LoVeC: Reinforcement Learning for Better Verbalized Confidence in Long-Form Generations
Pith reviewed 2026-05-19 12:39 UTC · model grok-4.3
pith:IOEXB33W Add to your LaTeX paper
What is a Pith Number?\usepackage{pith}
\pithnumber{IOEXB33W}
Prints a linked pith:IOEXB33W badge after your title and writes the identifier into PDF metadata. Compiles on arXiv with no extra files. Learn more
The pith
Reinforcement learning trains language models to attach accurate numerical confidence scores to each statement in long-form outputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LoVeC uses reinforcement learning to optimize large language models so they append an on-the-fly numerical confidence score to each generated statement in long-form question answering. In free-form and iterative tagging evaluation settings, the resulting models produce better-calibrated scores than prior verbalized approaches, generalize across domains on three long-form QA datasets, and run approximately twenty times faster than self-consistency baselines while achieving superior calibration.
What carries the argument
The LoVeC reinforcement learning procedure, which directly optimizes the model to generate accurate verbalized numerical confidence scores during the course of long-form generation.
Load-bearing premise
Reinforcement learning can directly optimize verbalized numerical confidence scores to be well-calibrated without relying on post-hoc consistency checks or external verifiers.
What would settle it
Run the trained models on a held-out long-form QA dataset and measure whether the emitted confidence scores correlate more strongly with actual statement accuracy than the scores from non-RL baselines; a clear drop in correlation would falsify the central claim.
Figures






read the original abstract
Hallucination remains a major challenge for the safe and trustworthy deployment of large language models (LLMs) in factual content generation. Prior work has explored confidence estimation as an effective approach to hallucination detection, but often relies on post-hoc self-consistency methods that require computationally expensive sampling. Verbalized confidence offers a more efficient alternative, but existing approaches are largely limited to short-form question answering (QA) tasks and do not generalize well to open-ended generation. In this paper, we propose LoVeC (Long-form Verbalized Confidence), a novel reinforcement learning based method that trains LLMs to append an on-the-fly numerical confidence score to each generated statement during long-form generation. The confidence score serves as a direct and interpretable signal of the factuality of generation. We introduce two evaluation settings, free-form tagging and iterative tagging, to assess different verbalized confidence estimation methods. Experiments on three long-form QA datasets show that our RL-trained models achieve better calibration and generalize robustly across domains. Also, our method is highly efficient, being 20 times faster than traditional self-consistency methods while achieving better calibration.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes LoVeC, a reinforcement learning method to train LLMs to append on-the-fly numerical confidence scores to each statement during long-form generation. It introduces free-form and iterative tagging evaluation settings and reports experiments on three long-form QA datasets showing improved calibration, robust cross-domain generalization, and a 20x inference-time speedup relative to self-consistency baselines.
Significance. If the central results are confirmed, the work would demonstrate that RL can be used to internalize calibration directly into the generation process for open-ended outputs, offering a more efficient alternative to sampling-based methods. The efficiency advantage at inference time would be a notable practical contribution for trustworthy long-form generation.
major comments (2)
- [Abstract] Abstract: The central claim of improved calibration via RL-trained verbalized confidence rests on the reward formulation, yet no details are provided on how the scalar reward per statement is computed (e.g., whether it uses ground-truth references, an auxiliary verifier, or another LLM). This information is load-bearing for assessing whether the method truly avoids external verifiers and for interpreting the reported 20x speedup.
- [Experiments] Experiments section: The abstract states that RL-trained models achieve better calibration and generalize robustly, but provides no information on the calibration metric (e.g., ECE or Brier score), the exact baselines, number of runs, error bars, or statistical significance tests. These omissions prevent verification of the quantitative claims.
minor comments (1)
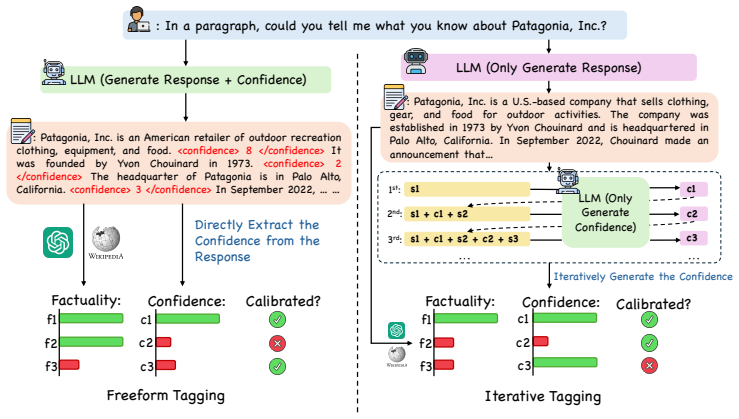
- [Evaluation Settings] Clarify the precise difference between the free-form tagging and iterative tagging protocols with an illustrative example of a generated statement and its tagged confidence score.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback on our manuscript. We have carefully reviewed each major comment and provide detailed responses below. We agree that additional clarifications are warranted and will revise the manuscript accordingly to improve clarity and verifiability.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of improved calibration via RL-trained verbalized confidence rests on the reward formulation, yet no details are provided on how the scalar reward per statement is computed (e.g., whether it uses ground-truth references, an auxiliary verifier, or another LLM). This information is load-bearing for assessing whether the method truly avoids external verifiers and for interpreting the reported 20x speedup.
Authors: We agree that the abstract would benefit from a concise description of the reward computation to make the central claims more self-contained. In Section 3.2 of the manuscript, the per-statement scalar reward is computed by comparing each generated statement against ground-truth references from the QA datasets via an automated factuality verifier (details in Appendix B). This verifier is used exclusively during RL training; at inference time the model generates verbalized confidence scores without any external components. This distinction is what enables the reported 20x speedup relative to sampling-based self-consistency. We will add a brief clause to the abstract summarizing the reward source and the training-versus-inference distinction. revision: yes
-
Referee: [Experiments] Experiments section: The abstract states that RL-trained models achieve better calibration and generalize robustly, but provides no information on the calibration metric (e.g., ECE or Brier score), the exact baselines, number of runs, error bars, or statistical significance tests. These omissions prevent verification of the quantitative claims.
Authors: We thank the referee for noting these gaps. Section 4.1 defines the primary calibration metric as Expected Calibration Error (ECE) with 10 equal-width bins; Brier score is reported as a secondary metric in the appendix. The main baselines are self-consistency sampling at 5, 10, and 20 samples, plus a verbalized-confidence baseline without RL. All quantitative results are averaged over 5 independent training runs with different random seeds; error bars show standard deviation. Statistical significance between LoVeC and the strongest baseline is assessed via paired t-tests (p < 0.05 reported in Table 2 and Appendix C). We will explicitly restate these experimental details in the main experiments section and ensure they appear in the abstract where space permits. revision: yes
Circularity Check
No significant circularity in LoVeC derivation chain
full rationale
The paper introduces an RL-based training procedure to produce verbalized numerical confidence scores during long-form generation. The RL objective optimizes for factuality signals in the generated statements, while evaluation relies on separate calibration metrics computed over held-out long-form QA datasets. These components do not reduce to each other by construction: the reward formulation during training is not shown to be identical to the post-training calibration scores, and no equations or self-citations are presented that would make the reported improvements tautological. The method is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Reinforcement learning can optimize verbalized confidence scores to match actual factuality in long-form text
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We design this confidence reward rconf for an output y using binary cross-entropy loss as below... rconf = λ · 1/n 1⊤ (1 + f ⊙ log(c) − (1 − f) ⊙ log(1 − c) / Rmax)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We explore both on-policy and off-policy RL methods, including DPO, ORPO, and GRPO
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Llama 2: Open foundation and fine-tuned chat models, 2023
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Harts...
work page 2023
-
[2]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. Mistral 7B, 2023
work page 2023
-
[3]
OpenAI. Chatgpt blog post. https://openai.com/blog/chatgpt, 2022. Accessed: 2024- 09-06
work page 2022
-
[4]
Siren's Song in the AI Ocean: A Survey on Hallucination in Large Language Models
Yue Zhang, Yafu Li, Leyang Cui, Deng Cai, Lemao Liu, Tingchen Fu, Xinting Huang, Enbo Zhao, Yu Zhang, Yulong Chen, et al. Siren’s song in the ai ocean: a survey on hallucination in large language models. ArXiv preprint, abs/2309.01219, 2023. URL https://arxiv.org/ abs/2309.01219
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qiang- long Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, and Ting Liu. A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions, 2023
work page 2023
-
[6]
LUQ: Long-text uncertainty quantification for LLMs
Caiqi Zhang, Fangyu Liu, Marco Basaldella, and Nigel Collier. LUQ: Long-text uncertainty quantification for LLMs. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors, Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 5244–5262, Miami, Florida, USA, November 2024. Association for Computational Linguisti...
-
[7]
Atomic calibration of llms in long-form generations, 2024
Caiqi Zhang, Ruihan Yang, Zhisong Zhang, Xinting Huang, Sen Yang, Dong Yu, and Nigel Collier. Atomic calibration of llms in long-form generations, 2024
work page 2024
-
[8]
Logu: Long-form generation with uncertainty expressions, 2024
Ruihan Yang, Caiqi Zhang, Zhisong Zhang, Xinting Huang, Sen Yang, Nigel Collier, Dong Yu, and Deqing Yang. Logu: Long-form generation with uncertainty expressions, 2024. URL https://arxiv.org/abs/2410.14309
-
[9]
Uncle: Uncertainty expressions in long-form generation, 2025
Ruihan Yang, Caiqi Zhang, Zhisong Zhang, Xinting Huang, Dong Yu, Nigel Collier, and Deqing Yang. Uncle: Uncertainty expressions in long-form generation, 2025
work page 2025
-
[10]
SelfCheckGPT: Zero-resource black- box hallucination detection for generative large language models
Potsawee Manakul, Adian Liusie, and Mark Gales. SelfCheckGPT: Zero-resource black- box hallucination detection for generative large language models. In Houda Bouamor, Juan Pino, and Kalika Bali, editors, Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 9004–9017, Singapore, December 2023. Association for Comput...
-
[11]
Hanxing Ding, Liang Pang, Zihao Wei, Huawei Shen, and Xueqi Cheng. Retrieve only when it needs: Adaptive retrieval augmentation for hallucination mitigation in large language models. arXiv preprint arXiv:2402.10612, 2024
-
[12]
Calibrating long-form generations from large language models, 2024
Yukun Huang, Yixin Liu, Raghuveer Thirukovalluru, Arman Cohan, and Bhuwan Dhingra. Calibrating long-form generations from large language models, 2024
work page 2024
-
[13]
Graph-based uncertainty metrics for long-form language model outputs
Mingjian Jiang, Yangjun Ruan, Prasanna Sattigeri, Salim Roukos, and Tatsunori Hashimoto. Graph-based uncertainty metrics for long-form language model outputs. ArXiv preprint, abs/2410.20783, 2024. URL https://arxiv.org/abs/2410.20783
-
[14]
Generating with confidence: Uncertainty quantification for black-box large language models, 2023
Zhen Lin, Shubhendu Trivedi, and Jimeng Sun. Generating with confidence: Uncertainty quantification for black-box large language models, 2023
work page 2023
-
[15]
Fact-checking the output of large language models via token-level uncertainty quantification
Ekaterina Fadeeva, Aleksandr Rubashevskii, Artem Shelmanov, Sergey Petrakov, Haonan Li, Hamdy Mubarak, Evgenii Tsymbalov, Gleb Kuzmin, Alexander Panchenko, Timothy Baldwin, Preslav Nakov, and Maxim Panov. Fact-checking the output of large language models via token-level uncertainty quantification. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,...
work page 2024
-
[16]
Litcab: Lightweight language model calibration over short- and long-form responses
Xin Liu, Muhammad Khalifa, and Lu Wang. Litcab: Lightweight language model calibration over short- and long-form responses. In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024. URL https://openreview.net/forum?id=jH67LHVOIO
work page 2024
-
[17]
OpenAI. Gpt-4 technical report, 2023. URL https://arxiv.org/abs/2303.08774
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
Manning, Stefano Ermon, and Chelsea Finn
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D. Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. In Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine, editors, Advances in Neural Information Processing Systems 36: Annual Conference ...
work page 2023
-
[19]
Survey on large language model-enhanced reinforcement learning: Concept, taxonomy, and methods
Yuji Cao, Huan Zhao, Yuheng Cheng, Ting Shu, Yue Chen, Guolong Liu, Gaoqi Liang, Junhua Zhao, Jinyue Yan, and Yun Li. Survey on large language model-enhanced reinforcement learning: Concept, taxonomy, and methods. IEEE Transactions on Neural Networks and Learning Systems, 2024
work page 2024
-
[20]
RLAIF vs. RLHF: Scaling Reinforcement Learning from Human Feedback with AI Feedback
Harrison Lee, Samrat Phatale, Hassan Mansoor, Thomas Mesnard, Johan Ferret, Kellie Lu, Colton Bishop, Ethan Hall, Victor Carbune, Abhinav Rastogi, et al. Rlaif vs. rlhf: Scaling rein- forcement learning from human feedback with ai feedback. arXiv preprint arXiv:2309.00267, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
Understanding the Effects of RLHF on LLM Generalisation and Diversity
Robert Kirk, Ishita Mediratta, Christoforos Nalmpantis, Jelena Luketina, Eric Hambro, Edward Grefenstette, and Roberta Raileanu. Understanding the effects of rlhf on llm generalisation and diversity. arXiv preprint arXiv:2310.06452, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
Meta. Llama 3 model card. 2024. URL https://github.com/meta-llama/llama3/blob/ main/MODEL_CARD.md
work page 2024
-
[23]
Gemma 2: Improving Open Language Models at a Practical Size
Gemma Team, Morgane Riviere, Shreya Pathak, Pier Giuseppe Sessa, Cassidy Hardin, Surya Bhupatiraju, Léonard Hussenot, Thomas Mesnard, Bobak Shahriari, Alexandre Ramé, et al. Gemma 2: Improving open language models at a practical size. arXiv preprint arXiv:2408.00118, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Correcting length bias in neural machine translation
Kenton Murray and David Chiang. Correcting length bias in neural machine translation. In Ondˇrej Bojar, Rajen Chatterjee, Christian Federmann, Mark Fishel, Yvette Graham, Barry Haddow, Matthias Huck, Antonio Jimeno Yepes, Philipp Koehn, Christof Monz, Matteo Negri, Aurélie Névéol, Mariana Neves, Matt Post, Lucia Specia, Marco Turchi, and Karin Verspoor, 1...
-
[25]
Lorenz Kuhn, Yarin Gal, and Sebastian Farquhar. Semantic uncertainty: Linguistic invari- ances for uncertainty estimation in natural language generation. In The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenRe- view.net, 2023. URL https://openreview.net/pdf?id=VD-AYtP0dve
work page 2023
-
[26]
Efficient out-of-domain detection for sequence to sequence models
Artem Vazhentsev, Akim Tsvigun, Roman Vashurin, Sergey Petrakov, Daniil Vasilev, Maxim Panov, Alexander Panchenko, and Artem Shelmanov. Efficient out-of-domain detection for sequence to sequence models. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki, editors, Findings of the Association for Computational Linguistics: ACL 2023 , pages 1430– 1454, T...
work page 2023
-
[27]
Shifting attention to relevance: Towards the uncertainty estimation of large language models
Jinhao Duan, Hao Cheng, Shiqi Wang, Chenan Wang, Alex Zavalny, Renjing Xu, Bhavya Kailkhura, and Kaidi Xu. Shifting attention to relevance: Towards the uncertainty estimation of large language models. ArXiv preprint, abs/2307.01379, 2023. URL https://arxiv.org/ abs/2307.01379
-
[28]
On the calibration of large language models and alignment
Chiwei Zhu, Benfeng Xu, Quan Wang, Yongdong Zhang, and Zhendong Mao. On the calibration of large language models and alignment. In Houda Bouamor, Juan Pino, and Kalika Bali, editors, Findings of the Association for Computational Linguistics: EMNLP 2023, pages 9778–9795, Singapore, December 2023. Association for Computational Linguistics. doi: 10.18653/v1/...
-
[29]
Can llms express their uncertainty? an empirical evaluation of confidence elicitation in llms
Miao Xiong, Zhiyuan Hu, Xinyang Lu, Yifei Li, Jie Fu, Junxian He, and Bryan Hooi. Can llms express their uncertainty? an empirical evaluation of confidence elicitation in llms. In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Aus- tria, May 7-11, 2024. OpenReview.net, 2024. URL https://openreview.net/forum?id= gjeQKFxFpZ
work page 2024
-
[30]
Katherine Tian, Eric Mitchell, Allan Zhou, Archit Sharma, Rafael Rafailov, Huaxiu Yao, Chelsea Finn, and Christopher Manning. Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback. In Houda Bouamor, Juan Pino, and Kalika Bali, editors,Proceedings of the 2023 Conference on Empiri...
-
[31]
Calibrating large language models using their generations only
Dennis Ulmer, Martin Gubri, Hwaran Lee, Sangdoo Yun, and Seong Oh. Calibrating large language models using their generations only. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors, Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15440–15459, Bangkok, Thailand, August 2024. Ass...
-
[32]
Language models with conformal factuality guarantees
Christopher Mohri and Tatsunori Hashimoto. Language models with conformal factuality guarantees. In Forty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024. OpenReview.net, 2024. URL https://openreview.net/forum? id=uYISs2tpwP
work page 2024
-
[33]
Qinyuan Cheng, Tianxiang Sun, Xiangyang Liu, Wenwei Zhang, Zhangyue Yin, Shimin Li, Linyang Li, Zhengfu He, Kai Chen, and Xipeng Qiu. Can AI assistants know what they don’t know? In Forty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024. OpenReview.net, 2024. URL https://openreview.net/forum? id=girxGkdECL
work page 2024
-
[34]
Teaching large language models to express knowledge boundary from their own signals, 2024
Lida Chen, Zujie Liang, Xintao Wang, Jiaqing Liang, Yanghua Xiao, Feng Wei, Jinglei Chen, Zhenghong Hao, Bing Han, and Wei Wang. Teaching large language models to express knowledge boundary from their own signals, 2024. URL https://arxiv.org/abs/2406. 10881. 12
work page 2024
-
[35]
Know the unknown: An uncertainty-sensitive method for llm instruction tuning, 2024
Jiaqi Li, Yixuan Tang, and Yi Yang. Know the unknown: An uncertainty-sensitive method for llm instruction tuning, 2024. URL https://arxiv.org/abs/2406.10099
-
[36]
Teaching Models to Express Their Uncertainty in Words
Stephanie Lin, Jacob Hilton, and Owain Evans. Teaching models to express their uncertainty in words. ArXiv preprint, abs/2205.14334, 2022. URL https://arxiv.org/abs/2205.14334
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[37]
Sayself: Teaching llms to express confidence with self-reflective rationales, 2024
Tianyang Xu, Shujin Wu, Shizhe Diao, Xiaoze Liu, Xingyao Wang, Yangyi Chen, and Jing Gao. Sayself: Teaching llms to express confidence with self-reflective rationales, 2024
work page 2024
-
[38]
doi: 10.18653/v1/2024.naacl-long.394
Hanning Zhang, Shizhe Diao, Yong Lin, Yi Fung, Qing Lian, Xingyao Wang, Yangyi Chen, Heng Ji, and Tong Zhang. R-tuning: Instructing large language models to say ‘I don‘t know’. In Kevin Duh, Helena Gomez, and Steven Bethard, editors,Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Lan...
-
[39]
Enhancing confidence expression in large language models through learning from past experience, 2024
Haixia Han, Tingyun Li, Shisong Chen, Jie Shi, Chengyu Du, Yanghua Xiao, Jiaqing Liang, and Xin Lin. Enhancing confidence expression in large language models through learning from past experience, 2024. URL https://arxiv.org/abs/2404.10315
-
[40]
Paul Stangel, David Bani-Harouni, Chantal Pellegrini, Ege Özsoy, Kamilia Zaripova, Matthias Keicher, and Nassir Navab. Rewarding doubt: A reinforcement learning approach to confidence calibration of large language models. arXiv preprint arXiv:2503.02623, 2025
-
[41]
Linguistic calibration of long- form generations
Neil Band, Xuechen Li, Tengyu Ma, and Tatsunori Hashimoto. Linguistic calibration of long- form generations. In Forty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024. OpenReview.net, 2024. URL https://openreview.net/ forum?id=rJVjQSQ8ye
work page 2024
-
[42]
Training language models to follow instructions with human feedback
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. Advances in neural information processing systems, 35:27730–27744, 2022
work page 2022
-
[43]
Amrith Setlur, Nived Rajaraman, Sergey Levine, and Aviral Kumar. Scaling test-time compute without verification or rl is suboptimal. arXiv preprint arXiv:2502.12118, 2025
-
[44]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
R-tuning: Instructing large language models to say ‘I don’t know’
Hanning Zhang, Shizhe Diao, Yong Lin, Yi Fung, Qing Lian, Xingyao Wang, Yangyi Chen, Heng Ji, and Tong Zhang. R-tuning: Instructing large language models to say ‘I don’t know’. In Kevin Duh, Helena Gomez, and Steven Bethard, editors,Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Lan...
work page 2024
-
[46]
URL https://aclanthology.org/2024
Association for Computational Linguistics. URL https://aclanthology.org/2024. naacl-long.394
work page 2024
-
[47]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Y Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models, 2024. URL https://arxiv. org/abs/2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[48]
Training Language Models to Self-Correct via Reinforcement Learning
Aviral Kumar, Vincent Zhuang, Rishabh Agarwal, Yi Su, John D Co-Reyes, Avi Singh, Kate Baumli, Shariq Iqbal, Colton Bishop, Rebecca Roelofs, et al. Training language models to self-correct via reinforcement learning. arXiv preprint arXiv:2409.12917, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[49]
Teaching large language models to reason with reinforcement learning
Alex Havrilla, Yuqing Du, Sharath Chandra Raparthy, Christoforos Nalmpantis, Jane Dwivedi- Yu, Maksym Zhuravinskyi, Eric Hambro, Sainbayar Sukhbaatar, and Roberta Raileanu. Teaching large language models to reason with reinforcement learning. arXiv preprint arXiv:2403.04642, 2024. 13
-
[50]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. Advances in Neural Information Processing Systems, 36:53728–53741, 2023
work page 2023
-
[51]
ORPO: Monolithic Preference Optimization without Reference Model
Jiwoo Hong, Noah Lee, and James Thorne. Orpo: Monolithic preference optimization without reference model. arXiv preprint arXiv:2403.07691, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[52]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[53]
Deep reinforcement learning from human preferences
Paul F Christiano, Jan Leike, Tom Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep reinforcement learning from human preferences. Advances in neural information processing systems, 30, 2017
work page 2017
-
[54]
Wildhallucinations: Evaluating long-form factuality in llms with real-world entity queries, 2024
Wenting Zhao, Tanya Goyal, Yu Ying Chiu, Liwei Jiang, Benjamin Newman, Abhilasha Ravichander, Khyathi Chandu, Ronan Le Bras, Claire Cardie, Yuntian Deng, and Yejin Choi. Wildhallucinations: Evaluating long-form factuality in llms with real-world entity queries, 2024. URL https://arxiv.org/abs/2407.17468
-
[55]
FActScore: Fine-grained atomic evaluation of factual precision in long form text generation
Sewon Min, Kalpesh Krishna, Xinxi Lyu, Mike Lewis, Wen-tau Yih, Pang Koh, Mohit Iyyer, Luke Zettlemoyer, and Hannaneh Hajishirzi. FActScore: Fine-grained atomic evaluation of factual precision in long form text generation. In Houda Bouamor, Juan Pino, and Kalika Bali, editors, Proceedings of the 2023 Conference on Empirical Methods in Natural Language Pro...
-
[56]
Alex Mallen, Akari Asai, Victor Zhong, Rajarshi Das, Daniel Khashabi, and Hannaneh Hajishirzi. When not to trust language models: Investigating effectiveness of paramet- ric and non-parametric memories. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki, editors, Proceedings of the 61st Annual Meeting of the Association for Compu- tational Linguistics...
-
[57]
doi: 10.18653/v1/2023.acl-long.546
Association for Computational Linguistics. doi: 10.18653/v1/2023.acl-long.546. URL https://aclanthology.org/2023.acl-long.546/
-
[58]
Language models (mostly) know what they know, 2022
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, Scott Johnston, Sheer El-Showk, Andy Jones, Nelson Elhage, Tristan Hume, Anna Chen, Yuntao Bai, Sam Bowman, Stanislav Fort, Deep Ganguli, Danny Hernandez, Josh Jacobson, Jackson Kernion, Shauna Kravec,...
work page 2022
-
[59]
Calibrating long-form generations from large language models
Yukun Huang, Yixin Liu, Raghuveer Thirukovalluru, Arman Cohan, and Bhuwan Dhingra. Calibrating long-form generations from large language models. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors,Findings of the Association for Computational Linguistics: EMNLP 2024, pages 13441–13460, Miami, Florida, USA, November 2024. Association for Computat...
-
[60]
TriviaQA: A large scale distantly supervised challenge dataset for reading comprehension
Mandar Joshi, Eunsol Choi, Daniel Weld, and Luke Zettlemoyer. TriviaQA: A large scale distantly supervised challenge dataset for reading comprehension. In Regina Barzilay and Min-Yen Kan, editors, Proceedings of the 55th Annual Meeting of the Association for Com- putational Linguistics (Volume 1: Long Papers) , pages 1601–1611, Vancouver, Canada, July 201...
-
[61]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. InThe Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29,
work page 2022
-
[62]
URL https://openreview.net/forum?id=nZeVKeeFYf9
OpenReview.net, 2022. URL https://openreview.net/forum?id=nZeVKeeFYf9. 14
work page 2022
-
[63]
Trl: Transformer reinforce- ment learning
Leandro von Werra, Younes Belkada, Lewis Tunstall, Edward Beeching, Tristan Thrush, Nathan Lambert, Shengyi Huang, Kashif Rasul, and Quentin Gallouédec. Trl: Transformer reinforce- ment learning. https://github.com/huggingface/trl, 2020
work page 2020
-
[64]
Efficient memory management for large language model serving with pagedattention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. In Proceedings of the 29th Symposium on Operating Systems Principles, pages 611–626, 2023
work page 2023
-
[65]
Jerry Wei, Chengrun Yang, Xinying Song, Yifeng Lu, Nathan Hu, Jie Huang, Dustin Tran, Daiyi Peng, Ruibo Liu, Da Huang, Cosmo Du, and Quoc V . Le. Long-form fac- tuality in large language models. In Amir Globersons, Lester Mackey, Danielle Bel- grave, Angela Fan, Ulrich Paquet, Jakub M. Tomczak, and Cheng Zhang, editors, Ad- vances in Neural Information Pr...
work page 2024
-
[66]
For the comparison between GPT-4o and the human average, we observe a Spearman correlation of 0.88, indicating a very strong alignment between the model and human judgments. 17 D Additional Results on Llama-3-8B-Instruct D.1 Reliability Diagrams Figure 4 displays reliability diagrams for the SOTA method LUQ, the vanilla model,LoVeC-SFT, and LoVeC-DPO. A r...
work page 2000
-
[67]
Break down and assess the factual accuracy of each i n d i v i d u a l detail
-
[68]
Consider names , dates , locations , statistics , events , and a t t r i b u t i o n s
-
[69]
Assign a numeric ** veracity rating ** from 0 to 10 based on this scale : 0: C o m p l e t e l y inc or re ct - entirely false or m i s l e a d i n g . 26 1 -3: Mostly in cor re ct - several key i n a c c u r a c i e s . 4 -6: P art ia ll y correct - mix of accurate and i n a c c u r a t e i n f o r m a t i o n . 7 -9: Mostly correct - ge ne ra ll y accur...
work page 1903
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.