: towards general-purpose vision-language models with instruction tuning
W Dai, J Li, D Li, AMH Tiong, J Zhao, W Wang, B Li, P Fung, and S Hoi. Instructblip: towards general-purpose vision-language models with instruction tuning. arxiv. Preprint posted online on June, 15:2023,
work page 2023
-
[5]
Video-MME: The First-Ever Comprehensive Evaluation Benchmark of Multi-modal LLMs in Video Analysis
Chaoyou Fu, Yuhan Dai, Yondong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, et al. Video-mme: The first-ever comprehensive evalua- tion benchmark of multi-modal llms in video analysis. arXiv preprint arXiv:2405.21075,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Vtimellm: Empower llm to grasp video moments
Bin Huang, Xin Wang, Hong Chen, Zihan Song, and Wenwu Zhu. Vtimellm: Empower llm to grasp video moments. arXiv preprint arXiv:2311.18445,
-
[7]
Peng Jin, Ryuichi Takanobu, Caiwan Zhang, Xiaochun Cao, and Li Yuan. Chat-univi: Unified vi- sual representation empowers large language models with image and video understanding. arXiv preprint arXiv:2311.08046,
-
[8]
The Kinetics Human Action Video Dataset
Will Kay, Joao Carreira, Karen Simonyan, Brian Zhang, Chloe Hillier, Sudheendra Vijaya- narasimhan, Fabio Viola, Tim Green, Trevor Back, Paul Natsev, et al. The kinetics human action video dataset. arXiv preprint arXiv:1705.06950,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
LLaVA-NeXT-Interleave: Tackling Multi-image, Video, and 3D in Large Multimodal Models
Feng Li, Renrui Zhang, Hao Zhang, Yuanhan Zhang, Bo Li, Wei Li, Zejun Ma, and Chunyuan Li. Llava-next-interleave: Tackling multi-image, video, and 3d in large multimodal models. arXiv preprint arXiv:2407.07895,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language- image pre-training with frozen image encoders and large language models. arXiv preprint arXiv:2301.12597, 2023a. KunChang Li, Yinan He, Yi Wang, Yizhuo Li, Wenhai Wang, Ping Luo, Yali Wang, Limin Wang, and Yu Qiao. Videochat: Chat-centric video understanding. arXiv prep...
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. arXiv preprint arXiv:2304.08485, 2023a. Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion, pp. 26296–26306, 2024a. Haotian Liu, Ch...
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Valley: Video assistant with large language model enhanced ability.arXiv preprint arXiv:2306.07207,
Ruipu Luo, Ziwang Zhao, Min Yang, Junwei Dong, Minghui Qiu, Pengcheng Lu, Tao Wang, and Zhongyu Wei. Valley: Video assistant with large language model enhanced ability.arXiv preprint arXiv:2306.07207,
-
[13]
Video-ChatGPT: Towards Detailed Video Understanding via Large Vision and Language Models
Muhammad Maaz, Hanoona Rasheed, Salman Khan, and Fahad Shahbaz Khan. Video-chatgpt: Towards detailed video understanding via large vision and language models. arXiv preprint arXiv:2306.05424,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Disentangled representa- tion learning for text-video retrieval
Qiang Wang, Yanhao Zhang, Yun Zheng, Pan Pan, and Xian-Sheng Hua. Disentangled representa- tion learning for text-video retrieval. arXiv preprint arXiv:2203.07111,
-
[15]
PLLaVA : Parameter-free LLaVA Extension from Images to Videos for Video Dense Captioning
15 Lin Xu, Yilin Zhao, Daquan Zhou, Zhijie Lin, See Kiong Ng, and Jiashi Feng. Pllava: Parameter-free llava extension from images to videos for video dense captioning. arXiv preprint arXiv:2404.16994,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
xgen-mm (blip-3): A family of open large multimodal models
Le Xue, Manli Shu, Anas Awadalla, Jun Wang, An Yan, Senthil Purushwalkam, Honglu Zhou, Viraj Prabhu, Yutong Dai, Michael S Ryoo, et al. xgen-mm (blip-3): A family of open large multimodal models. arXiv preprint arXiv:2408.08872,
-
[17]
Cat: enhancing multimodal large language model to answer questions in dynamic audio-visual scenarios
Qilang Ye, Zitong Yu, Rui Shao, Xinyu Xie, Philip Torr, and Xiaochun Cao. Cat: enhancing multimodal large language model to answer questions in dynamic audio-visual scenarios. arXiv preprint arXiv:2403.04640,
-
[18]
CLEVRER: CoLlision Events for Video REpresentation and Reasoning
Kexin Yi, Chuang Gan, Yunzhu Li, Pushmeet Kohli, Jiajun Wu, Antonio Torralba, and Joshua B Tenenbaum. Clevrer: Collision events for video representation and reasoning. arXiv preprint arXiv:1910.01442,
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[19]
Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding
Hang Zhang, Xin Li, and Lidong Bing. Video-llama: An instruction-tuned audio-visual language model for video understanding. arXiv preprint arXiv:2306.02858,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Flash-vstream: Memory-based real-time understanding for long video streams
Haoji Zhang, Yiqin Wang, Yansong Tang, Yong Liu, Jiashi Feng, Jifeng Dai, and Xiaojie Jin. Flash-vstream: Memory-based real-time understanding for long video streams. arXiv preprint arXiv:2406.08085, 2024a. Ruohong Zhang, Liangke Gui, Zhiqing Sun, Yihao Feng, Keyang Xu, Yuanhan Zhang, Di Fu, Chun- yuan Li, Alexander Hauptmann, Yonatan Bisk, et al. Direct ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.