Learning to Reason at the Frontier of Learnability
Pith reviewed 2026-05-23 02:38 UTC · model grok-4.3
The pith
Prioritizing questions with high variance in success rate improves reinforcement learning performance for large language models on reasoning tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
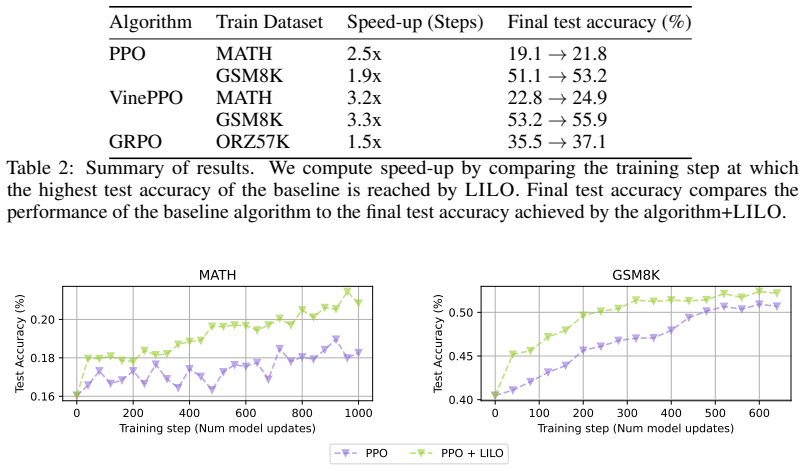
The paper establishes that throughout training with PPO and VinePPO on two widely used datasets, many questions are solved by all attempts or by none and thus supply no meaningful signal, while a curriculum that prioritizes questions with high variance of success consistently boosts training performance across multiple algorithms and datasets.
What carries the argument
The learnability curriculum that samples questions exhibiting high variance in success rate across multiple attempts.
If this is right
- Training performance improves consistently across PPO and VinePPO on multiple datasets.
- The RL stage of LLM training uses attempts more efficiently by avoiding questions that are already mastered or impossible.
- The final models reach higher performance levels on reasoning tasks for the same training budget.
- The method requires no change to the underlying reinforcement learning algorithms themselves.
Where Pith is reading between the lines
- The same variance signal could be used to decide dynamically how many attempts to allocate to each question rather than fixing the number in advance.
- If variance reliably tracks the frontier, the curriculum might reduce the total number of attempts needed to reach a target performance level.
- The approach could be tested on non-math reasoning tasks to check whether high-variance questions remain the most informative ones.
Load-bearing premise
That questions with high variance in success rate are the ones at the frontier of learnability and that prioritizing them produces net positive learning without introducing instability or distribution shift.
What would settle it
Training runs that apply the high-variance curriculum and show equal or lower final accuracy on held-out reasoning benchmarks compared with standard uniform sampling after the same number of steps.
Figures










read the original abstract
Reinforcement learning is now widely adopted as the final stage of large language model training, especially for reasoning-style tasks such as maths problems. Typically, models attempt each question many times during a single training step and attempt to learn from their successes and failures. However, we demonstrate that throughout training with two popular algorithms (PPO and VinePPO) on two widely used datasets, many questions are either solved by all attempts - meaning they are already learned - or by none - providing no meaningful training signal. To address this, we adapt a method from the reinforcement learning literature - sampling for learnability - and apply it to the reinforcement learning stage of LLM training. Our curriculum prioritises questions with high variance of success, i.e. those where the agent sometimes succeeds, but not always. Our findings demonstrate that this curriculum consistently boosts training performance across multiple algorithms and datasets, paving the way for more efficient and effective reinforcement learning with LLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that in RL fine-tuning of LLMs for reasoning tasks, many questions yield either all successes or all failures and thus provide no training signal; it adapts a 'sampling for learnability' curriculum that prioritizes questions with high success-rate variance and reports that this consistently improves training performance for both PPO and VinePPO on two standard datasets.
Significance. If the gains are shown to arise from improved learning signal rather than distribution shift, the approach could make RL stages of LLM training more sample-efficient by focusing compute on frontier items.
major comments (2)
- [Experiments] The central claim that the curriculum improves the learning signal (rather than merely altering the empirical training distribution) is load-bearing yet untested. No ablation is described that holds the effective data distribution fixed while varying only the selection criterion, nor is it stated whether final evaluation metrics are computed on the original full distribution versus the curriculum distribution.
- [Method] The weakest assumption—that high-variance items are reliably at the frontier and that prioritizing them yields net-positive learning without introducing instability—is not supported by any analysis of variance-estimate stability across training steps or of downstream effects on overall distribution coverage.
minor comments (2)
- [Abstract] The abstract states performance gains but supplies no quantitative details (effect sizes, number of runs, statistical tests, or error bars); these must be added to the main text and figures.
- [Method] Notation for success-rate variance and the precise sampling probability should be defined once in a dedicated subsection rather than introduced piecemeal.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below, clarifying evaluation details, noting limitations of the original experiments, and indicating planned revisions.
read point-by-point responses
-
Referee: [Experiments] The central claim that the curriculum improves the learning signal (rather than merely altering the empirical training distribution) is load-bearing yet untested. No ablation is described that holds the effective data distribution fixed while varying only the selection criterion, nor is it stated whether final evaluation metrics are computed on the original full distribution versus the curriculum distribution.
Authors: We agree that an explicit ablation isolating the selection criterion from distribution shift would strengthen the central claim. All reported evaluation metrics in the manuscript are computed on the original full test distributions (standard for MATH and GSM8K), not the curriculum distribution used only during training. Constructing a fixed-distribution control is non-trivial because the variance estimates (and thus sampling probabilities) evolve dynamically with the policy; a static reweighting would not replicate the online curriculum. We will add an explicit statement confirming the evaluation distribution and a limitations paragraph discussing the difficulty of the requested ablation. revision: partial
-
Referee: [Method] The weakest assumption—that high-variance items are reliably at the frontier and that prioritizing them yields net-positive learning without introducing instability—is not supported by any analysis of variance-estimate stability across training steps or of downstream effects on overall distribution coverage.
Authors: The approach is an adaptation of the established 'sampling for learnability' method from the RL literature, where high-variance prioritization has been shown to focus on frontier items. Our results show consistent gains without divergence across two algorithms and two datasets, providing indirect evidence of stability. We did not include per-step variance plots or explicit coverage analysis in the original submission. We will add these analyses (variance trajectories and coverage statistics) in the revision. revision: yes
Circularity Check
No significant circularity; empirical adaptation with independent validation.
full rationale
The paper adapts an existing RL sampling-for-learnability method to LLM post-training and reports empirical gains on PPO/VinePPO across datasets. No load-bearing step reduces to a self-definition, fitted parameter renamed as prediction, or self-citation chain. The curriculum is defined by observable success-rate variance on the training questions; performance lift is measured on held-out or full distributions without the result being forced by construction. The derivation chain consists of standard policy-gradient updates plus a data-selection heuristic whose benefit is externally falsifiable and not presupposed by the method itself.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption High variance in success rate across repeated attempts identifies questions at the frontier of learnability
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel matches?
matchesMATCHES: this paper passage directly uses, restates, or depends on the cited Recognition theorem or module.
Theorem 3.1 … Eπθ[∥∇θJ(θ)∥²] = … Eπθ[(r(sT) − E[r(sT)])²] … for binary rewards … = pθ(1 − pθ)
-
IndisputableMonolith/Foundation/LogicAsFunctionalEquation.leanTranslation Theorem / SatisfiesLawsOfLogic matches?
matchesMATCHES: this paper passage directly uses, restates, or depends on the cited Recognition theorem or module.
expected policy improvement increases with the variance of the final reward, i.e. learnability
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI, D. Guo, D. Yang, H. Zhang, J. Song, R. Zhang, R. Xu, Q. Zhu, S. Ma, P. Wang, X. Bi, X. Zhang, X. Yu, Y . Wu, Z. F. Wu, Z. Gou, Z. Shao, Z. Li, Z. Gao, A. Liu, B. Xue, B. Wang, B. Wu, B. Feng, C. Lu, C. Zhao, C. Deng, C. Zhang, C. Ruan, D. Dai, D. Chen, D. Ji, E. Li, F. Lin, F. Dai, F. Luo, G. Hao, G. Chen, G. Li, H. Zhang, H. Bao, H. Xu, H. W...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Tulu 3: Pushing Frontiers in Open Language Model Post-Training
N. Lambert, J. Morrison, V . Pyatkin, S. Huang, H. Ivison, F. Brahman, L. J. V . Miranda, A. Liu, N. Dziri, S. Lyu, Y . Gu, S. Malik, V . Graf, J. D. Hwang, J. Yang, R. L. Bras, O. Tafjord, C. Wilhelm, L. Soldaini, N. A. Smith, Y . Wang, P. Dasigi, and H. Hajishirzi, “Tulu 3: Pushing frontiers in open language model post-training,” 2025. [Online]. Availab...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
OpenAI, “Learning to reason with llms,” 2024. [Online]. Available: https://openai.com/index/ learning-to-reason-with-llms/
work page 2024
-
[4]
Understanding R1-Zero-Like Training: A Critical Perspective
Z. Liu, C. Chen, W. Li, P. Qi, T. Pang, C. Du, W. S. Lee, and M. Lin, “Understanding r1-zero-like training: A critical perspective,” 2025. [Online]. Available: https://arxiv.org/abs/2503.20783
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Vineppo: Unlocking rl potential for llm reasoning through refined credit assignment,
A. Kazemnejad, M. Aghajohari, E. Portelance, A. Sordoni, S. Reddy, A. Courville, and N. L. Roux, “Vineppo: Unlocking rl potential for llm reasoning through refined credit assignment,”
-
[6]
Available: https://arxiv.org/abs/2410.01679
[Online]. Available: https://arxiv.org/abs/2410.01679
-
[7]
Group robust preference optimization in reward-free rlhf,
S. S. Ramesh, Y . Hu, I. Chaimalas, V . Mehta, P. G. Sessa, H. B. Ammar, and I. Bogunovic, “Group robust preference optimization in reward-free rlhf,” 2024. [Online]. Available: https://arxiv.org/abs/2405.20304
-
[8]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,” 2017. [Online]. Available: https://arxiv.org/abs/1707.06347
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[9]
Training Verifiers to Solve Math Word Problems
K. Cobbe, V . Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Plappert, J. Tworek, J. Hilton, R. Nakano, C. Hesse, and J. Schulman, “Training verifiers to solve math word problems,” 2021. [Online]. Available: https://arxiv.org/abs/2110.14168
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[10]
Measuring Mathematical Problem Solving With the MATH Dataset
D. Hendrycks, C. Burns, S. Kadavath, A. Arora, S. Basart, E. Tang, D. Song, and J. Steinhardt, “Measuring mathematical problem solving with the math dataset,” 2021. [Online]. Available: https://arxiv.org/abs/2103.03874
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[11]
Open-Reasoner-Zero: An Open Source Approach to Scaling Up Reinforcement Learning on the Base Model
J. Hu, Y . Zhang, Q. Han, D. Jiang, X. Zhang, and H.-Y . Shum, “Open-reasoner-zero: An open source approach to scaling up reinforcement learning on the base model,” 2025. [Online]. Available: https://arxiv.org/abs/2503.24290
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Rho-1: Not all tokens are what you need,
Z. Lin, Z. Gou, Y . Gong, X. Liu, Y . Shen, R. Xu, C. Lin, Y . Yang, J. Jiao, N. Duan, and W. Chen, “Rho-1: Not all tokens are what you need,” 2025. [Online]. Available: https://arxiv.org/abs/2404.07965 10
-
[13]
Qwen, :, A. Yang, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Li, D. Liu, F. Huang, H. Wei, H. Lin, J. Yang, J. Tu, J. Zhang, J. Yang, J. Yang, J. Zhou, J. Lin, K. Dang, K. Lu, K. Bao, K. Yang, L. Yu, M. Li, M. Xue, P. Zhang, Q. Zhu, R. Men, R. Lin, T. Li, T. Tang, T. Xia, X. Ren, X. Ren, Y . Fan, Y . Su, Y . Zhang, Y . Wan, Y . Liu, Z. Cui, Z. Zhang, ...
work page 2025
-
[14]
Mathscale: Scaling instruction tuning for mathematical reasoning,
Z. Tang, X. Zhang, B. Wang, and F. Wei, “Mathscale: Scaling instruction tuning for mathematical reasoning,” 2024. [Online]. Available: https://arxiv.org/abs/2403.02884
-
[15]
C. He, R. Luo, Y . Bai, S. Hu, Z. L. Thai, J. Shen, J. Hu, X. Han, Y . Huang, Y . Zhang, J. Liu, L. Qi, Z. Liu, and M. Sun, “Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems,” 2024. [Online]. Available: https://arxiv.org/abs/2402.14008
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Back to Basics: Revisiting REINFORCE Style Optimization for Learning from Human Feedback in LLMs
A. Ahmadian, C. Cremer, M. Gall ´e, M. Fadaee, J. Kreutzer, O. Pietquin, A. ¨Ust¨un, and S. Hooker, “Back to basics: Revisiting reinforce style optimization for learning from human feedback in llms,” 2024. [Online]. Available: https://arxiv.org/abs/2402.14740
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Proximal curriculum for reinforcement learning agents,
G. Tzannetos, B. G. Ribeiro, P. Kamalaruban, and A. Singla, “Proximal curriculum for reinforcement learning agents,” 2023. [Online]. Available: https://arxiv.org/abs/2304.12877
-
[18]
Automatic goal generation for reinforcement learning agents,
C. Florensa, D. Held, X. Geng, and P. Abbeel, “Automatic goal generation for reinforcement learning agents,” in Proceedings of the 35th International Conference on Machine Learning , ser. Proceedings of Machine Learning Research, J. Dy and A. Krause, Eds., vol. 80. PMLR, 10–15 Jul 2018, pp. 1515–1528. [Online]. Available: https://proceedings.mlr.press/v80...
work page 2018
-
[19]
No regrets: Investigating and improving regret approximations for curriculum discovery,
A. Rutherford, M. Beukman, T. Willi, B. Lacerda, N. Hawes, and J. Foerster, “No regrets: Investigating and improving regret approximations for curriculum discovery,” 2024. [Online]. Available: https://arxiv.org/abs/2408.15099
-
[20]
Simple statistical gradient-following algorithms for connectionist reinforcement learning
R. J. Williams, “Simple statistical gradient-following algorithms for connectionist reinforcement learning,” Machine Learning, vol. 8, no. 3, pp. 229–256, May 1992. [Online]. Available: https://doi.org/10.1007/BF00992696
-
[21]
Asynchronous rlhf: Faster and more efficient off-policy rl for language models,
M. Noukhovitch, S. Huang, S. Xhonneux, A. Hosseini, R. Agarwal, and A. Courville, “Asynchronous rlhf: Faster and more efficient off-policy rl for language models,” 2024. [Online]. Available: https://arxiv.org/abs/2410.18252
-
[22]
OpenRLHF: An Easy-to-use, Scalable and High-performance RLHF Framework
J. Hu, X. Wu, Z. Zhu, Xianyu, W. Wang, D. Zhang, and Y . Cao, “Openrlhf: An easy-to-use, scalable and high-performance rlhf framework,” 2024. [Online]. Available: https://arxiv.org/abs/2405.11143
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
There may not be aha moment in r1-zero-like training — a pilot study,
Z. Liu, C. Chen, W. Li, T. Pang, C. Du, and M. Lin, “There may not be aha moment in r1-zero-like training — a pilot study,” https://oatllm.notion.site/oat-zero, 2025, notion Blog
work page 2025
-
[24]
L. T. B. L. R. S. S. C. H. K. R. L. Y . A. J. Z. S. Z. Q. B. D. L. Z. Y . F. G. L. Jia LI, Edward Beech- ing and S. Polu, “Numinamath,” [https://github.com/project-numina/aimo-progress-prize](https: //github.com/project-numina/aimo-progress-prize/blob/main/report/numina dataset.pdf), 2024
work page 2024
-
[25]
Solving Quantitative Reasoning Problems with Language Models
A. Lewkowycz, A. Andreassen, D. Dohan, E. Dyer, H. Michalewski, V . Ramasesh, A. Slone, C. Anil, I. Schlag, T. Gutman-Solo, Y . Wu, B. Neyshabur, G. Gur-Ari, and V . Misra, “Solving quantitative reasoning problems with language models,” 2022. [Online]. Available: https://arxiv.org/abs/2206.14858
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[26]
Teaching large language models to reason with reinforcement learning,
A. Havrilla, Y . Du, S. C. Raparthy, C. Nalmpantis, J. Dwivedi-Yu, M. Zhuravinskyi, E. Hambro, S. Sukhbaatar, and R. Raileanu, “Teaching large language models to reason with reinforcement learning,” 2024. [Online]. Available: https://arxiv.org/abs/2403.04642
-
[27]
M. Jiang, E. Grefenstette, and T. Rockt ¨aschel, “Prioritized level replay,” 2021. [Online]. Available: https://arxiv.org/abs/2010.03934
-
[28]
Learning Montezuma's Revenge from a Single Demonstration
T. Salimans and R. Chen, “Learning montezuma’s revenge from a single demonstration,” 2018. [Online]. Available: https://arxiv.org/abs/1812.03381 11
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[29]
Smaug: Fixing Failure Modes of Preference Optimisation with DPO-Positive
A. Pal, D. Karkhanis, S. Dooley, M. Roberts, S. Naidu, and C. White, “Smaug: Fixing failure modes of preference optimisation with dpo-positive,” 2024. [Online]. Available: https://arxiv.org/abs/2402.13228
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Q. Yu, Z. Zhang, R. Zhu, Y . Yuan, X. Zuo, Y . Yue, T. Fan, G. Liu, L. Liu, X. Liu, H. Lin, Z. Lin, B. Ma, G. Sheng, Y . Tong, C. Zhang, M. Zhang, W. Zhang, H. Zhu, J. Zhu, J. Chen, J. Chen, C. Wang, H. Yu, W. Dai, Y . Song, X. Wei, H. Zhou, J. Liu, W.-Y . Ma, Y .-Q. Zhang, L. Yan, M. Qiao, Y . Wu, and M. Wang, “Dapo: An open-source llm reinforcement lear...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Kimi k1.5: Scaling Reinforcement Learning with LLMs
K. Team, A. Du, B. Gao, B. Xing, C. Jiang, C. Chen, C. Li, C. Xiao, C. Du, C. Liao, C. Tang, C. Wang, D. Zhang, E. Yuan, E. Lu, F. Tang, F. Sung, G. Wei, G. Lai, H. Guo, H. Zhu, H. Ding, H. Hu, H. Yang, H. Zhang, H. Yao, H. Zhao, H. Lu, H. Li, H. Yu, H. Gao, H. Zheng, H. Yuan, J. Chen, J. Guo, J. Su, J. Wang, J. Zhao, J. Zhang, J. Liu, J. Yan, J. Wu, L. S...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Not All Rollouts are Useful: Down-Sampling Rollouts in LLM Reinforcement Learning
Y . E. Xu, Y . Savani, F. Fang, and Z. Kolter, “Not all rollouts are useful: Down-sampling rollouts in llm reinforcement learning,” 2025. [Online]. Available: https://arxiv.org/abs/2504.13818
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
The llama 4 herd: The beginning of a new era of natively multimodal ai innovation,
Meta AI, “The llama 4 herd: The beginning of a new era of natively multimodal ai innovation,” April 2025, accessed: 2025-05-16. [Online]. Available: https://ai.meta.com/blog/ llama-4-multimodal-intelligence/
work page 2025
-
[34]
Emergent complexity and zero-shot transfer via unsupervised environment design,
M. Dennis, N. Jaques, E. Vinitsky, A. Bayen, S. Russell, A. Critch, and S. Levine, “Emergent complexity and zero-shot transfer via unsupervised environment design,” 2021. [Online]. Available: https://arxiv.org/abs/2012.02096
-
[35]
M. Chevalier-Boisvert, B. Dai, M. Towers, R. Perez-Vicente, L. Willems, S. Lahlou, S. Pal, P. S. Castro, and J. Terry, “Minigrid & miniworld: Modular & customizable reinforcement learning environments for goal-oriented tasks,” in Advances in Neural Information Processing Systems , A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine...
work page 2023
-
[36]
Xland-minigrid: Scalable meta-reinforcement learning environments in jax,
A. Nikulin, V . Kurenkov, I. Zisman, A. Agarkov, V . Sinii, and S. Kolesnikov, “Xland-minigrid: Scalable meta-reinforcement learning environments in jax,” 2024. [Online]. Available: https://arxiv.org/abs/2312.12044
-
[37]
Jaxmarl: Multi-agent rl environments and algorithms in jax,
A. Rutherford, B. Ellis, M. Gallici, J. Cook, A. Lupu, G. Ingvarsson, T. Willi, R. Hammond, A. Khan, C. S. de Witt, A. Souly, S. Bandyopadhyay, M. Samvelyan, M. Jiang, R. T. Lange, S. Whiteson, B. Lacerda, N. Hawes, T. Rocktaschel, C. Lu, and J. N. Foerster, “Jaxmarl: Multi-agent rl environments and algorithms in jax,” 2024. [Online]. Available: https://a...
-
[38]
G. Brockman, V . Cheung, L. Pettersson, J. Schneider, J. Schulman, J. Tang, and W. Zaremba, “Openai gym,” 2016. [Online]. Available: https://arxiv.org/abs/1606.01540
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[39]
JAX: composable transformations of Python+NumPy programs,
J. Bradbury, R. Frostig, P. Hawkins, M. J. Johnson, C. Leary, D. Maclaurin, G. Necula, A. Paszke, J. VanderPlas, S. Wanderman-Milne, and Q. Zhang, “JAX: composable transformations of Python+NumPy programs,” 2018. [Online]. Available: http://github.com/jax-ml/jax
work page 2018
-
[40]
Measuring short-form factuality in large language models
J. Wei, N. Karina, H. W. Chung, Y . J. Jiao, S. Papay, A. Glaese, J. Schulman, and W. Fedus, “Measuring short-form factuality in large language models,” 2024. [Online]. Available: https://arxiv.org/abs/2411.04368
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
Evolving curricula with regret-based environment design,
J. Parker-Holder, M. Jiang, M. Dennis, M. Samvelyan, J. Foerster, E. Grefenstette, and T. Rockt¨aschel, “Evolving curricula with regret-based environment design,” 2023. [Online]. Available: https://arxiv.org/abs/2203.01302 12
-
[42]
Absolute Zero: Reinforced Self-play Reasoning with Zero Data
A. Zhao, Y . Wu, Y . Yue, T. Wu, Q. Xu, Y . Yue, M. Lin, S. Wang, Q. Wu, Z. Zheng, and G. Huang, “Absolute zero: Reinforced self-play reasoning with zero data,” 2025. [Online]. Available: https://arxiv.org/abs/2505.03335
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
R. S. Sutton and A. G. Barto, Reinforcement Learning: An Introduction, 2nd ed. The MIT Press, 2018. [Online]. Available: http://incompleteideas.net/book/the-book-2nd.html
work page 2018
-
[44]
Y . Bengio, J. Louradour, R. Collobert, and J. Weston, “Curriculum learning,” vol. 60, 06 2009, p. 6
work page 2009
-
[45]
Learning and development in neural networks: The importance of starting small
J. L. Elman, “Learning and development in neural networks: The importance of starting small.” Cognition, vol. 48, no. 1, pp. 71–99, 1993
work page 1993
-
[46]
Online batch selection for faster training of neural networks,
I. Loshchilov and F. Hutter, “Online batch selection for faster training of neural networks,”
-
[47]
Online Batch Selection for Faster Training of Neural Networks
[Online]. Available: https://arxiv.org/abs/1511.06343
work page internal anchor Pith review Pith/arXiv arXiv
-
[48]
Ordered sgd: A new stochastic optimization framework for empirical risk minimization,
K. Kawaguchi and H. Lu, “Ordered sgd: A new stochastic optimization framework for empirical risk minimization,” 2020. [Online]. Available: https://arxiv.org/abs/1907.04371
-
[49]
Accelerating deep learning by focusing on the biggest losers,
A. H. Jiang, D. L. K. Wong, G. Zhou, D. G. Andersen, J. Dean, G. R. Ganger, G. Joshi, M. Kaminksy, M. Kozuch, Z. C. Lipton, and P. Pillai, “Accelerating deep learning by focusing on the biggest losers,” 2019. [Online]. Available: https://arxiv.org/abs/1910.00762
-
[50]
Curriculum learning by transfer learning: Theory and experiments with deep networks,
D. Weinshall, G. Cohen, and D. Amir, “Curriculum learning by transfer learning: Theory and experiments with deep networks,” 2018. [Online]. Available: https://arxiv.org/abs/1802.03796
-
[51]
Active learning literature survey,
B. Settles, “Active learning literature survey,” University of Wisconsin-Madison Department of Computer Sciences, Technical Report TR1648, 2009. [Online]. Available: http://digital.library.wisc.edu/1793/60660
work page 2009
-
[52]
Confidence-based active learning,
M. Li and I. Sethi, “Confidence-based active learning,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 28, no. 8, pp. 1251–1261, 2006
work page 2006
-
[53]
Selection via proxy: Efficient data se- lection for deep learning.arXiv preprint arXiv:1906.11829,
C. Coleman, C. Yeh, S. Mussmann, B. Mirzasoleiman, P. Bailis, P. Liang, J. Leskovec, and M. Zaharia, “Selection via proxy: Efficient data selection for deep learning,” 2020. [Online]. Available: https://arxiv.org/abs/1906.11829
-
[54]
Prioritized training on points that are learnable, worth learning, and not yet learnt,
S. Mindermann, J. Brauner, M. Razzak, M. Sharma, A. Kirsch, W. Xu, B. H ¨oltgen, A. N. Gomez, A. Morisot, S. Farquhar, and Y . Gal, “Prioritized training on points that are learnable, worth learning, and not yet learnt,” 2022. [Online]. Available: https://arxiv.org/abs/2206.07137
-
[55]
An Overview and a Benchmark of Active Learning for Outlier Detection with One-Class Classifiers
H. Trittenbach, A. Englhardt, and K. B ¨ohm, “An overview and a benchmark of active learning for outlier detection with one-class classifiers,” 2019. [Online]. Available: https://arxiv.org/abs/1808.04759
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[56]
Training deep models faster with robust, approximate importance sampling,
T. B. Johnson and C. Guestrin, “Training deep models faster with robust, approximate importance sampling,” in Advances in Neural Information Processing Systems , S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett, Eds., vol. 31. Curran Associates, Inc., 2018. [Online]. Available: https://proceedings.neurips.cc/paper files/ p...
work page 2018
-
[57]
Not all samples are created equal: Deep learning with importance sampling,
A. Katharopoulos and F. Fleuret, “Not all samples are created equal: Deep learning with importance sampling,” in Proceedings of the 35th International Conference on Machine Learning , ser. Proceedings of Machine Learning Research, J. Dy and A. Krause, Eds., vol. 80. PMLR, 10–15 Jul 2018, pp. 2525–2534. [Online]. Available: https://proceedings.mlr.press/v8...
work page 2018
-
[58]
Self-paced learning for latent variable models,
M. Kumar, B. Packer, and D. Koller, “Self-paced learning for latent variable models,” in Advances in Neural Information Processing Systems , J. Lafferty, C. Williams, J. Shawe-Taylor, R. Zemel, and A. Culotta, Eds., vol. 23. Curran Associates, Inc., 2010. [Online]. Available: https://proceedings.neurips.cc/paper files/paper/2010/file/ e57c6b956a6521b28495...
work page 2010
-
[59]
Automated Curriculum Learning for Neural Networks
A. Graves, M. G. Bellemare, J. Menick, R. Munos, and K. Kavukcuoglu, “Automated curriculum learning for neural networks,” 2017. [Online]. Available: https://arxiv.org/abs/1704.03003
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[60]
Teacher-Student Curriculum Learning
T. Matiisen, A. Oliver, T. Cohen, and J. Schulman, “Teacher-student curriculum learning,” 2017. [Online]. Available: https://arxiv.org/abs/1707.00183
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[61]
A survey of multi-task deep reinforcement learning,
N. Vithayathil Varghese and Q. H. Mahmoud, “A survey of multi-task deep reinforcement learning,” Electronics, vol. 9, no. 9, 2020. [Online]. Available: https://www.mdpi.com/ 2079-9292/9/9/1363
work page 2020
-
[62]
Automatic curriculum learning through value disagreement,
Y . Zhang, P. Abbeel, and L. Pinto, “Automatic curriculum learning through value disagreement,”
-
[63]
Available: https://arxiv.org/abs/2006.09641
[Online]. Available: https://arxiv.org/abs/2006.09641
-
[64]
Information-theoretic task selection for meta-reinforcement learning,
R. L. Gutierrez and M. Leonetti, “Information-theoretic task selection for meta-reinforcement learning,” 2021. [Online]. Available: https://arxiv.org/abs/2011.01054
-
[65]
Maximum entropy gain exploration for long horizon multi-goal reinforcement learning,
S. Pitis, H. Chan, S. Zhao, B. Stadie, and J. Ba, “Maximum entropy gain exploration for long horizon multi-goal reinforcement learning,” 2020. [Online]. Available: https://arxiv.org/abs/2007.02832
-
[66]
arXiv preprint arXiv:1903.03698 , year=
V . H. Pong, M. Dalal, S. Lin, A. Nair, S. Bahl, and S. Levine, “Skew-fit: State-covering self- supervised reinforcement learning,” 2020. [Online]. Available: https://arxiv.org/abs/1903.03698
-
[67]
CLIC: Curriculum Learning and Imitation for object Control in non-rewarding environments
P. Fournier, O. Sigaud, C. Colas, and M. Chetouani, “Clic: Curriculum learning and imitation for object control in non-rewarding environments,” 2019. [Online]. Available: https://arxiv.org/abs/1901.09720
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[68]
Goal-gan: Multimodal trajectory prediction based on goal position estimation,
P. Dendorfer, A. Oˇsep, and L. Leal-Taix´e, “Goal-gan: Multimodal trajectory prediction based on goal position estimation,” 2020. [Online]. Available: https://arxiv.org/abs/2010.01114
-
[69]
T. Schaul, J. Quan, I. Antonoglou, and D. Silver, “Prioritized experience replay,” 2016. [Online]. Available: https://arxiv.org/abs/1511.05952 14 Supplementary Material Table of Contents A Policy gradient algorithms 16 B Proof of Theorem 3.1 17 C Additional method 19 C.1 An algorithm for selecting high learnability questions with no additional sampling co...
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[70]
Loss-Based Methods: Many methods use loss to prioritize training on hard data points [45, 46, 47]. In [48] the authors use the loss from a pre-trained model to estimate the difficulty of new samples for a freshly initialized network learning a new task
-
[71]
LILO can be seen as using return variance—or learnability—as an estimator of entropy or uncertainty
Uncertainty or Entropy : Several papers use the entropy of the answer distribution to prioritize training on data points the model is “unsure” about [ 49, 50, 51]. LILO can be seen as using return variance—or learnability—as an estimator of entropy or uncertainty. For Bernoulli random variables, as in the reasoning setting, maximum entropy corresponds to ...
-
[72]
Information Gain or Learning Progress: In some settings, it is possible to estimate or empirically compute the effect of training on a data point. This allows prioritizing samples that maximize the change in loss—i.e., the model’s learning progress [ 52, 11, 53, 49]. One can also aim to maximize the change in entropy or information gain [49, 53]. These ap...
-
[73]
Gradient-Based Approaches: One can select data points that minimize the variance of the gradient estimator computed by SGD [54, 55]. Self-paced learning [56] is an early approach that allows the model to determine the pace at which it incorporates harder examples with higher values of U. [ 57, 58] introduced the concept of a teacher–student setup, where t...
-
[74]
Each bullet point contains a claim and a hyperlink to the section of the paper that proves the claim
Claims Question: Do the main claims made in the abstract and introduction accurately reflect the paper’s contributions and scope? Answer: [Yes] Justification: Yes, each claim in the abstract in the introduction is summarised succinctly in the bullet points on page 2. Each bullet point contains a claim and a hyperlink to the section of the paper that prove...
-
[75]
Section 7 also contains some limitations
Limitations Question: Does the paper discuss the limitations of the work performed by the authors? Answer: [Yes] Justification: Section 9 contains limitations of the work, including LILO ’s sampling over- head, discarding of useful data and restriction to verifiable binary reward tasks. Section 7 also contains some limitations. Guidelines: • The answer NA...
-
[76]
Guidelines: • The answer NA means that the paper does not include theoretical results
Theory assumptions and proofs 28 Question: For each theoretical result, does the paper provide the full set of assumptions and a complete (and correct) proof? Answer: [Yes] Justification: The assumptions for Theorem 3.1 are present in its definition in Section 3, the full proof is in Appendix B and is linked to from Section 3. Guidelines: • The answer NA ...
-
[77]
Experimental result reproducibility Question: Does the paper fully disclose all the information needed to reproduce the main ex- perimental results of the paper to the extent that it affects the main claims and/or conclusions of the paper (regardless of whether the code and data are provided or not)? Answer: [Yes] Justification: Our method is fully descri...
-
[78]
This is described in Section 5
Open access to data and code Question: Does the paper provide open access to the data and code, with sufficient instruc- tions to faithfully reproduce the main experimental results, as described in supplemental material? Answer: [Yes] Justification: As in the previous checlist item, our the results in 6 were produced using existing open-source codebases, ...
-
[79]
Experimental setting/details Question: Does the paper specify all the training and test details (e.g., data splits, hyper- parameters, how they were chosen, type of optimizer, etc.) necessary to understand the results? Answer: [Yes] Justification: We provide all the hyperparameters specific to our method in Section 5. All the other hyperparameters for tra...
-
[80]
Experiment statistical significance Question: Does the paper report error bars suitably and correctly defined or other appropriate information about the statistical significance of the experiments? 30 Answer: [No] Justification: Since LLM training is computationally expensive we were unable to run the additional experiments needed to plot error bars. We h...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.