Recognition: no theorem link
Delightful Distributed Policy Gradient
Pith reviewed 2026-05-15 07:50 UTC · model grok-4.3
The pith
Delightful policy gradient gates updates by advantage times surprisal to suppress harmful rare failures while keeping rare successes in distributed RL.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
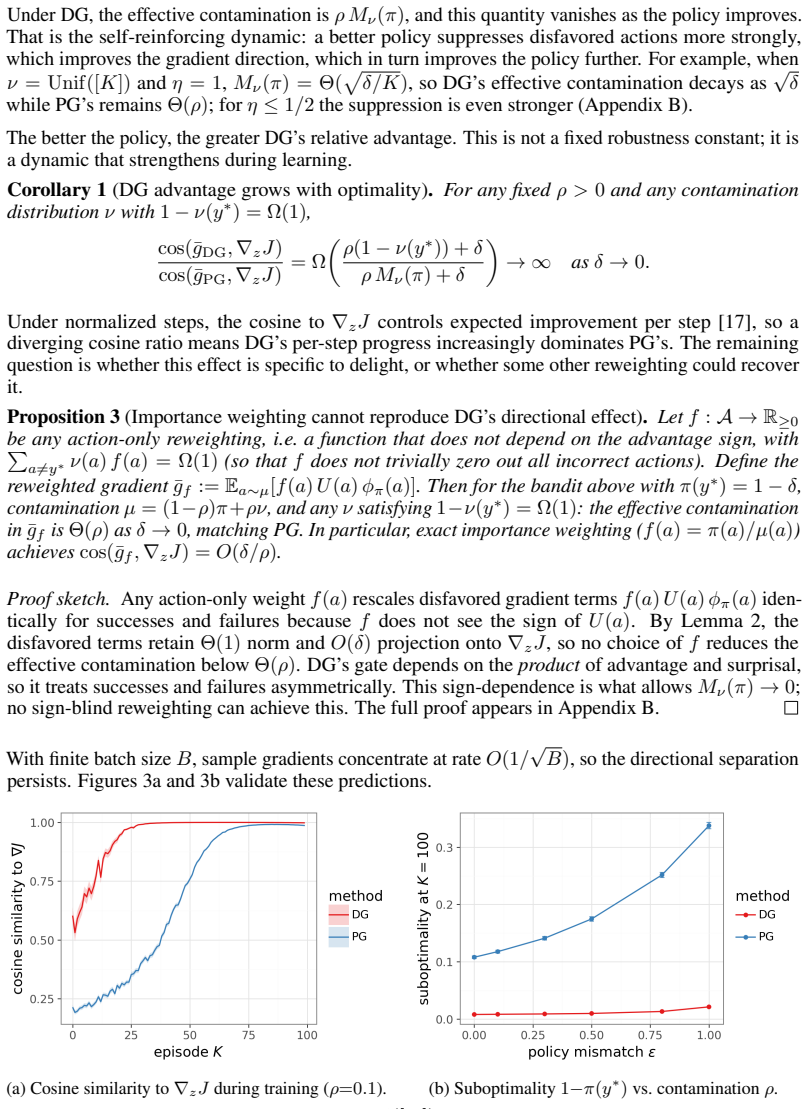
The delightful policy gradient separates high-surprisal successes from failures by gating the update with the product of advantage and surprisal. Tabular analysis shows that this product suppresses the perpendicular second moment of high-surprisal failures by a policy-overlap factor that vanishes as the learner improves. Any gate based only on learner probability suppresses both successes and failures; the advantage sign is therefore essential for the filter to work correctly.
What carries the argument
The delight gate, defined as the product of advantage and surprisal, which filters each policy-gradient update to retain only positive contributions from surprising data.
If this is right
- On MNIST with simulated staleness, DG without off-policy correction outperforms importance-weighted PG that receives exact behavior probabilities.
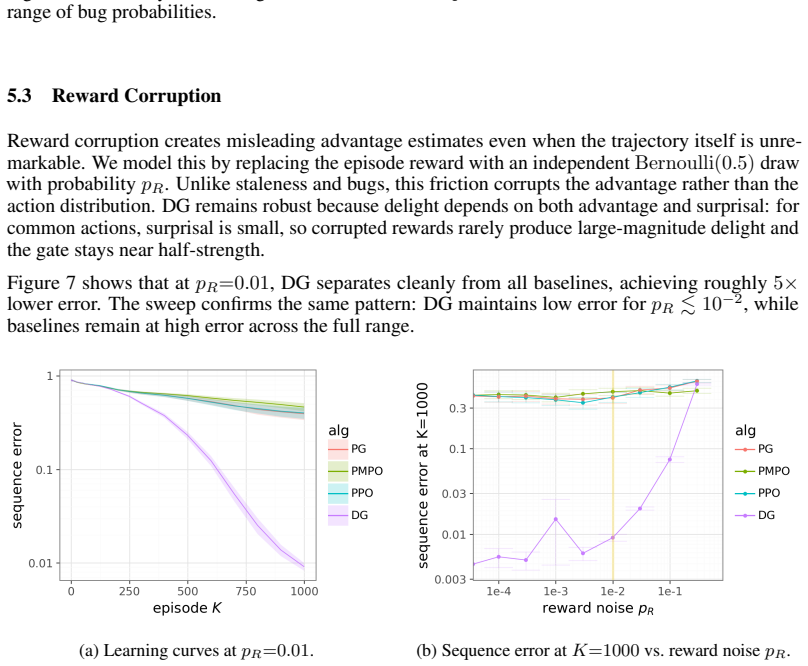
- On a transformer sequence task that includes staleness, actor bugs, reward corruption and rare discovery, DG reaches nearly an order-of-magnitude lower error.
- When all four frictions act together the sample-efficiency advantage grows with task complexity.
- The advantage sign is required; any surprisal-only gate suppresses both rare successes and rare failures.
Where Pith is reading between the lines
- The same delight gate could be applied to other distributed learning loops where collection lag produces high-surprisal data.
- Removing dependence on behavior probabilities simplifies large-scale implementations that already struggle with accurate importance weights.
- The tabular suppression argument suggests that the method may remain stable as policy overlap decreases during early training.
Load-bearing premise
The sign of the advantage correctly distinguishes success from failure even when rewards are corrupted or estimates are noisy.
What would settle it
An experiment that inverts the sign of advantage on high-surprisal samples while keeping all other conditions fixed; if DG then performs worse than an uncorrected gradient, the central claim is false.
Figures















read the original abstract
Distributed reinforcement learning trains on data from stale, buggy, or mismatched actors, producing actions with high surprisal (negative log-probability) under the learner's policy. The core difficulty is not surprising data per se, but \emph{negative learning from surprising data}. High-surprisal failures can dominate finite-batch updates through large perpendicular components, while high-surprisal successes reveal opportunities the current policy would otherwise miss. The \textit{Delightful Policy Gradient} (DG) separates these cases by gating each update with delight, the product of advantage and surprisal, suppressing rare failures and preserving rare successes without behavior probabilities. In a tabular analysis, DG suppresses the perpendicular second moment of high-surprisal failures by a policy-overlap factor that vanishes as the learner improves. The advantage sign is essential for surprisal-based filtering: any learner-probability-only gate that suppresses rare failures also suppresses rare successes. On MNIST with simulated staleness, DG without off-policy correction outperforms importance-weighted PG with exact behavior probabilities. On a transformer sequence task with staleness, actor bugs, reward corruption, and rare discovery, DG often achieves nearly order-of-magnitude lower error. When all four frictions act simultaneously, its sample-efficiency advantage is order-of-magnitude and grows with task complexity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the Delightful Policy Gradient (DG) for distributed RL, which gates each update by delight (advantage times surprisal) to suppress negative learning from high-surprisal failures while preserving rare successes, without requiring behavior probabilities. A tabular analysis shows that this suppresses the perpendicular second moment of high-surprisal failures by a policy-overlap factor that vanishes as the learner improves. Empirical results claim that DG without off-policy correction outperforms importance-weighted PG on MNIST with simulated staleness and achieves nearly order-of-magnitude lower error on a transformer sequence task under combined staleness, actor bugs, reward corruption, and rare discovery, with the advantage growing with task complexity.
Significance. If the tabular suppression mechanism generalizes to neural policies under function approximation and the reported empirical gains are robust, the method could offer a practical, probability-free way to improve robustness and sample efficiency in distributed RL with actor-learner mismatches. The explicit separation of advantage sign from pure surprisal filtering is a clear conceptual contribution that avoids suppressing rare successes.
major comments (2)
- [Tabular analysis] Tabular analysis: the derivation that DG suppresses the perpendicular second moment of high-surprisal failures by a vanishing policy-overlap factor is presented for the tabular setting, but the manuscript reports no measurements of the perpendicular component, overlap factor, or second-moment ratio under the neural-network policies used in the MNIST and transformer experiments, leaving the claimed explanation for the observed gains unverified.
- [Experimental results] Experimental sections: the central claim that DG achieves order-of-magnitude lower error and growing sample-efficiency advantage under simultaneous staleness, bugs, corruption, and rare discovery rests on results whose detailed methods, hyper-parameters, number of runs, and error bars are not provided, preventing verification of the outperformance over importance-weighted PG with exact behavior probabilities.
minor comments (2)
- [Abstract] The abstract states quantitative claims about tabular analysis and experimental outperformance but contains no equations defining delight or the update rule, which would improve immediate clarity.
- [Methods] Notation for surprisal (negative log-probability) and its estimation under stale data should be made explicit in the methods to allow reproduction.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback on our manuscript. We address each major comment point by point below.
read point-by-point responses
-
Referee: [Tabular analysis] Tabular analysis: the derivation that DG suppresses the perpendicular second moment of high-surprisal failures by a vanishing policy-overlap factor is presented for the tabular setting, but the manuscript reports no measurements of the perpendicular component, overlap factor, or second-moment ratio under the neural-network policies used in the MNIST and transformer experiments, leaving the claimed explanation for the observed gains unverified.
Authors: We agree that the manuscript does not report direct measurements of the perpendicular second moment, overlap factor, or second-moment ratio for the neural policies, so the tabular derivation remains an unverified explanation for the empirical gains. The tabular case is meant to illustrate the core mechanism (suppression of high-surprisal negative updates via the delight gate), but extending the exact perpendicular-component analysis to function approximation is non-trivial because the notion of a 'perpendicular' direction is not well-defined in high-dimensional parameter space. In the revision we will add an empirical proxy analysis: histograms of delight values across high-surprisal samples in both the MNIST and transformer experiments, together with the correlation between delight magnitude and the norm of the resulting policy update. This will provide concrete evidence that the gate is selectively attenuating large negative updates while preserving positive ones, thereby partially bridging the tabular insight to the neural results. revision: partial
-
Referee: [Experimental results] Experimental sections: the central claim that DG achieves order-of-magnitude lower error and growing sample-efficiency advantage under simultaneous staleness, bugs, corruption, and rare discovery rests on results whose detailed methods, hyper-parameters, number of runs, and error bars are not provided, preventing verification of the outperformance over importance-weighted PG with exact behavior probabilities.
Authors: The referee is correct that the experimental sections omitted the necessary methodological details. In the revised manuscript we will add a comprehensive experimental appendix that includes: (i) full hyper-parameter tables and network architectures for both the MNIST and transformer tasks, (ii) the exact number of independent runs (five random seeds for MNIST, three for the transformer task), (iii) error bars reported as standard error of the mean across seeds, and (iv) the precise implementation of the importance-weighted policy-gradient baseline that uses the exact behavior probabilities supplied by the simulator. These additions will allow independent verification of the reported performance differences. revision: yes
Circularity Check
No significant circularity; tabular derivation and empirical results remain independent
full rationale
The paper defines delight as the product of advantage and surprisal, then derives in a separate tabular analysis that this gate suppresses the perpendicular second moment of high-surprisal failures by a vanishing policy-overlap factor. This mathematical step is self-contained and does not reduce to the MNIST or transformer experiments by construction. The neural-network results are presented as downstream empirical validation rather than inputs that force the tabular claim. No self-citations, fitted parameters renamed as predictions, or ansatzes smuggled via prior work appear in the derivation chain. The advantage-sign requirement is stated explicitly as a necessary condition within the tabular case and does not loop back to the target performance numbers.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Delightful Exploration
Delight-gated exploration spends actions only when expected improvement times surprisal exceeds a gate price, recovers Pandora's reservation rule, and shows weaker regret growth than Thompson sampling or epsilon-greed...
Reference graph
Works this paper leans on
-
[1]
Preference optimization as probabilistic inference.arXiv e-prints, pages arXiv–2410, 2024
Abbas Abdolmaleki, Bilal Piot, Bobak Shahriari, Jost Tobias Springenberg, Tim Hertweck, Rishabh Joshi, Junhyuk Oh, Michael Bloesch, Thomas Lampe, Nicolas Heess, et al. Preference optimization as probabilistic inference.arXiv e-prints, pages arXiv–2410, 2024
work page 2024
-
[2]
Unifying count-based exploration and intrinsic motivation
Marc Bellemare, Sriram Srinivasan, Georg Ostrovski, Tom Schaul, David Saxton, and Remi Munos. Unifying count-based exploration and intrinsic motivation. InAdvances in Neural Information Processing Systems, volume 29, 2016
work page 2016
-
[3]
Decision transformer: Reinforcement learning via sequence modeling
Lili Chen, Kevin Lu, Aravind Rajeswaran, Kuang-Huei Lee, Aditya Grover, Misha Laskin, Pieter Abbeel, Aravind Srinivas, and Igor Mordatch. Decision transformer: Reinforcement learning via sequence modeling. InAdvances in Neural Information Processing Systems, volume 34, pages 15084–15097, 2021
work page 2021
-
[4]
First return, then explore.Nature, 590(7847):580–586, 2021
Adrien Ecoffet, Joost Huizinga, Joel Lehman, Kenneth O Stanley, and Jeff Clune. First return, then explore.Nature, 590(7847):580–586, 2021
work page 2021
-
[5]
IMPALA: Scalable distributed deep-RL with importance weighted actor-learner architectures
Lasse Espeholt, Hubert Soyer, Remi Munos, Karen Simonyan, V olodymyr Mnih, Tom Ward, Yotam Doron, Vlad Firoiu, Tim Harley, Iain Dunning, et al. IMPALA: Scalable distributed deep-RL with importance weighted actor-learner architectures. InInternational Conference on Machine Learning, pages 1407–1416, 2018
work page 2018
-
[6]
SEED RL: Scalable and effi- cient deep-RL with accelerated central inference
Lasse Espeholt, Hubert Soyer, Remi Munos, Karen Simonyan, V olodymyr Mnih, Tom Ward, Yotam Doron, Vlad Firoiu, Tim Harley, Iain Dunning, et al. SEED RL: Scalable and effi- cient deep-RL with accelerated central inference. InInternational Conference on Learning Representations, 2020
work page 2020
-
[7]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, He Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Defeating nondeterminism in LLM inference.Think- ing Machines Lab blog, 2025
Horace He. Defeating nondeterminism in LLM inference.Think- ing Machines Lab blog, 2025. https://thinkingmachines.ai/blog/ defeating-nondeterminism-in-llm-inference/
work page 2025
-
[9]
Podracer architectures for scalable reinforce- ment learning.arXiv preprint arXiv:2104.06272, 2021
Matteo Hessel, Ivo Danihelka, Fabio Viola, Arthur Guez, Simon Schmitt, Laurent Sifre, Theo- phane Weber, David Silver, and Hado van Hasselt. Podracer architectures for scalable reinforce- ment learning.arXiv preprint arXiv:2104.06272, 2021
-
[10]
Distributed prioritized experience replay
Daniel Horgan, John Quan, David Budden, Gabriel Barth-Maron, Matteo Hessel, Hado Van Hasselt, and David Silver. Distributed prioritized experience replay. In6th International Conference on Learning Represenations, 2018
work page 2018
-
[11]
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. InProc. of ICLR, 2015
work page 2015
-
[12]
Wouter Kool, Herke van Hoof, and Max Welling. Buy 4 REINFORCE samples, get a baseline for free! InDeep Reinforcement Learning Meets Structured Prediction, ICLR Workshop, 2019
work page 2019
-
[13]
Offline reinforcement learning with implicit Q-learning
Ilya Kostrikov, Ashvin Nair, and Sergey Levine. Offline reinforcement learning with implicit Q-learning. InInternational Conference on Learning Representations, 2022
work page 2022
-
[14]
Conservative Q-learning for offline reinforcement learning
Aviral Kumar, Aurick Zhou, George Tucker, and Sergey Levine. Conservative Q-learning for offline reinforcement learning. InAdvances in Neural Information Processing Systems, volume 33, pages 1179–1191, 2020
work page 2020
-
[15]
Safe and efficient off-policy reinforcement learning
Rémi Munos, Tom Stepleton, Anna Harutyunyan, and Marc Bellemare. Safe and efficient off-policy reinforcement learning. InAdvances in Neural Information Processing Systems 29, pages 1046–1054, 2016
work page 2016
-
[16]
Learning to reason with LLMs.OpenAI blog, 2024
OpenAI. Learning to reason with LLMs.OpenAI blog, 2024. https://openai.com/index/ learning-to-reason-with-llms/. 10
work page 2024
-
[17]
Ian Osband. Delightful policy gradient. Technical Report gdm/lfg-1, Google DeepMind, 2025
work page 2025
-
[18]
Curiosity-driven exploration by self-supervised prediction
Deepak Pathak, Pulkit Agrawal, Alexei A Efros, and Trevor Darrell. Curiosity-driven exploration by self-supervised prediction. InInternational Conference on Machine Learning, pages 2778– 2787, 2017
work page 2017
-
[19]
Advantage-Weighted Regression: Simple and Scalable Off-Policy Reinforcement Learning
Xue Bin Peng, Aviral Kumar, Grace Zhang, and Sergey Levine. Advantage-weighted regression: Simple and scalable off-policy reinforcement learning.arXiv preprint arXiv:1910.00177, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[20]
Reinforcement learning by reward-weighted regression
Jan Peters and Stefan Schaal. Reinforcement learning by reward-weighted regression. In International Conference on Machine Learning, pages 723–730, 2007
work page 2007
-
[21]
Off-policy temporal-difference learning with function approximation
Doina Precup, Richard Sutton, and Sanjoy Dasgupta. Off-policy temporal-difference learning with function approximation. InProceedings of The 18th International Conference on Machine Learning, pages 417–424, 2001
work page 2001
-
[22]
Trust region policy optimization
John Schulman, Sergey Levine, Pieter Abbeel, Michael Jordan, and Philipp Moritz. Trust region policy optimization. InProc. of ICML, 2015
work page 2015
-
[23]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[24]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Mingchuan Zhang, Y .K. Li, Y . Wu, and Daya Guo. DeepSeekMath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Sample efficient actor-critic with experience replay
Ziyu Wang, Victor Bapst, Nicolas Heess, V olodymyr Mnih, Remi Munos, Koray Kavukcuoglu, and Nando de Freitas. Sample efficient actor-critic with experience replay. InInternational Conference on Learning Representations, 2017
work page 2017
-
[26]
Ronald J Williams. Simple statistical gradient-following algorithms for connectionist reinforce- ment learning.Machine learning, 8(3):229–256, 1992
work page 1992
-
[27]
Your efficient RL framework secretly brings you off-policy RL training
Feng Yao et al. Your efficient RL framework secretly brings you off-policy RL training. Technical blog post, 2025.https://fengyao.notion.site/off-policy-rl. 11 A MNIST Diagnostic This appendix supplements the MNIST experiments of Section 3 with full experimental details, a learning rate robustness check, and a baseline sensitivity analysis. The robustness...
work page 2025
-
[28]
Every disfavored gradient vector has small projection onto the true gradient: ⟨ϕπ(i),∇ zJ⟩=O(δ)∥∇ zJ∥. These properties are proved in Osband [17]; we restate them here because they are the only external facts needed for the proofs below. B.1 Proof of Lemma 1 The key idea is that the sigmoid gate applied to a negative argument decays exponentially, convert...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.