League of LLMs: A Benchmark-Free Paradigm for Mutual Evaluation of Large Language Models
Pith reviewed 2026-05-19 03:13 UTC · model grok-4.3
The pith
Large language models can evaluate each other in repeated rounds to produce stable capability rankings without fixed benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
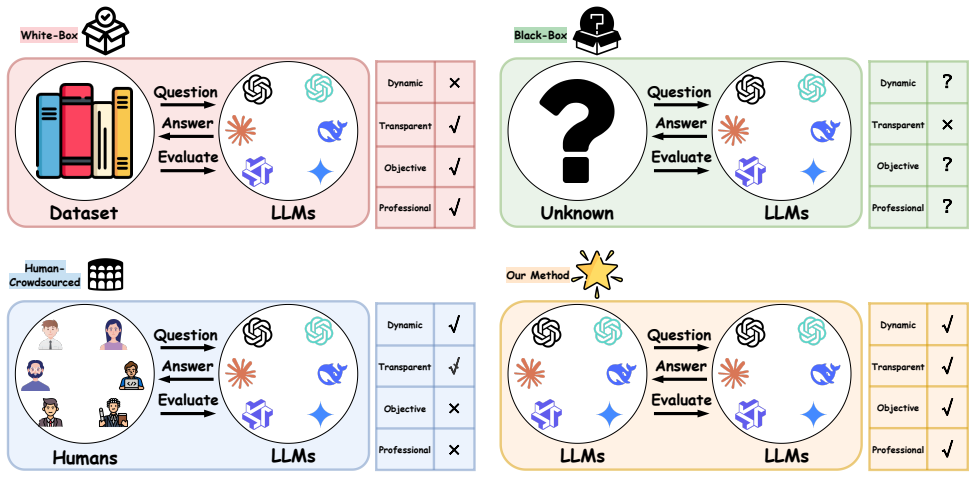
League of LLMs organizes LLMs into a self-governed league for multi-round mutual evaluation, integrating four core criteria to mitigate limitations of existing paradigms, and experiments on eight models demonstrate it distinguishes LLM capabilities while maintaining high internal ranking stability of 70.7 percent top-k consistency, along with empirical findings on memorization behaviors and in-family score differences.
What carries the argument
The self-governed league structure that enables LLMs to conduct repeated, multi-model mutual evaluations under the combined dynamic, transparent, objective, and professional criteria.
Load-bearing premise
Large language models can evaluate one another in an objective and professional manner without their own biases or contamination affecting the outcomes.
What would settle it
Repeated league runs on the same models producing top-k consistency well below 70 percent, or league rankings diverging sharply from rankings obtained on large sets of uncontaminated benchmark questions.
Figures




read the original abstract
Although large language models (LLMs) have shown exceptional capabilities across a wide range of tasks, reliable evaluation remains a critical challenge due to data contamination, opaque operation, and subjective preferences. To address these issues, we propose League of LLMs (LOL), a novel benchmark-free evaluation paradigm that organizes multiple LLMs into a self-governed league for multi-round mutual evaluation. LOL integrates four core criteria (dynamic, transparent, objective, and professional) to mitigate key limitations of existing paradigms. Experiments on eight mainstream LLMs in mathematics and programming demonstrate that LOL can effectively distinguish LLM capabilities while maintaining high internal ranking stability (Top-$k$ consistency $= 70.7\%$). Beyond ranking, LOL reveals empirical findings that are difficult for traditional paradigms to capture. For instance, ``memorization-based answering'' behaviors are observed in some models, and higher in-family scores are found in the OpenAI model family ($\Delta = 9$, $p < 0.05$). Finally, we make our framework and code publicly available as a valuable complement to the current LLM evaluation ecosystem.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes League of LLMs (LOL), a benchmark-free paradigm in which multiple LLMs are organized into a self-governed league that performs multi-round mutual evaluations. The approach integrates four core criteria (dynamic, transparent, objective, and professional) to address limitations of existing evaluation methods such as data contamination and opacity. Experiments involving eight mainstream LLMs on mathematics and programming tasks report that LOL distinguishes model capabilities while achieving 70.7% top-k ranking consistency; additional observations include memorization-based answering patterns and statistically significant in-family score inflation for OpenAI models (Δ = 9, p < 0.05). The framework and code are released publicly.
Significance. If the mutual-evaluation rankings can be shown to track genuine capability differences rather than model similarity or self-reinforcing bias, LOL would constitute a useful complement to benchmark-based evaluation by mitigating contamination risks. The public code release supports reproducibility and further experimentation. At present, however, the absence of external anchors limits the strength of the significance claim.
major comments (2)
- [Abstract] Abstract: the central claim that LOL 'can effectively distinguish LLM capabilities' rests on internal metrics (Top-k consistency = 70.7% and family score differences) computed from the same mutual evaluations; no correlation with human judgments, standard benchmarks, or other external validators is reported, leaving open the possibility that observed distinctions primarily reflect model similarity or shared training artifacts rather than objective capability.
- [Abstract] Abstract / experimental description: the four core criteria are asserted to produce objective and professional evaluations, yet the abstract provides no information on prompt templates, scoring rubrics, aggregation rules, or explicit controls for self-bias and contamination; without these details the objectivity claim cannot be assessed and the reported stability metric remains difficult to interpret.
minor comments (1)
- The abstract would be clearer if it briefly stated the number of evaluation rounds, the exact tasks used, and the total number of pairwise comparisons performed.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify the presentation of our benchmark-free evaluation paradigm. We respond to each major comment below and note planned revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that LOL 'can effectively distinguish LLM capabilities' rests on internal metrics (Top-k consistency = 70.7% and family score differences) computed from the same mutual evaluations; no correlation with human judgments, standard benchmarks, or other external validators is reported, leaving open the possibility that observed distinctions primarily reflect model similarity or shared training artifacts rather than objective capability.
Authors: We agree that external validators such as human judgments or standard benchmark correlations would strengthen claims of distinguishing genuine capabilities rather than similarity artifacts. The current work emphasizes a benchmark-free approach precisely to sidestep contamination and opacity issues in existing evaluations; the reported 70.7% top-k consistency across independent rounds and the statistically significant in-family inflation (Δ=9, p<0.05) provide internal evidence of stable distinctions and bias detection. We will revise the manuscript to explicitly discuss this limitation in a dedicated paragraph and outline future directions for external anchoring, such as targeted human comparisons on a subset of tasks. revision: partial
-
Referee: [Abstract] Abstract / experimental description: the four core criteria are asserted to produce objective and professional evaluations, yet the abstract provides no information on prompt templates, scoring rubrics, aggregation rules, or explicit controls for self-bias and contamination; without these details the objectivity claim cannot be assessed and the reported stability metric remains difficult to interpret.
Authors: The abstract is length-constrained, while the full manuscript details the prompt templates, scoring rubrics, multi-round aggregation rules, and controls for self-bias (including randomized evaluator pairing and anonymization) in the methods section. We will revise the abstract to include a concise reference to these mechanisms and the explicit controls for self-bias and contamination, enabling readers to better assess the objectivity claim and interpret the stability metric from the abstract alone. revision: yes
Circularity Check
No significant circularity in LOL mutual evaluation derivation
full rationale
The paper proposes a benchmark-free mutual evaluation framework (LOL) integrating four criteria and reports empirical results from experiments on eight LLMs, including internal Top-k consistency of 70.7% and in-family score differences. These metrics are computed directly from the generated evaluation data as descriptive properties of the process rather than predictions or first-principles derivations that reduce to fitted inputs by construction. No self-citations, uniqueness theorems, or ansatzes are invoked in a load-bearing way that collapses the central claims. The approach is self-contained by design as a complement to benchmarks, with observations like memorization behaviors standing as independent empirical findings from the mutual evaluations.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multi-round mutual evaluations by LLMs can satisfy dynamic, transparent, objective, and professional criteria simultaneously.
invented entities (1)
-
League of LLMs (LOL)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose League of LLMs (LOL), a novel benchmark-free evaluation paradigm that organizes multiple LLMs into a self-governed league for multi-round mutual evaluation. LOL integrates four core criteria (dynamic, transparent, objective, and professional)
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Top-k consistency = 70.7%
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
DeGenTWeb: A First Look at LLM-dominant Websites
DeGenTWeb shows LLM-dominant websites are common and increasing in Common Crawl and Bing search results, but accurate detection is getting harder with newer models.
Reference graph
Works this paper leans on
-
[1]
Achiam, J.; Adler, S.; Agarwal, S.; Ahmad, L.; Akkaya, I.; Aleman, F. L.; Almeida, D.; Altenschmidt, J.; Altman, S.; Anadkat, S.; et al. 2023. Gpt-4 technical report. arXiv preprint arXiv:2303.08774
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [2]
-
[3]
Llemma: An Open Language Model For Mathematics
Azerbayev, Z.; Schoelkopf, H.; Paster, K.; Santos, M. D.; McAleer, S.; Jiang, A. Q.; Deng, J.; Biderman, S.; and Welleck, S. 2023. Llemma: An open language model for mathematics. arXiv preprint arXiv:2310.10631
work page internal anchor Pith review arXiv 2023
-
[4]
Blunch, N. J. 1984. Position bias in multiple-choice questions. Journal of Marketing Research, 21(2): 216--220
work page 1984
- [5]
-
[6]
L.; Bucknall, B.; Haupt, A.; Wei, K.; Scheurer, J.; Hobbhahn, M.; et al
Casper, S.; Ezell, C.; Siegmann, C.; Kolt, N.; Curtis, T. L.; Bucknall, B.; Haupt, A.; Wei, K.; Scheurer, J.; Hobbhahn, M.; et al. 2024. Black-box access is insufficient for rigorous ai audits. In Proceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency, 2254--2272
work page 2024
-
[7]
Chang, Y.; Wang, X.; Wang, J.; Wu, Y.; Yang, L.; Zhu, K.; Chen, H.; Yi, X.; Wang, C.; Wang, Y.; et al. 2024. A survey on evaluation of large language models. ACM transactions on intelligent systems and technology, 15(3): 1--45
work page 2024
-
[8]
Humans or llms as the judge? a study on judgement biases.arXiv preprint arXiv:2402.10669, 2024
Chen, G. H.; Chen, S.; Liu, Z.; Jiang, F.; and Wang, B. 2024. Humans or llms as the judge? a study on judgement biases. arXiv preprint arXiv:2402.10669
-
[9]
Chen, M.; Tworek, J.; Jun, H.; Yuan, Q.; Pinto, H. P. D. O.; Kaplan, J.; Edwards, H.; Burda, Y.; Joseph, N.; Brockman, G.; et al. 2021. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374
work page internal anchor Pith review Pith/arXiv arXiv 2021
- [10]
-
[11]
Chern, E.; Zou, H.; Li, X.; Hu, J.; Feng, K.; Li, J.; and Liu, P. 2023. Generative AI for Math: Abel. https://github.com/GAIR-NLP/abel
work page 2023
-
[12]
N.; Li, T.; Li, D.; Zhu, B.; Zhang, H.; Jordan, M.; Gonzalez, J
Chiang, W.-L.; Zheng, L.; Sheng, Y.; Angelopoulos, A. N.; Li, T.; Li, D.; Zhu, B.; Zhang, H.; Jordan, M.; Gonzalez, J. E.; et al. 2024. Chatbot arena: An open platform for evaluating llms by human preference. In Forty-first International Conference on Machine Learning
work page 2024
-
[13]
Cobbe, K.; Kosaraju, V.; Bavarian, M.; Chen, M.; Jun, H.; Kaiser, L.; Plappert, M.; Tworek, J.; Hilton, J.; Nakano, R.; et al. 2021. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[14]
Connor Chen, W.-L. C.; and Tianle Li, A. N. A. 2025. Introducing Sentiment Control: Disentagling Sentiment and Substance
work page 2025
- [15]
-
[16]
Etzine, B.; Hashemi, M.; Madhusudhan, N.; Davasam, S.; Sharma, R.; Madhusudhan, S. T.; and Yadav, V. 2025. Revitalizing Saturated Benchmarks: A Weighted Metric Approach for Differentiating Large Language Model Performance. arXiv preprint arXiv:2503.05551
-
[17]
Ge, Y.; Hua, W.; Mei, K.; Tan, J.; Xu, S.; Li, Z.; Zhang, Y.; et al. 2023. Openagi: When llm meets domain experts. Advances in Neural Information Processing Systems, 36: 5539--5568
work page 2023
-
[18]
Gudibande, A.; Wallace, E.; Snell, C.; Geng, X.; Liu, H.; Abbeel, P.; Levine, S.; and Song, D. 2023. The False Promise of Imitating Proprietary LLMs. CoRR
work page 2023
-
[19]
Hamborg, K.-C.; H \"u lsmann, J.; and Kaspar, K. 2014. The interplay between usability and aesthetics: More evidence for the “what is usable is beautiful” notion. Advances in Human-Computer Interaction, 2014(1): 946239
work page 2014
-
[20]
Hendrycks, D.; Burns, C.; Basart, S.; Zou, A.; Mazeika, M.; Song, D.; and Steinhardt, J. 2020. Measuring massive multitask language understanding. arXiv preprint arXiv:2009.03300
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[21]
Hendrycks, D.; Burns, C.; Kadavath, S.; Arora, A.; Basart, S.; Tang, E.; Song, D.; and Steinhardt, J. 2021. Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874
work page internal anchor Pith review Pith/arXiv arXiv 2021
- [22]
-
[23]
Jain, N.; Han, K.; Gu, A.; Li, W.-D.; Yan, F.; Zhang, T.; Wang, S.; Solar-Lezama, A.; Sen, K.; and Stoica, I. 2024. Livecodebench: Holistic and contamination free evaluation of large language models for code. arXiv preprint arXiv:2403.07974
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
u chemann, S.; Bannert, M.; Dementieva, D.; Fischer, F.; Gasser, U.; Groh, G.; G \
Kasneci, E.; Se ler, K.; K \"u chemann, S.; Bannert, M.; Dementieva, D.; Fischer, F.; Gasser, U.; Groh, G.; G \"u nnemann, S.; H \"u llermeier, E.; et al. 2023. ChatGPT for good? On opportunities and challenges of large language models for education. Learning and individual differences, 103: 102274
work page 2023
- [25]
- [26]
-
[27]
Li, T.; Angelopoulos, A.; and Chiang, W.-L. 2024. Does style matter? disentangling style and substance in chatbot arena. LMSYS Blog
work page 2024
-
[28]
D.; Re, C.; Acosta-Navas, D.; Hudson, D
Liang, P.; Bommasani, R.; Lee, T.; Tsipras, D.; Soylu, D.; Yasunaga, M.; Zhang, Y.; Narayanan, D.; Wu, Y.; Kumar, A.; Newman, B.; Yuan, B.; Yan, B.; Zhang, C.; Cosgrove, C.; Manning, C. D.; Re, C.; Acosta-Navas, D.; Hudson, D. A.; Zelikman, E.; Durmus, E.; Ladhak, F.; Rong, F.; Ren, H.; Yao, H.; WANG, J.; Santhanam, K.; Orr, L.; Zheng, L.; Yuksekgonul, M....
work page 2023
-
[29]
Lu, P.; Qiu, L.; Yu, W.; Welleck, S.; and Chang, K.-W. 2023. A Survey of Deep Learning for Mathematical Reasoning. In ACL (1)
work page 2023
-
[30]
Luo, H.; Sun, Q.; Xu, C.; Zhao, P.; Lou, J.; Tao, C.; Geng, X.; Lin, Q.; Chen, S.; and Zhang, D. 2023. Wizardmath: Empowering mathematical reasoning for large language models via reinforced evol-instruct. arXiv preprint arXiv:2308.09583
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [31]
-
[32]
Mirzadeh, I.; Alizadeh, K.; Shahrokhi, H.; Tuzel, O.; Bengio, S.; and Farajtabar, M. 2024. Gsm-symbolic: Understanding the limitations of mathematical reasoning in large language models. arXiv preprint arXiv:2410.05229
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
Nejjar, M.; Zacharias, L.; Stiehle, F.; and Weber, I. 2025. LLMs for science:: Usage for code generation and data analysis. Journal of Software: Evolution and Process, 37(1): e2723
work page 2025
-
[34]
Raghubir, P.; and Valenzuela, A. 2006. Center-of-inattention: Position biases in decision-making. Organizational Behavior and Human Decision Processes, 99(1): 66--80
work page 2006
-
[35]
Rein, D.; Hou, B. L.; Stickland, A. C.; Petty, J.; Pang, R. Y.; Dirani, J.; Michael, J.; and Bowman, S. R. 2024. Gpqa: A graduate-level google-proof q&a benchmark. In First Conference on Language Modeling
work page 2024
-
[36]
Nlp evaluation in trouble: On the need to measure llm data contamination for each benchmark, 2023
Sainz, O.; Campos, J. A.; Garc \' a-Ferrero, I.; Etxaniz, J.; de Lacalle, O. L.; and Agirre, E. 2023. NLP evaluation in trouble: On the need to measure LLM data contamination for each benchmark. arXiv preprint arXiv:2310.18018
-
[37]
A.; Abid, A.; Fisch, A.; Brown, A
Srivastava, A.; Rastogi, A.; Rao, A.; Shoeb, A. A.; Abid, A.; Fisch, A.; Brown, A. R.; Santoro, A.; Gupta, A.; Garriga-Alonso, A.; et al. 2023. Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on machine learning research
work page 2023
-
[38]
Gemini: A Family of Highly Capable Multimodal Models
Team, G.; Anil, R.; Borgeaud, S.; Alayrac, J.-B.; Yu, J.; Soricut, R.; Schalkwyk, J.; Dai, A. M.; Hauth, A.; Millican, K.; et al. 2023. Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[39]
Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.-A.; Lacroix, T.; Rozi \`e re, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. 2023. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[40]
Tuch, A. N.; Roth, S. P.; Hornb k, K.; Opwis, K.; and Bargas-Avila, J. A. 2012. Is beautiful really usable? Toward understanding the relation between usability, aesthetics, and affect in HCI. Computers in human behavior, 28(5): 1596--1607
work page 2012
-
[41]
N.; Kaiser, .; and Polosukhin, I
Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A. N.; Kaiser, .; and Polosukhin, I. 2017. Attention is all you need. Advances in neural information processing systems, 30
work page 2017
- [42]
-
[43]
Wang, A.; Pruksachatkun, Y.; Nangia, N.; Singh, A.; Michael, J.; Hill, F.; Levy, O.; and Bowman, S. 2019. Superglue: A stickier benchmark for general-purpose language understanding systems. Advances in neural information processing systems, 32
work page 2019
- [44]
-
[45]
Xu, C.; Guan, S.; Greene, D.; Kechadi, M.; et al. 2024. Benchmark data contamination of large language models: A survey. arXiv preprint arXiv:2406.04244
work page internal anchor Pith review arXiv 2024
-
[46]
F.; Alon, U.; Neubig, G.; and Hellendoorn, V
Xu, F. F.; Alon, U.; Neubig, G.; and Hellendoorn, V. J. 2022. A systematic evaluation of large language models of code. In Proceedings of the 6th ACM SIGPLAN international symposium on machine programming, 1--10
work page 2022
-
[47]
Guanhua Zhang and Moritz Hardt
Yang, S.; Chiang, W.-L.; Zheng, L.; Gonzalez, J. E.; and Stoica, I. 2023. Rethinking benchmark and contamination for language models with rephrased samples. arXiv preprint arXiv:2311.04850
-
[48]
MetaMath: Bootstrap Your Own Mathematical Questions for Large Language Models
Yu, L.; Jiang, W.; Shi, H.; Yu, J.; Liu, Z.; Zhang, Y.; Kwok, J. T.; Li, Z.; Weller, A.; and Liu, W. 2023. Metamath: Bootstrap your own mathematical questions for large language models. arXiv preprint arXiv:2309.12284
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[49]
Zellers, R.; Holtzman, A.; Bisk, Y.; Farhadi, A.; and Choi, Y. 2019. Hellaswag: Can a machine really finish your sentence? arXiv preprint arXiv:1905.07830
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[50]
Zhong, W.; Cui, R.; Guo, Y.; Liang, Y.; Lu, S.; Wang, Y.; Saied, A.; Chen, W.; and Duan, N. 2023. Agieval: A human-centric benchmark for evaluating foundation models. arXiv preprint arXiv:2304.06364
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[51]
, " * write output.state after.block = add.period write newline
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint howpublished institution isbn journal key month note number organization pages publisher school series title type volume year label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block FUNCTION init.state.consts #0 'before.a...
-
[52]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.