Recognition: 3 theorem links
· Lean TheoremAR-VLA: True Autoregressive Action Expert for Vision-Language-Action Models
Pith reviewed 2026-05-15 12:46 UTC · model grok-4.3
The pith
An autoregressive action expert generates continuous causal action sequences in vision-language-action models by maintaining long-lived memory and re-anchoring for perception delays.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce a true autoregressive Action Expert that generates actions as a continuous causal sequence while conditioning on refreshable vision-language prefixes. In contrast to reactive models that reset context with each new observation, the expert maintains its own history through a long-lived memory and is inherently context-aware. A re-anchoring mechanism mathematically accounts for perception staleness to synchronize asynchronous hybrid modalities. This design enables efficient independent pretraining of kinematic syntax and modular integration with perception backbones, naturally ensuring spatio-temporally consistent action generation across frames.
What carries the argument
The autoregressive Action Expert, which generates actions as a continuous causal sequence conditioned on refreshable vision-language prefixes and maintains history via long-lived memory, synchronized by a re-anchoring mechanism that compensates for perception staleness.
If this is right
- The action expert can be pretrained independently on kinematic data before modular integration with any perception backbone.
- Action trajectories become inherently smoother and more spatio-temporally consistent because context is preserved across frames rather than reset.
- The same expert architecture works for both specialist policies and generalist VLAs without task-specific redesign of the action head.
- Re-anchoring during both training and inference allows the model to handle asynchronous vision-language and control rates without explicit synchronization modules.
Where Pith is reading between the lines
- Longer-horizon tasks may become feasible because the causal memory structure avoids the quadratic cost of ever-growing context windows in perception models.
- The separation of action syntax from perception semantics could support transfer of the pretrained expert across robot embodiments with minimal fine-tuning.
- In real-world deployment the re-anchoring step might be extended to include uncertainty estimates from the perception model to further reduce error accumulation.
Load-bearing premise
The re-anchoring mechanism can reliably compensate for perception staleness across varying control frequencies and dynamic scenes without introducing cumulative errors or requiring extensive per-task tuning.
What would settle it
Measure whether action smoothness and task success rates degrade when control frequency increases substantially beyond training conditions or when scenes change rapidly enough to make perception prefixes stale for multiple steps.
Figures





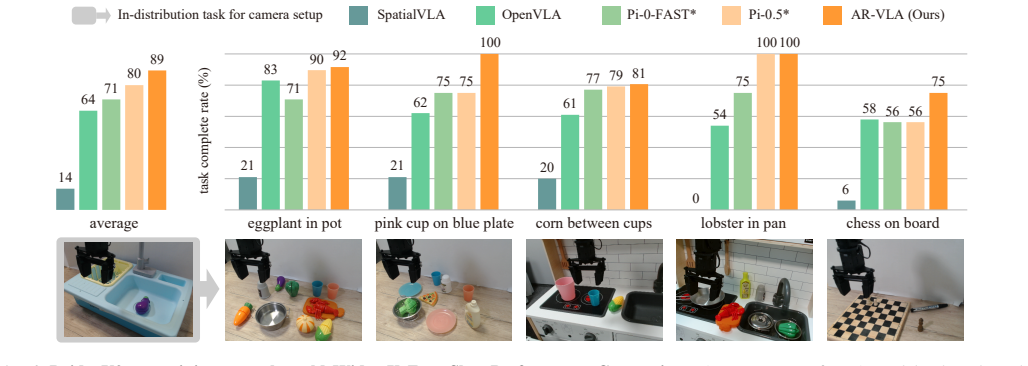










read the original abstract
We propose a standalone autoregressive (AR) Action Expert that generates actions as a continuous causal sequence while conditioning on refreshable vision-language prefixes. In contrast to existing Vision-Language-Action (VLA) models and diffusion policies that reset temporal context with each new observation and predict actions reactively, our Action Expert maintains its own history through a long-lived memory and is inherently context-aware. This structure addresses the frequency mismatch between fast control and slow reasoning, enabling efficient independent pretraining of kinematic syntax and modular integration with heavy perception backbones, naturally ensuring spatio-temporally consistent action generation across frames. To synchronize these asynchronous hybrid V-L-A modalities, we utilize a re-anchoring mechanism that mathematically accounts for perception staleness during both training and inference. Experiments on simulated and real-robot manipulation tasks demonstrate that the proposed method can effectively replace traditional chunk-based action heads for both specialist and generalist policies. AR-VLA exhibits superior history awareness and substantially smoother action trajectories while maintaining or exceeding the task success rates of state-of-the-art reactive VLAs. Overall, our work introduces a scalable, context-aware action generation schema that provides a robust structural foundation for training effective robotic policies. Code and Videos available at https://arvla.insait.ai
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AR-VLA, a Vision-Language-Action architecture centered on a standalone autoregressive Action Expert that produces actions as a continuous causal sequence conditioned on periodically refreshed vision-language prefixes. Unlike chunk-based or reactive VLA baselines, the expert maintains a long-lived internal memory for inherent temporal context, uses a re-anchoring step to compensate for perception staleness, and is claimed to resolve control-reasoning frequency mismatch while enabling modular pretraining and smoother trajectories at comparable success rates on simulated and real-robot manipulation tasks.
Significance. If the empirical claims hold after the requested clarifications, the work would supply a structurally cleaner alternative to chunked action heads in VLA models, with potential benefits for independent action pretraining and long-horizon consistency in hybrid perception-control loops.
major comments (3)
- [§3.2] §3.2 (Re-anchoring mechanism): the description remains qualitative ('mathematically accounts for perception staleness') with no explicit state-update equations, error-propagation bounds, or analysis of drift under 5–10× control-to-perception rate ratios; this is load-bearing for the central claim that AR inherently outperforms long-context chunking.
- [§4] §4 (Experiments): the abstract and results claim 'superior history awareness and substantially smoother trajectories' yet provide neither quantitative metrics (e.g., jerk, trajectory smoothness norms) nor statistical tests comparing against sufficiently long-context chunk baselines; the reported success-rate parity is therefore difficult to interpret.
- [§4.2] §4.2 (Ablations): no ablation isolating the contribution of the long-lived memory versus the re-anchoring adjustment is presented, leaving open whether the observed smoothness arises from the autoregressive structure itself or from the additional synchronization step.
minor comments (2)
- [§3.1] Notation for the action sequence length and memory horizon is introduced without a clear table or diagram relating them to control frequency.
- [Figure 3] Figure 3 (trajectory visualizations) would benefit from overlaid velocity or acceleration plots to substantiate the 'smoother' claim beyond visual inspection.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback on our manuscript. We have carefully considered each major comment and provide point-by-point responses below. All requested clarifications and additions will be incorporated in the revised version to strengthen the presentation of the re-anchoring mechanism, experimental metrics, and ablations.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Re-anchoring mechanism): the description remains qualitative ('mathematically accounts for perception staleness') with no explicit state-update equations, error-propagation bounds, or analysis of drift under 5–10× control-to-perception rate ratios; this is load-bearing for the central claim that AR inherently outperforms long-context chunking.
Authors: We agree that the re-anchoring description would benefit from greater mathematical detail. In the revised manuscript we will add the explicit state-update equations that define how the Action Expert's internal hidden state is adjusted upon receipt of each refreshed vision-language prefix. We will also derive and report error-propagation bounds together with an empirical analysis of state drift for control-to-perception rate ratios between 5× and 10×, using both simulated rollouts and real-robot data. These additions will directly support the claim that the autoregressive structure with re-anchoring provides advantages over long-context chunking. revision: yes
-
Referee: [§4] §4 (Experiments): the abstract and results claim 'superior history awareness and substantially smoother trajectories' yet provide neither quantitative metrics (e.g., jerk, trajectory smoothness norms) nor statistical tests comparing against sufficiently long-context chunk baselines; the reported success-rate parity is therefore difficult to interpret.
Authors: We acknowledge that quantitative smoothness metrics and rigorous statistical comparisons are needed. In the revision we will report mean jerk, integrated squared jerk, and trajectory curvature norms for all methods. We will also extend the chunk-based baselines to context lengths that match the effective history maintained by the AR expert and include statistical significance tests (paired t-tests across 5 random seeds) on both success rates and smoothness metrics. These changes will allow readers to interpret the smoothness and history-awareness claims beyond success-rate parity. revision: yes
-
Referee: [§4.2] §4.2 (Ablations): no ablation isolating the contribution of the long-lived memory versus the re-anchoring adjustment is presented, leaving open whether the observed smoothness arises from the autoregressive structure itself or from the additional synchronization step.
Authors: We thank the referee for this suggestion. We will add a dedicated ablation study that (i) removes the long-lived memory (resetting the expert state at each prefix refresh) and (ii) disables the re-anchoring adjustment while keeping the autoregressive structure. Results will be reported on both simulated and real-robot tasks, showing the individual and joint contributions of each component to trajectory smoothness and task success. This will clarify whether the observed benefits derive primarily from the autoregressive formulation or from the synchronization mechanism. revision: yes
Circularity Check
No circularity: AR-VLA proposal is a structural architecture change grounded in standard autoregressive modeling
full rationale
The paper introduces a standalone autoregressive Action Expert with long-lived memory and a re-anchoring mechanism to address frequency mismatch between perception and control. This is framed as an architectural alternative to chunk-based reactive heads, with claims supported by experimental results on simulated and real-robot tasks rather than any reduction of outputs to fitted parameters or self-referential definitions. No load-bearing self-citations, uniqueness theorems, or ansatzes imported from prior author work are invoked in the provided text; the re-anchoring is described at a high level as mathematically compensating for staleness without equations that collapse back to the input assumptions by construction. The derivation chain remains self-contained against external benchmarks of autoregressive sequence modeling.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Autoregressive sequence models can capture kinematic syntax sufficiently well for independent pretraining of action generation
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We define the AR Actor as a sequence model where one of the prediction dependencies is the continuous kinematic history... Par(τ) = ∏ P(a_t | Φ(v_i,l), a_<t, s_<t)
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_injective unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Dynamic Temporal Re-anchoring (DTR)... assigns fixed index n corresponding to the timestep when the image was captured... Score(q_m, k_VL_n) = q^T R(m-n) k_VL
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Phase 1: Action-Only Pretraining... L_Phase1 = ∑ L(x_t | x_<t)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
RoboMemArena: A Comprehensive and Challenging Robotic Memory Benchmark
RoboMemArena is a new large-scale robotic memory benchmark with real-world tasks, and PrediMem is a dual VLA system that outperforms baselines by managing memory buffers with predictive coding.
Reference graph
Works this paper leans on
-
[1]
InThe Fourteenth International Conference on Learning Representations, October 2025
LeRobot: An Open-Source Library for End-to-End Robot Learning. InThe Fourteenth International Conference on Learning Representations, October 2025
work page 2025
-
[2]
Michael Ahn, Anthony Brohan, Noah Brown, Yevgen Chebotar, Omar Cortes, Byron David, Chelsea Finn, Chuyuan Fu, Keerthana Gopalakrishnan, Karol Haus- man, Alex Herzog, Daniel Ho, Jasmine Hsu, Julian Ibarz, Brian Ichter, Alex Irpan, Eric Jang, Rosario Jauregui Ru- ano, Kyle Jeffrey, Sally Jesmonth, Nikhil J. Joshi, Ryan Julian, Dmitry Kalashnikov, Yuheng Kua...
work page 2022
-
[3]
PaliGemma: A versatile 3B VLM for transfer
Lucas Beyer, Andreas Steiner, Andr ´e Susano Pinto, Alexander Kolesnikov, Xiao Wang, Daniel Salz, Maxim Neumann, Ibrahim Alabdulmohsin, Michael Tschannen, Emanuele Bugliarello, et al. Paligemma: A versatile 3b vlm for transfer.arXiv preprint arXiv:2407.07726, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Johan Bjorck, Fernando Casta ˜neda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, et al. Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
InRobotics: Science and Systems, 2025
Kevin Black, Noah Brown, Danny Driess, Adnan Es- mail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al.\pi 0 : A vision-language-action flow model for general robot control. InRobotics: Science and Systems, 2025
work page 2025
-
[6]
Real-Time Execution of Action Chunking Flow Policies
Kevin Black, Manuel Y Galliker, and Sergey Levine. Real-time execution of action chunking flow policies. arXiv preprint arXiv:2506.07339, 2025
work page internal anchor Pith review arXiv 2025
-
[7]
RT-1: Robotics Transformer for Real-World Control at Scale
Anthony Brohan, Noah Brown, Justice Carbajal, Yev- gen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, Julian Ibarz, Brian Ichter, Alex Irpan, Tomas Jackson, Sally Jesmonth, Nikhil Joshi, Ryan Julian, Dmitry Kalashnikov, Yuheng Kuang, Isabel Leal, Kuang- Huei Lee, Sergey Levine, Yao Lu, Utsav Malla,...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[8]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-V oss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christo- pher Hesse, Mark Chen, Eric Sigler, Mateusz Lit...
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[9]
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, page 02783649241273668, 2023
work page 2023
-
[10]
Zichen Jeff Cui, Yibin Wang, Nur Muhammad Mahi Shafiullah, and Lerrel Pinto. From play to policy: Conditional behavior generation from uncurated robot data.arXiv preprint arXiv:2210.10047, 2022
-
[11]
Revla: Reverting visual domain limitation of robotic foundation models, 2024
Sombit Dey, Jan-Nico Zaech, Nikolay Nikolov, Luc Van Gool, and Danda Pani Paudel. Revla: Reverting visual domain limitation of robotic foundation models, 2024. URL https://arxiv.org/abs/2409.15250
-
[12]
PaLM-E: An Embodied Multimodal Language Model
Danny Driess, Fei Xia, Mehdi SM Sajjadi, Corey Lynch, Aakanksha Chowdhery, Ayzaan Wahid, Jonathan Tomp- son, Quan Vuong, Tianhe Yu, Wenlong Huang, et al. Palm-e: An embodied multimodal language model.arXiv preprint arXiv:2303.03378, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
Rvt2: Learning precise manipu- lation from few demonstrations.RSS, 2024
Ankit Goyal, Valts Blukis, Jie Xu, Yijie Guo, Yu-Wei Chao, and Dieter Fox. Rvt2: Learning precise manipu- lation from few demonstrations.RSS, 2024
work page 2024
-
[14]
Matthew J. Hausknecht and Peter Stone. Deep recurrent q-learning for partially observable mdps. InAAAI Fall Symposia, volume 45, page 141, 2015
work page 2015
-
[15]
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Es- mail, Michael Equi, Chelsea Finn, Niccolo Fusai, Manuel Y . Galliker, Dibya Ghosh, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Devin LeBlanc, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pert...
work page 2025
-
[16]
Thinking, fast and slow.Farrar, Straus and Giroux, 2011
Daniel Kahneman. Thinking, fast and slow.Farrar, Straus and Giroux, 2011
work page 2011
-
[17]
Vision-language-action models for robotics: A review towards real-world applications
Kento Kawaharazuka, Jihoon Oh, Jun Yamada, Ingmar Posner, and Yuke Zhu. Vision-language-action models for robotics: A review towards real-world applications. IEEE Access, 13:162467–162504, 2025. doi: 10.1109/ ACCESS.2025.3609980
-
[18]
arXiv preprint arXiv:1911.00172 , year=
Urvashi Khandelwal, Omer Levy, Dan Jurafsky, Luke Zettlemoyer, and Mike Lewis. Generalization through memorization: Nearest neighbor language models.arXiv preprint arXiv:1911.00172, 2019
-
[19]
Open- vla: An open-source vision-language-action model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Open- vla: An open-source vision-language-action model. In Conference on Robot Learning, 2024
work page 2024
-
[20]
Fine- tuning vision-language-action models: Optimizing speed and success
Moo Jin Kim, Chelsea Finn, and Percy Liang. Fine- tuning vision-language-action models: Optimizing speed and success. InRobotics: Science and Systems, 2025
work page 2025
-
[21]
Jin Kim, Nur Muhammad Mahi Shafiullah, and Lerrel Pinto
Seungjae Lee, Yibin Wang, Haritheja Etukuru, H. Jin Kim, Nur Muhammad Mahi Shafiullah, and Lerrel Pinto. Behavior generation with latent actions. InInternational Conference on Machine Learning, 2024
work page 2024
-
[22]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich K¨uttler, Mike Lewis, Wen-tau Yih, Tim Rockt ¨aschel, et al. Retrieval-augmented generation for knowledge- intensive nlp tasks.Advances in Neural Information Processing Systems, 33:9459–9474, 2020
work page 2020
-
[23]
Qixiu Li, Yaobo Liang, Zeyu Wang, Lin Luo, Xi Chen, Mozheng Liao, Fangyun Wei, Yu Deng, Sicheng Xu, Yizhong Zhang, Xiaofan Wang, Bei Liu, Jianlong Fu, Jianmin Bao, Dong Chen, Yuanchun Shi, Jiaolong Yang, and Baining Guo. CogACT: A Foundational Vision- Language-Action Model for Synergizing Cognition and Action in Robotic Manipulation, November 2024
work page 2024
-
[24]
Qixiu Li, Yaobo Liang, Zeyu Wang, Lin Luo, Xi Chen, Mozheng Liao, Fangyun Wei, Yu Deng, Sicheng Xu, Yizhong Zhang, et al. Cogact: A foundational vision-language-action model for synergizing cognition and action in robotic manipulation.arXiv preprint arXiv:2411.19650, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Evaluating Real-World Robot Manipulation Policies in Simulation, May 2024
Xuanlin Li, Kyle Hsu, Jiayuan Gu, Karl Pertsch, Oier Mees, Homer Rich Walke, Chuyuan Fu, Ishikaa Lunawat, Isabel Sieh, Sean Kirmani, Sergey Levine, Jiajun Wu, Chelsea Finn, Hao Su, Quan Vuong, and Ted Xiao. Evaluating Real-World Robot Manipulation Policies in Simulation, May 2024
work page 2024
-
[26]
Yicheng Liu, Shiduo Zhang, Zibin Dong, Baijun Ye, Tianyuan Yuan, Xiaopeng Yu, Linqi Yin, Chenhao Lu, Junhao Shi, Luca Jiang-Tao Yu, Liangtao Zheng, Tao Jiang, Jingjing Gong, Xipeng Qiu, and Hang Zhao. FASTer: Toward Efficient Autoregressive Vision Lan- guage Action Modeling via Neural Action Tokenization, December 2025
work page 2025
-
[27]
Omnisat: Compact action token, faster auto regres- sion, 2025
Huaihai Lyu, Chaofan Chen, Senwei Xie, Pengwei Wang, Xiansheng Chen, Shanghang Zhang, and Changsheng Xu. Omnisat: Compact action token, faster auto regres- sion, 2025. URL https://arxiv.org/abs/2510.09667
-
[28]
HAMLET: Switch Your Vision-Language-Action Model into a History-Aware Policy
Myungkyu Koo, Daewon Choi, Taeyoung Kim, Kyung- min Lee, Changyeon Kim, Younggyo Seo, Jinwoo Shin. HAMLET: Switch Your Vision-Language-Action Model into a History-Aware Policy. InThe Fourteenth Interna- tional Conference on Learning Representations, October 2025
work page 2025
-
[29]
Octo: An open-source generalist robot policy
Octo Model Team, Dibya Ghosh, Homer Walke bit, Karl Pertsch, Kevin Black, Oier Mees, Sudeep Dasari, Joey Hejna, Tobias Kreiman, Charles Xu, et al. Octo: An open-source generalist robot policy. InConference on Robot Learning, 2024
work page 2024
-
[30]
Stabilizing transformers for reinforcement learning
Emilio Parisotto, Francis Song, Jack Rae, Razvan Pas- canu, Caglar Gulcehre, Siddhant Jayakumar, Max Jader- berg, Raphael Lopez Kaufman, Aidan Clark, Seb Noury, et al. Stabilizing transformers for reinforcement learning. InInternational Conference on Machine Learning, pages 7487–7498. PMLR, 2020
work page 2020
-
[31]
FAST: Efficient Action Tokenization for Vision-Language-Action Models
Karl Pertsch, Kyle Stachowicz, Brian Ichter, Danny Driess, Suraj Nair, Quan Vuong, Oier Mees, Chelsea Finn, and Sergey Levine. Fast: Efficient action tokeniza- tion for vision-language-action models.arXiv preprint arXiv:2501.09747, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
SpatialVLA: Explor- ing Spatial Representations for Visual-Language-Action Model, May 2025
Delin Qu, Haoming Song, Qizhi Chen, Yuanqi Yao, Xinyi Ye, Yan Ding, Zhigang Wang, JiaYuan Gu, Bin Zhao, Dong Wang, and Xuelong Li. SpatialVLA: Explor- ing Spatial Representations for Visual-Language-Action Model, May 2025
work page 2025
-
[33]
Flower: Democratizing generalist robot policies with efficient vision-language-flow models
Moritz Reuss, Hongyi Zhou, Marcel R ¨uhle, ¨Omer Erdinc ¸ Ya˘gmurlu, Fabian Otto, and Rudolf Lioutikov. Flower: Democratizing generalist robot policies with efficient vision-language-flow models. In Joseph Lim, Shuran Song, and Hae-Won Park, editors,Proceedings of The 9th Conference on Robot Learning, volume 305 ofProceed- ings of Machine Learning Researc...
work page 2025
-
[34]
Behavior transformers: Cloning k modes with one stone
Nur Muhammad Shafiullah, Zichen Cui, Ariuntuya Arty Altanzaya, and Lerrel Pinto. Behavior transformers: Cloning k modes with one stone. InAdvances in Neu- ral Information Processing Systems, volume 35, pages 22955–22968, 2022
work page 2022
-
[35]
Hao Shi, Bin Xie, Yingfei Liu, Lin Sun bit, Fengrong Liu, Tiancai Wang, Erjin Zhou, Haoqiang Fan, Xi- angyu Zhang, and Gao Huang. Memoryvla: Perceptual- cognitive memory in vision-language-action models for robotic manipulation.arXiv preprint arXiv:2508.19236, 2025
-
[36]
Perceiver-actor: A multi-task transformer for robotic ma- nipulation
Mohit Shridhar, Lucas Manuelli, and Dieter Fox. Perceiver-actor: A multi-task transformer for robotic ma- nipulation. InProceedings of the 6th Conference on Robot Learning (CoRL), 2022
work page 2022
-
[37]
Haoming Song, Delin Qu, Yuanqi Yao, Qizhi Chen, Qi Lv, Yiwen Tang, Modi Shi, Guanghui Ren, Maoqing Yao, Bin Zhao, et al. Hume: Introducing system-2 thinking in visual-language-action model.arXiv preprint arXiv:2505.21432, 2025
-
[38]
Generalist robot manipulation beyond action labeled data
Alexander Spiridonov, Jan-Nico Zaech, Nikolay Nikolov, Luc Van Gool, and Danda Pani Paudel. Generalist robot manipulation beyond action labeled data. In9th Annual Conference on Robot Learning, 2025. URL https://openreview.net/forum?id=ZqBXnR6ppz
work page 2025
-
[39]
RoFormer: Enhanced Transformer with Rotary Position Embedding
Jianlin Su, Yu Lu, Shengfeng Pan, Ahmed Murtadha, Bo Wen, and Yunfeng Liu. Roformer: Enhanced trans- former with rotary position embedding, 2023. URL https://arxiv.org/abs/2104.09864
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[40]
End-to-end memory networks.Advances in Neural Information Processing Systems, 28, 2015
Sainbayar Sukhbaatar, Jason Weston, Rob Fergus, et al. End-to-end memory networks.Advances in Neural Information Processing Systems, 28, 2015
work page 2015
-
[41]
Octo: An Open-Source Generalist Robot Policy, May 2024
Octo Model Team, Dibya Ghosh, Homer Walke, Karl Pertsch, Kevin Black, Oier Mees, Sudeep Dasari, Joey Hejna, Tobias Kreiman, Charles Xu, Jianlan Luo, You Liang Tan, Lawrence Yunliang Chen, Pannag San- keti, Quan Vuong, Ted Xiao, Dorsa Sadigh, Chelsea Finn, and Sergey Levine. Octo: An Open-Source Generalist Robot Policy, May 2024
work page 2024
-
[42]
BridgeData V2: A Dataset for Robot Learning at Scale, January 2024
Homer Walke, Kevin Black, Abraham Lee, Moo Jin Kim, Max Du, Chongyi Zheng, Tony Zhao, Philippe Hansen- Estruch, Quan Vuong, Andre He, Vivek Myers, Kuan Fang, Chelsea Finn, and Sergey Levine. BridgeData V2: A Dataset for Robot Learning at Scale, January 2024
work page 2024
-
[43]
Instructvla: Vision-language-action instruction tuning from understanding to manipulation,
Shuai Yang, Hao Li, Yilun Chen, Bin Wang, Yang Tian, Tai Wang, Hanqing Wang, Feng Zhao, Yiyi Liao, and Jiangmiao Pang. Instructvla: Vision-language-action instruction tuning from understanding to manipulation,
- [44]
-
[45]
Latent action pretraining from videos
Seonghyeon Ye, Joel Jang, Byeongguk Jeon, Se June Joo, Jianwei Yang, Baolin Peng, Ajay Mandlekar, Reuben Tan, Yu-Wei Chao, Bill Yuchen Lin, Lars Liden, Kimin Lee, Jianfeng Gao, Luke Zettlemoyer, Dieter Fox, and Minjoon Seo. Latent action pretraining from videos. InThe Thirteenth International Conference on Learn- ing Representations, 2025. URL https://ope...
work page 2025
-
[46]
Robotic control via embodied chain-of-thought reasoning
Michał Zawalski, William Chen, Karl Pertsch, Oier Mees, Chelsea Finn, and Sergey Levine. Robotic control via embodied chain-of-thought reasoning. In8th Annual Conference on Robot Learning, 2024
work page 2024
-
[47]
Autoregressive ac- tion sequence learning for robotic manipulation, 2025
Xinyu Zhang, Yuhan Liu, Haonan Chang, Liam Schramm, and Abdeslam Boularias. Autoregressive ac- tion sequence learning for robotic manipulation, 2025. URL https://arxiv.org/abs/2410.03132
-
[48]
Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn
Tony Z. Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn. Learning Fine-Grained Bimanual Manip- ulation with Low-Cost Hardware, April 2023
work page 2023
-
[49]
Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn
Tony Z. Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn. Learning fine-grained bimanual manipu- lation with low-cost hardware. InRobotics: Science and Systems, 2023
work page 2023
-
[50]
BEAST: Efficient tokenization of b-splines encoded action sequences for imitation learning
Hongyi Zhou, Weiran Liao, Xi Huang, Yucheng Tang, Fabian Otto, Xiaogang Jia, Xinkai Jiang, Simon Hilber, Ge Li, Qian Wang, ¨Omer Erdinc ¸ Ya˘gmurlu, Nils Blank, Moritz Reuss, and Rudolf Lioutikov. BEAST: Efficient tokenization of b-splines encoded action sequences for imitation learning. InThe Thirty-ninth Annual Confer- ence on Neural Information Process...
work page 2025
-
[51]
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, et al. Rt-2: Vision-language- action models transfer web knowledge to robotic control. InConference on Robot Learning, pages 2165–2183. PMLR, 2023. Appendix Please check the supplementary material for videos for different task, and a...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.