Learning Geometry-Aware Nonprehensile Pushing and Pulling with Dexterous Hands
Pith reviewed 2026-05-18 13:48 UTC · model grok-4.3
The pith
A diffusion model trained on object geometry predicts pre-contact poses that let dexterous hands push and pull objects effectively.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Geometry-aware Dexterous Pushing and Pulling (GD2P) frames nonprehensile manipulation as the synthesis of pre-contact dexterous hand poses that produce effective object motion. Diverse poses are generated via contact-guided sampling and filtered by physics simulation; a diffusion model conditioned on object geometry is then trained to predict viable poses. At test time the model supplies poses that motion planners execute as pushing or pulling actions, with successful real-world results shown on both Allegro and LEAP hands.
What carries the argument
A diffusion model conditioned on object geometry that outputs viable pre-contact hand poses after contact-guided sampling and physics-simulation filtering.
If this is right
- The same trained model can be applied to multiple hand morphologies without retraining from scratch.
- Objects that are hard to grasp because of size or shape become reachable through stable multi-finger contacts.
- Standard motion planners become sufficient once a good initial pose is supplied by the learned model.
- Explicit modeling of full contact dynamics is avoided by relying on simulation-filtered examples.
Where Pith is reading between the lines
- The pipeline could be adapted to other nonprehensile skills such as sliding or pivoting by adding further object features to the conditioning.
- Pairing the method with online 3-D sensing would allow the system to handle previously unknown objects in unstructured settings.
- Similar sampling-plus-diffusion pipelines might transfer to non-hand end-effectors for comparable tasks.
Load-bearing premise
Poses generated from object geometry alone and screened in simulation will transfer to reliable real-world pushing and pulling on objects and environments never seen during training.
What would settle it
Real-world trials on a new set of objects with geometries outside the training set produce mostly failed or ineffective pushes and pulls despite using the model's predicted poses.
Figures















read the original abstract
Nonprehensile manipulation, such as pushing and pulling, enables robots to move, align, or reposition objects that may be difficult to grasp due to their geometry, size, or relationship to the robot or the environment. Much of the existing work in nonprehensile manipulation relies on parallel-jaw grippers or tools such as rods and spatulas. In contrast, multi-fingered dexterous hands offer richer contact modes and versatility for handling diverse objects to provide stable support over the objects, which compensates for the difficulty of modeling the dynamics of nonprehensile manipulation. Therefore, we propose Geometry-aware Dexterous Pushing and Pulling(GD2P) for nonprehensile manipulation with dexterous robotic hands. We study pushing and pulling by framing the problem as synthesizing and learning pre-contact dexterous hand poses that lead to effective manipulation. We generate diverse hand poses via contact-guided sampling, filter them using physics simulation, and train a diffusion model conditioned on object geometry to predict viable poses. At test time, we sample hand poses and use standard motion planners to select and execute pushing and pulling actions. We perform extensive real-world experiments with an Allegro Hand and a LEAP Hand, demonstrating that GD2P offers a scalable route for generating dexterous nonprehensile manipulation motions with its applicability to different hand morphologies. Our project website is available at: geodex2p.github.io.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes GD2P for nonprehensile pushing and pulling with dexterous hands. Hand poses are generated via contact-guided sampling, filtered by physics simulation, and used to train a geometry-conditioned diffusion model; at test time, sampled poses are executed via standard motion planners. Real-world validation is reported on Allegro and LEAP hands, with the central claim being that this pipeline provides a scalable route to dexterous nonprehensile motions applicable across hand morphologies and unseen objects.
Significance. If the simulation-to-real transfer for geometry-conditioned poses holds, the work offers a practical, morphology-agnostic approach to nonprehensile manipulation that leverages diffusion models and physics filtering rather than hand-specific dynamics modeling. The demonstration across two distinct hands (Allegro and LEAP) and the emphasis on real-world execution are concrete strengths that could influence future dexterous manipulation pipelines.
major comments (2)
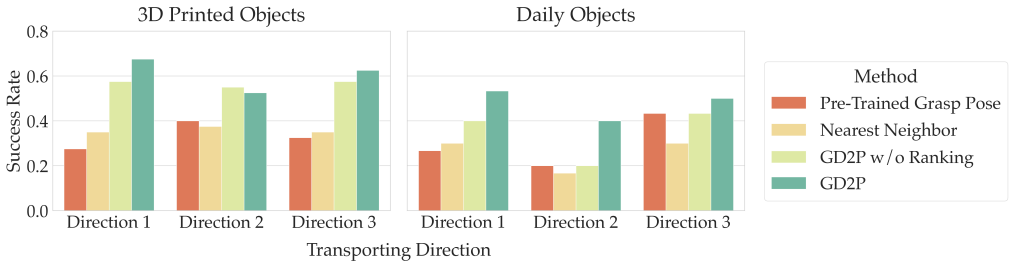
- [Experiments] Experiments section: the manuscript claims reliable real-world pushing/pulling across unseen objects and two hand morphologies after physics-simulation filtering of diffusion samples, yet provides no quantitative success rates, ablation on the filtering step, or analysis of failure modes attributable to unmodeled contact dynamics. This directly weakens the scalability claim because nonprehensile outcomes are sensitive to friction, compliance, and transients not determined by object geometry alone.
- [Method] Method section (diffusion model conditioning): the model is conditioned solely on object geometry to predict viable pre-contact poses, but the paper does not demonstrate or bound how well geometry encodes the contact forces and stability needed for pushing/pulling; any mismatch between sim ranking and real execution undermines the assertion that the pipeline generalizes without additional sensing or adaptation.
minor comments (1)
- [Abstract] Abstract: the phrase 'extensive real-world experiments' is used without even high-level statistics (e.g., number of objects, trials, or success criteria), reducing clarity for readers evaluating the empirical support.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below with honest responses and indicate where revisions will be made to strengthen the presentation of results and clarify methodological choices.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the manuscript claims reliable real-world pushing/pulling across unseen objects and two hand morphologies after physics-simulation filtering of diffusion samples, yet provides no quantitative success rates, ablation on the filtering step, or analysis of failure modes attributable to unmodeled contact dynamics. This directly weakens the scalability claim because nonprehensile outcomes are sensitive to friction, compliance, and transients not determined by object geometry alone.
Authors: We agree that quantitative success rates, ablations, and failure-mode analysis would provide stronger support for the scalability claims. The manuscript currently focuses on qualitative real-world demonstrations across multiple unseen objects and two hand morphologies to illustrate versatility. In the revised version we will add a table of success rates (successful manipulations over repeated trials per object and task), an ablation isolating the contribution of the physics-based filtering step, and a dedicated subsection discussing observed failure modes, including those arising from unmodeled friction, compliance, and contact transients. These additions will directly address the concern. revision: yes
-
Referee: [Method] Method section (diffusion model conditioning): the model is conditioned solely on object geometry to predict viable pre-contact poses, but the paper does not demonstrate or bound how well geometry encodes the contact forces and stability needed for pushing/pulling; any mismatch between sim ranking and real execution undermines the assertion that the pipeline generalizes without additional sensing or adaptation.
Authors: Conditioning exclusively on geometry is a deliberate design decision to enable generalization across unseen objects and hand morphologies without requiring force sensing or hand-specific dynamics models. Real-world execution results on both the Allegro and LEAP hands with novel objects provide empirical evidence that the resulting poses are effective when combined with physics filtering. We acknowledge, however, that geometry alone cannot fully encode all contact forces or transient dynamics. In revision we will expand the Method section with an explicit discussion of this limitation, including potential sim-to-real mismatches due to friction and compliance, and note how the physics filter mitigates some of these effects. We will also include qualitative observations from our experiments on transfer performance. revision: partial
Circularity Check
No circularity: GD2P is an empirical pipeline of sampling, simulation filtering, and diffusion training validated externally
full rationale
The paper's core chain consists of contact-guided pose sampling, physics-simulation filtering to create training data, training a diffusion model conditioned on object geometry, and then real-world execution with motion planning on two distinct hand platforms. This is a standard data-driven learning setup whose performance claims rest on experimental outcomes across unseen objects and morphologies rather than any quantity being redefined as its own input. No self-definitional equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the derivation; the simulation and diffusion components are external to the final claims and are not tautological with the reported results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Physics simulation provides a sufficiently accurate proxy for real-world contact dynamics when filtering candidate hand poses.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We generate diverse hand poses via contact-guided sampling, filter them using physics simulation, and train a diffusion model conditioned on object geometry to predict viable poses.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
train a diffusion model conditioned on object geometry... using basis point sets
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Efficient learning on point clouds with basis point sets,
S. Prokudin, C. Lassner, and J. Romero, “Efficient learning on point clouds with basis point sets,” inIEEE/CVF International Conference on Computer Vision (ICCV), 2019
work page 2019
-
[2]
Dexdiffuser: Generating dexterous grasps with diffusion models,
Z. Weng, H. Lu, D. Kragic, and J. Lundell, “Dexdiffuser: Generating dexterous grasps with diffusion models,” inIEEE Robotics and Automation Letters (RA-L), 2024
work page 2024
-
[3]
curobo: Parallelized collision-free minimum-jerk robot motion generation
B. Sundaralingam et al., “Curobo: Parallelized collision- free minimum-jerk robot motion generation,”arXiv preprint arXiv:2310.17274, 2023
-
[4]
Mechanics and Planning of Manipulator Pushing Operations,
M. T. Mason, “Mechanics and Planning of Manipulator Pushing Operations,” inInternational Journal of Robotics Research, 1986
work page 1986
-
[5]
Nonprehensile robotic manipulation: Controllability and planning,
K. Lynch, “Nonprehensile robotic manipulation: Controllability and planning,” Ph.D. dissertation, Carnegie Mellon University, 1996
work page 1996
-
[6]
Progress in Nonprehensile Manipulation,
M. T. Mason, “Progress in Nonprehensile Manipulation,” inInter- national Journal of Robotics Research (IJRR), 1999
work page 1999
-
[7]
Dynamic nonprehensile manipu- lation: Controllability, planning, and experiments,
K. M. Lynch and M. T. Mason, “Dynamic nonprehensile manipu- lation: Controllability, planning, and experiments,” inInternational Journal of Robotics Research (IJRR), 1999
work page 1999
-
[8]
Learning to Grasp the Ungraspable with Emergent Extrinsic Dexterity,
W. Zhou and D. Held, “Learning to Grasp the Ungraspable with Emergent Extrinsic Dexterity,” inConference on Robot Learning (CoRL), 2022
work page 2022
-
[9]
HACMan: Learning Hybrid Actor-Critic Maps for 6D Non-Prehensile Manip- ulation,
W. Zhou, B. Jiang, F. Yang, C. Paxton, and D. Held, “HACMan: Learning Hybrid Actor-Critic Maps for 6D Non-Prehensile Manip- ulation,” inConference on Robot Learning (CoRL), 2023
work page 2023
-
[10]
Hac- man++: Spatially-grounded motion primitives for manipulation,
B. Jiang, Y . Wu, W. Zhou, C. Paxton, and D. Held, “Hac- man++: Spatially-grounded motion primitives for manipulation,” in Robotics: Science and Systems (RSS), 2024
work page 2024
-
[11]
Corn: Contact-based object representation for nonprehensile manipulation of general unseen objects,
Y . Cho, J. Han, Y . Cho, and B. Kim, “Corn: Contact-based object representation for nonprehensile manipulation of general unseen objects,” inInternational Conference on Learning Representations (ICLR), 2024
work page 2024
-
[12]
Dywa: Dynamics-adaptive world action model for generalizable non- prehensile manipulation,
J. Lyu, Z. Li, X. Shi, C. Xu, Y . Wang, and H. Wang, “Dywa: Dynamics-adaptive world action model for generalizable non- prehensile manipulation,” inIEEE/CVF International Conference on Computer Vision (ICCV), 2025
work page 2025
-
[13]
Adaptigraph: Material- adaptive graph-based neural dynamics for robotic manipulation,
K. Zhang, B. Li, K. Hauser, and Y . Li, “Adaptigraph: Material- adaptive graph-based neural dynamics for robotic manipulation,” in Robotics: Science and Systems (RSS), 2024
work page 2024
-
[14]
Diffusion Policy: Visuomotor Policy Learning via Action Diffusion,
C. Chi et al., “Diffusion Policy: Visuomotor Policy Learning via Action Diffusion,” inRobotics: Science and Systems (RSS), 2023
work page 2023
-
[15]
Dynamic-resolution model learning for object pile manipulation,
Y . Wang, Y . Li, K. Driggs-Campbell, L. Fei-Fei, and J. Wu, “Dynamic-resolution model learning for object pile manipulation,” inRobotics: Science and Systems (RSS), 2023
work page 2023
-
[16]
LEAP Hand: Low-Cost, Efficient, and Anthropomorphic Hand for Robot Learning,
K. Shaw, A. Agarwal, and D. Pathak, “LEAP Hand: Low-Cost, Efficient, and Anthropomorphic Hand for Robot Learning,” in Robotics: Science and Systems (RSS), 2023
work page 2023
-
[17]
Dexterous non-prehensile manipulation for ungraspable object via extrinsic dexterity,
Y . Wang, Y . Li, Y . Yang, and Y . Chen, “Dexterous non-prehensile manipulation for ungraspable object via extrinsic dexterity,”arXiv preprint arXiv:2503.23120, 2025
-
[18]
Dexgraspvla: A vision-language-action framework towards general dexterous grasping,
Y . Zhong et al., “DexGraspVLA: A Vision-Language-Action Framework Towards General Dexterous Grasping,”arXiv preprint arXiv:2502.20900, 2025
-
[19]
Get a Grip: Multi-Finger Grasp Evaluation at Scale Enables Robust Sim-to-Real Transfer,
T. G. W. Lum et al., “Get a Grip: Multi-Finger Grasp Evaluation at Scale Enables Robust Sim-to-Real Transfer,” inConference on Robot Learning (CoRL), 2024
work page 2024
-
[20]
DexGraspNet: A large-scale robotic dexterous grasp dataset for general objects based on simulation,
R. Wang et al., “DexGraspNet: A large-scale robotic dexterous grasp dataset for general objects based on simulation,” inInternational Conference on Robotics and Automation (ICRA), 2023
work page 2023
-
[21]
DexGraspNet 2.0: Learning Generative Dexterous Grasping in Large-scale Synthetic Cluttered Scenes,
J. Zhang et al., “DexGraspNet 2.0: Learning Generative Dexterous Grasping in Large-scale Synthetic Cluttered Scenes,” inConference on Robot Learning (CoRL), 2024
work page 2024
-
[22]
Y . Xu et al., “UniDexGrasp: Universal robotic dexterous grasp- ing via learning diverse proposal generation and goal-conditioned policy,” inIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2023
work page 2023
-
[23]
W. Wan et al., “UniDexGrasp++: Improving dexterous grasping pol- icy learning via geometry-aware curriculum and iterative generalist- specialist learning,” inIEEE/CVF International Conference on Computer Vision (ICCV), 2023
work page 2023
-
[24]
Grasp multiple objects with one hand,
Y . Li et al., “Grasp multiple objects with one hand,” inIEEE Robotics and Automation Letters (RA-L), 2024
work page 2024
-
[25]
Isaac Gym: High Performance GPU-Based Physics Simulation For Robot Learning
V . Makoviychuk et al., “Isaac Gym: High Performance GPU- Based Physics Simulation For Robot Learning,”arXiv preprint arXiv:2108.10470, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[26]
Extrinsic dexterity: In-hand manipulation with external forces,
N. Chavan-Dafle et al., “Extrinsic dexterity: In-hand manipulation with external forces,” inIEEE International Conference on Robotics and Automation (ICRA), 2014
work page 2014
-
[27]
Dynamic on-palm manipulation via con- trolled sliding,
W. Yang and M. Posa, “Dynamic on-palm manipulation via con- trolled sliding,” inRobotics: Science and Systems (RSS), 2024
work page 2024
-
[28]
Synthesizing dexterous nonprehen- sile pregrasp for ungraspable objects,
S. Chen, A. Wu, and C. K. Liu, “Synthesizing dexterous nonprehen- sile pregrasp for ungraspable objects,” inACM SIGGRAPH, 2023
work page 2023
-
[29]
One-Shot Transfer of Long-Horizon Extrinsic Manipulation Through Contact Retargeting,
A. Wu, R. Wang, S. Chen, C. Eppner, and C. K. Liu, “One-Shot Transfer of Long-Horizon Extrinsic Manipulation Through Contact Retargeting,”arXiv preprint arXiv:2404.07468, 2024
-
[30]
Learn- ing to Group and Grasp Multiple Objects,
T. Yonemaru, W. Wan, T. Nishimura, and K. Harada, “Learn- ing to Group and Grasp Multiple Objects,”arXiv preprint arXiv:2502.08452, 2025
-
[31]
Factr: Force-attending curriculum training for contact-rich policy learning,
J. J. Liu, Y . Li, K. Shaw, T. Tao, R. Salakhutdinov, and D. Pathak, “Factr: Force-attending curriculum training for contact-rich policy learning,” inRobotics: Science and Systems (RSS), 2025
work page 2025
-
[32]
Deep differentiable grasp planner for high-dof grippers,
M. Liu, Z. Pan, K. Xu, K. Ganguly, and D. Manocha, “Deep differentiable grasp planner for high-dof grippers,” inRobotics: Science and Systems (RSS), 2020
work page 2020
-
[33]
Graspit! a versatile simulator for robotic grasping,
A. T. Miller and P. K. Allen, “Graspit! a versatile simulator for robotic grasping,”IEEE Robotics & Automation Magazine, 2004
work page 2004
-
[34]
Hand-object contact consistency reasoning for human grasps generation,
H. Jiang, S. Liu, J. Wang, and X. Wang, “Hand-object contact consistency reasoning for human grasps generation,” inIEEE/CVF International Conference on Computer Vision (ICCV), 2021
work page 2021
-
[35]
Auto-Encoding Variational Bayes,
D. P. Kingma and M. Welling, “Auto-Encoding Variational Bayes,” inInternational Conference on Learning Representations, 2014
work page 2014
-
[36]
Grasp’d: Differentiable contact-rich grasp synthe- sis for multi-fingered hands,
D. Turpin et al., “Grasp’d: Differentiable contact-rich grasp synthe- sis for multi-fingered hands,” inEuropean Conference on Computer Vision (ECCV), 2022
work page 2022
-
[37]
Fast-grasp’d: Dexterous multi-finger grasp gen- eration through differentiable simulation,
D. Turpin et al., “Fast-grasp’d: Dexterous multi-finger grasp gen- eration through differentiable simulation,” inIEEE International Conference on Robotics and Automation (ICRA), 2023
work page 2023
-
[38]
T. Liu, Z. Liu, Z. Jiao, Y . Zhu, and S.-C. Zhu, “Synthesizing diverse and physically stable grasps with arbitrary hand structures using differentiable force closure estimator,” inIEEE Robotics and Automation Letters (RA-L), 2022
work page 2022
-
[39]
Dexvlg: Dexterous vision-language-grasp model at scale,
J. He et al., “Dexvlg: Dexterous vision-language-grasp model at scale,”arXiv preprint arXiv:2507.02747, 2025
-
[40]
Dex1b: Learning with 1b demonstrations for dexterous manipulation,
J. Ye et al., “Dex1b: Learning with 1b demonstrations for dexterous manipulation,” inRobotics: Science and Systems (RSS), 2025
work page 2025
-
[41]
A Review of Robot Learning for Manipulation: Challenges, Representations, and Algo- rithms,
O. Kroemer, S. Niekum, and G. Konidaris, “A Review of Robot Learning for Manipulation: Challenges, Representations, and Algo- rithms,” inJournal of Machine Learning Research (JMLR), 2021
work page 2021
-
[42]
Learning Fine- Grained Bimanual Manipulation with Low-Cost Hardware,
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn, “Learning Fine- Grained Bimanual Manipulation with Low-Cost Hardware,” in Robotics: Science and Systems (RSS), 2023
work page 2023
-
[43]
Mobile ALOHA: Learning Bimanual Mobile Manipulation with Low-Cost Whole-Body Tele- operation,
Z. Fu, T. Z. Zhao, and C. Finn, “Mobile ALOHA: Learning Bimanual Mobile Manipulation with Low-Cost Whole-Body Tele- operation,” inConference on Robot Learning (CoRL), 2024
work page 2024
-
[44]
In-Hand Object Rotation via Rapid Motor Adaptation,
H. Qi, A. Kumar, R. Calandra, Y . Ma, and J. Malik, “In-Hand Object Rotation via Rapid Motor Adaptation,” inConference on Robot Learning (CoRL), 2022
work page 2022
-
[45]
Lessons from Learning to Spin “Pens
J. Wang et al., “Lessons from Learning to Spin “Pens”’,” in Conference on Robot Learning (CoRL), 2024
work page 2024
-
[46]
Solving Rubik's Cube with a Robot Hand
OpenAI et al., “Solving rubik’s cube with a robot hand,”arXiv preprint arXiv:1910.07113, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[47]
Learning to Singulate Objects in Packed Environments using a Dexterous Hand,
H. Jiang, Y . Wang, H. Zhou, and D. Seita, “Learning to Singulate Objects in Packed Environments using a Dexterous Hand,” in International Symposium on Robotics Research (ISRR), 2024
work page 2024
-
[48]
L. Xu et al., “Dexsingrasp: Learning a unified policy for dexterous object singulation and grasping in cluttered environments,”arXiv preprint arXiv:2504.04516, 2025
-
[49]
Sequential multi-object grasping with one dexterous hand,
S. He et al., “Sequential multi-object grasping with one dexterous hand,” inIEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2025
work page 2025
-
[50]
Veg- etable Peeling: A Case Study in Constrained Dexterous Manipula- tion,
T. Chen, E. Cousineau, N. Kuppuswamy, and P. Agrawal, “Veg- etable Peeling: A Case Study in Constrained Dexterous Manipula- tion,” inIEEE International Conference on Robotics and Automa- tion (ICRA), 2025
work page 2025
-
[51]
Twisting Lids Off with Two Hands,
T. Lin, Z.-H. Yin, H. Qi, P. Abbeel, and J. Malik, “Twisting Lids Off with Two Hands,” inConference on Robot Learning (CoRL), 2024
work page 2024
-
[52]
3d dif- fusion policy: Generalizable visuomotor policy learning via simple 3d representations,
Y . Ze, G. Zhang, K. Zhang, C. Hu, M. Wang, and H. Xu, “3d dif- fusion policy: Generalizable visuomotor policy learning via simple 3d representations,” inRobotics: Science and Systems (RSS), 2024
work page 2024
-
[53]
Crossing the Human-Robot Embodiment Gap with Sim-to-Real RL using One Human Demonstration,
T. G. W. Lum, O. Y . Lee, C. K. Liu, and J. Bohg, “Crossing the Human-Robot Embodiment Gap with Sim-to-Real RL using One Human Demonstration,” inConference on Robot Learning (CoRL), 2025
work page 2025
-
[54]
Task-oriented dexterous hand pose synthesis using differentiable grasp wrench boundary estimator,
J. Chen, Y . Chen, J. Zhang, and H. Wang, “Task-oriented dexterous hand pose synthesis using differentiable grasp wrench boundary estimator,” inIEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2024
work page 2024
-
[55]
Pushing ev- erything everywhere all at once: Probabilistic prehensile pushing,
P. Perugini, J. Lundell, K. Friedl, and D. Kragic, “Pushing ev- erything everywhere all at once: Probabilistic prehensile pushing,” IEEE Robotics and Automation Letters, 2025
work page 2025
-
[56]
T. Tieleman and G. Hinton,Lecture 6.5—rmsprop: Divide the gra- dient by a running average of its recent magnitude, COURSERA: Neural Networks for Machine Learning, 2012
work page 2012
-
[57]
Optimization by simulated annealing,
S. Kirkpatrick, C. D. Gelatt, and M. P. Vecchi, “Optimization by simulated annealing,”Science, vol. 220, no. 4598, 1983
work page 1983
-
[58]
U-Net: Convolutional Networks for Biomedical Image Segmentation,
O. Ronneberger, P. Fischer, and T. Brox, “U-Net: Convolutional Networks for Biomedical Image Segmentation,” inMICCAI, 2015
work page 2015
-
[59]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” inNeural Information Processing Systems, 2020
work page 2020
-
[60]
Sampling-based algorithms for opti- mal motion planning,
S. Karaman and E. Frazzoli, “Sampling-based algorithms for opti- mal motion planning,”International Journal of Robotics Research (IJRR), 2011
work page 2011
-
[61]
Robo-gs: A physics consistent spatial-temporal model for robotic arm with hybrid representation,
H. Lou et al., “Robo-gs: A physics consistent spatial-temporal model for robotic arm with hybrid representation,”arXiv preprint arXiv:2408.14873, 2024
-
[62]
Nerfstudio: A modular framework for neural radiance field development,
M. Tancik et al., “Nerfstudio: A modular framework for neural radiance field development,” inSIGGRAPH, 2023
work page 2023
-
[63]
Structure-from-Motion Re- visited,
J. L. Schönberger and J.-M. Frahm, “Structure-from-Motion Re- visited,” inIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016
work page 2016
-
[64]
Stablenormal: Reducing diffusion variance for stable and sharp normal,
C. Ye et al., “Stablenormal: Reducing diffusion variance for stable and sharp normal,”arXiv preprint arXiv:2406.16864, 2024
-
[65]
2D Gaussian Splatting for Geometrically Accurate Radiance Fields,
B. Huang, Z. Yu, A. Chen, A. Geiger, and S. Gao, “2D Gaussian Splatting for Geometrically Accurate Radiance Fields,” inSIG- GRAPH, ACM, 2024
work page 2024
-
[66]
NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis,
B. Mildenhall, P. P. Srinivasan, M. Tancik, J. T. Barron, R. Ra- mamoorthi, and R. Ng, “NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis,” inEuropean Conference on Computer Vision (ECCV), 2020
work page 2020
-
[67]
Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection
S. Liu et al., “Grounding dino: Marrying dino with grounded pre-training for open-set object detection,”arXiv preprint arXiv:2303.05499, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[68]
SAM 2: Segment Anything in Images and Videos
N. Ravi et al., “Sam 2: Segment anything in images and videos,” arXiv preprint arXiv:2408.00714, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[69]
Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks
T. Ren et al.,Grounded sam: Assembling open-world models for diverse visual tasks, 2024. arXiv:2401.14159 [cs.CV]
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[70]
A. Kirillov et al., “Segment Anything,”arXiv preprint arXiv:2304.02643, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [71]
-
[72]
3D Avg.” refers to the average success rate over all 3D-printed objects, “DO Avg
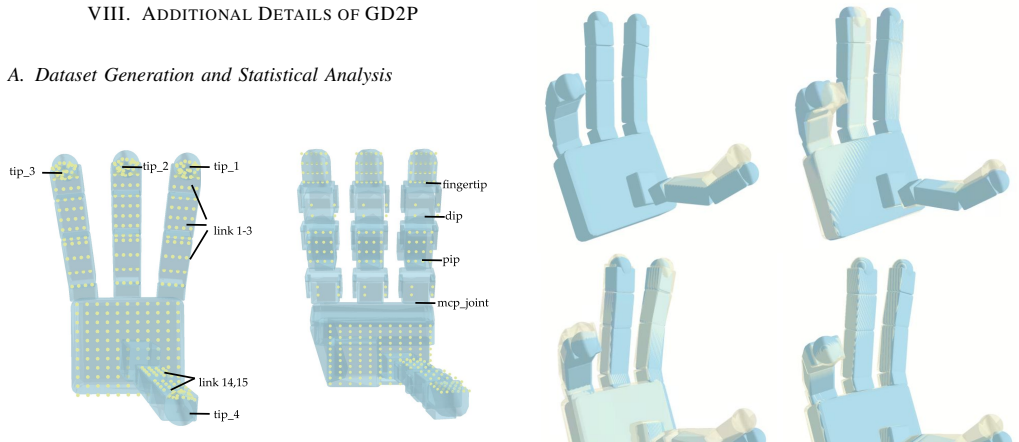
arXiv:2403.14610 [cs.CV]. VIII. ADDITIONALDETAILS OFGD2P A. Dataset Generation and Statistical Analysis Fig. 11: Contact candidates on the Allegro Hand and LEAP Hand. Refer to Table II and Table III for the number of contacts on each link. During dataset generation, we specify the contact candi- dates according to Figure 11 and Table II&III, and we set th...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.