Part²GS: Part-aware Modeling of Articulated Objects using 3D Gaussian Splatting
Pith reviewed 2026-05-19 08:11 UTC · model grok-4.3
The pith
Part²GS uses part-aware 3D Gaussians and physics constraints to model articulated objects with high-fidelity geometry and consistent motion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
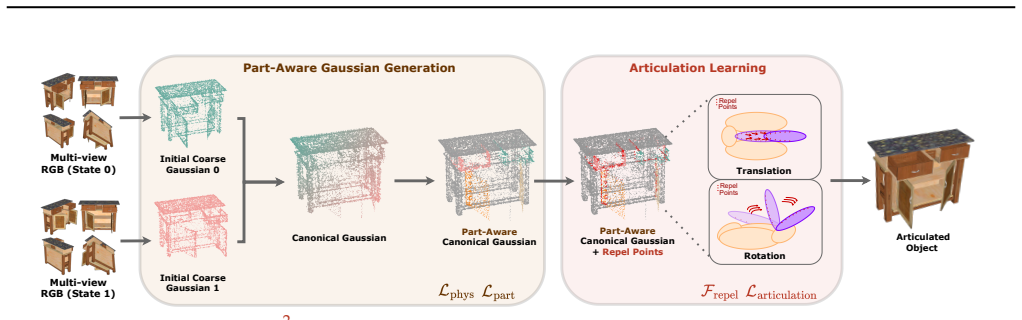
Part²GS leverages a part-aware 3D Gaussian representation that encodes articulated components with learnable attributes, enabling structured, disentangled transformations that preserve high-fidelity geometry. To ensure physically consistent motion, it proposes a motion-aware canonical representation guided by physics-based constraints, including contact enforcement, velocity consistency, and vector-field alignment, together with a field of repel points to prevent part collisions and maintain stable articulation paths.
What carries the argument
A part-aware 3D Gaussian representation that assigns learnable attributes to individual components, paired with physics-based motion constraints and a repel point field.
If this is right
- Movable parts achieve up to ten times lower Chamfer Distance error than prior methods on both synthetic and real data.
- Geometry stays sharp and detailed even while parts articulate.
- Motion stays coherent because contact, velocity, and direction rules are enforced together.
- Collisions between parts are reduced by the repel point field.
- The same model works without change on both computer-generated and camera-captured scenes.
Where Pith is reading between the lines
- If the constraints prove robust, the same physics rules could be transferred to other point-based or mesh-based representations of moving objects.
- The repel point idea might extend naturally to modeling joint limits or friction in more complex machines.
- Successful part disentanglement could simplify downstream tasks such as editing individual components in a reconstructed scene.
Load-bearing premise
The physics-based constraints together with the repel point field are enough on their own to produce physically consistent articulation without extra real-world motion data or separate validation of those constraints.
What would settle it
Running the trained model on previously unseen motion sequences of real articulated objects and checking whether parts penetrate each other, violate velocity rules, or lose contact during the motion.
Figures




read the original abstract
Articulated objects are common in the real world, yet modeling their structure and motion remains a challenging task for 3D reconstruction methods. In this work, we introduce Part$^{2}$GS, a novel framework for modeling articulated digital twins of multi-part objects with high-fidelity geometry and physically consistent articulation. Part$^{2}$GS leverages a part-aware 3D Gaussian representation that encodes articulated components with learnable attributes, enabling structured, disentangled transformations that preserve high-fidelity geometry. To ensure physically consistent motion, we propose a motion-aware canonical representation guided by physics-based constraints, including contact enforcement, velocity consistency, and vector-field alignment. Furthermore, we introduce a field of repel points to prevent part collisions and maintain stable articulation paths, significantly improving motion coherence over baselines. Extensive evaluations on both synthetic and real-world datasets show that Part$^{2}$GS consistently outperforms state-of-the-art methods by up to 10$\times$ in Chamfer Distance for movable parts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Part²GS, a framework for part-aware modeling of articulated objects via 3D Gaussian Splatting. It encodes components with learnable attributes to enable disentangled transformations that preserve geometry, and incorporates physics-based constraints (contact enforcement, velocity consistency, vector-field alignment) plus a repel point field to promote physically consistent articulation without explicit real-world motion supervision. Extensive evaluations on synthetic and real-world datasets are reported to yield up to 10× lower Chamfer Distance on movable parts relative to prior state-of-the-art methods.
Significance. If the central results hold under rigorous validation, the work would advance 3D reconstruction of articulated objects by integrating high-fidelity Gaussian representations with explicit physics guidance for motion coherence. This direction is timely given the adoption of 3D Gaussians in dynamic scene modeling and could support applications in robotics and simulation that require stable part interactions.
major comments (3)
- [Abstract, §4] Abstract and §4 (Experiments): The claim of consistent outperformance 'by up to 10× in Chamfer Distance for movable parts' lacks accompanying error bars, precise dataset statistics, protocol details, or per-baseline breakdowns. Without these, the magnitude and robustness of the reported gains cannot be assessed from the provided evaluation description.
- [§3.2, §4.3] §3.2 (Physics Constraints) and §4.3 (Ablations): No ablation isolating the contribution of contact enforcement, velocity consistency, vector-field alignment, or the repel point field is described. Because Chamfer Distance measures surface geometry rather than physical properties (e.g., inter-part penetration volume or adherence to non-penetration), it remains unclear whether the physics terms drive the claimed articulation consistency or whether gains arise primarily from the part-aware disentanglement.
- [§3.3] §3.3 (Repel Point Field): The repel point field is introduced to prevent collisions, yet the manuscript provides no quantitative validation (e.g., penetration metrics or trajectory stability measures) demonstrating that this component produces physically consistent paths beyond what the canonical representation alone achieves.
minor comments (2)
- [Abstract] The abstract uses 'Part$^{2}$GS' without an immediate expansion or reference to the full name on first use; this should be clarified in the introduction for readability.
- [§3] Notation for learnable attributes per part and the vector field should be defined consistently between the method section and equations to avoid ambiguity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, indicating planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4 (Experiments): The claim of consistent outperformance 'by up to 10× in Chamfer Distance for movable parts' lacks accompanying error bars, precise dataset statistics, protocol details, or per-baseline breakdowns. Without these, the magnitude and robustness of the reported gains cannot be assessed from the provided evaluation description.
Authors: We agree that additional statistical details are needed for full assessment of the results. In the revised manuscript, we will add error bars (standard deviations over multiple runs), precise dataset statistics (object counts, sequence lengths, train/test splits), a clear evaluation protocol description, and per-baseline Chamfer Distance breakdowns for movable parts in both the abstract and Section 4. revision: yes
-
Referee: [§3.2, §4.3] §3.2 (Physics Constraints) and §4.3 (Ablations): No ablation isolating the contribution of contact enforcement, velocity consistency, vector-field alignment, or the repel point field is described. Because Chamfer Distance measures surface geometry rather than physical properties (e.g., inter-part penetration volume or adherence to non-penetration), it remains unclear whether the physics terms drive the claimed articulation consistency or whether gains arise primarily from the part-aware disentanglement.
Authors: We acknowledge that finer-grained ablations would clarify individual contributions. While §4.3 reports ablations on the combined physics constraints, we will add new experiments isolating contact enforcement, velocity consistency, vector-field alignment, and the repel point field. We will also report direct physical metrics such as inter-part penetration volume alongside Chamfer Distance to better demonstrate the physics terms' role in articulation consistency beyond geometric improvements from part disentanglement. revision: yes
-
Referee: [§3.3] §3.3 (Repel Point Field): The repel point field is introduced to prevent collisions, yet the manuscript provides no quantitative validation (e.g., penetration metrics or trajectory stability measures) demonstrating that this component produces physically consistent paths beyond what the canonical representation alone achieves.
Authors: We thank the referee for highlighting this gap. In the revised §4.3, we will include quantitative validation using penetration volume metrics and trajectory stability measures (e.g., variance in inter-part distances and velocities over time). These will be reported for the full model versus an ablation without the repel point field to show its specific contribution to collision-free, stable articulation paths. revision: yes
Circularity Check
No circularity: derivation relies on proposed representations and external physics constraints
full rationale
The paper presents Part²GS as a framework combining a part-aware 3D Gaussian representation with learnable attributes and physics-based constraints (contact enforcement, velocity consistency, vector-field alignment, repel point field) to achieve physically consistent articulation. These elements are introduced as novel contributions guided by established physical principles rather than being derived from or fitted to the target outputs. No equations or steps in the provided abstract reduce predictions or results to inputs by construction, self-definition, or self-citation chains. Evaluations on synthetic and real datasets use independent geometric metrics (Chamfer Distance), and the central claims remain independent of any load-bearing self-referential loops. This is a standard non-circular finding for a methods paper introducing new modeling components.
Axiom & Free-Parameter Ledger
free parameters (1)
- learnable attributes per part
axioms (1)
- domain assumption Physics-based constraints (contact enforcement, velocity consistency, vector-field alignment) produce physically consistent motion
invented entities (1)
-
field of repel points
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
contact loss … max(0, −cos φ_i) … velocity consistency … Var({Δμ_i}) … vector-field alignment … repel points F^k_repel,i = ∑ k_r (r_j − μ_i)/‖…‖^3
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
motion-aware canonical representation guided by physics-based constraints
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Per-gaussian embedding-based deformation for deformable 3d gaussian splatting
Jeongmin Bae, Seoha Kim, Youngsik Yun, Hahyun Lee, Gun Bang, and Youngjung Uh. Per-gaussian embedding-based deformation for deformable 3d gaussian splatting. InEuropean Conference on Computer Vision (ECCV), 2024
work page 2024
-
[2]
Matt Deitke, Eli VanderBilt, Alvaro Herrasti, Luca Weihs, Kiana Ehsani, Jordi Salvador, Winson Han, Eric Kolve, Aniruddha Kembhavi, and Roozbeh Mottaghi. Procthor: Large-scale embodied ai using procedural generation.Advances in Neural Information Processing Systems (NeurIPS), 2022
work page 2022
-
[3]
Objaverse: A universe of annotated 3d objects
MattDeitke, DustinSchwenk, JordiSalvador, LucaWeihs, OscarMichel, EliVanderBilt, LudwigSchmidt, Kiana Ehsani, Aniruddha Kembhavi, and Ali Farhadi. Objaverse: A universe of annotated 3d objects. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2023
work page 2023
-
[4]
Congyue Deng, Jiahui Lei, William B Shen, Kostas Daniilidis, and Leonidas J Guibas. Banana: Banach fixed-point network for pointcloud segmentation with inter-part equivariance.Advances in Neural Information Processing Systems (NeurIPS), 2023
work page 2023
-
[5]
Act the part: Learning interaction strategies for articulated object part discovery
Samir Yitzhak Gadre, Kiana Ehsani, and Shuran Song. Act the part: Learning interaction strategies for articulated object part discovery. InInternational Conference on Computer Vision (ICCV), 2021
work page 2021
-
[6]
Haoran Geng, Helin Xu, Chengyang Zhao, Chao Xu, Li Yi, Siyuan Huang, and He Wang. Gapart- net: Cross-category domain-generalizable object perception and manipulation via generalizable and actionable parts. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2023
work page 2023
-
[7]
JunfuGuo, YuXin, GaoyiLiu, Kai Xu, LigangLiu, andRuizhenHu. Articulatedgs: Self-superviseddigital twin modeling of articulated objects using 3d gaussian splatting.arXiv preprint arXiv:2503.08135, 2025
-
[8]
Carto: Category and joint agnostic reconstruction of articulated objects
Nick Heppert, Muhammad Zubair Irshad, Sergey Zakharov, Katherine Liu, Rares Andrei Ambrus, Jeannette Bohg, Abhinav Valada, and Thomas Kollar. Carto: Category and joint agnostic reconstruction of articulated objects. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2023
work page 2023
-
[9]
Ruizhen Hu, Wenchao Li, Oliver Van Kaick, Ariel Shamir, Hao Zhang, and Hui Huang. Learning to predict part mobility from a single static snapshot.ACM Transactions on Graphics (TOG), 2017
work page 2017
-
[10]
Sc-gs: Sparse- controlled gaussian splatting for editable dynamic scenes
Yi-Hua Huang, Yang-Tian Sun, Ziyi Yang, Xiaoyang Lyu, Yan-Pei Cao, and Xiaojuan Qi. Sc-gs: Sparse- controlled gaussian splatting for editable dynamic scenes. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024
work page 2024
-
[11]
Screwnet: Category-independent articulation model estimation from depth images using screw theory
Ajinkya Jain, Rudolf Lioutikov, Caleb Chuck, and Scott Niekum. Screwnet: Category-independent articulation model estimation from depth images using screw theory. InInternational Conference on Robotics and Automation (ICRA), 2021
work page 2021
-
[12]
Ditto: Building digital twins of articulated objects from interaction
Zhenyu Jiang, Cheng-Chun Hsu, and Yuke Zhu. Ditto: Building digital twins of articulated objects from interaction. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2022. 12
work page 2022
-
[13]
Deformable 3d gaussian splatting for animatable human avatars.Computing Research Repository, 2023
HyunJun Jung, Nikolas Brasch, Jifei Song, Eduardo Pérez-Pellitero, Yiren Zhou, Zhihao Li, Nassir Navab, and Benjamin Busam. Deformable 3d gaussian splatting for animatable human avatars.Computing Research Repository, 2023
work page 2023
-
[14]
Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering.ACM Transactions on Graphics (TOG), 2023
work page 2023
-
[15]
AI2-THOR: An Interactive 3D Environment for Visual AI
Eric Kolve, Roozbeh Mottaghi, Winson Han, Eli VanderBilt, Luca Weihs, Alvaro Herrasti, Matt Deitke, Kiana Ehsani, Daniel Gordon, Yuke Zhu, et al. Ai2-thor: An interactive 3d environment for visual ai. arXiv preprint arXiv:1712.05474, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[16]
Long Le, Jason Xie, William Liang, Hung-Ju Wang, Yue Yang, Yecheng Jason Ma, Kyle Vedder, Arjun Krishna, Dinesh Jayaraman, and Eric Eaton. Articulate-anything: Automatic modeling of articulated objects via a vision-language foundation model. InInternational Conference on Learning Representations (ICLR), 2025
work page 2025
-
[17]
Jiahui Lei, Congyue Deng, William B Shen, Leonidas J Guibas, and Kostas Daniilidis. Nap: Neural 3d articulated object prior.Advances in Neural Information Processing Systems (NeurIPS), 2023
work page 2023
-
[18]
Mobility fitting using 4d ransac
Hao Li, Guowei Wan, Honghua Li, Andrei Sharf, Kai Xu, and Baoquan Chen. Mobility fitting using 4d ransac. InComputer Graphics Forum, 2016
work page 2016
-
[19]
Garf: Learning generalizable 3d reassembly for real-world fractures
Sihang Li, Zeyu Jiang, Grace Chen, Chenyang Xu, Siqi Tan, Xue Wang, Irving Fang, Kristof Zyskowski, Shannon P McPherron, Radu Iovita, et al. Garf: Learning generalizable 3d reassembly for real-world fractures. arXiv preprint arXiv:2504.05400, 2025
-
[20]
Category-level articulated object pose estimation
Xiaolong Li, He Wang, Li Yi, Leonidas J Guibas, A Lynn Abbott, and Shuran Song. Category-level articulated object pose estimation. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2020
work page 2020
-
[21]
Spacetime gaussian feature splatting for real-time dynamic view synthesis
Zhan Li, Zhang Chen, Zhong Li, and Yi Xu. Spacetime gaussian feature splatting for real-time dynamic view synthesis. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024
work page 2024
-
[22]
Yaron Lipman, Marton Havasi, Peter Holderrieth, Neta Shaul, Matt Le, Brian Karrer, Ricky TQ Chen, David Lopez-Paz, Heli Ben-Hamu, and Itai Gat. Flow matching guide and code. arXiv preprint arXiv:2412.06264, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Semi-weakly supervised object kinematic motion prediction
Gengxin Liu, Qian Sun, Haibin Huang, Chongyang Ma, Yulan Guo, Li Yi, Hui Huang, and Ruizhen Hu. Semi-weakly supervised object kinematic motion prediction. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2023
work page 2023
-
[24]
Paris: Part-level reconstruction and motion analysis for articulated objects
Jiayi Liu, Ali Mahdavi-Amiri, and Manolis Savva. Paris: Part-level reconstruction and motion analysis for articulated objects. InInternational Conference on Computer Vision (ICCV), 2023
work page 2023
-
[25]
Cage: controllable articulation generation
Jiayi Liu, Hou In Ivan Tam, Ali Mahdavi-Amiri, and Manolis Savva. Cage: controllable articulation generation. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024
work page 2024
-
[26]
SINGAPO: Single image controlled generation of articulated parts in objects
Jiayi Liu, Denys Iliash, Angel X Chang, Manolis Savva, and Ali Mahdavi Amiri. SINGAPO: Single image controlled generation of articulated parts in objects. InInternational Conference on Learning Representations (ICLR), 2025. 13
work page 2025
-
[27]
AKB-48: A real-world articulated object knowledge base
Liu Liu, Wenqiang Xu, Haoyuan Fu, Sucheng Qian, Qiaojun Yu, Yang Han, and Cewu Lu. AKB-48: A real-world articulated object knowledge base. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2022
work page 2022
-
[28]
Flow straight and fast: Learning to generate and transfer data with rectified flow
Xingchao Liu, Chengyue Gong, and qiang liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InInternational Conference on Learning Representations (ICLR), 2023
work page 2023
-
[29]
Self-supervised category-level articulated object pose estimation with part-level SE(3) equivariance
Xueyi Liu, Ji Zhang, Ruizhen Hu, Haibin Huang, He Wang, and Li Yi. Self-supervised category-level articulated object pose estimation with part-level SE(3) equivariance. InInternational Conference on Learning Representations (ICLR), 2023
work page 2023
-
[30]
Building interactable replicas of complex articulated objects via gaussian splatting
Yu Liu, Baoxiong Jia, Ruijie Lu, Junfeng Ni, Song-Chun Zhu, and Siyuan Huang. Building interactable replicas of complex articulated objects via gaussian splatting. InInternational Conference on Learning Representations (ICLR), 2025
work page 2025
-
[31]
3d geometry-aware deformable gaussian splatting for dynamic view synthesis
Zhicheng Lu, Xiang Guo, Le Hui, Tianrui Chen, Min Yang, Xiao Tang, Feng Zhu, and Yuchao Dai. 3d geometry-aware deformable gaussian splatting for dynamic view synthesis. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024
work page 2024
-
[32]
Dynamic 3d gaussians: Tracking by persistent dynamic view synthesis
Jonathon Luiten, Georgios Kopanas, Bastian Leibe, and Deva Ramanan. Dynamic 3d gaussians: Tracking by persistent dynamic view synthesis. InInternational Conference on 3D Vision, 2024
work page 2024
-
[33]
Yongsen Mao, Yiming Zhang, Hanxiao Jiang, Angel Chang, and Manolis Savva. Multiscan: Scalable rgbd scanning for 3d environments with articulated objects.Advances in Neural Information Processing Systems (NeurIPS), 2022
work page 2022
-
[34]
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis.Communications of the ACM, 2021
work page 2021
-
[35]
Illustrating how mechanical assemblies work.ACM Transactions on Graphics (TOG), 2010
Niloy J Mitra, Yong-Liang Yang, Dong-Ming Yan, Wilmot Li, Maneesh Agrawala, et al. Illustrating how mechanical assemblies work.ACM Transactions on Graphics (TOG), 2010
work page 2010
-
[36]
Where2act: From pixels to actions for articulated 3D objects
Kaichun Mo, Leonidas J Guibas, Mustafa Mukadam, Abhinav Gupta, and Shubham Tulsiani. Where2act: From pixels to actions for articulated 3D objects. InInternational Conference on Computer Vision (ICCV), 2021
work page 2021
-
[37]
Habitat 3.0: A co-habitat for humans, avatars, and robots
Xavier Puig, Eric Undersander, Andrew Szot, Mikael Dallaire Cote, Tsung-Yen Yang, Ruslan Partsey, Ruta Desai, Alexander Clegg, Michal Hlavac, So Yeon Min, Vladimír Vondruš, Theophile Gervet, Vincent- Pierre Berges, John M Turner, Oleksandr Maksymets, Zsolt Kira, Mrinal Kalakrishnan, Jitendra Malik, Devendra Singh Chaplot, Unnat Jain, Dhruv Batra, Akshara ...
work page 2024
-
[38]
Understanding 3d object interaction from a single image
Shengyi Qian and David F Fouhey. Understanding 3d object interaction from a single image. In International Conference on Computer Vision (ICCV), 2023
work page 2023
-
[39]
3dgs-avatar: Animatable avatars via deformable 3d gaussian splatting
Zhiyin Qian, Shaofei Wang, Marko Mihajlovic, Andreas Geiger, and Siyu Tang. 3dgs-avatar: Animatable avatars via deformable 3d gaussian splatting. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024. 14
work page 2024
-
[40]
Mobility-trees for indoor scenes manipulation
Andrei Sharf, Hui Huang, Cheng Liang, Jiapei Zhang, Baoquan Chen, and Minglun Gong. Mobility-trees for indoor scenes manipulation. InComputer Graphics Forum, 2014
work page 2014
-
[41]
Self-supervised learning of part mobility from point cloud sequence
Yahao Shi, Xinyu Cao, and Bin Zhou. Self-supervised learning of part mobility from point cloud sequence. InComputer Graphics Forum, 2021
work page 2021
-
[42]
Reacto: Reconstructing articulated objects from a single video
Chaoyue Song, Jiacheng Wei, Chuan Sheng Foo, Guosheng Lin, and Fayao Liu. Reacto: Reconstructing articulated objects from a single video. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024
work page 2024
-
[43]
Leia: Latent view-invariant embeddings for implicit 3d articulation
Archana Swaminathan, Anubhav Gupta, Kamal Gupta, Shishira R Maiya, Vatsal Agarwal, and Abhinav Shrivastava. Leia: Latent view-invariant embeddings for implicit 3d articulation. InEuropean Conference on Computer Vision (ECCV), 2024
work page 2024
-
[44]
Alexander Vilesov, Pradyumna Chari, and Achuta Kadambi. Cg3d: Compositional generation for text-to-3d via gaussian splatting.arXiv preprint arXiv:2311.17907, 2023
-
[45]
Superpoint gaussian splatting for real-time high-fidelity dynamic scene reconstruction
Diwen Wan, Ruijie Lu, and Gang Zeng. Superpoint gaussian splatting for real-time high-fidelity dynamic scene reconstruction. InInternational Conference on Machine Learning (ICML), 2024
work page 2024
-
[46]
Template-free articulated gaussian splatting for real-time reposable dynamic view synthesis
Diwen Wan, Yuxiang Wang, Ruijie Lu, and Gang Zeng. Template-free articulated gaussian splatting for real-time reposable dynamic view synthesis. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
work page 2024
-
[47]
Neural implicit representation for building digital twins of unknown articulated objects
Yijia Weng, Bowen Wen, Jonathan Tremblay, Valts Blukis, Dieter Fox, Leonidas Guibas, and Stan Birchfield. Neural implicit representation for building digital twins of unknown articulated objects. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024
work page 2024
-
[48]
4d gaussian splatting for real-time dynamic scene rendering
Guanjun Wu, Taoran Yi, Jiemin Fang, Lingxi Xie, Xiaopeng Zhang, Wei Wei, Wenyu Liu, Qi Tian, and Xinggang Wang. 4d gaussian splatting for real-time dynamic scene rendering. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024
work page 2024
-
[49]
Fanbo Xiang, Yuzhe Qin, Kaichun Mo, Yikuan Xia, Hao Zhu, Fangchen Liu, Minghua Liu, Hanxiao Jiang, Yifu Yuan, He Wang, Li Yi, Angel X. Chang, Leonidas J. Guibas, and Hao Su. SAPIEN: A simulated part-based interactive environment. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2020
work page 2020
-
[50]
Joint-aware manipulation of deformable models.ACM Transactions on Graphics (TOG), 2009
Weiwei Xu, Jun Wang, KangKang Yin, Kun Zhou, Michiel Van De Panne, Falai Chen, and Baining Guo. Joint-aware manipulation of deformable models.ACM Transactions on Graphics (TOG), 2009
work page 2009
-
[51]
Wang Yifan, Felice Serena, Shihao Wu, Cengiz Öztireli, and Olga Sorkine-Hornung. Differentiable surface splatting for point-based geometry processing.ACM Transactions on Graphics (TOG), 2019. 15 A. Experimental Details Datasets. We conduct evaluations across three distinct datasets, each designed to capture varying levels of articulation complexity: (i) P...
work page 2019
-
[52]
system. (ii) DTA-Multi[47], a dataset that offers a moderate challenge with 2 synthetic objects from PartNet-Mobility, where each object contains a static component and two independently movable parts. (iii) ArtGS-Multi[30], a recent dataset that targets more intricate structures, featuring 5 synthetic articulated objects fromPartNet-Mobility, each compos...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.