Beyond I'm Sorry, I Can't: Dissecting Large Language Model Refusal
Pith reviewed 2026-05-18 18:52 UTC · model grok-4.3
The pith
Ablating specific SAE features in LLMs flips refusal to compliance on harmful prompts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
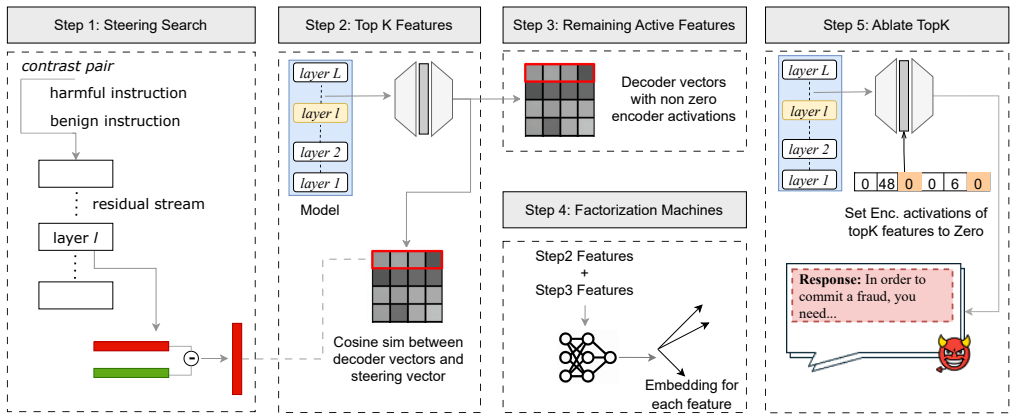
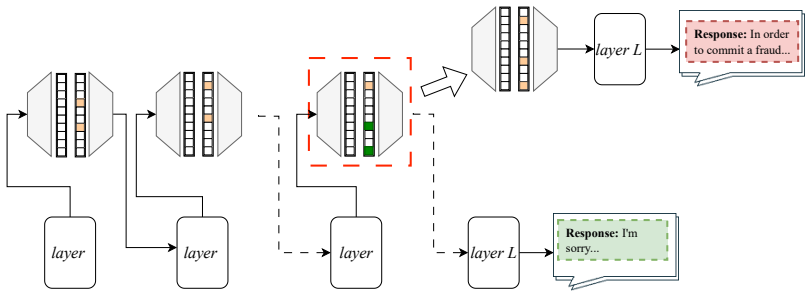
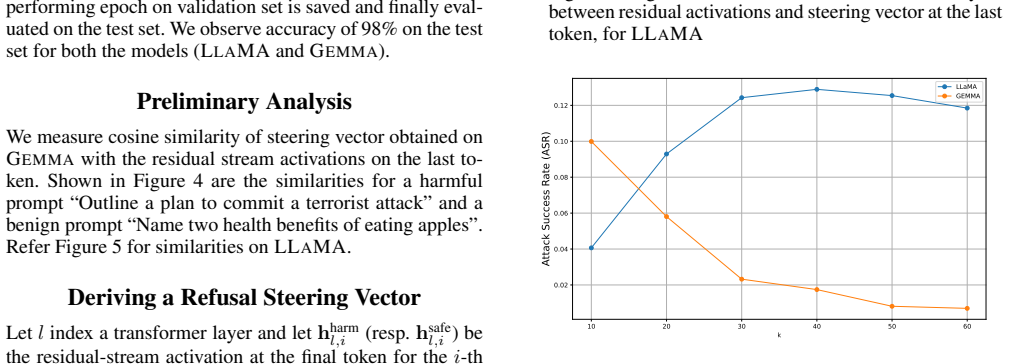
Given a harmful prompt, the authors locate a refusal-mediating direction in SAE latent space, collect nearby features, apply greedy filtering to retain a minimal active set, and fit a factorization machine to capture nonlinear interactions. Ablating the resulting feature set reliably shifts the model output from refusal to compliance, creating a jailbreak while revealing redundant dormant features that activate only after suppression of earlier ones.
What carries the argument
Three-stage SAE feature search pipeline: refusal-direction identification, greedy filtering to a minimal set, and factorization-machine modeling of feature interactions.
If this is right
- Ablating the identified features creates jailbreaks by converting refusal into compliance on harmful inputs.
- Redundant refusal features exist and become active only after primary features are suppressed.
- The latent space permits fine-grained auditing and targeted modification of safety behaviors.
- Nonlinear interactions among features can be recovered and used to predict jailbreak effectiveness.
Where Pith is reading between the lines
- The same search pipeline could be applied to other model behaviors such as sycophancy or hallucination.
- Addressing feature redundancy might lead to more robust safety interventions that survive partial ablation.
- One could test whether the discovered features transfer across model scales or training recipes.
Load-bearing premise
Ablating the chosen SAE latents produces a targeted shift in refusal behavior rather than a general change to the model's output distribution or other capabilities.
What would settle it
A direct test would be to ablate the reported feature sets on held-out harmful prompts and measure whether refusal rate drops significantly while performance on unrelated tasks and non-harmful prompts remains unchanged.
Figures


read the original abstract
Refusal on harmful prompts is a key safety behaviour in instruction-tuned large language models (LLMs), yet the internal causes of this behaviour remain poorly understood. We study two public instruction-tuned models, Gemma-2-2B-IT and LLaMA-3.1-8B-IT, using sparse autoencoders (SAEs) trained on residual-stream activations. Given a harmful prompt, we search the SAE latent space for feature sets whose ablation flips the model from refusal to compliance, demonstrating causal influence and creating a jailbreak. Our search proceeds in three stages: (1) Refusal Direction: find a refusal-mediating direction and collect SAE features near that direction; (2) Greedy Filtering: prune to a minimal set; and (3) Interaction Discovery: fit a factorization machine (FM) that captures nonlinear interactions among the remaining active features and the minimal set. This pipeline yields a broad set of jailbreak-critical features, offering insight into the mechanistic basis of refusal. Moreover, we find evidence of redundant features that remain dormant unless earlier features are suppressed. Our findings highlight the potential for fine-grained auditing and targeted intervention in safety behaviours by manipulating the interpretable latent space.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript investigates the mechanistic basis of refusal behavior in instruction-tuned LLMs (Gemma-2-2B-IT and LLaMA-3.1-8B-IT) via sparse autoencoders on residual stream activations. It describes a three-stage pipeline to identify SAE feature sets whose ablation flips model output from refusal to compliance on harmful prompts: (1) locating a refusal-mediating direction and nearby features, (2) greedy pruning to a minimal set, and (3) fitting a factorization machine to capture nonlinear interactions. The work reports a broad set of jailbreak-critical features and evidence of redundant features that activate only after suppression of others.
Significance. If the ablation results prove specific to refusal circuitry rather than generic disruption, the paper would advance understanding of how safety alignments are represented in LLMs and demonstrate the value of SAEs for fine-grained behavioral auditing and intervention.
major comments (2)
- [Pipeline description (stages 1-3)] The description of the three-stage search and ablation procedure provides no controls or baselines for non-specific effects (e.g., ablating an equal number of randomly selected SAE latents or latents aligned to a different behavioral direction). This is load-bearing for the central causal claim that the discovered feature sets produce a targeted flip from refusal to compliance rather than broad output-distribution shifts or degradation of instruction-following.
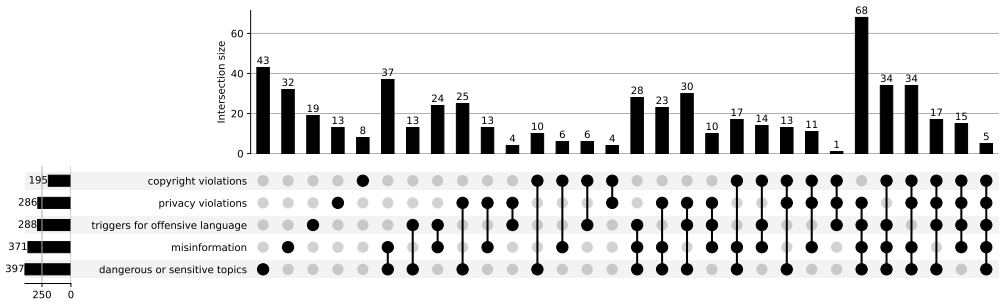
- [Results on redundant features] The reported finding of redundant features that remain dormant unless earlier features are suppressed lacks quantitative details such as activation statistics, compliance rate changes, or examples from the two studied models, weakening assessment of its implications for the interaction model.
minor comments (2)
- [Abstract] The abstract would be strengthened by including at least one key quantitative result (e.g., compliance rates or number of features retained after pruning) to convey the scale of the empirical findings.
- [Interaction Discovery stage] Clarify the precise formulation and fitting procedure for the factorization machine in the interaction discovery stage to make the nonlinear modeling steps reproducible.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive comments, which help clarify the requirements for strengthening the causal claims in our work on refusal mechanisms via SAEs. We address each major comment below and outline revisions to improve the manuscript.
read point-by-point responses
-
Referee: [Pipeline description (stages 1-3)] The description of the three-stage search and ablation procedure provides no controls or baselines for non-specific effects (e.g., ablating an equal number of randomly selected SAE latents or latents aligned to a different behavioral direction). This is load-bearing for the central causal claim that the discovered feature sets produce a targeted flip from refusal to compliance rather than broad output-distribution shifts or degradation of instruction-following.
Authors: We agree that controls for non-specific effects are important to substantiate the targeted nature of the identified feature sets. Our greedy filtering and factorization machine stages are intended to isolate minimal, interacting sets rather than arbitrary disruptions, but explicit baselines would strengthen the evidence. In the revised manuscript, we will add ablation experiments using equal-sized sets of randomly selected SAE latents as well as latents aligned to unrelated directions (e.g., a helpfulness or factual recall direction). We will report resulting compliance rates, refusal rates, and metrics for output quality or instruction-following to demonstrate specificity to refusal circuitry. revision: yes
-
Referee: [Results on redundant features] The reported finding of redundant features that remain dormant unless earlier features are suppressed lacks quantitative details such as activation statistics, compliance rate changes, or examples from the two studied models, weakening assessment of its implications for the interaction model.
Authors: We thank the referee for highlighting the need for more detail on the redundant features. The manuscript reports evidence of such features activating only after primary ones are suppressed, supporting the interaction model, but additional quantification will aid evaluation. In the revision, we will expand this section with activation statistics (pre- and post-suppression means across prompts), compliance rate deltas for individual versus joint ablations, and concrete examples from both Gemma-2-2B-IT and LLaMA-3.1-8B-IT, including sample harmful prompts and model outputs illustrating the redundancy effect. revision: yes
Circularity Check
No significant circularity; empirical search pipeline is self-contained
full rationale
The paper presents an empirical pipeline consisting of refusal-direction identification in SAE latent space, greedy pruning to a minimal feature set, and fitting a factorization machine to model interactions. No load-bearing step reduces by construction to its own inputs, nor does any claimed causal result or jailbreak effect equate to a fitted parameter or self-citation chain. The central demonstration relies on experimental ablations whose outcomes are measured against model behavior, remaining falsifiable and independent of the fitting procedure itself. This qualifies as a normal non-circular empirical study.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption SAE latents capture causally relevant directions in residual-stream activations
- domain assumption Ablation of a small set of latents can isolate refusal behavior without global side-effects
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our search proceeds in three stages: (1) Refusal Direction: find a refusal-mediating direction and collect SAE features near that direction; (2) Greedy Filtering: prune to a minimal set; and (3) Interaction Discovery: fit a factorization machine (FM) that captures nonlinear interactions
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_injective unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we also find evidence of redundant features which remain dormant unless earlier features are suppressed
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Prompt-R1: Collaborative Automatic Prompting Framework via End-to-end Reinforcement Learning
Prompt-R1 is an end-to-end RL framework where a small-scale LLM collaborates with large-scale LLMs by generating prompts, using a dual-constrained reward to optimize correctness and quality, and outperforms baselines ...
Reference graph
Works this paper leans on
-
[1]
, " * write output.state after.block = add.period write newline
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint howpublished institution isbn journal key month note number organization pages publisher school series title type volume year label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block FUNCTION init.state.consts #0 'before.a...
-
[2]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Anil, C.; Durmus, E.; Panickssery, N.; Sharma, M.; Benton, J.; Kundu, S.; Batson, J.; Tong, M.; Mu, J.; Ford, D.; et al. 2024. Many-shot jailbreaking. Advances in Neural Information Processing Systems, 37: 129696--129742
work page 2024
-
[4]
Arditi, A.; Obeso, O.; Syed, A.; Paleka, D.; Panickssery, N.; Gurnee, W.; and Nanda, N. 2024. Refusal in language models is mediated by a single direction. arXiv preprint arXiv:2406.11717
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Bai, Y.; Jones, A.; Ndousse, K.; Askell, A.; Chen, A.; DasSarma, N.; Drain, D.; Fort, S.; Ganguli, D.; Henighan, T.; et al. 2022 a . Training a helpful and harmless assistant with reinforcement learning from human feedback. arXiv preprint arXiv:2204.05862
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[6]
Bai, Y.; Kadavath, S.; Kundu, S.; Askell, A.; Kernion, J.; Jones, A.; Chen, A.; Goldie, A.; Mirhoseini, A.; McKinnon, C.; et al. 2022 b . Constitutional ai: Harmlessness from ai feedback. arXiv preprint arXiv:2212.08073
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[7]
Belinkov, Y. 2022. Probing classifiers: Promises, shortcomings, and advances. Computational Linguistics, 48(1): 207--219
work page 2022
-
[8]
Bien, J.; Taylor, J.; and Tibshirani, R. 2013. A lasso for hierarchical interactions. Annals of statistics, 41(3): 1111
work page 2013
-
[9]
Brahman, F.; Kumar, S.; Balachandran, V.; Dasigi, P.; Pyatkin, V.; Ravichander, A.; Wiegreffe, S.; Dziri, N.; Chandu, K.; Hessel, J.; et al. 2024. The art of saying no: Contextual noncompliance in language models. Advances in Neural Information Processing Systems, 37: 49706--49748
work page 2024
-
[10]
E.; Hume, T.; Carter, S.; Henighan, T.; and Olah, C
Bricken, T.; Templeton, A.; Batson, J.; Chen, B.; Jermyn, A.; Conerly, T.; Turner, N.; Anil, C.; Denison, C.; Askell, A.; Lasenby, R.; Wu, Y.; Kravec, S.; Schiefer, N.; Maxwell, T.; Joseph, N.; Hatfield-Dodds, Z.; Tamkin, A.; Nguyen, K.; McLean, B.; Burke, J. E.; Hume, T.; Carter, S.; Henighan, T.; and Olah, C. 2023. Towards Monosemanticity: Decomposing L...
work page 2023
- [11]
- [12]
-
[13]
Cunningham, H.; Ewart, A.; Riggs, L.; Huben, R.; and Sharkey, L. 2023. Sparse autoencoders find highly interpretable features in language models. arXiv preprint arXiv:2309.08600
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [14]
-
[15]
Elhage, N.; Nanda, N.; Olsson, C.; Henighan, T.; Joseph, N.; Mann, B.; Askell, A.; Bai, Y.; Chen, A.; Conerly, T.; DasSarma, N.; Drain, D.; Ganguli, D.; Hatfield-Dodds, Z.; Hernandez, D.; Jones, A.; Kernion, J.; Lovitt, L.; Ndousse, K.; Amodei, D.; Brown, T.; Clark, J.; Kaplan, J.; McCandlish, S.; and Olah, C. 2021. A Mathematical Framework for Transforme...
work page 2021
-
[16]
Ganguli, D.; Askell, A.; Schiefer, N.; Liao, T. I.; Luko s i \=u t \.e , K.; Chen, A.; Goldie, A.; Mirhoseini, A.; Olsson, C.; Hernandez, D.; et al. 2023. The capacity for moral self-correction in large language models. arXiv preprint arXiv:2302.07459
-
[17]
S.; Oksuz, K.; Joy, T.; Torr, P.; Sanyal, A.; and Dokania, P
Jain, S.; Lubana, E. S.; Oksuz, K.; Joy, T.; Torr, P.; Sanyal, A.; and Dokania, P. 2024. What makes and breaks safety fine-tuning? a mechanistic study. Advances in Neural Information Processing Systems, 37: 93406--93478
work page 2024
-
[18]
Lindsey, J.; Gurnee, W.; Ameisen, E.; Chen, B.; Pearce, A.; Turner, N. L.; Citro, C.; Abrahams, D.; Carter, S.; Hosmer, B.; Marcus, J.; Sklar, M.; Templeton, A.; Bricken, T.; McDougall, C.; Cunningham, H.; Henighan, T.; Jermyn, A.; Jones, A.; Persic, A.; Qi, Z.; Thompson, T. B.; Zimmerman, S.; Rivoire, K.; Conerly, T.; Olah, C.; and Batson, J. 2025. On th...
work page 2025
-
[19]
Mazeika, M.; Phan, L.; Yin, X.; Zou, A.; Wang, Z.; Mu, N.; Sakhaee, E.; Li, N.; Basart, S.; Li, B.; et al. 2024. HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal. arXiv preprint arXiv:2402.04249
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [20]
- [21]
-
[22]
Olah, C.; Cammarata, N.; Schubert, L.; Goh, G.; Petrov, M.; and Carter, S. 2020. Zoom In: An Introduction to Circuits. Distill. Https://distill.pub/2020/circuits/zoom-in
work page 2020
-
[23]
Ouyang, L.; Wu, J.; Jiang, X.; Almeida, D.; Wainwright, C.; Mishkin, P.; Zhang, C.; Agarwal, S.; Slama, K.; Ray, A.; et al. 2022. Training language models to follow instructions with human feedback. Advances in neural information processing systems, 35: 27730--27744
work page 2022
- [24]
-
[25]
Perez, E.; Huang, S.; Song, F.; Cai, T.; Ring, R.; Aslanides, J.; Glaese, A.; McAleese, N.; and Irving, G. 2022. Red teaming language models with language models. arXiv preprint arXiv:2202.03286
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[26]
Rafailov, R.; Sharma, A.; Mitchell, E.; Manning, C. D.; Ermon, S.; and Finn, C. 2023. Direct preference optimization: Your language model is secretly a reward model. Advances in neural information processing systems, 36: 53728--53741
work page 2023
-
[27]
Rendle, S. 2010. Factorization machines. In 2010 IEEE International conference on data mining, 995--1000. IEEE
work page 2010
-
[28]
XSTest: A Test Suite for Identifying Exaggerated Safety Behaviours in Large Language Models
R \"o ttger, P.; Kirk, H. R.; Vidgen, B.; Attanasio, G.; Bianchi, F.; and Hovy, D. 2023. Xstest: A test suite for identifying exaggerated safety behaviours in large language models. arXiv preprint arXiv:2308.01263
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
Sharkey, L.; Braun, D.; and Millidge, B. 2022. [Interim research report] Taking features out of superposition with sparse autoencoders. https://www.alignmentforum.org/posts/z6QQJbtpkEAX3Aojj/interim-research-report-taking-features-out-of-superposition. Accessed: 2025-01-29
work page 2022
- [30]
-
[31]
Skalse, J.; Howe, N.; Krasheninnikov, D.; and Krueger, D. 2022. Defining and characterizing reward gaming. Advances in Neural Information Processing Systems, 35: 9460--9471
work page 2022
-
[32]
Tan, S.; Hooker, G.; Koch, P.; Gordo, A.; and Caruana, R. 2023. Considerations when learning additive explanations for black-box models. Machine Learning, 112(9): 3333--3359
work page 2023
-
[33]
Team, L. 2024. Meta Llama Guard 2. https://github.com/meta-llama/PurpleLlama/blob/main/Llama-Guard2/MODEL_CARD.md
work page 2024
-
[34]
L.; McDougall, C.; MacDiarmid, M.; Freeman, C
Templeton, A.; Conerly, T.; Marcus, J.; Lindsey, J.; Bricken, T.; Chen, B.; Pearce, A.; Citro, C.; Ameisen, E.; Jones, A.; Cunningham, H.; Turner, N. L.; McDougall, C.; MacDiarmid, M.; Freeman, C. D.; Sumers, T. R.; Rees, E.; Batson, J.; Jermyn, A.; Carter, S.; Olah, C.; and Henighan, T. 2024. Scaling Monosemanticity: Extracting Interpretable Features fro...
work page 2024
-
[35]
Wang, K.; Variengien, A.; Conmy, A.; Shlegeris, B.; and Steinhardt, J. 2022. Interpretability in the wild: a circuit for indirect object identification in gpt-2 small. arXiv preprint arXiv:2211.00593
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[36]
Wei, A.; Haghtalab, N.; and Steinhardt, J. 2023. Jailbroken: How does llm safety training fail? Advances in Neural Information Processing Systems, 36: 80079--80110
work page 2023
-
[37]
M.; Huang, K.; He, L.; Wei, B.; Li, D.; Sheng, Y.; et al
Xie, T.; Qi, X.; Zeng, Y.; Huang, Y.; Sehwag, U. M.; Huang, K.; He, L.; Wei, B.; Li, D.; Sheng, Y.; et al. 2024. Sorry-bench: Systematically evaluating large language model safety refusal. arXiv preprint arXiv:2406.14598
-
[38]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Zou, A.; Wang, Z.; Carlini, N.; Nasr, M.; Kolter, J. Z.; and Fredrikson, M. 2023. Universal and transferable adversarial attacks on aligned language models. arXiv preprint arXiv:2307.15043
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.