RoboTAG: End-to-end Robot Configuration Estimation via Topological Alignment Graph
Pith reviewed 2026-05-18 00:23 UTC · model grok-4.3
The pith
A topological graph with 2D and 3D branches estimates robot configurations from single images by enforcing cross-branch consistency on closed loops.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
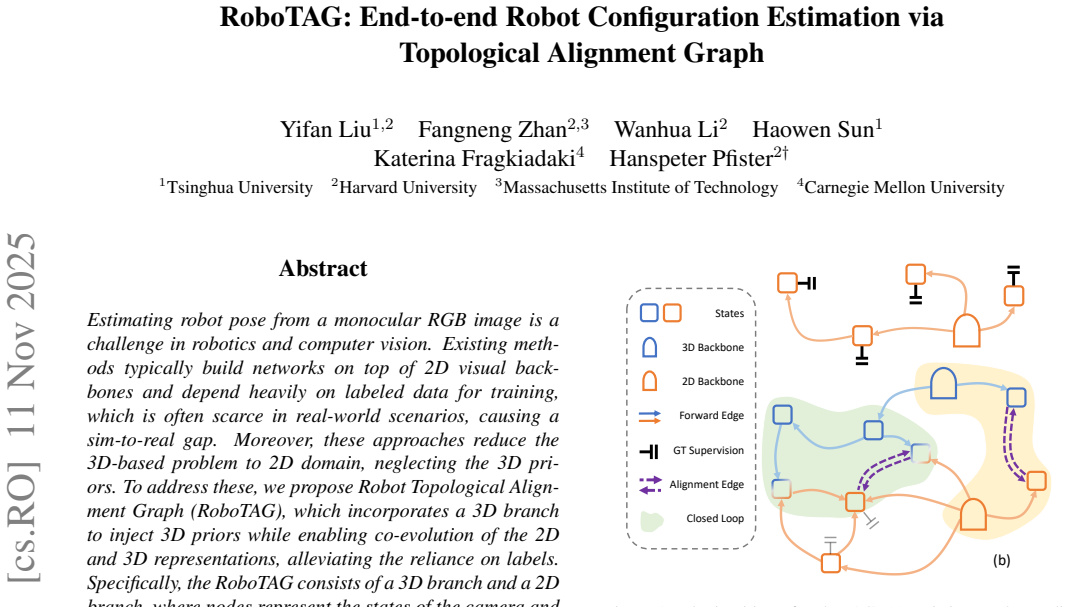
The central discovery is that the RoboTAG architecture, built from a 3D branch that supplies geometric priors and a 2D branch that processes image features, can be coupled by a topological alignment graph whose closed loops supply an internal consistency loss; this loss drives co-evolution of the two representations and thereby reduces dependence on large quantities of annotated training data while still producing accurate end-to-end estimates of robot configuration from a single RGB frame.
What carries the argument
The topological alignment graph, whose nodes encode camera and robot states and whose edges encode either variable dependencies or 2D-3D alignments, with closed loops that enable consistency supervision between the branches.
If this is right
- The same graph construction works across multiple robot morphologies without architecture changes.
- Training can proceed with far fewer labeled real images than current supervised baselines require.
- The 3D branch and 2D branch improve each other through the shared loops rather than being trained in isolation.
- The resulting model narrows the sim-to-real performance gap that appears when networks are trained only on synthetic data.
Where Pith is reading between the lines
- The same loop-based consistency mechanism could be reused for other estimation problems that combine image features with explicit 3D geometry, such as hand tracking or object pose recovery.
- If the graph edges are made differentiable, the method might support online adaptation when a robot encounters a new environment.
- Extending the node set to include temporal states could allow the same framework to handle video sequences without separate recurrent modules.
Load-bearing premise
That the closed loops defined in the graph produce a consistency signal strong enough to inject useful 3D priors into the 2D branch and thereby cut the amount of labeled data required.
What would settle it
On a new robot type and with the same small training set, a standard 2D-only baseline achieves equal or higher pose accuracy than the full RoboTAG model.
Figures



read the original abstract
Estimating robot pose from a monocular RGB image is a challenge in robotics and computer vision. Existing methods typically build networks on top of 2D visual backbones and depend heavily on labeled data for training, which is often scarce in real-world scenarios, causing a sim-to-real gap. Moreover, these approaches reduce the 3D-based problem to 2D domain, neglecting the 3D priors. To address these, we propose Robot Topological Alignment Graph (RoboTAG), which incorporates a 3D branch to inject 3D priors while enabling co-evolution of the 2D and 3D representations, alleviating the reliance on labels. Specifically, the RoboTAG consists of a 3D branch and a 2D branch, where nodes represent the states of the camera and robot system, and edges capture the dependencies between these variables or denote alignments between them. Closed loops are then defined in the graph, on which a consistency supervision across branches can be applied. Experimental results demonstrate that our method is effective across robot types, suggesting new possibilities of alleviating the data bottleneck in robotics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes RoboTAG, an end-to-end framework for estimating robot configuration (pose) from monocular RGB images. It introduces a Topological Alignment Graph with parallel 2D and 3D branches whose nodes represent camera/robot states and edges represent dependencies or alignments; closed loops in the graph are used to impose cross-branch consistency supervision that co-evolves the representations and reduces the need for labeled data. The authors report that the method is effective across robot types.
Significance. If the central claims are substantiated by rigorous experiments, RoboTAG could offer a practical route to label-efficient robot pose estimation by injecting 3D priors and using topological consistency as a form of self-supervision. This would directly address the data bottleneck and sim-to-real gap that currently limit deployment of vision-based robotics methods.
major comments (2)
- [Experiments] Experiments section: the central claim that closed-loop consistency supervision alleviates the labeled-data requirement is not supported by any ablation that varies label fraction or removes the consistency term; without such controls it is impossible to determine whether observed gains arise from the graph structure or from other unstated factors.
- [Method] Method section (graph construction and 3D branch): the manuscript states that the 3D branch injects useful priors and that closed loops yield effective cross-branch signals, yet provides no analysis of how the monocular 3D priors are obtained or their noise characteristics; if these priors are inaccurate the consistency loss could become uninformative or harmful, undermining the label-efficiency argument.
minor comments (2)
- [Abstract] Abstract: the statement that 'experimental results demonstrate that our method is effective' is unsupported by any quantitative metrics, baseline comparisons, or error statistics.
- [Method] Notation: the definitions of nodes, edges, and closed loops would benefit from explicit mathematical formulation (e.g., an equation defining the consistency loss on a loop) to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important areas for strengthening the experimental validation of our label-efficiency claims and for providing more detailed analysis of the 3D priors. We address each major comment below and have revised the manuscript to incorporate additional experiments and analysis.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the central claim that closed-loop consistency supervision alleviates the labeled-data requirement is not supported by any ablation that varies label fraction or removes the consistency term; without such controls it is impossible to determine whether observed gains arise from the graph structure or from other unstated factors.
Authors: We agree that the original experiments lacked direct ablations on label fraction and removal of the consistency term, which are necessary to isolate the contribution of the closed-loop supervision to label efficiency. In the revised manuscript we have added a new set of controlled experiments (Section 4.3) that train RoboTAG and baseline variants using 10%, 25%, 50%, and 100% of the available labeled data, both with and without the consistency supervision. The results show that the performance advantage of the full model increases as the label fraction decreases, providing direct evidence that the consistency term is responsible for the observed gains in low-label regimes rather than other factors. revision: yes
-
Referee: [Method] Method section (graph construction and 3D branch): the manuscript states that the 3D branch injects useful priors and that closed loops yield effective cross-branch signals, yet provides no analysis of how the monocular 3D priors are obtained or their noise characteristics; if these priors are inaccurate the consistency loss could become uninformative or harmful, undermining the label-efficiency argument.
Authors: We thank the referee for this observation. The 3D priors are generated by combining a pre-trained monocular depth network with known robot forward kinematics to lift 2D detections into 3D. While the original manuscript described the overall graph construction, it did not include a dedicated analysis of prior accuracy or noise sensitivity. In the revised Method section we have added a detailed description of the prior-generation pipeline together with quantitative measurements of prior error on both synthetic and real-world data. We also include a sensitivity study that injects controlled noise into the 3D priors and shows that the consistency supervision remains beneficial and does not degrade performance even under moderate noise levels, thereby supporting the robustness of the label-efficiency argument. revision: yes
Circularity Check
No significant circularity; method defines explicit supervision structure without reducing claims to inputs by construction.
full rationale
The paper proposes RoboTAG as a graph-based architecture with 2D/3D branches, nodes for states, edges for alignments, and explicitly defined closed loops for cross-branch consistency supervision. This is presented as a novel design to inject 3D priors and reduce label dependence, with effectiveness shown via experiments across robot types. No equations or results are shown to reduce by construction to fitted parameters or self-defined quantities (e.g., no 'prediction' that is the fit itself). No load-bearing self-citations, uniqueness theorems from prior author work, or ansatzes smuggled via citation appear in the provided text. The derivation is a standard proposal of architecture and loss terms, self-contained against external benchmarks rather than tautological.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption A separate 3D branch can inject useful 3D priors into a primarily 2D visual pipeline
- ad hoc to paper Closed loops in the alignment graph produce meaningful cross-branch consistency signals usable as supervision
invented entities (1)
-
Topological Alignment Graph (RoboTAG)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
nodes represent the states of the camera and robot system, and edges capture the dependencies... Closed loops are then defined in the graph, on which a consistency supervision across branches can be applied.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Real-time holistic robot pose es- timation with unknown states
Shikun Ban, Juling Fan, Xiaoxuan Ma, Wentao Zhu, Yu Qiao, and Yizhou Wang. Real-time holistic robot pose es- timation with unknown states. InEuropean Conference on Computer Vision, pages 1–17, Malmo, Sweden, 2024. 1, 3, 4, 5, 6, 7
work page 2024
-
[2]
Stable video diffusion: Scaling latent video diffusion models to large datasets, 2023
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, Varun Jampani, and Robin Rombach. Stable video diffusion: Scaling latent video diffusion models to large datasets, 2023. 1
work page 2023
-
[3]
End-to-end learnable geometric vision by backprop- agating PnP optimization
Bo Chen, Alvaro Parra, Jiewei Cao, Nan Li, and Tat-Jun Chin. End-to-end learnable geometric vision by backprop- agating PnP optimization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8100–8109, 2020. 2, 6
work page 2020
-
[4]
Learning human-to-robot handovers from point clouds
Sammy Christen, Wei Yang, Claudia P ´erez-D’Arpino, Ot- mar Hilliges, Dieter Fox, and Yu-Wei Chao. Learning human-to-robot handovers from point clouds. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9654–9664, 2023. 1
work page 2023
-
[5]
Guoguang Du, Kai Wang, Shiguo Lian, and Kaiyong Zhao. Vision-based robotic grasping from object localization, ob- ject pose estimation to grasp estimation for parallel grippers: a review.Artificial Intelligence Review, 54(3):1677–1734,
-
[6]
ARTag, a fiducial marker system using digi- tal techniques
Mark Fiala. ARTag, a fiducial marker system using digi- tal techniques. InProceedings of the IEEE Computer Soci- ety Conference on Computer Vision and Pattern Recognition, pages 590–596, San Diego, CA, 2005. 2
work page 2005
-
[7]
Sergio Garrido-Jurado, Rafael Mu ˜noz-Salinas, Fran- cisco Jos ´e Madrid-Cuevas, and Manuel Jes ´us Mar ´ın- Jim´enez. Automatic generation and detection of highly reliable fiducial markers under occlusion.Pattern Recogni- tion, 47(6):2280–2292, 2014. 2
work page 2014
-
[8]
Raktim Gautam Goswami, Prashanth Krishnamurthy, Yann LeCun, and Farshad Khorrami. Robopepp: Vision-based robot pose and joint angle estimation through embedding predictive pre-training. InProceedings of the Computer Vi- sion and Pattern Recognition Conference, pages 6930–6939,
-
[9]
Xujun Han, Shaochen Wang, Xiucai Huang, and Zhen Kan. PoseFusion: Multi-scale keypoint correspondence for monocular camera-to-robot pose estimation in robotic ma- nipulation. InProceedings of the IEEE International Con- ference on Robotics and Automation, pages 795–801, Yoko- hama, Japan, 2024. 2
work page 2024
-
[10]
Deep residual learning for image recognition, 2015
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition, 2015. 7
work page 2015
-
[11]
Masked autoencoders are scalable vision learners, 2021
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Doll´ar, and Ross Girshick. Masked autoencoders are scalable vision learners, 2021. 2
work page 2021
-
[12]
Jonathan Ho, Tim Salimans, Alexey Gritsenko, William Chan, Mohammad Norouzi, and David J Fleet. Video diffu- sion models. InAdvances in Neural Information Processing Systems, pages 8633–8646. Curran Associates, Inc., 2022. 1
work page 2022
-
[13]
Robust robot-camera calibra- tion
Jarmo Ilonen and Ville Kyrki. Robust robot-camera calibra- tion. InProceedings of the International Conference on Ad- vanced Robotics, pages 67–74. IEEE, 2011. 2
work page 2011
-
[14]
Single-view robot pose and joint angle estimation via render & compare
Yann Labb ´e, Justin Carpentier, Mathieu Aubry, and Josef Sivic. Single-view robot pose and joint angle estimation via render & compare. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 1654–1663, 2021. 1, 2, 5, 6
work page 2021
-
[15]
Camera-to-robot pose estimation from a single im- age
Timothy E Lee, Jonathan Tremblay, Thang To, Jia Cheng, Terry Mosier, Oliver Kroemer, Dieter Fox, and Stan Birch- field. Camera-to-robot pose estimation from a single im- age. InProceedings of the IEEE International Conference on Robotics and Automation, pages 9426–9432, Paris, France,
-
[16]
Shiqi Li, Chi Xu, and Ming Xie. A robust o (n) solution to the perspective-n-point problem.IEEE transactions on pattern analysis and machine intelligence, 34(7):1444–1450, 2012. 2
work page 2012
-
[17]
Self-supervised monocular multi-robot relative localization with efficient deep neural networks
Shushuai Li, Christophe De Wagter, and Guido CHE De Croon. Self-supervised monocular multi-robot relative localization with efficient deep neural networks. InProceed- ings of the International Conference on Robotics and Au- tomation, pages 9689–9695. IEEE, 2022. 1
work page 2022
-
[18]
Make-your-3d: Fast and consistent subject- driven 3d content generation, 2024
Fangfu Liu, Hanyang Wang, Weiliang Chen, Haowen Sun, and Yueqi Duan. Make-your-3d: Fast and consistent subject- driven 3d content generation, 2024. 1
work page 2024
-
[19]
Differentiable robot rendering.arXiv preprint arXiv:2410.13851, 2024
Ruoshi Liu, Alper Canberk, Shuran Song, and Carl V on- drick. Differentiable robot rendering.arXiv preprint arXiv:2410.13851, 2024. 1
-
[20]
Jingpei Lu, Florian Richter, and Michael C. Yip. Markerless camera-to-robot pose estimation via self-supervised sim-to- real transfer. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21296– 21306, Vancouver, Canada, 2023. 2
work page 2023
-
[21]
David Marr.Vision: A computational investigation into the human representation and processing of visual information. MIT press, 2010. 1
work page 2010
-
[22]
AprilTag: A robust and flexible visual fiducial system
Edwin Olson. AprilTag: A robust and flexible visual fiducial system. InProceedings of the IEEE International Confer- ence on Robotics and Automation, pages 3400–3407, Shang- hai, China, 2011. 2
work page 2011
-
[23]
Andreas Papadimitriou, Sina Sharif Mansouri, and George Nikolakopoulos. Range-aided ego-centric collaborative pose estimation for multiple robots.Expert Systems with Applica- tions, 202:117052, 2022. 1
work page 2022
-
[24]
Frank C Park and Bryan J Martin. Robot sensor calibration: solving AX= XB on the euclidean group.IEEE Transactions on Robotics and Automation, 10(5):717–721, 1994. 2
work page 1994
-
[25]
Yara Rizk, Mariette Awad, and Edward W Tunstel. Coop- erative heterogeneous multi-robot systems: A survey.ACM Computing Surveys (CSUR), 52(2):1–31, 2019. 1
work page 2019
-
[26]
Ashutosh Saxena, Sung H. Chung, and Andrew Y . Ng. Learning depth from single monocular images. InProceed- ings of the 19th International Conference on Neural Infor- mation Processing Systems, page 1161–1168, Cambridge, MA, USA, 2005. MIT Press. 4
work page 2005
-
[27]
Pose estimation and adaptive robot be- haviour for human-robot interaction
Mikael Svenstrup, Soren Tranberg, Hans Jorgen Andersen, and Thomas Bak. Pose estimation and adaptive robot be- haviour for human-robot interaction. InProceedings of the IEEE International Conference on Robotics and Automation, pages 3571–3576. IEEE, 2009. 1
work page 2009
-
[28]
Yang Tian, Jiyao Zhang, Zekai Yin, and Hao Dong. Robot structure prior guided temporal attention for camera-to-robot pose estimation from image sequence. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8917–8926, Vancouver, Canada, 2023. 2
work page 2023
-
[29]
Robokeygen: robot pose and joint angles estimation via diffusion-based 3d key- point generation
Yang Tian, Jiyao Zhang, Guowei Huang, Bin Wang, Ping Wang, Jiangmiao Pang, and Hao Dong. Robokeygen: robot pose and joint angles estimation via diffusion-based 3d key- point generation. InProceedings of the IEEE International Conference on Robotics and Automation, pages 5375–5381, Yokohama, Japan, 2024. 2, 6
work page 2024
-
[30]
Multi-view human pose estimation in human-robot interac- tion
Chengjun Xu, Xinyi Yu, Zhengan Wang, and Linlin Ou. Multi-view human pose estimation in human-robot interac- tion. InProceedings of the Annual Conference of the IEEE Industrial Electronics Society, pages 4769–4775. IEEE,
-
[31]
Dekun Yang and John Illingworth. Calibrating a robot cam- era. InProceedings of the British Machine Vision Confer- ence, pages 1–10, York, UK, 1994. 2
work page 1994
-
[32]
Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiao- gang Xu, Jiashi Feng, and Hengshuang Zhao. Depth any- thing v2.arXiv:2406.09414, 2024. 6, 7
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
Cogvideox: Text-to-video diffusion models with an expert transformer, 2025
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiao- han Zhang, Guanyu Feng, Da Yin, Yuxuan Zhang, Weihan Wang, Yean Cheng, Bin Xu, Xiaotao Gu, Yuxiao Dong, and Jie Tang. Cogvideox: Text-to-video diffusion models with an expert transformer, 2025. 1
work page 2025
-
[34]
Yipeng Zhang, Yifan Liu, Zonghao Guo, Yidan Zhang, Xuesong Yang, Chi Chen, Jun Song, Bo Zheng, Yuan Yao, Zhiyuan Liu, et al. Llava-uhd v2: an mllm integrating high- resolution feature pyramid via hierarchical window trans- former.arXiv e-prints, pages arXiv–2412, 2024. 7
work page 2024
-
[35]
Tesseract: Learning 4d embodied world models
Haoyu Zhen, Qiao Sun, Hongxin Zhang, Junyan Li, Siyuan Zhou, Yilun Du, and Chuang Gan. Tesseract: Learning 4d embodied world models. 2025. 1
work page 2025
-
[36]
Xiaopin Zhong, Wenxuan Zhu, Weixiang Liu, Jianye Yi, Chengxiang Liu, and Zongze Wu. G-SAM: A robust one- shot keypoint detection framework for PnP based robot pose estimation.Journal of Intelligent & Robotic Systems, 109(2): 28, 2023. 2
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.