One Trajectory, One Token: Grounded Video Tokenization via Panoptic Sub-object Trajectory
Pith reviewed 2026-05-19 12:50 UTC · model grok-4.3
The pith
Videos tokenized by panoptic sub-object trajectories cut token count tenfold while improving retrieval and VideoQA accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
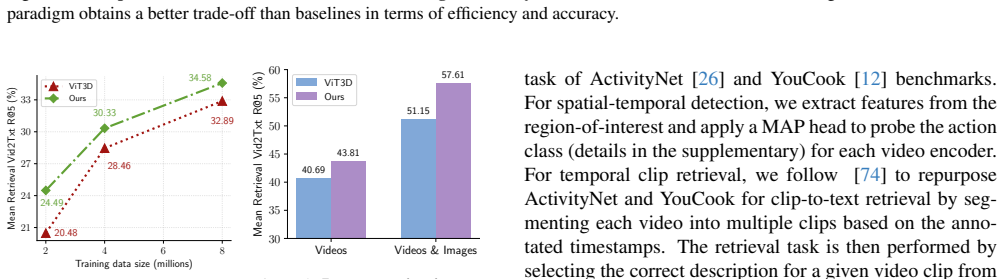
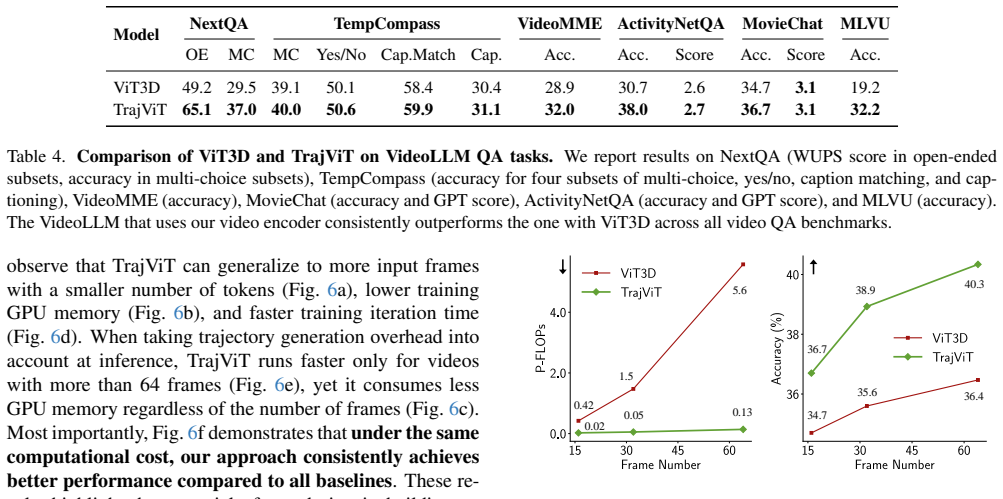
TrajViT extracts panoptic sub-object trajectories from video frames and converts each trajectory into a single semantically meaningful token. This strategy replaces uniform space-time patch tokenization with one that follows object motion and identity. Trained via contrastive learning, the model outperforms space-time ViT3D by 6 percent top-5 recall on average in video-text retrieval while using 10 times fewer tokens. When employed as the video encoder in modern VideoLLMs, it delivers an average 5.2 percent performance lift across six VideoQA benchmarks together with 4 times faster training and 18 times lower inference FLOPs.
What carries the argument
Panoptic sub-object trajectory, the continuous path of a semantic sub-object across frames that is encoded as exactly one token to capture its identity and motion.
If this is right
- Token count drops by a factor of ten on video-text retrieval while top-5 recall rises by 6 percent on average.
- VideoLLM training runs four times faster and inference uses eighteen times fewer FLOPs.
- Average performance improves by 5.2 percent across six VideoQA benchmarks when TrajViT serves as the video encoder.
- Tokenization now scales with scene complexity rather than raw video length.
Where Pith is reading between the lines
- The same trajectory principle could extend to other time-series data such as audio or motion capture where distinct entities move continuously.
- Robustness to moving cameras might increase because tokens track objects instead of remaining anchored to a static grid.
- Experiments on hour-long videos would test whether the efficiency advantage widens as patch-based methods scale linearly with duration.
Load-bearing premise
Reliable panoptic sub-object trajectories can be extracted from videos without introducing errors or biases that would degrade semantic and temporal information needed for downstream tasks.
What would settle it
If trajectory extraction errors on videos with frequent occlusions or rapid camera motion cause TrajViT to fall below ViT3D accuracy on retrieval or VideoQA benchmarks, the superiority claim would not hold.
Figures









read the original abstract
Effective video tokenization is critical for scaling transformer models for long videos. Current approaches tokenize videos using space-time patches, leading to excessive tokens and computational inefficiencies. The best token reduction strategies degrade performance and barely reduce the number of tokens when the camera moves. We introduce grounded video tokenization, a paradigm that organizes tokens based on panoptic sub-object trajectories rather than fixed patches. Our method aligns with fundamental perceptual principles, ensuring that tokenization reflects scene complexity rather than video duration. We propose TrajViT, a video encoder that extracts object trajectories and converts them into semantically meaningful tokens, significantly reducing redundancy while maintaining temporal coherence. Trained with contrastive learning, TrajViT significantly outperforms space-time ViT (ViT3D) across multiple video understanding benchmarks, e.g., TrajViT outperforms ViT3D by a large margin of 6% top-5 recall in average at video-text retrieval task with 10x token deduction. We also show TrajViT as a stronger model than ViT3D for being the video encoder for modern VideoLLM, obtaining an average of 5.2% performance improvement across 6 VideoQA benchmarks while having 4x faster training time and 18x less inference FLOPs. TrajViT is the first efficient encoder to consistently outperform ViT3D across diverse video analysis tasks, making it a robust and scalable solution.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces grounded video tokenization, which organizes video tokens around panoptic sub-object trajectories rather than fixed space-time patches. The proposed TrajViT encoder, trained with contrastive learning, is claimed to outperform a space-time ViT baseline (ViT3D) by 6% top-5 recall on video-text retrieval at 10x token reduction, deliver 5.2% average gains across six VideoQA benchmarks when used as a VideoLLM encoder, and provide 4x faster training with 18x lower inference FLOPs.
Significance. If the empirical margins prove robust, the approach could meaningfully advance efficient long-video modeling by aligning tokenization with scene complexity and perceptual principles, offering a practical route to lower redundancy in video transformers and VideoLLMs.
major comments (1)
- [Abstract / Experimental evaluation] The reported gains (6% retrieval, 5.2% VideoQA) are load-bearing on the claim that panoptic trajectory extraction remains reliable and information-preserving under camera motion, occlusion, and fast motion. The abstract notes that prior reduction methods fail precisely in these regimes, yet no ablation or quantitative assessment of extraction error rates or downstream sensitivity to missed/broken tracks is referenced in the provided summary.
minor comments (1)
- [Abstract] Clarify whether '10x token deduction' refers to a fixed reduction factor or an average; consistent terminology would aid comparison with prior token-reduction baselines.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the robustness of our trajectory extraction. We address the major comment below.
read point-by-point responses
-
Referee: [Abstract / Experimental evaluation] The reported gains (6% retrieval, 5.2% VideoQA) are load-bearing on the claim that panoptic trajectory extraction remains reliable and information-preserving under camera motion, occlusion, and fast motion. The abstract notes that prior reduction methods fail precisely in these regimes, yet no ablation or quantitative assessment of extraction error rates or downstream sensitivity to missed/broken tracks is referenced in the provided summary.
Authors: We agree that a direct quantitative assessment of extraction reliability under camera motion, occlusion, and fast motion would strengthen the validation of our claims. The full manuscript evaluates TrajViT on diverse benchmarks (e.g., MSR-VTT, ActivityNet, and VideoQA datasets) that contain substantial camera motion, occlusions, and rapid movements; the consistent 6% retrieval and 5.2% VideoQA gains over ViT3D indicate that trajectory-based tokenization preserves information more effectively than fixed patches in these regimes. However, we acknowledge the absence of a dedicated ablation on extraction error rates and sensitivity to missed or broken tracks. We will add this analysis in the revision, including metrics on track continuity and an ablation simulating track breaks to measure downstream impact. revision: yes
Circularity Check
No circularity; empirical method with independent benchmark comparisons
full rationale
The paper introduces a grounded video tokenization approach using panoptic sub-object trajectories and evaluates TrajViT empirically against ViT3D on retrieval and VideoQA tasks. Performance margins (e.g., 6% top-5 recall, 5.2% VideoQA gains) are presented as experimental outcomes from contrastive training, not as derivations that reduce to fitted inputs or self-citations by construction. No load-bearing equations, uniqueness theorems, or ansatzes are invoked that collapse to the method's own definitions. The central claims rest on observable benchmark differences rather than tautological re-labeling of inputs.
Axiom & Free-Parameter Ledger
invented entities (1)
-
TrajViT
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_add / embed_strictMono_of_one_lt (orbit structure under generator) echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
organizes tokens based on panoptic sub-object trajectories rather than fixed patches... Rooted in Spelke’s core cognitive principles and the Gestalt Principle of common fate
-
IndisputableMonolith/Foundation/ArrowOfTime.leanarrow_from_z (temporal order from monotonic accumulation) echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
TrajViT... extracts object trajectories and converts them into semantically meaningful tokens, significantly reducing redundancy while maintaining temporal coherence
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
TrajTok: Learning Trajectory Tokens enables better Video Understanding
TrajTok learns adaptive trajectory tokens for videos through a unified end-to-end segmenter, improving understanding performance and efficiency over patch-based or external-pipeline tokenizers.
Reference graph
Works this paper leans on
-
[1]
Flamingo: a visual language model for few-shot learning
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning. Advances in neural information processing systems, 35:23716–23736, 2022. 3, 4
work page 2022
-
[2]
Vivit: A video vision transformer
Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lu ˇci´c, and Cordelia Schmid. Vivit: A video vision transformer. In Proceedings of the IEEE/CVF international conference on computer vi- sion, pages 6836–6846, 2021. 1, 2, 5, 6, 7
work page 2021
-
[3]
Token Merging: Your ViT But Faster
Daniel Bolya, Cheng-Yang Fu, Xiaoliang Dai, Peizhao Zhang, Christoph Feichtenhofer, and Judy Hoffman. Token merging: Your vit but faster. arXiv preprint arXiv:2210.09461, 2022. 1, 2, 5
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
Re- visiting the” video” in video-language understanding
Shyamal Buch, Crist ´obal Eyzaguirre, Adrien Gaidon, Jiajun Wu, Li Fei-Fei, and Juan Carlos Niebles. Re- visiting the” video” in video-language understanding. In Proceedings of the IEEE/CVF conference on com- puter vision and pattern recognition , pages 2917– 2927, 2022. 2
work page 2022
-
[5]
PuMer: Pruning and merging tokens for efficient vision language models
Qingqing Cao, Bhargavi Paranjape, and Hannaneh Hajishirzi. PuMer: Pruning and merging tokens for efficient vision language models. In Proceedings of the 61st Annual Meeting of the Association for Com- putational Linguistics (Volume 1: Long Papers), pages 12890–12903, Toronto, Canada, 2023. Association for Computational Linguistics. 2
work page 2023
-
[6]
Subobject-level image tokenization
Delong Chen, Samuel Cahyawijaya, Jianfeng Liu, Baoyuan Wang, and Pascale Fung. Subobject-level image tokenization. arXiv preprint arXiv:2402.14327,
-
[7]
Liang Chen, Haozhe Zhao, Tianyu Liu, Shuai Bai, Junyang Lin, Chang Zhou, and Baobao Chang. An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language mod- els, 2024. 3
work page 2024
-
[8]
Panda-70m: Captioning 70m videos with multiple cross-modality teachers
Tsai-Shien Chen, Aliaksandr Siarohin, Willi Mena- pace, Ekaterina Deyneka, Hsiang-wei Chao, Byung Eun Jeon, Yuwei Fang, Hsin-Ying Lee, Jian Ren, Ming-Hsuan Yang, et al. Panda-70m: Captioning 70m videos with multiple cross-modality teachers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages 13320–13331, 2024. 2, 5
work page 2024
-
[9]
Putting the ob- ject back into video object segmentation
Ho Kei Cheng, Seoung Wug Oh, Brian Price, Joon- Young Lee, and Alexander Schwing. Putting the ob- ject back into video object segmentation. In Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3151–3161, 2024. 3
work page 2024
-
[10]
Joonmyung Choi, Sanghyeok Lee, Jaewon Chu, Min- hyuk Choi, and Hyunwoo J. Kim. vid-tldr: Training free token merging for light-weight video transformer,
-
[11]
Don’t look twice: Faster video transformers with run-length tok- enization
Rohan Choudhury, Guanglei Zhu, Sihan Liu, Koichiro Niinuma, Kris Kitani, and L ´aszl´o Jeni. Don’t look twice: Faster video transformers with run-length tok- enization. Advances in Neural Information Processing Systems, 37:28127–28149, 2025. 1, 2, 5, 7
work page 2025
-
[12]
Pradipto Das, Chenliang Xu, Richard F Doell, and Ja- son J Corso. A thousand frames in just a few words: Lingual description of videos through latent topics and sparse object stitching. In Proceedings of the IEEE conference on computer vision and pattern recogni- tion, pages 2634–2641, 2013. 6
work page 2013
-
[13]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929, 2020. 5
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[14]
Sam2act: Integrating visual foundation model with a memory architecture for robotic manipulation
Haoquan Fang, Markus Grotz, Wilbert Pumacay, Yi Ru Wang, Dieter Fox, Ranjay Krishna, and Jiafei Duan. Sam2act: Integrating visual foundation model with a memory architecture for robotic manipulation. arXiv preprint arXiv:2501.18564, 2025. 2
-
[15]
Adaptive token sampling for efficient vision transformers, 2022
Mohsen Fayyaz, Soroush Abbasi Koohpayegani, Farnoush Rezaei Jafari, Sunando Sengupta, Hamid Reza Vaezi Joze, Eric Sommerlade, Hamed Pirsi- avash, and Juergen Gall. Adaptive token sampling for efficient vision transformers, 2022. 2
work page 2022
-
[16]
Masked autoencoders as spatiotemporal learners, 2022
Christoph Feichtenhofer, Haoqi Fan, Yanghao Li, and Kaiming He. Masked autoencoders as spatiotemporal learners, 2022. 2
work page 2022
-
[17]
Video-MME: The First-Ever Comprehensive Evaluation Benchmark of Multi-modal LLMs in Video Analysis
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, et al. Video- mme: The first-ever comprehensive evaluation bench- mark of multi-modal llms in video analysis. arXiv preprint arXiv:2405.21075, 2024. 7
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Datacomp: In search of the next generation of multimodal datasets
Samir Yitzhak Gadre, Gabriel Ilharco, Alex Fang, Jonathan Hayase, Georgios Smyrnis, Thao Nguyen, Ryan Marten, Mitchell Wortsman, Dhruba Ghosh, Jieyu Zhang, et al. Datacomp: In search of the next generation of multimodal datasets. Advances in Neu- ral Information Processing Systems, 36:27092–27112,
-
[19]
The” some- thing something” video database for learning and eval- uating visual common sense
Raghav Goyal, Samira Ebrahimi Kahou, Vincent Michalski, Joanna Materzynska, Susanne Westphal, Heuna Kim, Valentin Haenel, Ingo Fruend, Peter Yianilos, Moritz Mueller-Freitag, et al. The” some- thing something” video database for learning and eval- uating visual common sense. In Proceedings of the IEEE international conference on computer vision , pages 58...
work page 2017
-
[20]
Ava: A video dataset of spatio- temporally localized atomic visual actions
Chunhui Gu, Chen Sun, David A Ross, Carl V ondrick, Caroline Pantofaru, Yeqing Li, Sudheendra Vijaya- narasimhan, George Toderici, Susanna Ricco, Rahul Sukthankar, et al. Ava: A video dataset of spatio- temporally localized atomic visual actions. In Pro- ceedings of the IEEE conference on computer vision and pattern recognition, pages 6047–6056, 2018. 6
work page 2018
-
[21]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016. 4
work page 2016
-
[22]
Space- time correspondence as a contrastive random walk
Allan Jabri, Andrew Owens, and Alexei Efros. Space- time correspondence as a contrastive random walk. Advances in neural information processing systems , 33:19545–19560, 2020. 8
work page 2020
-
[23]
Per- ceiver: General perception with iterative attention
Andrew Jaegle, Felix Gimeno, Andy Brock, Oriol Vinyals, Andrew Zisserman, and Joao Carreira. Per- ceiver: General perception with iterative attention. In International conference on machine learning , pages 4651–4664. PMLR, 2021. 3
work page 2021
-
[24]
Video-lavit: Unified video-language pre-training with decoupled visual-motional tokenization, 2024
Yang Jin, Zhicheng Sun, Kun Xu, Kun Xu, Liwei Chen, Hao Jiang, Quzhe Huang, Chengru Song, Yu- liang Liu, Di Zhang, Yang Song, Kun Gai, and Yadong Mu. Video-lavit: Unified video-language pre-training with decoupled visual-motional tokenization, 2024. 2
work page 2024
-
[25]
The Kinetics Human Action Video Dataset
Will Kay, Joao Carreira, Karen Simonyan, Brian Zhang, Chloe Hillier, Sudheendra Vijayanarasimhan, Fabio Viola, Tim Green, Trevor Back, Paul Natsev, et al. The kinetics human action video dataset. arXiv preprint arXiv:1705.06950, 2017. 6
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[26]
Dense-captioning events in videos
Ranjay Krishna, Kenji Hata, Frederic Ren, Li Fei-Fei, and Juan Carlos Niebles. Dense-captioning events in videos. In Proceedings of the IEEE international con- ference on computer vision, pages 706–715, 2017. 5, 6
work page 2017
-
[27]
Less is more: Clipbert for video-and-language learning via sparse sampling
Jie Lei, Linjie Li, Luowei Zhou, Zhe Gan, Tamara L Berg, Mohit Bansal, and Jingjing Liu. Less is more: Clipbert for video-and-language learning via sparse sampling. In Proceedings of the IEEE/CVF con- ference on computer vision and pattern recognition , pages 7331–7341, 2021. 2
work page 2021
-
[28]
Reveal- ing single frame bias for video-and-language learning
Jie Lei, Tamara L Berg, and Mohit Bansal. Reveal- ing single frame bias for video-and-language learning. arXiv preprint arXiv:2206.03428, 2022. 2, 7
-
[29]
Lmms- eval: Accelerating the development of large multimoal models, 2024
Bo Li, Peiyuan Zhang, Kaichen Zhang, Fanyi Pu, Xin- run Du, Yuhao Dong, Haotian Liu, Yuanhan Zhang, Ge Zhang, Chunyuan Li, and Ziwei Liu. Lmms- eval: Accelerating the development of large multimoal models, 2024. 7
work page 2024
-
[30]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre- training with frozen image encoders and large lan- guage models, 2023. 3
work page 2023
-
[31]
Videochat: Chat-centric video understanding,
KunChang Li, Yinan He, Yi Wang, Yizhuo Li, Wen- hai Wang, Ping Luo, Yali Wang, Limin Wang, and Yu Qiao. Videochat: Chat-centric video understanding,
-
[32]
Videomamba: State space model for efficient video understanding, 2024
Kunchang Li, Xinhao Li, Yi Wang, Yinan He, Yali Wang, Limin Wang, and Yu Qiao. Videomamba: State space model for efficient video understanding, 2024. 2
work page 2024
-
[33]
Svitt: Temporal learning of sparse video-text transformers
Yi Li, Kyle Min, Subarna Tripathi, and Nuno Vascon- celos. Svitt: Temporal learning of sparse video-text transformers. In Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 18919–18929, 2023. 2
work page 2023
-
[34]
Llama-vid: An image is worth 2 tokens in large language models,
Yanwei Li, Chengyao Wang, and Jiaya Jia. Llama-vid: An image is worth 2 tokens in large language models,
-
[35]
arXiv preprint arXiv:2202.07800 , year=
Youwei Liang, Chongjian Ge, Zhan Tong, Yib- ing Song, Jue Wang, and Pengtao Xie. Not all patches are what you need: Expediting vision trans- formers via token reorganizations. arXiv preprint arXiv:2202.07800, 2022. 2
-
[36]
Swinbert: End-to-end transformers with sparse attention for video captioning
Kevin Lin, Linjie Li, Chung-Ching Lin, Faisal Ahmed, Zhe Gan, Zicheng Liu, Yumao Lu, and Li- juan Wang. Swinbert: End-to-end transformers with sparse attention for video captioning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 17949–17958, 2022. 1
work page 2022
-
[37]
PPLLaVA: Varied Video Sequence Understanding With Prompt Guidance
Ruyang Liu, Haoran Tang, Haibo Liu, Yixiao Ge, Ying Shan, Chen Li, and Jiankun Yang. Ppllava: Var- ied video sequence understanding with prompt guid- ance. arXiv preprint arXiv:2411.02327, 2024. 7
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
TempCompass: Do Video LLMs Really Understand Videos?
Yuanxin Liu, Shicheng Li, Yi Liu, Yuxiang Wang, Shuhuai Ren, Lei Li, Sishuo Chen, Xu Sun, and Lu Hou. Tempcompass: Do video llms really understand videos? arXiv preprint arXiv:2403.00476, 2024. 7
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decou- pled weight decay regularization. arXiv preprint arXiv:1711.05101, 2017. 1
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[40]
Clip4clip: An empir- ical study of clip for end to end video clip retrieval,
Huaishao Luo, Lei Ji, Ming Zhong, Yang Chen, Wen Lei, Nan Duan, and Tianrui Li. Clip4clip: An empir- ical study of clip for end to end video clip retrieval,
-
[41]
Video-ChatGPT: Towards Detailed Video Understanding via Large Vision and Language Models
Muhammad Maaz, Hanoona Rasheed, Salman Khan, and Fahad Shahbaz Khan. Video-chatgpt: Towards 10 detailed video understanding via large vision and lan- guage models. arXiv preprint arXiv:2306.05424 ,
work page internal anchor Pith review Pith/arXiv arXiv
-
[42]
Nerf: Representing scenes as neural radiance fields for view synthesis
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis. Communications of the ACM , 65(1): 99–106, 2021. 4
work page 2021
-
[43]
Atten- tion bottlenecks for multimodal fusion
Arsha Nagrani, Shan Yang, Anurag Arnab, Aren Jansen, Cordelia Schmid, and Chen Sun. Atten- tion bottlenecks for multimodal fusion. In Advances in Neural Information Processing Systems , pages 14200–14213. Curran Associates, Inc., 2021. 2
work page 2021
-
[44]
Daniel Neimark, Omri Bar, Maya Zohar, and Dotan Asselmann. Video transformer network. In Pro- ceedings of the IEEE/CVF international conference on computer vision, pages 3163–3172, 2021. 1
work page 2021
-
[45]
Ia-red2: Interpretability-aware redundancy reduction for vision transformers, 2021
Bowen Pan, Rameswar Panda, Yifan Jiang, Zhangyang Wang, Rogerio Feris, and Aude Oliva. Ia-red2: Interpretability-aware redundancy reduction for vision transformers, 2021. 2
work page 2021
-
[46]
Tracking multi- ple independent targets: Evidence for a parallel track- ing mechanism
Zenon W Pylyshyn and Ron W Storm. Tracking multi- ple independent targets: Evidence for a parallel track- ing mechanism. Spatial vision, 3(3):179–197, 1988. 2
work page 1988
-
[47]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sas- try, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748–8763. PMLR, 2021. 2, 4
work page 2021
-
[48]
Towards universal soccer video understanding, 2024
Jiayuan Rao, Haoning Wu, Hao Jiang, Ya Zhang, Yan- feng Wang, and Weidi Xie. Towards universal soccer video understanding, 2024. 3
work page 2024
-
[49]
SAM 2: Segment Anything in Images and Videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman R ¨adle, Chloe Rolland, Laura Gustafson, et al. Sam 2: Segment anything in images and videos. arXiv preprint arXiv:2408.00714 , 2024. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[50]
Michael S Ryoo, AJ Piergiovanni, Anurag Arnab, Mostafa Dehghani, and Anelia Angelova. Token- learner: What can 8 learned tokens do for images and videos? arXiv preprint arXiv:2106.11297, 2021. 1, 2, 5
-
[51]
LongVU: Spatiotemporal Adaptive Compression for Long Video-Language Understanding
Xiaoqian Shen, Yunyang Xiong, Changsheng Zhao, Lemeng Wu, Jun Chen, Chenchen Zhu, Zechun Liu, Fanyi Xiao, Balakrishnan Varadarajan, Florian Bor- des, Zhuang Liu, Hu Xu, Hyunwoo J. Kim, Bilge Soran, Raghuraman Krishnamoorthi, Mohamed Elho- seiny, and Vikas Chandra. Longvu: Spatiotemporal adaptive compression for long video-language under- standing. arXiv p...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[52]
Video-xl: Extra-long vision language model for hour-scale video understanding, 2024
Yan Shu, Zheng Liu, Peitian Zhang, Minghao Qin, Junjie Zhou, Zhengyang Liang, Tiejun Huang, and Bo Zhao. Video-xl: Extra-long vision language model for hour-scale video understanding, 2024. 2
work page 2024
-
[53]
Hollywood in homes: Crowdsourcing data collection for activity understanding
Gunnar A Sigurdsson, G ¨ul Varol, Xiaolong Wang, Ali Farhadi, Ivan Laptev, and Abhinav Gupta. Hollywood in homes: Crowdsourcing data collection for activity understanding. In Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11–14, 2016, Proceedings, Part I 14 , pages 510–526. Springer, 2016. 5
work page 2016
-
[54]
Moviechat: From dense token to sparse memory for long video under- standing
Enxin Song, Wenhao Chai, Guanhong Wang, Yucheng Zhang, Haoyang Zhou, Feiyang Wu, Haozhe Chi, Xun Guo, Tian Ye, Yanting Zhang, et al. Moviechat: From dense token to sparse memory for long video under- standing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages 18221–18232, 2024. 2, 7
work page 2024
-
[55]
UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild
Khurram Soomro, Amir Roshan Zamir, and Mubarak Shah. Ucf101: A dataset of 101 human actions classes from videos in the wild. arXiv preprint arXiv:1212.0402, 2012. 6
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[56]
Principles of object perception
Elizabeth S Spelke. Principles of object perception. Cognitive science, 14(1):29–56, 1990. 2
work page 1990
-
[57]
Roformer: Enhanced transformer with rotary position embedding
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding. Neuro- computing, 568:127063, 2024. 4
work page 2024
-
[58]
Global device growth and traffic pro- files
Cisco Systems. Global device growth and traffic pro- files. Technical report, Cisco, 2018. Accessed: 2024- 11-29. 1
work page 2018
-
[59]
Videomae: Masked autoencoders are data-efficient learners for self-supervised video pre-training
Zhan Tong, Yibing Song, Jue Wang, and Limin Wang. Videomae: Masked autoencoders are data-efficient learners for self-supervised video pre-training. Ad- vances in neural information processing systems , 35: 10078–10093, 2022. 2
work page 2022
-
[60]
A Vaswani. Attention is all you need. Advances in Neural Information Processing Systems, 2017. 1
work page 2017
-
[61]
A century of gestalt psy- chology in visual perception: I
Johan Wagemans, James H Elder, Michael Kubovy, Stephen E Palmer, Mary A Peterson, Manish Singh, and R¨udiger V on der Heydt. A century of gestalt psy- chology in visual perception: I. perceptual grouping and figure–ground organization. Psychological bul- letin, 138(6):1172, 2012. 2
work page 2012
-
[62]
Efficient video trans- formers with spatial-temporal token selection
Junke Wang, Xitong Yang, Hengduo Li, Liu Li, Zux- uan Wu, and Yu-Gang Jiang. Efficient video trans- formers with spatial-temporal token selection. In ECCV, 2022. 2
work page 2022
-
[63]
Vatex: A large- scale, high-quality multilingual dataset for video-and- 11 language research
Xin Wang, Jiawei Wu, Junkun Chen, Lei Li, Yuan- Fang Wang, and William Yang Wang. Vatex: A large- scale, high-quality multilingual dataset for video-and- 11 language research. In Proceedings of the IEEE/CVF international conference on computer vision , pages 4581–4591, 2019. 5
work page 2019
-
[64]
Internvideo2: Scaling foun- dation models for multimodal video understanding
Yi Wang, Kunchang Li, Xinhao Li, Jiashuo Yu, Yi- nan He, Guo Chen, Baoqi Pei, Rongkun Zheng, Zun Wang, Yansong Shi, et al. Internvideo2: Scaling foun- dation models for multimodal video understanding. In European Conference on Computer Vision , pages 396–416. Springer, 2024. 6, 7
work page 2024
-
[65]
Next-qa: Next phase of question-answering to explaining temporal actions
Junbin Xiao, Xindi Shang, Angela Yao, and Tat-Seng Chua. Next-qa: Next phase of question-answering to explaining temporal actions. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9777–9786, 2021. 7
work page 2021
-
[66]
Msr-vtt: A large video description dataset for bridging video and language
Jun Xu, Tao Mei, Ting Yao, and Yong Rui. Msr-vtt: A large video description dataset for bridging video and language. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5288– 5296, 2016. 5
work page 2016
-
[67]
Track anything: Segment anything meets videos
Jinyu Yang, Mingqi Gao, Zhe Li, Shang Gao, Fangjing Wang, and Feng Zheng. Track anything: Segment anything meets videos. arXiv preprint arXiv:2304.11968, 2023. 3
-
[68]
Visionzip: Longer is better but not necessary in vision language models, 2024
Senqiao Yang, Yukang Chen, Zhuotao Tian, Chengyao Wang, Jingyao Li, Bei Yu, and Jiaya Jia. Visionzip: Longer is better but not necessary in vision language models, 2024. 3
work page 2024
-
[69]
Activitynet-qa: A dataset for understanding complex web videos via question answering
Zhou Yu, Dejing Xu, Jun Yu, Ting Yu, Zhou Zhao, Yueting Zhuang, and Dacheng Tao. Activitynet-qa: A dataset for understanding complex web videos via question answering. In Proceedings of the AAAI Con- ference on Artificial Intelligence , pages 9127–9134,
-
[70]
Videoglue: Video general understanding evaluation of foundation models
Liangzhe Yuan, Nitesh Bharadwaj Gundavarapu, Long Zhao, Hao Zhou, Yin Cui, Lu Jiang, Xuan Yang, Menglin Jia, Tobias Weyand, Luke Friedman, et al. Videoglue: Video general understanding evaluation of foundation models. arXiv preprint arXiv:2307.03166,
-
[71]
Vide- ollama 3: Frontier multimodal foundation models for image and video understanding, 2025
Boqiang Zhang, Kehan Li, Zesen Cheng, Zhiqiang Hu, Yuqian Yuan, Guanzheng Chen, Sicong Leng, Yuming Jiang, Hang Zhang, Xin Li, Peng Jin, Wenqi Zhang, Fan Wang, Lidong Bing, and Deli Zhao. Vide- ollama 3: Frontier multimodal foundation models for image and video understanding, 2025. 2
work page 2025
-
[72]
Llava-mini: Efficient image and video large multimodal models with one vision token, 2025
Shaolei Zhang, Qingkai Fang, Zhe Yang, and Yang Feng. Llava-mini: Efficient image and video large multimodal models with one vision token, 2025. 2
work page 2025
-
[73]
LLaVA-Video: Video Instruction Tuning With Synthetic Data
Yuanhan Zhang, Jinming Wu, Wei Li, Bo Li, Ze- jun Ma, Ziwei Liu, and Chunyuan Li. Video in- struction tuning with synthetic data. arXiv preprint arXiv:2410.02713, 2024. 7
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[74]
Long Zhao, Nitesh B Gundavarapu, Liangzhe Yuan, Hao Zhou, Shen Yan, Jennifer J Sun, Luke Friedman, Rui Qian, Tobias Weyand, Yue Zhao, et al. Video- prism: A foundational visual encoder for video under- standing. arXiv preprint arXiv:2402.13217, 2024. 6, 7
-
[75]
MLVU: Benchmarking Multi-task Long Video Understanding
Junjie Zhou, Yan Shu, Bo Zhao, Boya Wu, Shitao Xiao, Xi Yang, Yongping Xiong, Bo Zhang, Tiejun Huang, and Zheng Liu. Mlvu: A comprehensive benchmark for multi-task long video understanding. arXiv preprint arXiv:2406.04264, 2024. 7 12 One Trajectory, One Token: Grounded Video Tokenization via Panoptic Sub-object Trajectory Supplementary Material
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[76]
More Implementation Details We provide the complete training details in Table 7. We optimize the models using AdamW optimizer [39] with a learning rate of 10−4, a weight decay of 10−2, and mixed precision training. We adopt a cosine annealing learning rate schedule. The contrastive view (batch size) for video training is set to 256, and all models are tra...
-
[77]
More Architecture Details To complement the main paper, we provide additional de- tails on our model architecture and TokenMerge baseline’s architecture. Trajectory Encoder. We provide the complete architec- tural details of our trajectory tokenizer in table ??. As shown, the parameter size of our tokenizer is an order of magnitude smaller compared with m...
-
[78]
A frame is classified as a key frame if it is proposed by at least two out of the three detectors
Key Frame Detection Algorithm We illustrate the details of our key frame detection algo- rithm, which ensembles three sub-detectors to ensure ro- bust scene boundary identification. A frame is classified as a key frame if it is proposed by at least two out of the three detectors. All detectors are implemented using the Content- Aware Detector from the PyS...
-
[79]
Detailed setup in A V Av2 Spatial Temporal Detection task We follow the setup in [59] to evaluate our model on the A V Av2 spatial-temporal action detection task. In this task, given an object’s bounding box in a specific video frame, the model must predict the action associated with that object at that time instant. This requires extracting video feature...
-
[80]
Full tables for scaling performance experi- ments We provide the complete table for the scaling up experi- ments, which we only show the plots of average trend in the main table. Table 10 presents the performance variations of the model with the change of the scale of the training data. Table 11 presents the model’s performance with im- ages adding to tra...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.