Learning to Plan, Planning to Learn: Adaptive Hierarchical RL-MPC for Sample-Efficient Decision Making
Pith reviewed 2026-05-16 21:07 UTC · model grok-4.3
The pith
A hierarchical fusion of reinforcement learning and model predictive control adaptively allocates samples to regions of high value uncertainty.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
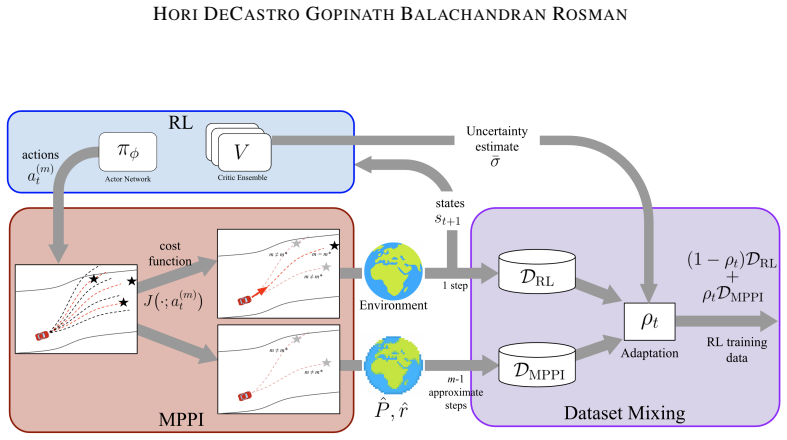
The formulation couples the two planning paradigms by using reinforcement learning actions to inform the MPPI sampler and adaptively aggregating MPPI samples to inform value estimation. The resulting process increases MPPI exploration where value estimates are uncertain, which improves training robustness and the quality of the learned policies. This yields a planner that handles complex problems and adapts across applications, with measured improvements in data efficiency, rewards, task success, and convergence speed.
What carries the argument
The adaptive aggregation of MPPI samples guided by uncertainty in the reinforcement learning value estimates, which dynamically directs additional planning effort to improve policy updates.
If this is right
- Higher task success rates, reaching up to 72 percent improvement over existing methods in the evaluated domains.
- Accelerated policy convergence by a factor of 2.1 compared with non-adaptive sampling.
- Improved data efficiency in sample-intensive planning problems.
- A planning approach that extends readily to other continuous control tasks without domain-specific retuning.
Where Pith is reading between the lines
- The same uncertainty-driven allocation could be applied to other model-based reinforcement learning hybrids to reduce wasted computation on well-estimated regions.
- Real-time systems might gain responsiveness by capping total samples while still prioritizing uncertain areas during online execution.
- The coupling might generalize to settings where the model used for MPPI sampling is itself learned from data.
Load-bearing premise
Adaptively increasing MPPI samples where value estimates are uncertain will improve training robustness and policy quality without introducing bias or instability in the value function.
What would settle it
An experiment in one of the tested domains (race driving, modified Acrobot, or Lunar Lander) where the adaptive sampler produces equal or lower success rates and no faster convergence than a fixed-sample non-adaptive baseline.
Figures







read the original abstract
We propose a new approach for solving planning problems with a hierarchical structure, fusing reinforcement learning and MPC planning. Our formulation tightly and elegantly couples the two planning paradigms. It leverages reinforcement learning actions to inform the MPPI sampler, and adaptively aggregates MPPI samples to inform the value estimation. The resulting adaptive process leverages further MPPI exploration where value estimates are uncertain, and improves training robustness and the overall resulting policies. This results in a robust planning approach that can handle complex planning problems and easily adapts to different applications, as demonstrated over several domains, including race driving, modified Acrobot, and Lunar Lander with added obstacles. Our results in these domains show better data efficiency and overall performance in terms of both rewards and task success, with up to a 72% increase in success rate compared to existing approaches, as well as accelerated convergence (x2.1) compared to non-adaptive sampling.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a hierarchical RL-MPC framework that couples reinforcement learning actions to guide an MPPI sampler and adaptively aggregates MPPI samples to refine value estimates. The adaptive process allocates more samples where value estimates are uncertain, with the goal of improving training robustness and policy quality. Empirical results are reported across race driving, modified Acrobot, and Lunar Lander with obstacles, claiming up to 72% higher success rates and 2.1x faster convergence relative to non-adaptive baselines.
Significance. If the adaptive aggregation step can be shown to produce unbiased value targets, the method would provide a concrete mechanism for interleaving model-free and model-based planning that improves sample efficiency without requiring hand-crafted domain adaptations. The reported gains in success rate and convergence speed, if reproducible with ablations and statistical controls, would strengthen the case for hybrid planners in continuous control tasks.
major comments (2)
- [Method section (adaptive aggregation paragraph)] The description of adaptive MPPI aggregation for value estimation (visible in the method outline) does not include a sampling-density correction. When the number of MPPI samples is increased conditionally on value uncertainty, the resulting Monte-Carlo targets overweight high-variance regions unless the estimator is explicitly re-weighted by the inverse of the local sampling density; no such term or derivation appears.
- [Experimental results (domains and metrics)] The central performance claims (72% success-rate increase and 2.1x convergence) rest on unspecified implementation choices and post-hoc domain adaptations. No ablation isolating the adaptive component versus fixed-sample MPPI, no error bars, and no statistical significance tests are referenced, leaving the attribution of gains to the proposed coupling unverified.
minor comments (1)
- Notation for the uncertainty signal used to modulate MPPI sample count should be defined explicitly (e.g., as variance of the value estimator or as a separate network output) to allow reproduction.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will revise the paper to incorporate the suggested improvements for clarity and rigor.
read point-by-point responses
-
Referee: [Method section (adaptive aggregation paragraph)] The description of adaptive MPPI aggregation for value estimation (visible in the method outline) does not include a sampling-density correction. When the number of MPPI samples is increased conditionally on value uncertainty, the resulting Monte-Carlo targets overweight high-variance regions unless the estimator is explicitly re-weighted by the inverse of the local sampling density; no such term or derivation appears.
Authors: We agree that the current description is incomplete on this point. To produce unbiased Monte-Carlo value targets under adaptive sampling, an inverse-density re-weighting term is required. In the revised manuscript we will add an explicit derivation of the sampling-density correction and incorporate the corresponding re-weighting factor into the adaptive aggregation formula. revision: yes
-
Referee: [Experimental results (domains and metrics)] The central performance claims (72% success-rate increase and 2.1x convergence) rest on unspecified implementation choices and post-hoc domain adaptations. No ablation isolating the adaptive component versus fixed-sample MPPI, no error bars, and no statistical significance tests are referenced, leaving the attribution of gains to the proposed coupling unverified.
Authors: We acknowledge that the current experimental section lacks the requested controls. The revised version will include (i) an ablation isolating the adaptive aggregation component against fixed-sample MPPI, (ii) error bars from multiple independent runs, and (iii) statistical significance tests on the reported success-rate and convergence improvements. Expanded implementation details will also be provided to clarify any domain-specific choices. revision: yes
Circularity Check
No significant circularity in the adaptive RL-MPC coupling
full rationale
The paper proposes a hierarchical fusion of RL actions guiding MPPI sampling and adaptive MPPI aggregation informing value estimates. All performance claims (72% success-rate lift, 2.1x convergence) are presented strictly as empirical outcomes from experiments on race driving, Acrobot, and Lunar Lander. No equations, fitted parameters, or self-citations are shown that reduce the central claims to tautological inputs; the method description remains an independent algorithmic construction validated externally.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
M. Bhardwaj, Sanjiban Choudhury, and Byron Boots. Blending MPC & value function approximation for efficient reinforcement learning, 2020a. Mohak Bhardwaj, Ankur Handa, Dieter Fox, and Byron Boots. Information theoretic model predictive q- learning. InProceedings of the 2nd Conference on Learning for Dynamics and Control, volume 120 of Proceedings of Machi...
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
UCB Exploration via Q-Ensembles
Richard Y Chen, Szymon Sidor, Pieter Abbeel, and John Schulman. Ucb exploration via q-ensembles.arXiv preprint arXiv:1706.01502,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Td-mpc2: Scalable, robust world models for continuous control
Nicklas Hansen, Hao Su, and Xiaolong Wang. Td-mpc2: Scalable, robust world models for continuous control. InInternational Conference on Learning Representations (ICLR) 2024, Spotlight,
work page 2024
-
[4]
TD-MPC2: Scalable, Robust World Models for Continuous Control
Preprint arXiv:2310.16828. Zhang-Wei Hong, Joni Pajarinen, and Jan Peters. Model-based lookahead reinforcement learning.arXiv preprint arXiv:1908.06012,
work page internal anchor Pith review Pith/arXiv arXiv 1908
-
[5]
Prakrut Kotecha, Ganga Nair B, and Shishir Kolathaya. Real-time gait adaptation for quadrupeds using model predictive control and reinforcement learning.arXiv preprint arXiv:2510.20706,
-
[6]
Yankai Li and Mo Chen. Unifying model predictive path integral control, reinforcement learning, and diffu- sion models for optimal control and planning.arXiv preprint arXiv:2502.20476,
-
[7]
Isaac Gym: High Performance GPU-Based Physics Simulation For Robot Learning
11 HORIDECASTROGOPINATHBALACHANDRANROSMAN Viktor Makoviychuk, Lukasz Wawrzyniak, Yunrong Guo, Michelle Lu, Kier Storey, Miles Macklin, David Hoeller, Nikita Rudin, Arthur Allshire, Ankur Handa, et al. Isaac Gym: High performance GPU-based physics simulation for robot learning.arXiv preprint arXiv:2108.10470,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Moerland, Joost Broekens, Aske Plaat, and Catholijn M
ISSN 1935-8237. doi: 10.1561/2200000086. Vedant Mundheda, Zhouchonghao Wu, and Jeff Schneider. Teacher-guided off-road autonomous driving. In ML4AD, Philadelphia, PA, USA,
-
[9]
Khang Nguyen, Khai Nguyen, An T Le, Jan Peters, Manfred Huber, Ngo Anh Vien, and Minh Nhat Vu. Td- grpc: Temporal difference learning with group relative policy constraint for humanoid locomotion.arXiv preprint arXiv:2505.13549,
-
[10]
Actor-critic model predictive control: Differentiable optimization meets reinforcement learn- ing
Angel Romero, Elie Aljalbout, Yunlong Song, and Davide Scaramuzza. Actor-critic model predictive control: Differentiable optimization meets reinforcement learning.arXiv preprint arxiv:2306.09852, 2023a. URL https://arxiv.org/abs/2306.09852. Angel Romero, Yunlong Song, and D. Scaramuzza. Actor-critic model predictive control, 2023b. Andrey Rudenko, Luigi P...
-
[11]
High-Dimensional Continuous Control Using Generalized Advantage Estimation
John Schulman, Philipp Moritz, Sergey Levine, Michael Jordan, and Pieter Abbeel. High-dimensional con- tinuous control using generalized advantage estimation.arXiv preprint arXiv:1506.02438,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm
David Silver, Thomas Hubert, Julian Schrittwieser, Ioannis Antonoglou, Matthew Lai, Arthur Guez, Marc Lanctot, Laurent Sifre, Dharshan Kumaran, Thore Graepel, et al. Mastering chess and shogi by self-play with a general reinforcement learning algorithm.arXiv preprint arXiv:1712.01815,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Yubin Wang, Zengqi Peng, Yusen Xie, Yulin Li, Hakim Ghazzai, and Jun Ma
doi: 10.1109/TNNLS.2022.3207346. Yubin Wang, Zengqi Peng, Yusen Xie, Yulin Li, Hakim Ghazzai, and Jun Ma. Learning the references of on- line model predictive control for urban self-driving.CoRR, abs/2308.15808,
-
[14]
Yuhang Wang, Hanwei Guo, Sizhe Wang, Long Qian, and Xuguang Lan
Also arXiv:2308.15808. Yuhang Wang, Hanwei Guo, Sizhe Wang, Long Qian, and Xuguang Lan. Bootstrapped model predictive control,
-
[15]
´Alvaro Serra-Gomez, Daniel Jarne Ornia, Dhruva Tirumala, and Thomas Moerland. A kl-regularization framework for learning to plan with adaptive priors.arXiv preprint, arXiv:2510.04280,
work page internal anchor Pith review arXiv
-
[16]
Reward. • Passing reward: increased with the vehicle’s relative speed to a nearbyOtherVehiclewhen overtaking (i.e., larger forward relative velocity yields larger reward). • Progress reward: proportional to the forward arc-length progress along the track centerline. • Boundary penalty: decreased according to the magnitude of the boundary deviation coeffi-...
work page 2017
-
[17]
RL term.Three common forms are used for the RL term
The MPPI running cost is decomposed as Ji = t+H−1X τ=t wRL JRL(ˆxi τ , ui τ;a t) +w D Jdanger(ˆxi τ) +J other(ˆxi τ , ui τ) ,(27) wherew RL, wD ∈R ≥0 are fixed weights. RL term.Three common forms are used for the RL term. (i) is used for the results in Section 5, and (ii), (iii) are used for the results in Section D. (i) Target-tracking form: Jtrack RL (ˆ...
work page 2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.