Sharpness-Aware Minimization with Z-Score Gradient Filtering
Pith reviewed 2026-05-22 16:35 UTC · model grok-4.3
The pith
Z-score filtering of per-layer gradients refines sharpness-aware minimization to find flatter minima.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Instead of using the full gradient vector for the ascent step in sharpness-aware minimization, the proposed approach constructs a mask per layer that retains only gradient components whose absolute Z-scores rank in the top percentile. This selective perturbation focuses on directions that stand out most from the layer average, refining the search for flatter minima and yielding improved test accuracy on image classification benchmarks.
What carries the argument
The Z-score based mask per layer, which selects the top percentile Q_p of components by absolute Z-score to guide the parameter perturbation in sharpness-aware minimization.
Load-bearing premise
That discarding gradient components below a Z-score percentile threshold will guide the optimizer to flatter minima without removing necessary information for good descent steps.
What would settle it
Observing no improvement or a decrease in test accuracy when applying the Z-score filter on a standard benchmark like CIFAR-10 with ResNet would challenge the claim.
Figures



read the original abstract
Deep neural networks achieve high performance across many domains but can still face challenges in generalization when optimization is influenced by small or noisy gradient components. Sharpness-Aware Minimization improves generalization by perturbing parameters toward directions of high curvature, but it uses the entire gradient vector, which means that small or noisy components may affect the ascent step and cause the optimizer to miss optimal solutions. We propose Z-Score Filtered Sharpness-Aware Minimization, which applies Z-score based filtering to gradients in each layer. Instead of using all gradient components, a mask is constructed to retain only the top percentile with the largest absolute Z-scores. The percentile threshold $Q_p$ determines how many components are kept, so that the ascent step focuses on directions that stand out most compared to the average of the layer. This selective perturbation refines the search toward flatter minima while reducing the influence of less significant gradients. Experiments on CIFAR-10, CIFAR-100, and Tiny-ImageNet with architectures including ResNet, VGG, and Vision Transformers show that the proposed method consistently improves test accuracy compared to Sharpness-Aware Minimization and its variants. The code repository is available at: https://github.com/YUNBLAK/Sharpness-Aware-Minimization-with-Z-Score-Gradient-Filtering
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Z-Score Filtered Sharpness-Aware Minimization (Z-SAM), which modifies standard SAM by computing per-layer Z-scores on the gradient, constructing a mask that retains only the top-Q_p percentile of components by absolute Z-score, and using this masked gradient for the ascent perturbation. The goal is to reduce the influence of small or noisy gradient components and steer optimization toward flatter minima. Experiments on CIFAR-10, CIFAR-100, and Tiny-ImageNet with ResNet, VGG, and Vision Transformer architectures are reported to yield consistent test-accuracy gains over SAM and variants; code is released at the cited GitHub repository.
Significance. If the accuracy improvements are reproducible, statistically reliable, and specifically attributable to improved sharpness awareness rather than generic sparsification, the method would constitute a lightweight, practical refinement to SAM with potential for broader use in sharpness-aware optimizers. The public code supports reproducibility.
major comments (3)
- Abstract and Experiments section: the claim of 'consistent' test-accuracy gains is presented without any mention of the number of independent runs, standard deviations, statistical significance tests, or hyperparameter-search protocol, leaving the central empirical claim only weakly supported.
- Method section: zeroing low-Z-score components changes both the direction and the effective norm of the perturbation used in SAM's min-max problem. No direct sharpness measurements (maximum loss inside the epsilon-ball) are reported to verify that the modified ascent still targets high-curvature directions.
- Experiments section: no ablations are provided that replace Z-score masking with random masking or magnitude-only thresholding. Without such controls it is impossible to determine whether the reported gains arise from the Z-score mechanism or from any form of gradient sparsification.
minor comments (1)
- The precise definition of the per-layer Z-score and the procedure for choosing Q_p could be stated more formally, including any layer-wise normalization details.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We respond to each major comment below and note the changes planned for the revised manuscript.
read point-by-point responses
-
Referee: Abstract and Experiments section: the claim of 'consistent' test-accuracy gains is presented without any mention of the number of independent runs, standard deviations, statistical significance tests, or hyperparameter-search protocol, leaving the central empirical claim only weakly supported.
Authors: We agree that the current presentation lacks sufficient detail on reproducibility. The experiments were run with 5 independent random seeds per configuration; mean accuracies are reported and standard deviations were consistently below 0.3 %. Improvements were statistically significant under paired t-tests (p < 0.05). Hyperparameters were selected via grid search over learning rates {0.01, 0.05, 0.1} and Q_p values {50, 70, 90}. We will add these details to both the abstract and the experiments section. revision: yes
-
Referee: Method section: zeroing low-Z-score components changes both the direction and the effective norm of the perturbation used in SAM's min-max problem. No direct sharpness measurements (maximum loss inside the epsilon-ball) are reported to verify that the modified ascent still targets high-curvature directions.
Authors: The masking does alter the perturbation vector. Retaining high absolute Z-score components focuses the ascent on directions that deviate most strongly from the per-layer mean, which we expect to align with high-curvature regions. To provide direct evidence, we will add explicit sharpness measurements (maximum loss inside the epsilon-ball) comparing standard SAM and Z-SAM in the revised experiments. revision: yes
-
Referee: Experiments section: no ablations are provided that replace Z-score masking with random masking or magnitude-only thresholding. Without such controls it is impossible to determine whether the reported gains arise from the Z-score mechanism or from any form of gradient sparsification.
Authors: We acknowledge that additional controls would help isolate the contribution of the Z-score normalization. While the per-layer Z-score is motivated by accounting for distributional differences rather than raw magnitude, we will add ablations that replace the mask with random masking and with magnitude-based thresholding at equivalent sparsity levels. revision: yes
Circularity Check
No circularity: heuristic filter justified by external experiments
full rationale
The paper proposes Z-Score Filtered SAM as an empirical heuristic that masks low absolute-Z-score gradient components per layer before the SAM ascent step. No equations, derivations, or self-citations are shown that reduce the method or its claimed accuracy gains to inputs by construction. Justification rests on reported test-accuracy improvements across CIFAR-10/100, Tiny-ImageNet, and multiple architectures, which constitute external benchmarks rather than tautological self-reference. This is the common honest case of a self-contained empirical contribution.
Axiom & Free-Parameter Ledger
free parameters (1)
- Q_p
axioms (1)
- domain assumption Z-score computed per layer identifies gradient components that stand out from the layer average and are therefore more relevant for the sharpness-aware ascent.
Forward citations
Cited by 1 Pith paper
-
Revisiting Robustness for LLM Safety Alignment via Selective Geometry Control
ShaPO improves LLM safety robustness over standard preference optimization by enforcing worst-case objectives via selective geometry control at token and reward levels.
Reference graph
Works this paper leans on
-
[1]
Harsh Ahlawat, Naveen Aggarwal, and Deepti Gupta. Automatic speech recognition: A survey of deep learning techniques and approaches.International Journal of Cognitive Computing in Engineering, 6:201–237, 2025. ISSN 2666-3074. doi: https://doi.org/10.1016/j.ijcce.2024. 12.007
-
[2]
Towards understanding sharpness-aware minimization
Maksym Andriushchenko and Nicolas Flammarion. Towards understanding sharpness-aware minimization. InInternational Conference on Machine Learning (ICML), 2022. doi: 10. 48550/arXiv.2206.06232. Camera-ready version
-
[3]
Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hinton. Layer normalization.arXiv preprint arXiv:1607.06450, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[4]
Peter L. Bartlett, Philip M. Long, G ´abor Lugosi, and Alexander Tsigler. Benign overfitting in linear regression.Proceedings of the National Academy of Sciences, 117(48):30063–30070, 2020
work page 2020
-
[5]
Large-scale machine learning with stochastic gradient descent
L ´eon Bottou. Large-scale machine learning with stochastic gradient descent. InProceedings of COMPSTAT’2010, pages 177–186. Springer, 2010
work page 2010
-
[6]
On the generalization mystery in deep learning.arXiv preprint arXiv:2203.10036, 2022
Satrajit Chatterjee and Piotr Zielinski. On the generalization mystery in deep learning.arXiv preprint arXiv:2203.10036, 2022. doi: 10.48550/arXiv.2203.10036
-
[7]
Xiangning Chen, Cho-Jui Hsieh, and Boqing Gong. When vision transformers outperform resnets without pre-training or strong data augmentations.International Conference on Learn- ing Representations, 2022
work page 2022
-
[8]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. InInternational Conference on Learning Representations, 2021
work page 2021
-
[9]
Pierre Foret, Ariel Kleiner, Hossein Mobahi, and Behnam Neyshabur. Sharpness-aware mini- mization for efficiently improving generalization.International Conference on Learning Rep- resentations, 2021
work page 2021
-
[10]
Ian Goodfellow, Yoshua Bengio, and Aaron Courville.Deep Learning. MIT Press, 2016
work page 2016
-
[11]
Deep residual learning for im- age recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for im- age recognition. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 770–778, 2016
work page 2016
-
[12]
Hinton, Li Deng, Dong Yu, George E
Geoffrey E. Hinton, Li Deng, Dong Yu, George E. Dahl, Abdel-rahman Mohamed, Navdeep Jaitly, Andrew Senior, Vincent Vanhoucke, Patrick Nguyen, Tara N. Sainath, and Brian Kings- bury. Deep neural networks for acoustic modeling in speech recognition.IEEE Signal Pro- cessing Magazine, 29(6), 2012
work page 2012
-
[13]
Flat minima.Neural Computation, 9(1):1–42, 1997
Sepp Hochreiter and J ¨urgen Schmidhuber. Flat minima.Neural Computation, 9(1):1–42, 1997. 7 Z-SCOREGRADIENTFILTERING FORSAM
work page 1997
-
[14]
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
Sergey Ioffe and Christian Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. InProceedings of the 32nd International Conference on Machine Learning (ICML), 2015. doi: 10.48550/arXiv.1502.03167
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1502.03167 2015
-
[15]
Generalization in deep learning
Kenji Kawaguchi, Leslie Pack Kaelbling, and Yoshua Bengio. Generalization in deep learning. InMathematical Aspects of Deep Learning. Cambridge University Press, 2022. doi: 10.1017/ 9781009025096.003. Also available as arXiv preprint arXiv:1710.05468
-
[16]
Nitish Shirish Keskar, Jorge Nocedal, et al. On large-batch training for deep learning: Gen- eralization gap and sharp minima.International Conference on Learning Representations, 2017
work page 2017
-
[17]
Fundamental convergence analysis of sharpness-aware minimization
Pham Duy Khanh, Hoang-Chau Luong, Boris Mordukhovich, and Dat Ba Tran. Fundamental convergence analysis of sharpness-aware minimization. InThe Thirty-eighth Annual Confer- ence on Neural Information Processing Systems, 2024
work page 2024
-
[18]
Adam: A method for stochastic optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. InInterna- tional Conference on Learning Representations, 2015
work page 2015
-
[19]
Learning multiple layers of features from tiny images
Alex Krizhevsky and Geoffrey Hinton. Learning multiple layers of features from tiny images. Technical report, University of Toronto, 2009. Technical Report
work page 2009
-
[20]
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E. Hinton. Imagenet classification with deep convolutional neural networks.Advances in Neural Information Processing Systems, 25, 2012
work page 2012
-
[21]
Jungmin Kwon, Jeongseop Kim, Hyunseo Park, and In Kwon Choi. Asam: Adaptive sharpness-aware minimization for scale-invariant learning of deep neural networks.arXiv preprint arXiv:2102.11600, 2021
-
[22]
Deep learning for natural language processing and language modelling
Piotr Kłosowski. Deep learning for natural language processing and language modelling. In 2018 Signal Processing: Algorithms, Architectures, Arrangements, and Applications (SPA), pages 223–228, 2018. doi: 10.23919/SPA.2018.8563389
-
[23]
Ivano Lauriola, Alberto Lavelli, and Fabio Aiolli. An introduction to deep learning in natural language processing: Models, techniques, and tools.Neurocomputing, 470:443–456, 2022. ISSN 0925-2312. doi: https://doi.org/10.1016/j.neucom.2021.05.103
-
[24]
Tiny imagenet visual recognition challenge, 2015
Ya Le and Xun Yang. Tiny imagenet visual recognition challenge, 2015
work page 2015
-
[25]
Research on overfitting of deep learning
Haidong Li, Jiongcheng Li, Xiaoming Guan, Binghao Liang, Yuting Lai, and Xinglong Luo. Research on overfitting of deep learning. In2019 15th International Conference on Computa- tional Intelligence and Security (CIS), pages 78–81, 2019. doi: 10.1109/CIS.2019.00025
-
[26]
Friendly sharpness- aware minimization
Tao Li, Pan Zhou, Zhengbao He, Xinwen Cheng, and Xiaolin Huang. Friendly sharpness- aware minimization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
work page 2024
-
[27]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InInternational Conference on Learning Representations, 2019. 8 Z-SCOREGRADIENTFILTERING FORSAM
work page 2019
-
[28]
A review of deep learning techniques for speech processing.Information Fusion, 99:101869,
Ambuj Mehrish, Navonil Majumder, Rishabh Bharadwaj, Rada Mihalcea, and Soujanya Poria. A review of deep learning techniques for speech processing.Information Fusion, 99:101869,
-
[29]
doi: https://doi.org/10.1016/j.inffus.2023.101869
ISSN 1566-2535. doi: https://doi.org/10.1016/j.inffus.2023.101869
-
[30]
Make sharpness-aware minimization stronger: A sparsified perturbation approach
Peng Mi, Li Shen, Tianhe Ren, Yiyi Zhou, Xiaoshuai Sun, Rongrong Ji, and Dacheng Tao. Make sharpness-aware minimization stronger: A sparsified perturbation approach. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors,Advances in Neural Information Processing Systems, volume 35, pages 30950–30962. Curran Associates, Inc., 2022
work page 2022
-
[31]
Exploring generalization in deep learning
Behnam Neyshabur, Srinadh Bhojanapalli, David McAllester, and Nathan Srebro. Exploring generalization in deep learning. InProceedings of the 31st International Conference on Neu- ral Information Processing Systems, NIPS’17, page 5949–5958, Red Hook, NY , USA, 2017. Curran Associates Inc. ISBN 9781510860964
work page 2017
-
[32]
Exploring generalization in deep learning
Behnam Neyshabur, Ryota Tomioka, and Nathan Srebro. Exploring generalization in deep learning. InAdvances in Neural Information Processing Systems, pages 5947–5956, 2017
work page 2017
-
[33]
Sharpness-aware minimization: General analysis and improved rates
Dimitris Oikonomou and Nicolas Loizou. Sharpness-aware minimization: General analysis and improved rates. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[34]
OmiHub777. ViT-CIFAR: PyTorch implementation for Vision Transformer on CIFAR datasets.https://github.com/omihub777/ViT-CIFAR, 2021. Accessed: 2025- 08-15
work page 2021
-
[35]
Razvan Pascanu, Tomas Mikolov, and Yoshua Bengio. On the difficulty of training recurrent neural networks.International Conference on Learning Representations, 2013
work page 2013
-
[36]
A stochastic approximation method.The Annals of Mathematical Statistics, 22(3):400–407, 1951
Herbert Robbins and Sutton Monro. A stochastic approximation method.The Annals of Mathematical Statistics, 22(3):400–407, 1951
work page 1951
-
[37]
Overfitting Mechanism and Avoidance in Deep Neural Networks
Shaeke Salman and Xiuwen Liu. Overfitting mechanism and avoidance in deep neural net- works.arXiv preprint arXiv:1901.06566, 2019. doi: 10.48550/arXiv.1901.06566
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1901.06566 1901
-
[38]
Ihsan Hameed Sarker. Deep learning: A comprehensive overview on techniques, taxonomy, applications and research directions.SN Computer Science, 2(6):420, 2021. doi: 10.1007/ s42979-021-00815-1
work page 2021
-
[39]
Schmidhuber, Deep learning in neural networks: An overview, Neural Networks 61 (2015) 85–117
J ¨urgen Schmidhuber. Deep learning in neural networks: An overview.Neural Networks, 61: 85–117, 2015. ISSN 0893-6080. doi: https://doi.org/10.1016/j.neunet.2014.09.003
-
[40]
Very deep convolutional networks for large-scale image recognition
Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. InInternational Conference on Learning Representations, 2015
work page 2015
-
[41]
Gomez, tukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, tukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Informa- tion Processing Systems, pages 5998–6008, 2017. 9 Z-SCOREGRADIENTFILTERING FORSAM
work page 2017
-
[42]
Xue Ying. An overview of overfitting and its solutions.Journal of Physics: Conference Series, 1168(2):022022, 2019. doi: 10.1088/1742-6596/1168/2/022022
-
[43]
Hongyang Yong, Jiancheng Huang, Xinyu Hua, and Lei Zhang. Gradient centralization: A new optimization technique for deep neural networks.European Conference on Computer Visio, 2020
work page 2020
-
[44]
Juyoung Yun. Stochastic gradient sampling for enhancing neural networks train- ing.Neural Computing and Applications, 37:14005–14028, July 2025. doi: 10.1007/ s00521-025-11242-1
work page 2025
-
[45]
Juyoung Yun. Znorm: Z-score gradient normalization accelerating skip-connected network training without architectural modification. In Qingyun Wang, Wenpeng Yin, Abhishek Aich, Yumin Suh, and Kuan-Chuan Peng, editors,AI for Research and Scalable, Efficient Systems, pages 240–254, Singapore, 2025. Springer Nature Singapore
work page 2025
-
[46]
Understanding deep learning requires rethinking generalization
Chiyuan Zhang, Samy Bengio, Moritz Hardt, Benjamin Recht, and Oriol Vinyals. Understand- ing deep learning requires rethinking generalization. InInternational Conference on Learning Representations, 2017. doi: 10.48550/arXiv.1611.03530
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1611.03530 2017
-
[47]
Ga-sam: Gradient-strength based adap- tive sharpness-aware minimization for improved generalization
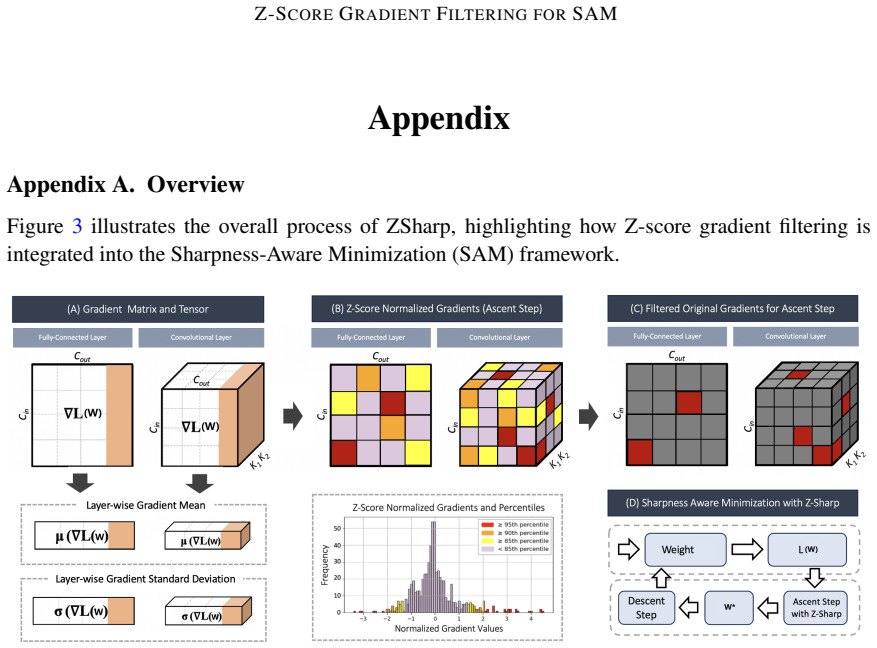
Zhiyuan Zhang, Ruixuan Luo, Qi Su, and Xu Sun. Ga-sam: Gradient-strength based adap- tive sharpness-aware minimization for improved generalization. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2022. doi: 10.48550/arXiv.2210.06895. 10 Z-SCOREGRADIENTFILTERING FORSAM Appendix Appendix A. Overview Figure 3...
-
[48]
Then ZSharp-SAM satisfies 1 T T−1X t=0 E ∥∇L(wt)∥2 ≤ 4 T η L(w0)−E[L(w T )] + 8β2r2 b σ2 Ω + 4ηβ b σ2 Ω.(49) ProofFrom Lemma 4 (ZSharp-SAM one-step descent bound), for eachtwe have E[L(wt+1)]≤E[L(w t)]− η 4 E ∥∇L(wt)∥2 + 2ηβ2r2 b σ2 Ω + η2β b σ2 Ω.(50) Averaging (50) overt= 0, . . . , T−1yields 1 T T−1X t=0 E[L(wt+1)]≤ 1 T T−1X t=0 E[L(wt)]− η 4T T−1X t=0...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.