VS-Bench: Evaluating VLMs for Strategic Abilities in Multi-Agent Environments
Pith reviewed 2026-05-19 11:53 UTC · model grok-4.3
The pith
Vision-language models show strong perception yet lag significantly in strategic reasoning and decision-making across multi-agent visual environments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
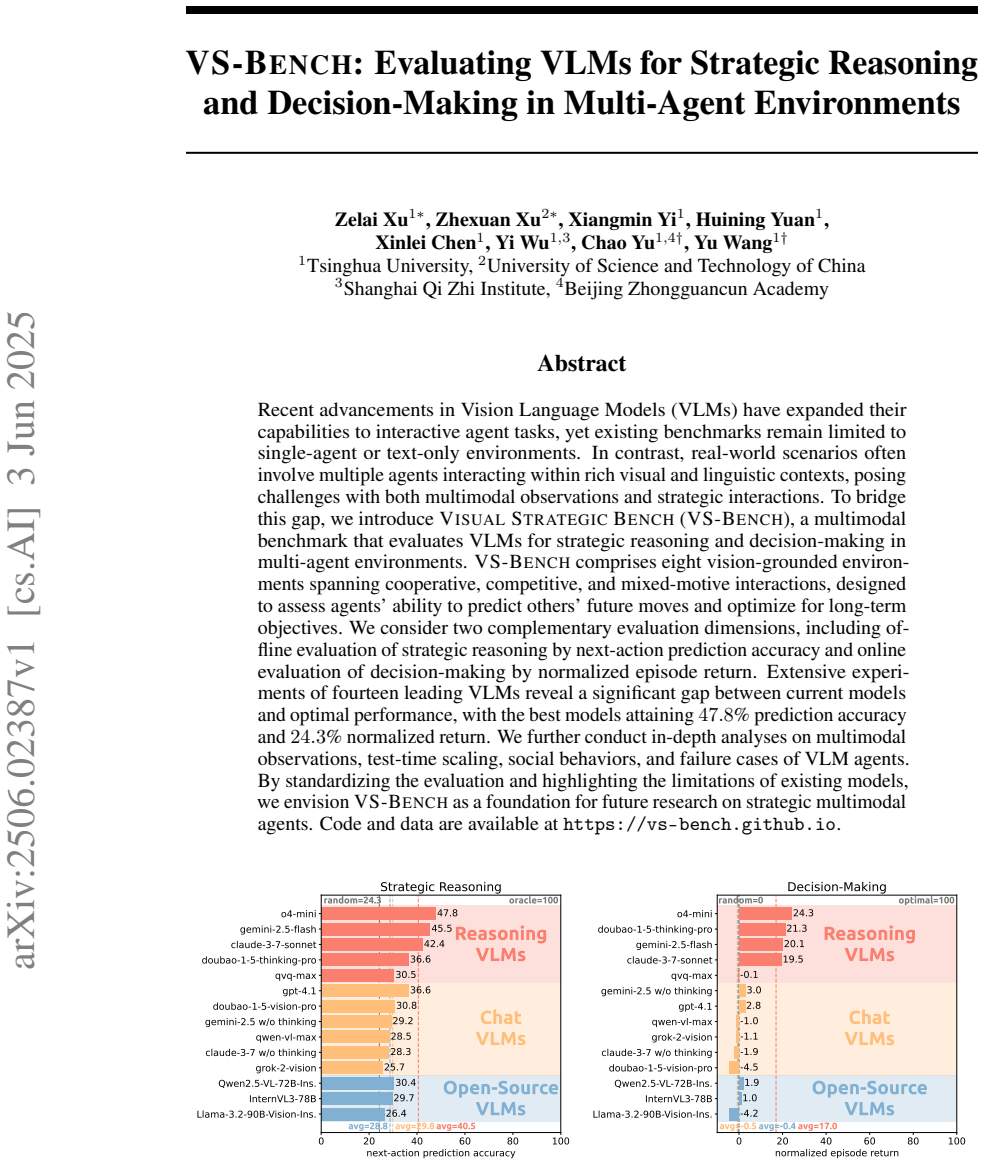
VS-Bench measures VLM performance in multi-agent environments along three axes: perception via element recognition accuracy, strategic reasoning via next-action prediction accuracy, and decision-making via normalized episode return, establishing that current models retain a substantial gap to optimal levels in reasoning and decision-making despite capable perception.
What carries the argument
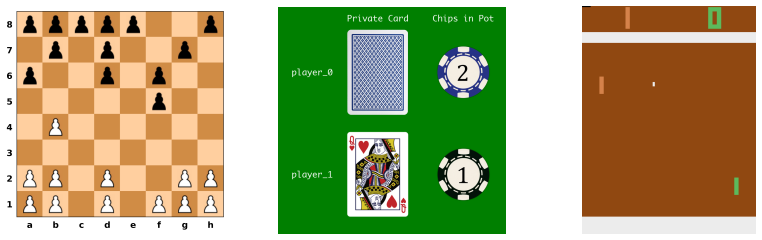
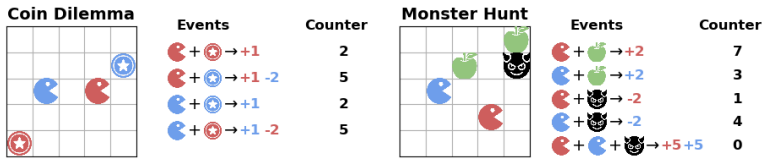
VS-Bench, a benchmark built from ten vision-grounded environments that evaluate cooperative, competitive, and mixed-motive interactions through the metrics of element recognition accuracy, next-action prediction accuracy, and normalized episode return.
If this is right
- Improved strategic performance in these environments would support deploying VLMs as agents in interactive multi-agent applications such as simulations or games.
- Documented failure modes can directly inform targeted enhancements to VLM reasoning components.
- Human performance data collected in the same environments provides concrete targets for model iteration.
- Standardized use of VS-Bench could accelerate systematic progress on multimodal strategic agents.
Where Pith is reading between the lines
- Adding environments with greater scale or partial observability could expose further limits in current VLM strategies.
- Looping VS-Bench evaluations into VLM training might narrow the observed gaps over successive model versions.
- The visual emphasis implies that purely text-based strategic benchmarks may miss key multimodal interaction challenges.
Load-bearing premise
The ten chosen vision-grounded environments and the three chosen metrics of element recognition, next-action prediction, and normalized return serve as valid proxies for strategic abilities in real-world multi-agent settings.
What would settle it
Demonstrating that one or more VLMs reach near-optimal normalized returns and substantially higher next-action prediction accuracy across all ten environments would indicate the reported gap is smaller than claimed.
Figures














read the original abstract
Recent advancements in Vision Language Models (VLMs) have expanded their capabilities to interactive agent tasks, yet existing benchmarks remain limited to single-agent or text-only environments. In contrast, real-world scenarios often involve multiple agents interacting within rich visual and textual contexts, posing challenges with both multimodal observations and strategic interactions. To bridge this gap, we introduce Visual Strategic Bench (VS-Bench), a multimodal benchmark that evaluates VLMs for strategic abilities in multi-agent environments. VS-Bench comprises ten vision-grounded environments that cover cooperative, competitive, and mixed-motive interactions. The performance of VLM agents is evaluated across three dimensions: perception measured by element recognition accuracy; strategic reasoning measured by next-action prediction accuracy; and decision-making measured by normalized episode return. Extensive experiments on fifteen leading VLMs show that, although current models exhibit strong perception abilities, there remains a significant gap to optimal performance in reasoning and decision-making, with the best-performing model attaining 46.6% prediction accuracy and 31.4% normalized return. We further analyze the key factors influencing performance, conduct human experiments, and examine failure modes to provide a deeper understanding of VLMs' strategic abilities. By standardizing the evaluation and highlighting the limitations of existing models, we envision VS-Bench as a foundation for future research on strategic multimodal agents. Code and data are available at https://vs-bench.github.io.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces VS-Bench, a multimodal benchmark consisting of ten vision-grounded multi-agent environments spanning cooperative, competitive, and mixed-motive settings. It evaluates fifteen VLMs using three metrics: element recognition accuracy for perception, next-action prediction accuracy for strategic reasoning, and normalized episode return for decision-making. Results show strong perception but substantial gaps in reasoning and decision-making, with the best model reaching 46.6% prediction accuracy and 31.4% normalized return. The authors additionally analyze influencing factors, compare to human performance, examine failure modes, and release code and data.
Significance. If the environments and metrics validly isolate strategic abilities from perception and task artifacts, the work identifies concrete limitations in current VLMs for multi-agent strategic tasks and offers a standardized testbed for future multimodal agent research. The public release of code and data is a clear strength supporting reproducibility.
major comments (2)
- [Abstract] Abstract and Evaluation section: the central claim of a 'significant gap to optimal performance in reasoning and decision-making' rests on next-action prediction and normalized return cleanly separating strategic abilities from perception. The manuscript provides no evidence that next-action labels derive from full POMDP rollouts rather than expert policies or that agents receive only raw visual observations instead of privileged state summaries, leaving open the possibility that the reported gap reflects interface or labeling artifacts.
- [Results] Results and Experiments: performance figures for the fifteen models are reported without statistical significance tests, error bars, data-split details, or validation that the three metrics capture strategic ability rather than environment-specific artifacts, weakening the cross-model and cross-environment comparisons.
minor comments (1)
- [Abstract] The abstract could briefly indicate the specific VLMs tested or the distribution of environment types to give readers immediate context for the scale of the evaluation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript introducing VS-Bench. We address each major comment below with clarifications and planned revisions to strengthen the presentation of our metrics and results.
read point-by-point responses
-
Referee: [Abstract] Abstract and Evaluation section: the central claim of a 'significant gap to optimal performance in reasoning and decision-making' rests on next-action prediction and normalized return cleanly separating strategic abilities from perception. The manuscript provides no evidence that next-action labels derive from full POMDP rollouts rather than expert policies or that agents receive only raw visual observations instead of privileged state summaries, leaving open the possibility that the reported gap reflects interface or labeling artifacts.
Authors: We agree that explicit documentation of label generation and observation interfaces is necessary to support the separation of perception from strategic abilities. Next-action labels are produced by executing optimal or near-optimal policies: where tractable we solve the underlying POMDP using standard dynamic programming methods to obtain action sequences that maximize expected return; otherwise we adopt the expert policies supplied with each environment's original implementation. All VLM agents are provided exclusively with raw RGB visual frames and the standard textual observations emitted by the environment APIs, with no privileged state vectors or internal summaries. We have added a dedicated paragraph plus a summary table in the revised Evaluation section that lists the exact source of labels and observations for each of the ten environments. revision: yes
-
Referee: [Results] Results and Experiments: performance figures for the fifteen models are reported without statistical significance tests, error bars, data-split details, or validation that the three metrics capture strategic ability rather than environment-specific artifacts, weakening the cross-model and cross-environment comparisons.
Authors: We acknowledge that the original results section would benefit from additional statistical detail. In the revision we now report error bars as one standard deviation across five independent evaluation runs per model-environment pair. We include paired t-tests with p-values for key model comparisons. Data splits are described explicitly: next-action prediction uses an environment-wise 70/30 train/test partition with no temporal overlap. To validate that the metrics reflect strategic ability rather than artifacts, we add baseline comparisons against random agents and the same optimal/expert policies used for labeling; these show that both prediction accuracy and normalized return scale monotonically with policy quality across environments. These additions are incorporated into the Results and Experiments sections. revision: yes
Circularity Check
No circularity: empirical benchmark with direct measurements on external environments and metrics
full rationale
The paper introduces VS-Bench as a new benchmark with ten vision-grounded multi-agent environments and reports empirical performance of fifteen VLMs using three explicitly defined metrics (element recognition accuracy, next-action prediction accuracy, and normalized episode return). The key results (e.g., best model at 46.6% prediction accuracy and 31.4% normalized return) are obtained through direct experimentation and human comparisons against these externally specified environments and metrics. No equations, derivations, fitted parameters, or self-referential definitions appear; the central claims rest on straightforward empirical evaluation rather than any reduction to inputs by construction or load-bearing self-citations. The evaluation is therefore self-contained against the chosen benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The ten vision-grounded environments adequately represent cooperative, competitive, and mixed-motive strategic interactions.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
VS-Bench comprises eight vision-grounded environments... offline evaluation of strategic reasoning by next-action prediction accuracy and online evaluation of decision-making by normalized episode return.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We evaluate fourteen leading VLMs... best-performing model attaining 47.8% prediction accuracy and 24.3% normalized return.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Saaket Agashe, Yue Fan, Anthony Reyna, and Xin Eric Wang. Llm-coordination: evaluating and analyzing multi-agent coordination abilities in large language models. arXiv preprint arXiv:2310.03903, 2023
- [2]
-
[3]
Vqa: Visual question answering
Stanislaw Antol, Aishwarya Agrawal, Jiasen Lu, Margaret Mitchell, Dhruv Batra, C Lawrence Zitnick, and Devi Parikh. Vqa: Visual question answering. In Proceedings of the IEEE international conference on computer vision, pages 2425–2433, 2015
work page 2015
-
[4]
Atari. Pong. Arcade Video Game, 1972
work page 1972
-
[5]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwenvll: A versatile vision-language model for understanding, localization, text reading, and beyond. arXiv preprint arXiv:2308.12966, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2.5-vl technical report. arXiv preprint arXiv:2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
The hanabi challenge: A new frontier for ai research
Nolan Bard, Jakob N Foerster, Sarath Chandar, Neil Burch, Marc Lanctot, H Francis Song, Emilio Parisotto, Vincent Dumoulin, Subhodeep Moitra, Edward Hughes, et al. The hanabi challenge: A new frontier for ai research. Artificial Intelligence, 280:103216, 2020
work page 2020
-
[8]
The arcade learning environment: An evaluation platform for general agents
Marc G Bellemare, Yavar Naddaf, Joel Veness, and Michael Bowling. The arcade learning environment: An evaluation platform for general agents. Journal of artificial intelligence research, 47:253–279, 2013
work page 2013
-
[9]
Dota 2 with Large Scale Deep Reinforcement Learning
Christopher Berner, Greg Brockman, Brooke Chan, Vicki Cheung, Przemysław D˛ ebiak, Christy Dennison, David Farhi, Quirin Fischer, Shariq Hashme, Chris Hesse, et al. Dota 2 with large scale deep reinforcement learning. arXiv preprint arXiv:1912.06680, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1912
-
[10]
Windows agent arena: Evaluating multi-modal os agents at scale.arXiv preprint arXiv:2409.08264,
Rogerio Bonatti, Dan Zhao, Francesco Bonacci, Dillon Dupont, Sara Abdali, Yinheng Li, Yadong Lu, Justin Wagle, Kazuhito Koishida, Arthur Bucker, et al. Windows agent arena: Evaluating multi-modal os agents at scale. arXiv preprint arXiv:2409.08264, 2024
-
[11]
Superhuman ai for multiplayer poker
Noam Brown and Tuomas Sandholm. Superhuman ai for multiplayer poker. Science, 365(6456):885–890, 2019
work page 2019
-
[12]
On the utility of learning about humans for human-ai coordination
Micah Carroll, Rohin Shah, Mark K Ho, Tom Griffiths, Sanjit Seshia, Pieter Abbeel, and Anca Dragan. On the utility of learning about humans for human-ai coordination. Advances in neural information processing systems, 32, 2019
work page 2019
-
[13]
MLE-bench: Evaluating Machine Learning Agents on Machine Learning Engineering
Jun Shern Chan, Neil Chowdhury, Oliver Jaffe, James Aung, Dane Sherburn, Evan Mays, Giulio Starace, Kevin Liu, Leon Maksin, Tejal Patwardhan, et al. Mle-bench: Evaluating machine learning agents on machine learning engineering. arXiv preprint arXiv:2410.07095, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Llmarena: Assessing capabilities of large language models in dynamic multi-agent environments
Junzhe Chen, Xuming Hu, Shuodi Liu, Shiyu Huang, Wei-Wei Tu, Zhaofeng He, and Lijie Wen. Llmarena: Assessing capabilities of large language models in dynamic multi-agent environments. arXiv preprint arXiv:2402.16499, 2024
-
[15]
Microsoft COCO Captions: Data Collection and Evaluation Server
Xinlei Chen, Hao Fang, Tsung-Yi Lin, Ramakrishna Vedantam, Saurabh Gupta, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco captions: Data collection and evaluation server. arXiv preprint arXiv:1504.00325, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[16]
Efficient selectivity and backup operators in monte-carlo tree search
Rémi Coulom. Efficient selectivity and backup operators in monte-carlo tree search. In International conference on computers and games, pages 72–83. Springer, 2006
work page 2006
-
[17]
Gemini 2.5: Our most intelligent ai model, 2025
Google DeepMined. Gemini 2.5: Our most intelligent ai model, 2025
work page 2025
-
[18]
Gtbench: Uncovering the strategic reasoning limitations of llms via game-theoretic evaluations
Jinhao Duan, Renming Zhang, James Diffenderfer, Bhavya Kailkhura, Lichao Sun, Elias Stengel-Eskin, Mohit Bansal, Tianlong Chen, and Kaidi Xu. Gtbench: Uncovering the strategic reasoning limitations of llms via game-theoretic evaluations. arXiv preprint arXiv:2402.12348, 2024. 11
-
[19]
Ward Edwards. The theory of decision making. Psychological bulletin, 51(4):380, 1954
work page 1954
-
[20]
Multi-agent systems: an introduction to distributed artificial intelligence, volume 1
Jacques Ferber and Gerhard Weiss. Multi-agent systems: an introduction to distributed artificial intelligence, volume 1. Addison-wesley Reading, 1999
work page 1999
-
[21]
Learning with Opponent-Learning Awareness
Jakob N Foerster, Richard Y Chen, Maruan Al-Shedivat, Shimon Whiteson, Pieter Abbeel, and Igor Mordatch. Learning with opponent-learning awareness. arXiv preprint arXiv:1709.04326, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
- [22]
- [23]
-
[24]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Benchmarking vision, language, & action models on robotic learning tasks
Pranav Guruprasad, Harshvardhan Sikka, Jaewoo Song, Yangyue Wang, and Paul Pu Liang. Benchmarking vision, language, & action models on robotic learning tasks. arXiv preprint arXiv:2411.05821, 2024
-
[26]
WebVoyager: Building an End-to-End Web Agent with Large Multimodal Models
Hongliang He, Wenlin Yao, Kaixin Ma, Wenhao Yu, Yong Dai, Hongming Zhang, Zhenzhong Lan, and Dong Yu. Webvoyager: Building an end-to-end web agent with large multimodal models. arXiv preprint arXiv:2401.13919, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Hengyuan Hu, Adam Lerer, Alex Peysakhovich, and Jakob Foerster. “other-play” for zero-shot coordination. In International Conference on Machine Learning, pages 4399–4410. PMLR, 2020
work page 2020
-
[28]
Language instructed reinforcement learning for human-ai coordination
Hengyuan Hu and Dorsa Sadigh. Language instructed reinforcement learning for human-ai coordination. In International Conference on Machine Learning, pages 13584–13598. PMLR, 2023
work page 2023
-
[29]
Jen-tse Huang, Eric John Li, Man Ho Lam, Tian Liang, Wenxuan Wang, Youliang Yuan, Wenxiang Jiao, Xing Wang, Zhaopeng Tu, and Michael R Lyu. How far are we on the decision- making of llms? evaluating llms’ gaming ability in multi-agent environments.arXiv preprint arXiv:2403.11807, 2024
-
[30]
VisualWebArena: Evaluating Multimodal Agents on Realistic Visual Web Tasks
Jing Yu Koh, Robert Lo, Lawrence Jang, Vikram Duvvur, Ming Chong Lim, Po-Yu Huang, Graham Neubig, Shuyan Zhou, Ruslan Salakhutdinov, and Daniel Fried. Visualwebarena: Evaluating multimodal agents on realistic visual web tasks. arXiv preprint arXiv:2401.13649, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
arXiv preprint arXiv:2302.02083 , volume=
Michal Kosinski. Theory of mind may have spontaneously emerged in large language models. arXiv preprint arXiv:2302.02083, 4:169, 2023
-
[32]
Harold W Kuhn. A simplified two-person poker. Contributions to the Theory of Games , 1(97-103):2, 1950
work page 1950
-
[33]
Openspiel: A framework for reinforcement learning in games.arXiv preprint arXiv:1908.09453, 2019
Marc Lanctot, Edward Lockhart, Jean-Baptiste Lespiau, Vinicius Zambaldi, Satyaki Upadhyay, Julien Pérolat, Sriram Srinivasan, Finbarr Timbers, Karl Tuyls, Shayegan Omidshafiei, et al. Openspiel: A framework for reinforcement learning in games. arXiv preprint arXiv:1908.09453, 2019
-
[34]
Scalable evaluation of multi-agent reinforcement learning with melting pot
Joel Z Leibo, Edgar A Dueñez-Guzman, Alexander Vezhnevets, John P Agapiou, Peter Sunehag, Raphael Koster, Jayd Matyas, Charlie Beattie, Igor Mordatch, and Thore Graepel. Scalable evaluation of multi-agent reinforcement learning with melting pot. In International conference on machine learning, pages 6187–6199. PMLR, 2021
work page 2021
-
[35]
Maintaining cooperation in complex social dilemmas using deep reinforcement learning
Adam Lerer and Alexander Peysakhovich. Maintaining cooperation in complex social dilemmas using deep reinforcement learning. arXiv preprint arXiv:1707.01068, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[36]
Kaixin Li, Yuchen Tian, Qisheng Hu, Ziyang Luo, Zhiyong Huang, and Jing Ma. Mmcode: Benchmarking multimodal large language models for code generation with visually rich pro- gramming problems. arXiv preprint arXiv:2404.09486, 2024. 12
-
[37]
On the effects of data scale on ui control agents
Wei Li, William E Bishop, Alice Li, Christopher Rawles, Folawiyo Campbell-Ajala, Divya Tyamagundlu, and Oriana Riva. On the effects of data scale on ui control agents. Advances in Neural Information Processing Systems, 37:92130–92154, 2024
work page 2024
-
[38]
Markov games as a framework for multi-agent reinforcement learning
Michael L Littman. Markov games as a framework for multi-agent reinforcement learning. In Machine learning proceedings 1994, pages 157–163. Elsevier, 1994
work page 1994
-
[39]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
work page 2023
-
[40]
Visualagent bench: Towards large multimodal models as visual foundation agents
Xiao Liu, Tianjie Zhang, Yu Gu, Iat Long Iong, Yifan Xu, Xixuan Song, Shudan Zhang, Hanyu Lai, Xinyi Liu, Hanlin Zhao, et al. Visualagentbench: Towards large multimodal models as visual foundation agents. arXiv preprint arXiv:2408.06327, 2024
-
[41]
Richard Lorentz and Therese Horey. Programming breakthrough. In International Conference on Computers and Games, pages 49–59. Springer, 2013
work page 2013
-
[42]
Multi-agent actor-critic for mixed cooperative-competitive environments
Ryan Lowe, Yi I Wu, Aviv Tamar, Jean Harb, OpenAI Pieter Abbeel, and Igor Mordatch. Multi-agent actor-critic for mixed cooperative-competitive environments. Advances in neural information processing systems, 30, 2017
work page 2017
-
[43]
Christopher Lu, Timon Willi, Christian A Schroeder De Witt, and Jakob Foerster. Model-free opponent shaping. In International Conference on Machine Learning, pages 14398–14411. PMLR, 2022
work page 2022
-
[44]
Games and decisions: Introduction and critical survey
R Duncan Luce and Howard Raiffa. Games and decisions: Introduction and critical survey. Wiley, 1957
work page 1957
-
[45]
Llama 3.2: Revolutionizing edge ai and vision with open, customizable models, 2024
meta. Llama 3.2: Revolutionizing edge ai and vision with open, customizable models, 2024
work page 2024
-
[46]
Playing Atari with Deep Reinforcement Learning
V olodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wierstra, and Martin Riedmiller. Playing atari with deep reinforcement learning. arXiv preprint arXiv:1312.5602, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[47]
Human-level control through deep reinforcement learning
V olodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A Rusu, Joel Veness, Marc G Bellemare, Alex Graves, Martin Riedmiller, Andreas K Fidjeland, Georg Ostrovski, et al. Human-level control through deep reinforcement learning. nature, 518(7540):529–533, 2015
work page 2015
-
[48]
Deepstack: Expert-level artificial intelligence in heads-up no-limit poker
Matej Moravˇcík, Martin Schmid, Neil Burch, Viliam Lis`y, Dustin Morrill, Nolan Bard, Trevor Davis, Kevin Waugh, Michael Johanson, and Michael Bowling. Deepstack: Expert-level artificial intelligence in heads-up no-limit poker. Science, 356(6337):508–513, 2017
work page 2017
-
[49]
A generalized training approach for multiagent learning
Paul Muller, Shayegan Omidshafiei, Mark Rowland, Karl Tuyls, Julien Perolat, Siqi Liu, Daniel Hennes, Luke Marris, Marc Lanctot, Edward Hughes, et al. A generalized training approach for multiagent learning. arXiv preprint arXiv:1909.12823, 2019
- [50]
-
[51]
Openai o3 and o4-mini system card, 2025
OpenAI. Openai o3 and o4-mini system card, 2025
work page 2025
-
[52]
Training language models to follow instructions with human feedback
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. Advances in neural information processing systems, 35:27730–27744, 2022
work page 2022
-
[53]
Prosocial learning agents solve generalized Stag Hunts better than selfish ones
Alexander Peysakhovich and Adam Lerer. Prosocial learning agents solve generalized stag hunts better than selfish ones. arXiv preprint arXiv:1709.02865, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[54]
Bdi agents: from theory to practice
Anand S Rao, Michael P Georgeff, et al. Bdi agents: from theory to practice. In Icmas, volume 95, pages 312–319, 1995
work page 1995
-
[55]
Prisoner’s dilemma: A study in conflict and cooperation, volume 165
Anatol Rapoport and Albert M Chammah. Prisoner’s dilemma: A study in conflict and cooperation, volume 165. University of Michigan press, 1965. 13
work page 1965
-
[56]
AndroidWorld: A Dynamic Benchmarking Environment for Autonomous Agents
Christopher Rawles, Sarah Clinckemaillie, Yifan Chang, Jonathan Waltz, Gabrielle Lau, Mary- beth Fair, Alice Li, William Bishop, Wei Li, Folawiyo Campbell-Ajala, et al. Androidworld: A dynamic benchmarking environment for autonomous agents. arXiv preprint arXiv:2405.14573, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[57]
Jean-Jacques Rousseau. A discourse on inequality. Penguin, 1985
work page 1985
-
[58]
Jaxmarl: Multi-agent rl environments and algorithms in jax
Alexander Rutherford, Benjamin Ellis, Matteo Gallici, Jonathan Cook, Andrei Lupu, Garðar Ingvarsson Juto, Timon Willi, Ravi Hammond, Akbir Khan, Christian Schroeder de Witt, et al. Jaxmarl: Multi-agent rl environments and algorithms in jax. Advances in Neural Information Processing Systems, 37:50925–50951, 2024
work page 2024
-
[59]
Solving breakthrough with race patterns and job-level proof number search
Abdallah Saffidine, Nicolas Jouandeau, and Tristan Cazenave. Solving breakthrough with race patterns and job-level proof number search. InAdvances in Computer Games: 13th International Conference, ACG 2011, Tilburg, The Netherlands, November 20-22, 2011, Revised Selected Papers 13, pages 196–207. Springer, 2012
work page 2011
-
[60]
The starcraft multi-agent challenge
Mikayel Samvelyan, Tabish Rashid, Christian Schroeder De Witt, Gregory Farquhar, Nan- tas Nardelli, Tim GJ Rudner, Chia-Man Hung, Philip HS Torr, Jakob Foerster, and Shimon Whiteson. The starcraft multi-agent challenge. arXiv preprint arXiv:1902.04043, 2019
- [61]
-
[62]
Claude E Shannon. Xxii. programming a computer for playing chess. The London, Edinburgh, and Dublin Philosophical Magazine and Journal of Science, 41(314):256–275, 1950
work page 1950
-
[63]
Lloyd S Shapley. Stochastic games. Proceedings of the national academy of sciences , 39(10):1095–1100, 1953
work page 1953
-
[64]
Mas- tering the game of go with deep neural networks and tree search
David Silver, Aja Huang, Chris J Maddison, Arthur Guez, Laurent Sifre, George Van Den Driess- che, Julian Schrittwieser, Ioannis Antonoglou, Veda Panneershelvam, Marc Lanctot, et al. Mas- tering the game of go with deep neural networks and tree search. nature, 529(7587):484–489, 2016
work page 2016
-
[65]
Bayes' Bluff: Opponent Modelling in Poker
Finnegan Southey, Michael P Bowling, Bryce Larson, Carmelo Piccione, Neil Burch, Darse Billings, and Chris Rayner. Bayes’ bluff: Opponent modelling in poker. arXiv preprint arXiv:1207.1411, 2012
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[66]
Collaborat- ing with humans without human data
DJ Strouse, Kevin McKee, Matt Botvinick, Edward Hughes, and Richard Everett. Collaborat- ing with humans without human data. Advances in Neural Information Processing Systems, 34:14502–14515, 2021
work page 2021
-
[67]
Discovering diverse multi-agent strategic behavior via reward randomization
Zhenggang Tang, Chao Yu, Boyuan Chen, Huazhe Xu, Xiaolong Wang, Fei Fang, Simon Du, Yu Wang, and Yi Wu. Discovering diverse multi-agent strategic behavior via reward randomization. arXiv preprint arXiv:2103.04564, 2021
-
[68]
Gemini Robotics: Bringing AI into the Physical World
Gemini Robotics Team, Saminda Abeyruwan, Joshua Ainslie, Jean-Baptiste Alayrac, Montser- rat Gonzalez Arenas, Travis Armstrong, Ashwin Balakrishna, Robert Baruch, Maria Bauza, Michiel Blokzijl, et al. Gemini robotics: Bringing ai into the physical world. arXiv preprint arXiv:2503.20020, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [69]
-
[70]
Td-gammon, a self-teaching backgammon program, achieves master-level play
Gerald Tesauro. Td-gammon, a self-teaching backgammon program, achieves master-level play. Neural computation, 6(2):215–219, 1994
work page 1994
-
[71]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timo- thée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[72]
Dan Troyka. Breakthrough. About Board Games 8x8 Game Design Competition Winner, 2000
work page 2000
-
[73]
Grandmaster level in starcraft ii using multi-agent reinforcement learning
Oriol Vinyals, Igor Babuschkin, Wojciech M Czarnecki, Michaël Mathieu, Andrew Dudzik, Jun- young Chung, David H Choi, Richard Powell, Timo Ewalds, Petko Georgiev, et al. Grandmaster level in starcraft ii using multi-agent reinforcement learning. nature, 575(7782):350–354, 2019. 14
work page 2019
-
[74]
Theory of games and economic behavior: 60th anniversary commemorative edition
John V on Neumann and Oskar Morgenstern. Theory of games and economic behavior: 60th anniversary commemorative edition. In Theory of games and economic behavior. Princeton university press, 2007
work page 2007
-
[75]
Are large vision language models good game players? arXiv preprint arXiv:2503.02358, 2025
Xinyu Wang, Bohan Zhuang, and Qi Wu. Are large vision language models good game players? arXiv preprint arXiv:2503.02358, 2025
-
[76]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022
work page 2022
-
[77]
An introduction to multiagent systems
Michael Wooldridge. An introduction to multiagent systems. John wiley & sons, 2009
work page 2009
- [78]
-
[79]
Chengxing Xie, Canyu Chen, Feiran Jia, Ziyu Ye, Shiyang Lai, Kai Shu, Jindong Gu, Adel Bibi, Ziniu Hu, David Jurgens, et al. Can large language model agents simulate human trust behavior? In The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
work page 2024
-
[80]
Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh J Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, et al. Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments. Advances in Neural Information Processing Systems, 37:52040–52094, 2024
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.