HeartcareGPT: A Unified Multimodal ECG Suite for Dual Signal-Image Modeling and Understanding
Pith reviewed 2026-05-19 10:40 UTC · model grok-4.3
The pith
A unified model processes ECG signals and images together to deliver consistent gains on heart data tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
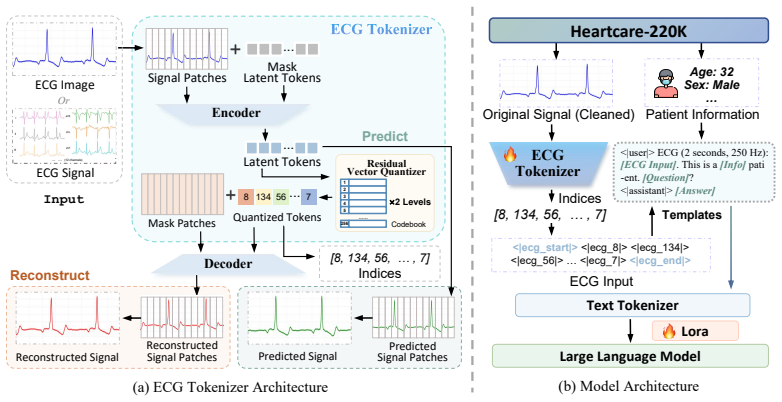
HeartcareGPT, built upon a structure-aware discrete tokenizer and the Dual Stream Projection Alignment paradigm, enables joint optimizing and modeling of native ECG signals and images within a shared feature space, achieving consistent improvements across diverse ECG understanding tasks and validating both the unified modeling paradigm and the necessity of a high-quality data pipeline.
What carries the argument
Dual Stream Projection Alignment (DSPA) paradigm, a dual encoder projection alignment mechanism that projects native ECG signal and image features into one shared space for joint modeling.
If this is right
- The model records consistent performance lifts on a range of ECG understanding and cross-modal generalization tasks.
- The results confirm that a unified signal-image modeling paradigm is effective for this domain.
- The experiments demonstrate the importance of a carefully constructed high-quality data pipeline for training success.
- The work supplies a methodological base for extending multimodal models into other physiological signal areas.
Where Pith is reading between the lines
- The same dual-alignment structure could be tested on related biosignals such as EEG or blood-pressure waveforms.
- The released benchmark may become a reference point for comparing future multimodal ECG systems.
- Clinical software could incorporate the joint signal-image route to reduce the number of separate analysis modules needed for routine ECG review.
Load-bearing premise
That merging high-quality clinical ECG reports from top hospitals with open-source data through a dedicated pipeline yields a fine-grained, unbiased instruction dataset suitable for effective model training and cross-modal alignment.
What would settle it
If the model shows no measurable improvement over single-modality baselines when evaluated on the Heartcare-Bench across multiple ECG understanding tasks, the benefit of the unified dual-stream approach would be refuted.
Figures





read the original abstract
Although electrocardiograms (ECG) play a dominant role in cardiovascular diagnosis and treatment, their intrinsic data forms and representational patterns pose significant challenges for medical multimodal large language models (Med-MLLMs) in achieving cross-modal semantic alignment. To address this gap, we propose Heartcare Suite, a unified ECG suite designed for dual signal-image modeling and understanding: (i) Heartcare-400K. A fine-grained ECG instruction dataset on top of our data pipeline engine--HeartAgent--by integrating high quality clinical ECG reports from top hospitals with open-source data. (ii) Heartcare-Bench. A systematic benchmark assessing performance of models in multi-perspective ECG understanding and cross-modal generalization, providing guidance for optimizing ECG comprehension models. (iii) HeartcareGPT. Built upon a structure-aware discrete tokenizer Beat, we propose Dual Stream Projection Alignment (DSPA) paradigm--a dual encoder projection alignment mechanism enabling joint optimizing and modeling native ECG signal-image within a shared feature space. HeartcareGPT achieves consistent improvements across diverse ECG understanding tasks, validating both the effectiveness of the unified modeling paradigm and the necessity of a high-quality data pipeline, and establishing a methodological foundation for extending Med-MLLMs towards physiological signal domains. Our project is available at https://github.com/ZJU4HealthCare/HeartcareGPT .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Heartcare Suite for unified multimodal ECG modeling and understanding. It consists of (i) Heartcare-400K, a fine-grained instruction dataset constructed via the HeartAgent pipeline by combining high-quality clinical ECG reports from top hospitals with open-source data; (ii) Heartcare-Bench, a systematic benchmark for multi-perspective ECG understanding and cross-modal generalization; and (iii) HeartcareGPT, which uses a structure-aware discrete tokenizer (Beat) together with the Dual Stream Projection Alignment (DSPA) paradigm—a dual-encoder projection mechanism—to jointly model native ECG signals and images in a shared feature space. The central claim is that this unified approach yields consistent improvements across diverse ECG understanding tasks, validating both the DSPA paradigm and the necessity of the high-quality data pipeline.
Significance. If the reported gains can be shown to arise specifically from the DSPA alignment and the HeartAgent-curated dataset (rather than from increased data volume or the tokenizer alone), the work would supply a concrete methodological foundation for extending Med-MLLMs into physiological-signal domains and for addressing cross-modal semantic alignment challenges that are characteristic of ECG data.
major comments (2)
- [Abstract] Abstract: the claim that HeartcareGPT 'achieves consistent improvements across diverse ECG understanding tasks' is presented without any quantitative metrics, baseline comparisons, error analysis, or experimental details. This leaves the central empirical claim without visible supporting evidence even in the summary of the work.
- [Experiments] Experiments / Results section: the strongest claim—that observed gains on Heartcare-Bench are attributable to the DSPA paradigm and the HeartAgent 400K pipeline—requires ablations that hold model size, training compute, and total token count fixed while varying only the alignment mechanism or the data source (clinical reports vs. open-source only). No such controls are described, so alternative explanations (larger effective data volume or the discrete tokenizer alone) cannot be ruled out.
minor comments (1)
- [Abstract] Abstract: the acronym DSPA is introduced without an immediate parenthetical expansion on first use, which reduces immediate readability for readers unfamiliar with the paradigm.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comments point by point below and have revised the manuscript to improve clarity and experimental rigor.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that HeartcareGPT 'achieves consistent improvements across diverse ECG understanding tasks' is presented without any quantitative metrics, baseline comparisons, error analysis, or experimental details. This leaves the central empirical claim without visible supporting evidence even in the summary of the work.
Authors: We agree that the abstract would be strengthened by including key quantitative results. In the revised manuscript we have updated the abstract to report specific metrics, including average performance gains on Heartcare-Bench relative to strong baselines, while preserving brevity. The full experimental details, baselines, and error analysis remain in the Experiments section. revision: yes
-
Referee: [Experiments] Experiments / Results section: the strongest claim—that observed gains on Heartcare-Bench are attributable to the DSPA paradigm and the HeartAgent 400K pipeline—requires ablations that hold model size, training compute, and total token count fixed while varying only the alignment mechanism or the data source (clinical reports vs. open-source only). No such controls are described, so alternative explanations (larger effective data volume or the discrete tokenizer alone) cannot be ruled out.
Authors: We acknowledge the value of tightly controlled ablations. Our original experiments compared variants with and without DSPA and with different data compositions, but did not explicitly fix total token count across all runs. We have added new ablation tables in the revised Experiments section that hold model size, training compute budget, and token count constant while isolating the alignment mechanism and the HeartAgent curation step. These results support that the observed gains arise from DSPA and data quality rather than volume or the tokenizer alone. revision: yes
Circularity Check
No significant circularity; claims rest on new data and proposed mechanisms
full rationale
The paper introduces original elements including the Heartcare-400K dataset constructed via the new HeartAgent pipeline, the Heartcare-Bench benchmark, and the HeartcareGPT model with its Beat tokenizer and Dual Stream Projection Alignment (DSPA) paradigm. Validation of effectiveness is presented through empirical improvements on ECG understanding tasks rather than any mathematical derivation or prediction that reduces by construction to prior fitted parameters, self-definitions, or load-bearing self-citations. The central claims depend on newly collected clinical data and a proposed alignment mechanism, remaining independent of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Clinical ECG reports from top hospitals integrated via HeartAgent form a high-quality fine-grained instruction dataset.
Reference graph
Works this paper leans on
-
[1]
OpenAI. Gpt-4v(ision) system card. https://cdn.openai.com/papers/GPTV_System_ Card.pdf, 2023
work page 2023
-
[2]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
work page 2023
-
[3]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report. arXiv preprint arXiv:2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Zhe Chen, Weiyun Wang, Yue Cao, Yangzhou Liu, Zhangwei Gao, Erfei Cui, Jinguo Zhu, Shen- glong Ye, Hao Tian, Zhaoyang Liu, et al. Expanding performance boundaries of open-source multimodal models with model, data, and test-time scaling. arXiv preprint arXiv:2412.05271, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
mPLUG-Owl3: Towards Long Image-Sequence Understanding in Multi-Modal Large Language Models
Jiabo Ye, Haiyang Xu, Haowei Liu, Anwen Hu, Ming Yan, Qi Qian, Ji Zhang, Fei Huang, and Jingren Zhou. mplug-owl3: Towards long image-sequence understanding in multi-modal large language models. arXiv preprint arXiv:2408.04840, 2024
work page internal anchor Pith review arXiv 2024
-
[6]
Yi: Open Foundation Models by 01.AI
Alex Young, Bei Chen, Chao Li, Chengen Huang, Ge Zhang, Guanwei Zhang, Guoyin Wang, Heng Li, Jiangcheng Zhu, Jianqun Chen, et al. Yi: Open foundation models by 01. ai. arXiv preprint arXiv:2403.04652, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ramé, Morgane Rivière, et al. Gemma 3 technical report. arXiv preprint arXiv:2503.19786, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Anthropic. Claude 3.5. https://www.anthropic.com, 2024. Large Language Model by Anthropic
work page 2024
-
[9]
Llava-med: Training a large language-and-vision assistant for biomedicine in one day
Chunyuan Li, Cliff Wong, Sheng Zhang, Naoto Usuyama, Haotian Liu, Jianwei Yang, Tristan Naumann, Hoifung Poon, and Jianfeng Gao. Llava-med: Training a large language-and-vision assistant for biomedicine in one day. Advances in Neural Information Processing Systems, 36: 28541–28564, 2023
work page 2023
-
[10]
Huatuogpt-vision, towards injecting medical visual knowledge into multimodal llms at scale
Junying Chen, Chi Gui, Ruyi Ouyang, Anningzhe Gao, Shunian Chen, Guiming Hardy Chen, Xidong Wang, Ruifei Zhang, Zhenyang Cai, Ke Ji, et al. Huatuogpt-vision, towards injecting medical visual knowledge into multimodal llms at scale. arXiv preprint arXiv:2406.19280, 2024
-
[11]
arXiv preprint arXiv:2502.19634 (2025)
Jiazhen Pan, Che Liu, Junde Wu, Fenglin Liu, Jiayuan Zhu, Hongwei Bran Li, Chen Chen, Cheng Ouyang, and Daniel Rueckert. Medvlm-r1: Incentivizing medical reasoning capability of vision-language models (vlms) via reinforcement learning. arXiv preprint arXiv:2502.19634, 2025
-
[12]
Tianwei Lin, Wenqiao Zhang, Sijing Li, Yuqian Yuan, Binhe Yu, Haoyuan Li, Wanggui He, Hao Jiang, Mengze Li, Xiaohui Song, et al. Healthgpt: A medical large vision-language model for unifying comprehension and generation via heterogeneous knowledge adaptation. arXiv preprint arXiv:2502.09838, 2025
-
[13]
Jiarui Jin, Haoyu Wang, Hongyan Li, Jun Li, Jiahui Pan, and Shenda Hong. Reading your heart: Learning ecg words and sentences via pre-training ecg language model. arXiv preprint arXiv:2502.10707, 2025. 10
-
[14]
Ptb-xl, a large publicly available electrocardiography dataset
Patrick Wagner, Nils Strodthoff, Ralf-Dieter Bousseljot, Dieter Kreiseler, Fatima I Lunze, Wojciech Samek, and Tobias Schaeffter. Ptb-xl, a large publicly available electrocardiography dataset. Scientific data, 7(1):1–15, 2020
work page 2020
-
[15]
Image based deep learning in 12-lead ecg diagnosis
Raymond Ao and George He. Image based deep learning in 12-lead ecg diagnosis. Frontiers in Artificial Intelligence, 5:1087370, 2023
work page 2023
-
[16]
Multimodal chatgpt-4v for electrocardiogram interpretation: Promise and limitations
Lingxuan Zhu, Weiming Mou, Keren Wu, Yancheng Lai, Anqi Lin, Tao Yang, Jian Zhang, and Peng Luo. Multimodal chatgpt-4v for electrocardiogram interpretation: Promise and limitations. Journal of Medical Internet Research, 26:e54607, 2024
work page 2024
-
[17]
Ptb-image: A scanned paper ecg dataset for digitization and image-based diagnosis,
Cuong V Nguyen, Hieu X Nguyen, Dung D Pham Minh, and Cuong D Do. Comparing deep neu- ral network for multi-label ecg diagnosis from scanned ecg. arXiv preprint arXiv:2502.14909, 2025
-
[18]
Learning Transferable Visual Models From Natural Language Supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agar- wal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision, 2021. URL https://arxiv.org/abs/2103.00020
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[19]
Sigmoid Loss for Language Image Pre-Training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training, 2023. URL https://arxiv.org/abs/2303.15343
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
Taming transformers for high-resolution image synthesis
Patrick Esser, Robin Rombach, and Bjorn Ommer. Taming transformers for high-resolution image synthesis. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12873–12883, 2021
work page 2021
-
[21]
Ecg-sl: Electrocardiogram (ecg) segment learning, a deep learning method for ecg signal
Han Yu, Huiyuan Yang, and Akane Sano. Ecg-sl: Electrocardiogram (ecg) segment learning, a deep learning method for ecg signal. arXiv preprint arXiv:2310.00818, 2023
-
[22]
Large language model-informed ecg dual attention network for heart failure risk prediction
Chen Chen, Lei Li, Marcel Beetz, Abhirup Banerjee, Ramneek Gupta, and Vicente Grau. Large language model-informed ecg dual attention network for heart failure risk prediction. IEEE Transactions on Big Data, 2025
work page 2025
-
[23]
Han Yu, Peikun Guo, and Akane Sano. Ecg semantic integrator (esi): A foundation ecg model pretrained with llm-enhanced cardiological text. arXiv preprint arXiv:2405.19366, 2024
-
[24]
Ecg-lm: Understanding electrocardiogram with a large language model
Kai Yang, Massimo Hong, Jiahuan Zhang, Yizhen Luo, Suyuan Zhao, Ou Zhang, Xiaomao Yu, Jiawen Zhou, Liuqing Yang, Ping Zhang, et al. Ecg-lm: Understanding electrocardiogram with a large language model. Health Data Science, 5:0221, 2025
work page 2025
-
[25]
Mingsheng Cai, Jiuming Jiang, Wenhao Huang, Che Liu, and Rossella Arcucci. Supreme: A supervised pre-training framework for multimodal ecg representation learning. arXiv preprint arXiv:2502.19668, 2025
-
[26]
Consen- sus graph representation learning for better grounded image captioning
Wenqiao Zhang, Haochen Shi, Siliang Tang, Jun Xiao, Qiang Yu, and Yueting Zhuang. Consen- sus graph representation learning for better grounded image captioning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 35, pages 3394–3402, 2021
work page 2021
-
[27]
Hyperllava: Dynamic visual and language expert tuning for multimodal large language models
Wenqiao Zhang, Tianwei Lin, Jiang Liu, Fangxun Shu, Haoyuan Li, Lei Zhang, He Wanggui, Hao Zhou, Zheqi Lv, Hao Jiang, et al. Hyperllava: Dynamic visual and language expert tuning for multimodal large language models. arXiv preprint arXiv:2403.13447, 2024
-
[28]
Med-flamingo: a multimodal medical few-shot learner
Michael Moor, Qian Huang, Shirley Wu, Michihiro Yasunaga, Yash Dalmia, Jure Leskovec, Cyril Zakka, Eduardo Pontes Reis, and Pranav Rajpurkar. Med-flamingo: a multimodal medical few-shot learner. In Machine Learning for Health (ML4H), pages 353–367. PMLR, 2023
work page 2023
-
[29]
Wenqiao Zhang, Lei Zhu, James Hallinan, Shengyu Zhang, Andrew Makmur, Qingpeng Cai, and Beng Chin Ooi. Boostmis: Boosting medical image semi-supervised learning with adaptive pseudo labeling and informative active annotation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20666–20676, 2022. 11
work page 2022
-
[30]
Juan Manuel Zambrano Chaves, Shih-Cheng Huang, Yanbo Xu, Hanwen Xu, Naoto Usuyama, Sheng Zhang, Fei Wang, Yujia Xie, Mahmoud Khademi, Ziyi Yang, et al. Towards a clinically accessible radiology foundation model: open-access and lightweight, with automated evaluation. arXiv preprint arXiv:2403.08002, 2024
-
[31]
Sijing Li, Tianwei Lin, Lingshuai Lin, Wenqiao Zhang, Jiang Liu, Xiaoda Yang, Juncheng Li, Yucheng He, Xiaohui Song, Jun Xiao, et al. Eyecaregpt: Boosting comprehensive ophthalmology understanding with tailored dataset, benchmark and model. arXiv preprint arXiv:2504.13650, 2025
-
[32]
Skingpt-4: an interactive dermatology diagnostic system with visual large language model
Juexiao Zhou, Xiaonan He, Liyuan Sun, Jiannan Xu, Xiuying Chen, Yuetan Chu, Longxi Zhou, Xingyu Liao, Bin Zhang, and Xin Gao. Skingpt-4: an interactive dermatology diagnostic system with visual large language model. arXiv preprint arXiv:2304.10691, 2023
-
[33]
Med-moe: Mixture of domain-specific experts for lightweight medical vision-language models, 2024
Songtao Jiang, Tuo Zheng, Yan Zhang, Yeying Jin, Li Yuan, and Zuozhu Liu. Med-moe: Mixture of domain-specific experts for lightweight medical vision-language models, 2024. URL https://arxiv.org/abs/2404.10237
-
[34]
pdf2svg: A simple tool to convert pdf files to svg files using poppler
David Barton. pdf2svg: A simple tool to convert pdf files to svg files using poppler. https: //github.com/dawbarton/pdf2svg, 2023. Accessed: 2025-05-16
work page 2023
-
[35]
Pymupdf: Python bindings for mupdf – a lightweight pdf and xps viewer
Artifex Software Inc. Pymupdf: Python bindings for mupdf – a lightweight pdf and xps viewer. https://github.com/pymupdf/PyMuPDF, 2024. Accessed: 2025-05-16
work page 2024
-
[36]
Wfdb app toolbox for matlab/octave
Ikaros Silva. Wfdb app toolbox for matlab/octave. https://github.com/ikarosilva/ wfdb-app-toolbox, 2023. Accessed: 2025-05-16
work page 2023
-
[37]
lxml: Xml and html with python
Martijn Faassen, Stefan Behnel, et al. lxml: Xml and html with python. https://github. com/lxml/lxml, 2024. Accessed: 2025-05-16
work page 2024
-
[38]
Neurokit2: Python toolbox for neurophysiological signal processing
Dominique Makowski and contributors. Neurokit2: Python toolbox for neurophysiological signal processing. https://github.com/neuropsychology/NeuroKit, 2024. Accessed: 2025-05-16
work page 2024
-
[39]
Matplotlib: A 2d graphics environment
John D Hunter. Matplotlib: A 2d graphics environment. Computing in Science & Engineering, 9(3):90–95, 2007
work page 2007
-
[40]
MiniCPM: Unveiling the Potential of Small Language Models with Scalable Training Strategies
Shengding Hu, Yuge Tu, Xu Han, Chaoqun He, Ganqu Cui, Xiang Long, Zhi Zheng, Yewei Fang, Yuxiang Huang, Weilin Zhao, et al. Minicpm: Unveiling the potential of small language models with scalable training strategies. arXiv preprint arXiv:2404.06395, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
Text chunking using transformation-based learning
Lance A Ramshaw and Mitchell P Marcus. Text chunking using transformation-based learning. In Natural language processing using very large corpora, pages 157–176. Springer, 1999
work page 1999
-
[42]
Bleu: a method for automatic evaluation of machine translation
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. Bleu: a method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics, pages 311–318, 2002
work page 2002
-
[43]
Rouge: A package for automatic evaluation of summaries
Chin-Yew Lin. Rouge: A package for automatic evaluation of summaries. In Text summa- rization branches out: Proceedings of the ACL-04 workshop , pages 74–81. Association for Computational Linguistics, 2004
work page 2004
-
[44]
Heartcare Suite: Multi-dimensional Understanding ECG with Raw Multi- lead Signal Modeling
Saahil Jain, Ashwin Agrawal, Adriel Saporta, Steven QH Truong, Du Nguyen Duong, Tan Bui, Pierre Chambon, Yuhao Zhang, Matthew P Lungren, Andrew Y Ng, et al. Radgraph: Extracting clinical entities and relations from radiology reports. arXiv preprint arXiv:2106.14463, 2021. 12 Appendix This is the Appendix for “Heartcare Suite: Multi-dimensional Understandi...
-
[45]
Completeness of abnormal features mentioned (higher=more complete): 10,
-
[46]
Completeness of key diagnoses included (higher=more complete): 10,
-
[47]
Absence of critical diagnostic errors (higher=better): 8,
-
[48]
Whether wording is appropriate, avoiding absolute expressions: 5 • Requirements:
-
[49]
Score each item in the criteria above from 0 to 100 based on comparison with the reference report. – A score from 90 to 100 indicates full compliance with the description; – A score from 80 to 89indicates substantial compliance with the description; – A score from 60 to 79indicates partial non-compliance with certain aspects; – A score below 60 indicates ...
-
[50]
Calculate weighted dimension scores: score_i × weight_i
-
[51]
The final total score is the sum of all weighted dimension scores: total_score = sum(score_i × weight_i) / sum(weight_i))
-
[52]
The output must be must be in the form of JSON: { "item_scores": { "1": score_1, "2": score_2, ..., "17": score_17 }, "total_score": total_score } Figure 5: Evaluation prompt. 16 These experiments fully demonstrate the importance and synergistic effects of each component in our design, with every module playing a critical role. This further validates the ...
-
[53]
Please assign the most suitable shape and structure classification with a detailed examination of the provided ECG sequence of this subject. A. Non-diagnostic T abnormalities; B. Ventricular premature complex; C. Low QRS voltage in limb leads; D. Non-specific ST elevation
-
[54]
Investigate the patient’s ECG reading and diagnose its classification based on its features. A. Normal; B. Incomplete left bundle branch block; C. Long QTc-interval; D. Complete right bundle branch block
-
[55]
By conducting a detailed evaluation of the ECG trace of the person, output the correct rate and regularity it should be classified under. A. Bigeminal pattern; B. Sinus tachycardia; C. Sinus rhythm; D. Normal functioning artificial pacemaker
-
[56]
What would you determine the pattern and timing of this ECG reading to be? A. Atrial fibrillation; B. Atrial flutter; C. Normal functioning artificial pacemaker; D. Normal
-
[57]
With precision and attention to detail, work through the subject’s ECG reading and give the most appropriate rhythm based on its characteristics. A. Sinus bradycardia; B. Atrial flutter; C. Paroxysmal supraventricular tachycardia; D. Atrial fibrillation. Open-QA Question:
-
[58]
Given the ECG finding, please work through its features and classify the right shape and structure
-
[59]
Assign the waveform associated with the ECG characteristic
-
[60]
What pattern and timing does ECG interpretation exhibit?
-
[61]
Through meticulous examination of the patient’s ECG sequence, please accurately determine the diagnosis that best defines it
-
[62]
What rhythm does the given ECG characteristic from the patient exhibit? Positive condition:
-
[63]
Based on the ECG pattern, after thorough examination, the form is classified as {condition}
-
[64]
The diagnostic classification observed in the given ECG observation suggests a evident link to suggestive of {condition}
-
[65]
After systematic analysis, the ECG evaluation is classified as {condition}
-
[66]
Clinical findings from this ECG assessment reinforce the presence of {condition} as a evident outcome
- [67]
-
[68]
All leads demonstrate physiological waveforms, and the overall conclusion is a normal ECG
-
[69]
Standard diagnostic criteria confirm that the signal is entirely normal, with no pathological findings
-
[70]
No evidence of ST-segment elevation, depression, or T-wave inversions
-
[71]
Healthy cardiac activity
-
[72]
complete right bundle branch block
Heart rate is regular, with consistent P-P and R-R intervals. Table 7: Sample QA templates for tasks. 18 Category Evaluation Criteria Weight Diagnostic Completeness Completeness of abnormal features mentioned 10 Completeness of key diagnoses included 10 Absence of critical diagnostic errors 10 Whether the report describes severity or likelihood of the fin...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.