Improving the Reasoning of Multi-Image Grounding in MLLMs via Reinforcement Learning
Pith reviewed 2026-05-19 06:46 UTC · model grok-4.3
The pith
Reinforcement learning post-training with synthesized chain-of-thought data improves multi-image grounding reasoning in MLLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors establish that synthesizing high-quality chain-of-thought data for cold-start initialization, performing LoRA-based supervised fine-tuning, curating RL data via rejection sampling from the merged SFT model, and then applying rule-based reinforcement learning produces more reliable reasoning paths and lifts performance on multi-image grounding tasks.
What carries the argument
Rule-based reinforcement learning that steers the model toward optimal reasoning paths after rejection sampling curates reliable training examples from the SFT model.
Load-bearing premise
The synthesized chain-of-thought data and the rule-based rewards used in rejection sampling and RL actually produce reliable reasoning paths rather than superficial patterns that only work on the chosen benchmarks.
What would settle it
Running the final model on a newly designed multi-image grounding test set whose required reasoning steps differ from those in the synthesized data and observing zero or negative improvement would falsify the claim.
Figures


read the original abstract
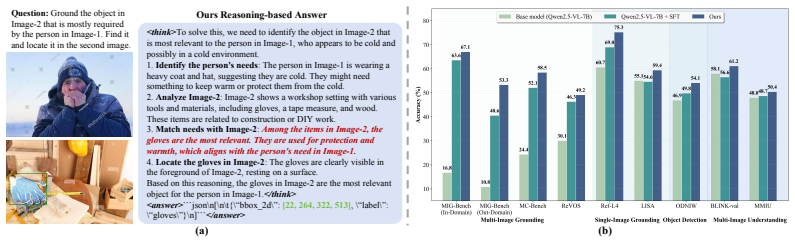
Multimodal Large Language Models (MLLMs) perform well in single-image visual grounding but struggle with real-world tasks that demand cross-image reasoning and multi-modal instructions. To address this, we adopt a reinforcement learning (RL) based post-training strategy for MLLMs in multi-image grounding tasks. We first synthesize high-quality chain-of-thought (CoT) data for cold-start initialization, followed by supervised fine-tuning (SFT) using low-rank adaptation (LoRA). Subsequently, we apply rejection sampling with the merged SFT model to curate reliable RL data and use rule-based RL to guide the model toward optimal reasoning paths. Extensive experiments demonstrate the effectiveness of our approach, achieving +9.04% on MIG-Bench and +4.41% on average across seven out-of-domain benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a reinforcement learning (RL) post-training pipeline for multimodal large language models (MLLMs) on multi-image grounding. The approach first synthesizes chain-of-thought (CoT) data for supervised fine-tuning (SFT) with LoRA, then applies rejection sampling on the SFT model to curate RL training data, and finally uses rule-based RL to optimize reasoning paths. The central empirical claim is that this yields a +9.04% gain on MIG-Bench and a +4.41% average improvement across seven out-of-domain benchmarks.
Significance. If the reported gains arise from improved cross-image logical reasoning rather than output formatting, the work would provide a practical recipe for enhancing MLLM capabilities on tasks requiring multi-image inference. The pipeline combines established techniques (CoT synthesis, rejection sampling, rule-based RL) in a new application domain; the absence of free parameters or invented axioms in the core method is a modest strength, but the result remains an empirical performance claim whose robustness depends on the fidelity of the reward signal.
major comments (3)
- [Method, RL stage] The rule-based reward function (described in the RL stage of the method) must be shown to evaluate logical correctness of multi-image inferences such as spatial relations or object correspondences across images. If the rules primarily penalize format errors or reward CoT markers, the headline gains could reflect improved output style rather than verifiable reasoning, directly undermining the central claim that rejection sampling + rule-based RL produces reliable reasoning paths.
- [Experiments] The experimental results section reports percentage improvements (+9.04% on MIG-Bench, +4.41% OOD average) but provides no details on the precise baseline models and their configurations, statistical significance tests, error bars, number of runs, or explicit controls for data leakage. These omissions make it impossible to assess whether the gains are robust or driven by post-hoc choices, which is load-bearing for the effectiveness claim.
- [Data preparation] The synthesis procedure for the high-quality CoT data (used for cold-start SFT) requires explicit validation that the generated reasoning paths contain genuine cross-image inferences rather than benchmark-specific patterns. Without such validation, the subsequent RL stage may amplify superficial correlations.
minor comments (1)
- Clarify the exact LoRA rank and target modules used in SFT, and provide the full list of the seven out-of-domain benchmarks with their individual scores in a table.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments on our manuscript. We address each major comment point by point below, providing clarifications and indicating where we will revise the manuscript to strengthen the presentation and address the concerns raised.
read point-by-point responses
-
Referee: [Method, RL stage] The rule-based reward function (described in the RL stage of the method) must be shown to evaluate logical correctness of multi-image inferences such as spatial relations or object correspondences across images. If the rules primarily penalize format errors or reward CoT markers, the headline gains could reflect improved output style rather than verifiable reasoning, directly undermining the central claim that rejection sampling + rule-based RL produces reliable reasoning paths.
Authors: We appreciate the referee's emphasis on distinguishing between format improvements and genuine reasoning gains. Our rule-based reward function incorporates explicit checks for logical correctness in multi-image scenarios, including verification of spatial relations between objects across images and accurate object correspondences, in addition to basic format compliance. These rules are applied to both the reasoning steps and the final output to guide the model toward reliable inference paths. We will revise the method section to include a more detailed breakdown of the reward components along with illustrative examples demonstrating their focus on cross-image logical consistency rather than stylistic markers. revision: yes
-
Referee: [Experiments] The experimental results section reports percentage improvements (+9.04% on MIG-Bench, +4.41% OOD average) but provides no details on the precise baseline models and their configurations, statistical significance tests, error bars, number of runs, or explicit controls for data leakage. These omissions make it impossible to assess whether the gains are robust or driven by post-hoc choices, which is load-bearing for the effectiveness claim.
Authors: We acknowledge that the current experimental section would benefit from greater transparency to allow full assessment of robustness. In the revised manuscript, we will specify the exact baseline models and their configurations, report results from statistical significance tests, include error bars derived from multiple independent runs, state the number of runs performed, and describe the controls implemented to prevent data leakage. These additions will provide stronger evidence supporting the effectiveness of the proposed pipeline. revision: yes
-
Referee: [Data preparation] The synthesis procedure for the high-quality CoT data (used for cold-start SFT) requires explicit validation that the generated reasoning paths contain genuine cross-image inferences rather than benchmark-specific patterns. Without such validation, the subsequent RL stage may amplify superficial correlations.
Authors: The CoT synthesis procedure is structured to elicit reasoning that integrates information across multiple images through carefully designed prompts targeting logical connections. To directly address the concern, we will incorporate an explicit validation analysis in the revised paper, such as qualitative examples and categorization of inference types present in the synthesized data, to confirm the presence of genuine cross-image reasoning and reduce the possibility of amplifying superficial patterns. revision: yes
Circularity Check
Empirical RL pipeline with independent benchmark evaluation
full rationale
The paper outlines a standard training sequence—synthesizing CoT data for SFT initialization, applying LoRA-based supervised fine-tuning, performing rejection sampling to curate RL data, and then conducting rule-based RL—followed by direct empirical measurement of accuracy gains on MIG-Bench and seven out-of-domain benchmarks. No mathematical derivation or prediction step is presented that reduces by construction to fitted parameters, self-citations, or internal definitions; the reported improvements (+9.04% and +4.41%) are external performance numbers on held-out test sets and do not collapse into quantities defined inside the method itself. The central claims therefore remain falsifiable against independent benchmarks rather than tautological.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Synthetic chain-of-thought data generated by an existing model is sufficiently high-quality to serve as cold-start supervision.
- domain assumption Rule-based rewards in the RL stage align with actual correctness on multi-image grounding tasks.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We adopt a reinforcement learning (RL) based post-training strategy... synthesize high-quality chain-of-thought (CoT) data... supervised fine-tuning (SFT) using low-rank adaptation (LoRA)... rejection sampling... rule-based RL... accuracy reward... format reward
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Group Relative Policy Optimization (GRPO)... accuracy reward racc... format reward rformat
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
Don't Show Pixels, Show Cues: Unlocking Visual Tool Reasoning in Language Models via Perception Programs
Perception Programs rewrite dense visual tool outputs into language-native summaries, boosting MLLM accuracy by 15-45% absolute on BLINK perception tasks and setting new state-of-the-art results.
-
RCoT-Seg: Reinforced Chain-of-Thought for Video Reasoning and Segmentation
RCoT-Seg uses GRPO-reinforced keyframe selection from a CoT-start corpus followed by SAM2 mask propagation to improve video object segmentation under implicit temporal instructions over prior MLLM sampling methods.
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report. arXiv preprint arXiv:2502.13923, 10 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Revisiting referring expression comprehension evaluation in the era of large multimodal models
Jierun Chen, Fangyun Wei, Jinjing Zhao, Sizhe Song, Bohuai Wu, Zhuoxuan Peng, S-H Gary Chan, and Hongyang Zhang. Revisiting referring expression comprehension evaluation in the era of large multimodal models. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 513–524, 2025
work page 2025
-
[3]
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 24185–24198, 2024
work page 2024
-
[4]
SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training
Tianzhe Chu, Yuexiang Zhai, Jihan Yang, Shengbang Tong, Saining Xie, Dale Schuurmans, Quoc V Le, Sergey Levine, and Yi Ma. Sft memorizes, rl generalizes: A comparative study of foundation model post-training. arXiv preprint arXiv:2501.17161, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Huilin Deng, Ding Zou, Rui Ma, Hongchen Luo, Yang Cao, and Yu Kang. Boosting the generalization and reasoning of vision language models with curriculum reinforcement learning. arXiv preprint arXiv:2503.07065, 2025
-
[6]
OpenVLThinker: Complex Vision-Language Reasoning via Iterative SFT-RL Cycles
Yihe Deng, Hritik Bansal, Fan Yin, Nanyun Peng, Wei Wang, and Kai-Wei Chang. Open- vlthinker: An early exploration to complex vision-language reasoning via iterative self- improvement. arXiv preprint arXiv:2503.17352, 2025
work page internal anchor Pith review arXiv 2025
-
[7]
Ahmed El-Kishky, Alexander Wei, Andre Saraiva, Borys Minaiev, Daniel Selsam, David Dohan, Francis Song, Hunter Lightman, Ignasi Clavera, Jakub Pachocki, et al. Competitive programming with large reasoning models. arXiv preprint arXiv:2502.06807, 2025
-
[8]
Video-R1: Reinforcing Video Reasoning in MLLMs
Kaituo Feng, Kaixiong Gong, Bohao Li, Zonghao Guo, Yibing Wang, Tianshuo Peng, Junfei Wu, Xiaoying Zhang, Benyou Wang, and Xiangyu Yue. Video-r1: Reinforcing video reasoning in mllms. arXiv preprint arXiv:2503.21776, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Blink: Multimodal large language models can see but not perceive
Xingyu Fu, Yushi Hu, Bangzheng Li, Yu Feng, Haoyu Wang, Xudong Lin, Dan Roth, Noah A Smith, Wei-Chiu Ma, and Ranjay Krishna. Blink: Multimodal large language models can see but not perceive. In European Conference on Computer Vision, pages 148–166. Springer, 2024
work page 2024
-
[10]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Vision-R1: Incentivizing Reasoning Capability in Multimodal Large Language Models
Wenxuan Huang, Bohan Jia, Zijie Zhai, Shaosheng Cao, Zheyu Ye, Fei Zhao, Zhe Xu, Yao Hu, and Shaohui Lin. Vision-r1: Incentivizing reasoning capability in multimodal large language models. arXiv preprint arXiv:2503.06749, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, et al. Openai o1 system card. arXiv preprint arXiv:2412.16720, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Mantis: Interleaved multi-image instruction tuning
Dongfu Jiang, Xuan He, Huaye Zeng, Cong Wei, Max Ku, Qian Liu, and Wenhu Chen. Mantis: Interleaved multi-image instruction tuning. arXiv preprint arXiv:2405.01483, 2024
-
[14]
Lumen: Unleashing versatile vision-centric capabilities of large multimodal models
Yang Jiao, Shaoxiang Chen, Zequn Jie, Jingjing Chen, Lin Ma, and Yu-Gang Jiang. Lumen: Unleashing versatile vision-centric capabilities of large multimodal models. arXiv preprint arXiv:2403.07304, 2024
-
[15]
Lisa: Reasoning segmentation via large language model
Xin Lai, Zhuotao Tian, Yukang Chen, Yanwei Li, Yuhui Yuan, Shu Liu, and Jiaya Jia. Lisa: Reasoning segmentation via large language model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9579–9589, 2024
work page 2024
-
[16]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, et al. Llava-onevision: Easy visual task transfer. arXiv preprint arXiv:2408.03326, 2024. 11
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
LLaVA-NeXT-Interleave: Tackling Multi-image, Video, and 3D in Large Multimodal Models
Feng Li, Renrui Zhang, Hao Zhang, Yuanhan Zhang, Bo Li, Wei Li, Zejun Ma, and Chunyuan Li. Llava-next-interleave: Tackling multi-image, video, and 3d in large multimodal models. arXiv preprint arXiv:2407.07895, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Grounded language-image pre-training
Liunian Harold Li, Pengchuan Zhang, Haotian Zhang, Jianwei Yang, Chunyuan Li, Yiwu Zhong, Lijuan Wang, Lu Yuan, Lei Zhang, Jenq-Neng Hwang, et al. Grounded language-image pre-training. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10965–10975, 2022
work page 2022
-
[19]
Migician: Revealing the magic of free-form multi-image grounding in multimodal large language models
You Li, Heyu Huang, Chi Chen, Kaiyu Huang, Chao Huang, Zonghao Guo, Zhiyuan Liu, Jinan Xu, Yuhua Li, Ruixuan Li, et al. Migician: Revealing the magic of free-form multi-image grounding in multimodal large language models. arXiv preprint arXiv:2501.05767, 2025
-
[20]
Groundinggpt: Language enhanced multi-modal grounding model
Zhaowei Li, Qi Xu, Dong Zhang, Hang Song, Yiqing Cai, Qi Qi, Ran Zhou, Junting Pan, Zefeng Li, Van Tu Vu, et al. Groundinggpt: Language enhanced multi-modal grounding model. arXiv preprint arXiv:2401.06071, 2024
-
[21]
Improved visual-spatial reasoning via r1-zero-like training
Zhenyi Liao, Qingsong Xie, Yanhao Zhang, Zijian Kong, Haonan Lu, Zhenyu Yang, and Zhijie Deng. Improved visual-spatial reasoning via r1-zero-like training. arXiv preprint arXiv:2504.00883, 2025
-
[22]
Visual instruction tuning.Advances in neural information processing systems , 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems , 36:34892–34916, 2023
work page 2023
-
[23]
Seg-Zero: Reasoning-Chain Guided Segmentation via Cognitive Reinforcement
Yuqi Liu, Bohao Peng, Zhisheng Zhong, Zihao Yue, Fanbin Lu, Bei Yu, and Jiaya Jia. Seg- zero: Reasoning-chain guided segmentation via cognitive reinforcement. arXiv preprint arXiv:2503.06520, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Visual-RFT: Visual Reinforcement Fine-Tuning
Ziyu Liu, Zeyi Sun, Yuhang Zang, Xiaoyi Dong, Yuhang Cao, Haodong Duan, Dahua Lin, and Jiaqi Wang. Visual-rft: Visual reinforcement fine-tuning. arXiv preprint arXiv:2503.01785, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Generation and comprehension of unambiguous object descriptions
Junhua Mao, Jonathan Huang, Alexander Toshev, Oana Camburu, Alan L Yuille, and Kevin Murphy. Generation and comprehension of unambiguous object descriptions. In Proceedings of the IEEE conference on computer vision and pattern recognition , pages 11–20, 2016
work page 2016
-
[26]
Mmiu: Multimodal multi-image understanding for evaluating large vision-language models
Fanqing Meng, Jin Wang, Chuanhao Li, Quanfeng Lu, Hao Tian, Jiaqi Liao, Xizhou Zhu, Jifeng Dai, Yu Qiao, Ping Luo, et al. Mmiu: Multimodal multi-image understanding for evaluating large vision-language models. arXiv preprint arXiv:2408.02718, 2024
-
[27]
OpenAI. Gpt-4o. https://openai.com/index/hello-gpt-4o/, 2024
work page 2024
-
[28]
Training language models to follow instructions with human feedback
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. Advances in neural information processing systems , 35:27730–27744, 2022
work page 2022
-
[29]
arXiv preprint arXiv:2504.05599
Yi Peng, Xiaokun Wang, Yichen Wei, Jiangbo Pei, Weijie Qiu, Ai Jian, Yunzhuo Hao, Jiachun Pan, Tianyidan Xie, Li Ge, et al. Skywork r1v: Pioneering multimodal reasoning with chain-of- thought. arXiv preprint arXiv:2504.05599, 2025
-
[30]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. Advances in Neural Information Processing Systems , 36:53728–53741, 2023
work page 2023
-
[31]
Glamm: Pixel grounding large multimodal model
Hanoona Rasheed, Muhammad Maaz, Sahal Shaji, Abdelrahman Shaker, Salman Khan, Hisham Cholakkal, Rao M Anwer, Eric Xing, Ming-Hsuan Yang, and Fahad S Khan. Glamm: Pixel grounding large multimodal model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13009–13018, 2024
work page 2024
-
[32]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Y Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300, 2024. 12
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
VLM-R1: A Stable and Generalizable R1-style Large Vision-Language Model
Haozhan Shen, Peng Liu, Jingcheng Li, Chunxin Fang, Yibo Ma, Jiajia Liao, Qiaoli Shen, Zilun Zhang, Kangjia Zhao, Qianqian Zhang, et al. Vlm-r1: A stable and generalizable r1-style large vision-language model. arXiv preprint arXiv:2504.07615, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Reason- 14 rft: Reinforcement fine-tuning for visual reasoning.arXiv preprint arXiv:2503.20752, 2025
Huajie Tan, Yuheng Ji, Xiaoshuai Hao, Minglan Lin, Pengwei Wang, Zhongyuan Wang, and Shanghang Zhang. Reason-rft: Reinforcement fine-tuning for visual reasoning. arXiv preprint arXiv:2503.20752, 2025
-
[35]
Kimi Team, Angang Du, Bofei Gao, Bowei Xing, Changjiu Jiang, Cheng Chen, Cheng Li, Chenjun Xiao, Chenzhuang Du, Chonghua Liao, et al. Kimi k1. 5: Scaling reinforcement learning with llms. arXiv preprint arXiv:2501.12599, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
V3det: Vast vocabulary visual detection dataset
Jiaqi Wang, Pan Zhang, Tao Chu, Yuhang Cao, Yujie Zhou, Tong Wu, Bin Wang, Conghui He, and Dahua Lin. V3det: Vast vocabulary visual detection dataset. In Proceedings of the IEEE/CVF International Conference on Computer Vision , pages 19844–19854, 2023
work page 2023
-
[37]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution. arXiv preprint arXiv:2409.12191, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
Advancing fine-grained visual understanding with multi-scale alignment in multi-modal models
Wei Wang, Zhaowei Li, Qi Xu, Linfeng Li, YiQing Cai, Botian Jiang, Hang Song, Xingcan Hu, Pengyu Wang, and Li Xiao. Advancing fine-grained visual understanding with multi-scale alignment in multi-modal models. arXiv preprint arXiv:2411.09691, 2024
-
[39]
Time-R1: Post-Training Large Vision Language Model for Temporal Video Grounding
Ye Wang, Ziheng Wang, Boshen Xu, Yang Du, Kejun Lin, Zihan Xiao, Zihao Yue, Jianzhong Ju, Liang Zhang, Dingyi Yang, et al. Time-r1: Post-training large vision language model for temporal video grounding. arXiv preprint arXiv:2503.13377, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
LLaVA-CoT: Let Vision Language Models Reason Step-by-Step
Guowei Xu, Peng Jin, Li Hao, Yibing Song, Lichao Sun, and Li Yuan. Llava-o1: Let vision language models reason step-by-step. arXiv preprint arXiv:2411.10440, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
Mc-bench: A benchmark for multi-context visual grounding in the era of mllms
Yunqiu Xu, Linchao Zhu, and Yi Yang. Mc-bench: A benchmark for multi-context visual grounding in the era of mllms. arXiv preprint arXiv:2410.12332, 2024
-
[42]
Visa: Reasoning video object segmentation via large language models
Cilin Yan, Haochen Wang, Shilin Yan, Xiaolong Jiang, Yao Hu, Guoliang Kang, Weidi Xie, and Efstratios Gavves. Visa: Reasoning video object segmentation via large language models. In European Conference on Computer Vision, pages 98–115. Springer, 2024
work page 2024
-
[43]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report. arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
R1-Onevision: Advancing Generalized Multimodal Reasoning through Cross-Modal Formalization
Yi Yang, Xiaoxuan He, Hongkun Pan, Xiyan Jiang, Yan Deng, Xingtao Yang, Haoyu Lu, Dacheng Yin, Fengyun Rao, Minfeng Zhu, et al. R1-onevision: Advancing generalized multimodal reasoning through cross-modal formalization. arXiv preprint arXiv:2503.10615, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
MiniCPM-V: A GPT-4V Level MLLM on Your Phone
Yuan Yao, Tianyu Yu, Ao Zhang, Chongyi Wang, Junbo Cui, Hongji Zhu, Tianchi Cai, Haoyu Li, Weilin Zhao, Zhihui He, et al. Minicpm-v: A gpt-4v level mllm on your phone. arXiv preprint arXiv:2408.01800, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[46]
mplug-owl3: Towards long image-sequence understanding in multi-modal large language models
Jiabo Ye, Haiyang Xu, Haowei Liu, Anwen Hu, Ming Yan, Qi Qian, Ji Zhang, Fei Huang, and Jingren Zhou. mplug-owl3: Towards long image-sequence understanding in multi-modal large language models. arXiv preprint arXiv:2408.04840, 2024
-
[47]
Perception-r1: Pioneering perception policy with reinforcement learning
En Yu, Kangheng Lin, Liang Zhao, Jisheng Yin, Yana Wei, Yuang Peng, Haoran Wei, Jian- jian Sun, Chunrui Han, Zheng Ge, et al. Perception-r1: Pioneering perception policy with reinforcement learning. arXiv preprint arXiv:2504.07954, 2025
-
[48]
Modeling context in referring expressions
Licheng Yu, Patrick Poirson, Shan Yang, Alexander C Berg, and Tamara L Berg. Modeling context in referring expressions. In Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part II 14 , pages 69–85. Springer, 2016. 13
work page 2016
-
[49]
Yufei Zhan, Yousong Zhu, Hongyin Zhao, Fan Yang, Ming Tang, and Jinqiao Wang. Griffon v2: Advancing multimodal perception with high-resolution scaling and visual-language co-referring. arXiv preprint arXiv:2403.09333, 2024
-
[50]
Yufei Zhan, Yousong Zhu, Shurong Zheng, Hongyin Zhao, Fan Yang, Ming Tang, and Jinqiao Wang. Vision-r1: Evolving human-free alignment in large vision-language models via vision- guided reinforcement learning. arXiv preprint arXiv:2503.18013, 2025
-
[51]
Jingyi Zhang, Jiaxing Huang, Huanjin Yao, Shunyu Liu, Xikun Zhang, Shijian Lu, and Dacheng Tao. R1-vl: Learning to reason with multimodal large language models via step-wise group relative policy optimization. arXiv preprint arXiv:2503.12937, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
TinyLLaVA- Video-R1: Towards Smaller LMMs for Video Reason- ing,
Xingjian Zhang, Siwei Wen, Wenjun Wu, and Lei Huang. Tinyllava-video-r1: Towards smaller lmms for video reasoning. arXiv preprint arXiv:2504.09641, 2025
-
[53]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models. arXiv preprint arXiv:2504.10479, 2025. 14
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.