Recognition: no theorem link
RoboPlayground: Democratizing Robotic Evaluation through Structured Physical Domains
Pith reviewed 2026-05-10 18:42 UTC · model grok-4.3
The pith
Natural language instructions compile into reproducible families of robotic manipulation tasks inside structured physical domains.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
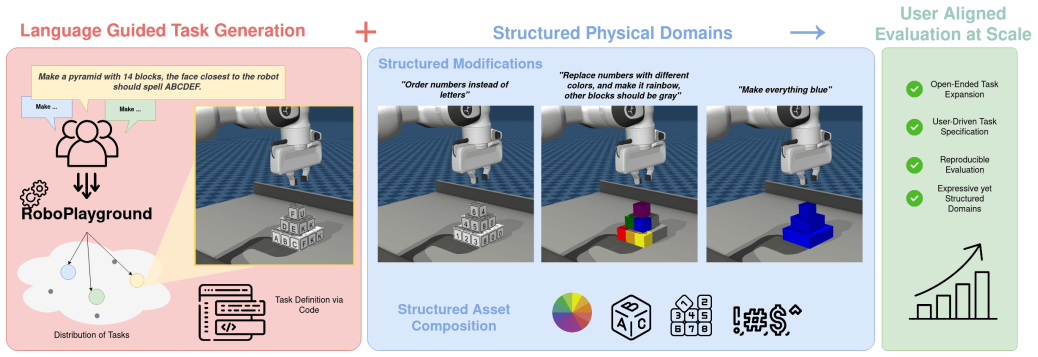
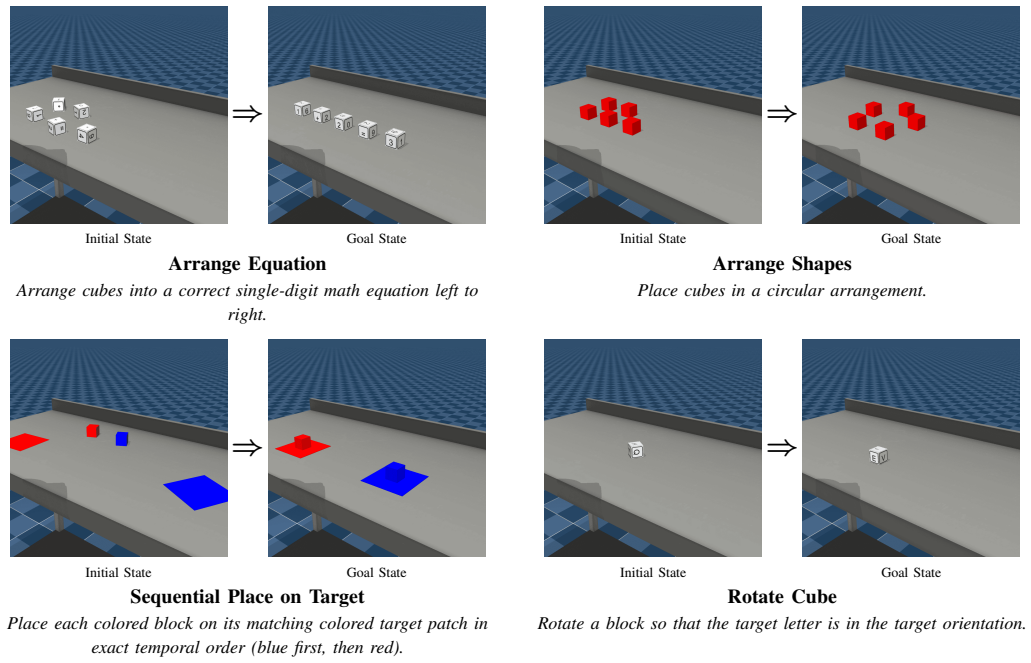
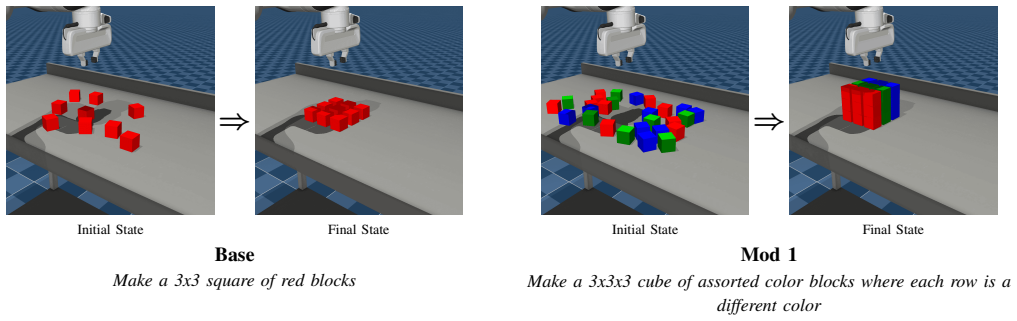
RoboPlayground shows that natural language instructions can be compiled into reproducible task specifications that include explicit asset definitions, initialization distributions, and success predicates. Each compiled instruction defines a structured family of related tasks, allowing controlled semantic and behavioral variation while preserving executability and comparability across evaluations. In a block manipulation domain this produces task spaces whose diversity scales with contributor diversity rather than with total task count.
What carries the argument
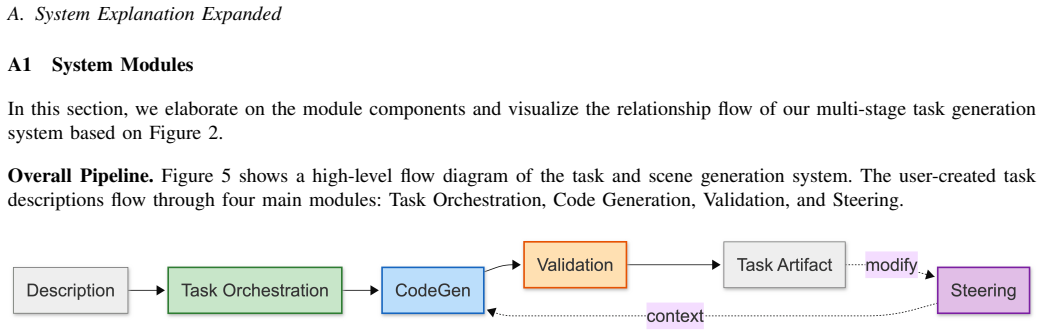
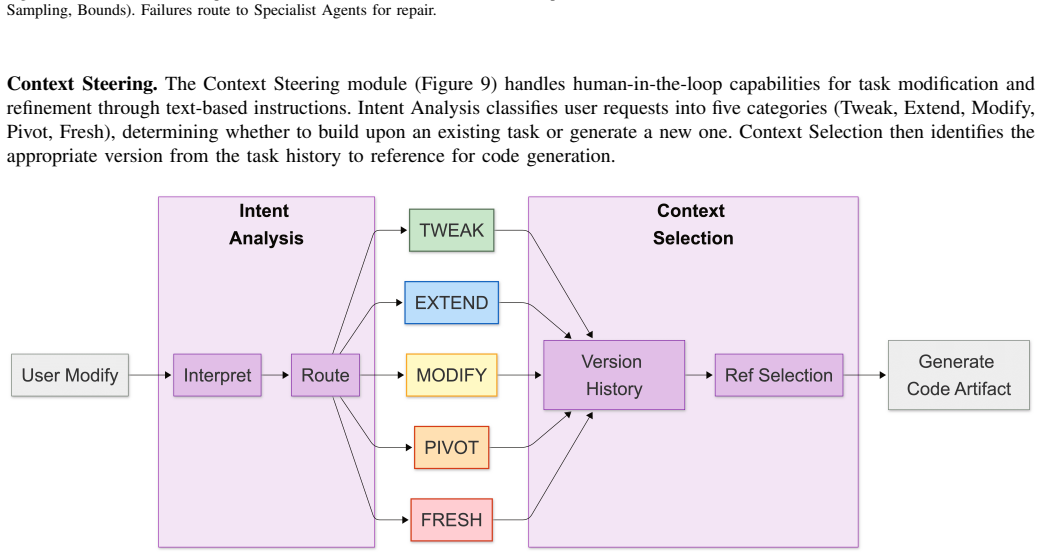
The language-to-specification compiler that turns a single natural language instruction into a family of executable tasks with fixed asset lists, sampled initial states, and predicate-defined success criteria.
If this is right
- Policies that pass fixed benchmarks still exhibit generalization failures when tested across the language-defined task families.
- Evaluation spaces expand continuously as more contributors author instructions rather than through centralized addition of new tasks.
- The language interface lowers cognitive workload compared with direct programming or code-assist baselines.
- Controlled semantic and behavioral variations remain comparable because every instance shares the same compiled asset list, distribution, and success predicate.
Where Pith is reading between the lines
- The same language-compilation structure could be applied to domains other than blocks to test whether generalization gaps appear in wider manipulation skills.
- Continuous contributor growth would make evaluation sets evolve without a single team maintaining them, shifting the bottleneck from task creation to compiler reliability.
- Specific semantic variations isolated by the compiler could be used to diagnose exactly which aspects of user intent a policy fails to handle.
Load-bearing premise
Natural language instructions can be compiled into reproducible task specifications with explicit asset definitions, initialization distributions, and success predicates while enabling controlled semantic and behavioral variation without loss of executability or comparability.
What would settle it
A policy tested on the language-defined task families produces the same success distribution and failure modes as it does on the original fixed benchmarks, or a user study finds no measurable drop in cognitive workload relative to programming baselines.
Figures









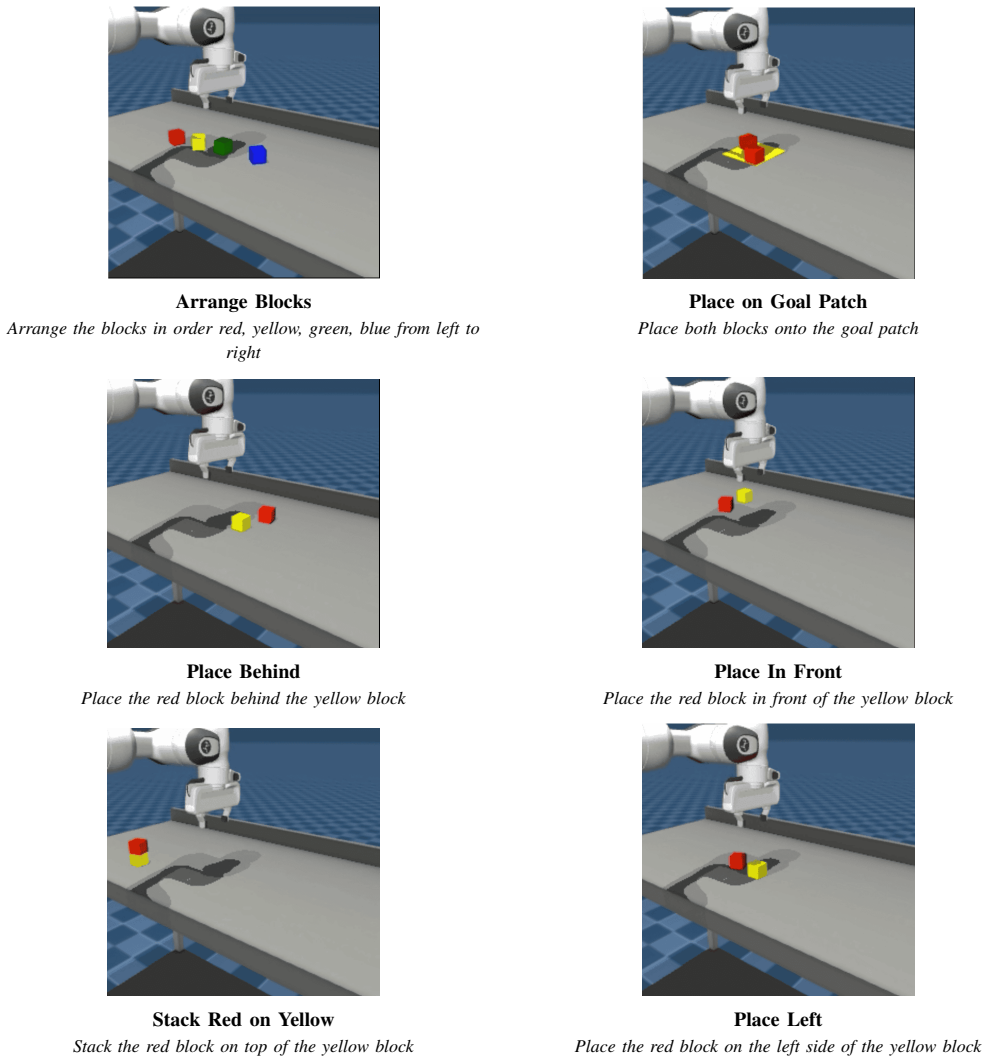


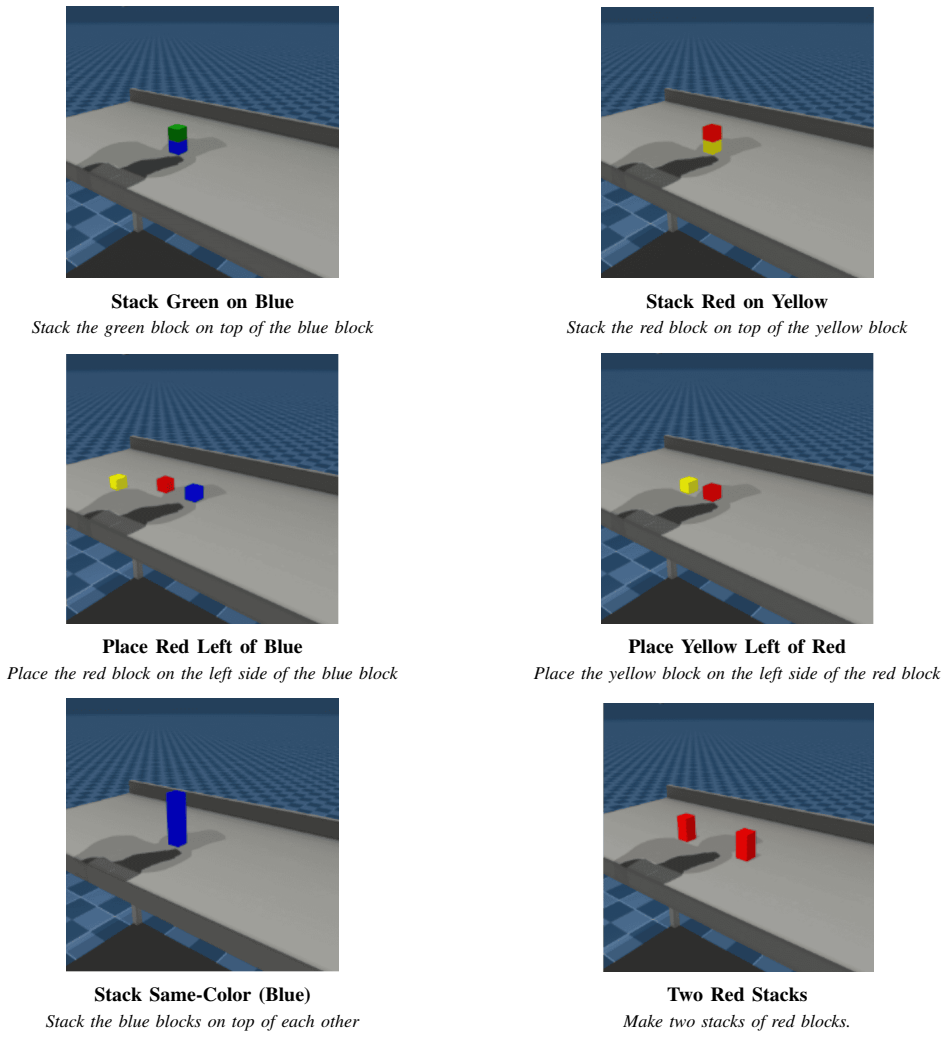








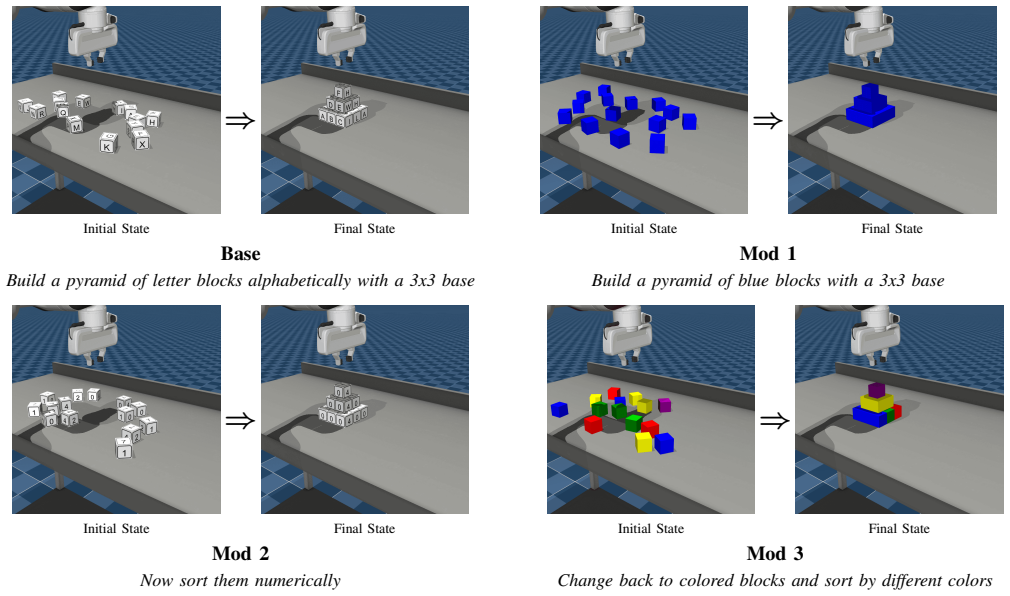
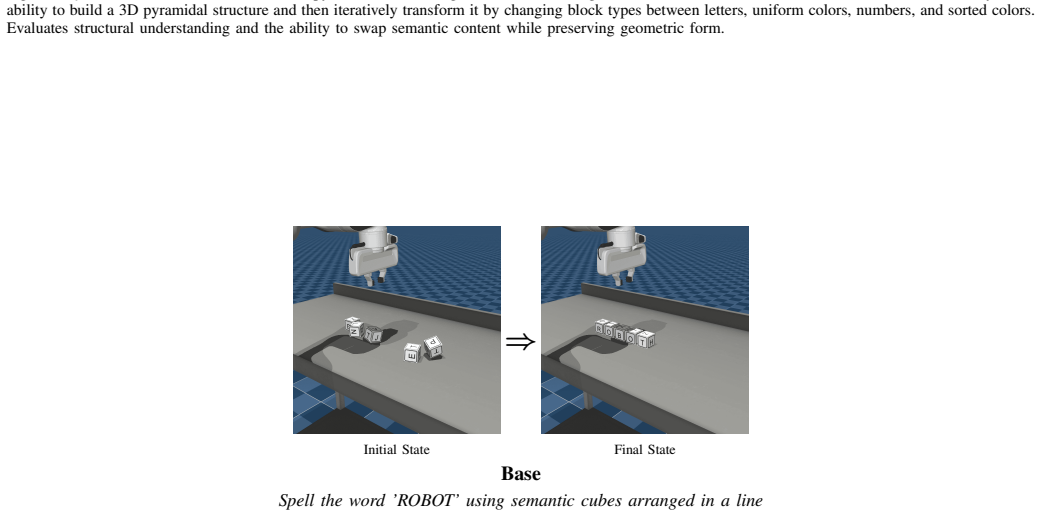
read the original abstract
Evaluation of robotic manipulation systems has largely relied on fixed benchmarks authored by a small number of experts, where task instances, constraints, and success criteria are predefined and difficult to extend. This paradigm limits who can shape evaluation and obscures how policies respond to user-authored variations in task intent, constraints, and notions of success. We argue that evaluating modern manipulation policies requires reframing evaluation as a language-driven process over structured physical domains. We present RoboPlayground, a framework that enables users to author executable manipulation tasks using natural language within a structured physical domain. Natural language instructions are compiled into reproducible task specifications with explicit asset definitions, initialization distributions, and success predicates. Each instruction defines a structured family of related tasks, enabling controlled semantic and behavioral variation while preserving executability and comparability. We instantiate RoboPlayground in a structured block manipulation domain and evaluate it along three axes. A user study shows that the language-driven interface is easier to use and imposes lower cognitive workload than programming-based and code-assist baselines. Evaluating learned policies on language-defined task families reveals generalization failures that are not apparent under fixed benchmark evaluations. Finally, we show that task diversity scales with contributor diversity rather than task count alone, enabling evaluation spaces to grow continuously through crowd-authored contributions. Project Page: https://roboplayground.github.io
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper argues that robotic manipulation evaluation has relied on fixed, expert-authored benchmarks that limit accessibility and obscure policy responses to variations in task intent. It presents RoboPlayground, a framework enabling users to author executable manipulation tasks via natural language within a structured physical domain; these instructions compile into reproducible specifications with explicit asset definitions, initialization distributions, and success predicates, forming task families that support controlled semantic and behavioral variation while preserving executability and comparability. The framework is instantiated in a block-manipulation domain and assessed via a user study on usability, policy generalization experiments, and analysis of how task diversity scales with contributor diversity.
Significance. If substantiated, the work could meaningfully advance the field by shifting evaluation from rigid expert benchmarks toward accessible, language-driven, and continuously expandable task spaces. The structured domain ensures reproducibility and controlled variation, while the user study and policy tests provide initial support for claims of improved usability and exposure of generalization failures. The observation that diversity scales with contributor variety rather than task count alone is a notable strength for long-term scalability.
major comments (2)
- [Abstract and Evaluation sections] Abstract and Evaluation sections: The manuscript states that the user study shows the language-driven interface is easier to use and imposes lower cognitive workload than baselines, and that policy evaluations reveal generalization failures not apparent under fixed benchmarks, but supplies no quantitative results, sample sizes, statistical details, error bars, or p-values. This is load-bearing for the central usability and generalization claims.
- [Methods/Compilation section] Methods/Compilation section: The weakest assumption is that natural language instructions compile into reproducible task specifications without loss of executability or comparability; while the abstract asserts explicit asset definitions, initialization distributions, and success predicates as outputs, no concrete compilation algorithm, failure modes, or validation metrics are referenced to confirm this holds across variations.
minor comments (2)
- [Abstract] The project page is referenced but no details on code or data release are provided in the text; adding a reproducibility statement would strengthen the submission.
- [Introduction] The term 'structured physical domain' is used repeatedly without an early, self-contained definition or diagram; a brief formalization in the introduction would improve clarity for readers outside the immediate subfield.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of the work and for the recommendation of minor revision. We address each major comment below and will strengthen the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract and Evaluation sections] Abstract and Evaluation sections: The manuscript states that the user study shows the language-driven interface is easier to use and imposes lower cognitive workload than baselines, and that policy evaluations reveal generalization failures not apparent under fixed benchmarks, but supplies no quantitative results, sample sizes, statistical details, error bars, or p-values. This is load-bearing for the central usability and generalization claims.
Authors: We agree that the usability and generalization claims are central and would be strengthened by explicit quantitative support. The Evaluation section summarizes the user-study outcomes and policy results but does not present the requested statistical details. In the revised manuscript we will expand the Evaluation section to report participant counts, mean cognitive-workload scores with standard deviations, statistical tests with p-values, and quantitative policy metrics (success rates across task variations with error bars). These additions will directly substantiate the statements in the abstract. revision: yes
-
Referee: [Methods/Compilation section] Methods/Compilation section: The weakest assumption is that natural language instructions compile into reproducible task specifications without loss of executability or comparability; while the abstract asserts explicit asset definitions, initialization distributions, and success predicates as outputs, no concrete compilation algorithm, failure modes, or validation metrics are referenced to confirm this holds across variations.
Authors: We acknowledge that the compilation step is foundational and that the current description leaves the reproducibility assumption under-specified. The manuscript states the intended outputs of compilation but does not detail the algorithm or its validation. In the revised Methods/Compilation section we will provide a concrete description of the compilation pipeline, enumerate common failure modes (e.g., ambiguous phrasing that yields invalid predicates), and report validation metrics such as compilation success rate over a held-out set of instructions. These additions will make the reproducibility claim verifiable. revision: yes
Circularity Check
No significant circularity
full rationale
The paper defines RoboPlayground as an independent framework that compiles natural language into executable task specifications (asset definitions, initialization distributions, success predicates) within a block-manipulation domain. All load-bearing claims are supported by external evaluations: a user study comparing usability and cognitive load against programming baselines, policy generalization tests that expose failures invisible under fixed benchmarks, and empirical scaling of task diversity with contributor diversity. No self-definitional loops, fitted inputs renamed as predictions, or load-bearing self-citations appear; the derivation chain consists of framework construction followed by independent empirical validation rather than reduction to its own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Natural language instructions can be compiled into reproducible task specifications with explicit asset definitions, initialization distributions, and success predicates.
invented entities (2)
-
RoboPlayground framework
no independent evidence
-
Language-defined task families
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
Michael Ahn, Anthony Brohan, Noah Brown, Yevgen Chebotar, Omar Cortes, Byron David, Chelsea Finn, Chuyuan Fu, Keerthana Gopalakrishnan, Karol Haus- man, Alex Herzog, Daniel Ho, Jasmine Hsu, Julian Ibarz, Brian Ichter, Alex Irpan, Eric Jang, Rosario Jauregui Ruano, Kyle Jeffrey, Sally Jesmonth, Nikhil J Joshi, Ryan Julian, Dmitry Kalashnikov, Yuheng Kuang,...
work page internal anchor Pith review arXiv 2022
-
[2]
Cursor: Ai-powered code editor
Anysphere. Cursor: Ai-powered code editor. https: //cursor.com/, 2023. AI-assisted integrated development environment. Available at https://cursor.com/
2023
-
[3]
Pranav Atreya, Karl Pertsch, Tony Lee, Moo Jin Kim, Arhan Jain, Artur Kuramshin, Clemens Eppner, Cyrus Neary, Edward Hu, Fabio Ramos, Jonathan Tremblay, Kanav Arora, Kirsty Ellis, Luca Macesanu, Marcel Torne Villasevil, Matthew Leonard, Meedeum Cho, Ozgur Aslan, Shivin Dass, Jie Wang, William Reger, Xingfang Yuan, Xuning Yang, Abhishek Gupta, Dinesh Jayar...
-
[4]
Qwen3-vl technical report,
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shu- tong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixua...
-
[5]
URL https://arxiv.org/abs/2511.21631
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Sus-a quick and dirty usability scale
John Brooke et al. Sus-a quick and dirty usability scale. Usability evaluation in industry, 189(194):4–7, 1996
1996
-
[7]
A taxon- omy for evaluating generalist robot manipulation poli- cies.IEEE Robotics and Automation Letters, 2026
Jensen Gao, Suneel Belkhale, Sudeep Dasari, Ashwin Balakrishna, Dhruv Shah, and Dorsa Sadigh. A taxon- omy for evaluating generalist robot manipulation poli- cies.IEEE Robotics and Automation Letters, 2026
2026
-
[8]
Ran Gong, Xiaohan Zhang, Jinghuan Shang, Maria Vit- toria Minniti, Jigarkumar Patel, Valerio Pepe, Riedana Yan, Ahmet Gundogdu, Ivan Kapelyukh, Ali Abbas, Xiaoqiang Yan, Harsh Patel, Laura Herlant, and Karl Schmeckpeper. Anytask: an automated task and data generation framework for advancing sim-to-real policy learning, 2026. URL https://arxiv.org/abs/2512.17853
-
[9]
Development of nasa-tlx (task load index): Results of empirical and theo- retical research
Sandra G Hart and Lowell E Staveland. Development of nasa-tlx (task load index): Results of empirical and theo- retical research. InAdvances in psychology, volume 52, pages 139–183. Elsevier, 1988
1988
-
[10]
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Es- mail, Michael Equi, Chelsea Finn, Niccolo Fusai, Manuel Y . Galliker, Dibya Ghosh, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Devin LeBlanc, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pert...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Po- laRiS: Scalable real-to-sim evaluations for generalist robot policies, 2025
Arhan Jain, Mingtong Zhang, Kanav Arora, William Chen, Marcel Torne, Muhammad Zubair Irshad, Sergey Zakharov, Yue Wang, Sergey Levine, Chelsea Finn, Wei-Chiu Ma, Dhruv Shah, Abhishek Gupta, and Karl Pertsch. Polaris: Scalable real-to-sim evaluations for generalist robot policies, 2025. URL https://arxiv.org/ abs/2512.16881
- [12]
-
[13]
Lawrence Zitnick, and Ross Girshick
Justin Johnson, Bharath Hariharan, Laurens van der Maaten, Li Fei-Fei, C. Lawrence Zitnick, and Ross Girshick. Clevr: A diagnostic dataset for compositional language and elementary visual reasoning, 2016. URL https://arxiv.org/abs/1612.06890
-
[14]
Gen2sim: Scaling up robot learning in simulation with generative models, 2023
Pushkal Katara, Zhou Xian, and Katerina Fragkiadaki. Gen2sim: Scaling up robot learning in simulation with generative models, 2023. URL https://arxiv.org/abs/2310. 18308
2023
-
[15]
arXiv:2104.14337 (2021), https://arxiv.org/abs/2104.14337
Douwe Kiela, Max Bartolo, Yixin Nie, Divyansh Kaushik, Atticus Geiger, Zhengxuan Wu, Bertie Vidgen, Grusha Prasad, Amanpreet Singh, Pratik Ringshia, Zhiyi Ma, Tristan Thrush, Sebastian Riedel, Zeerak Waseem, Pontus Stenetorp, Robin Jia, Mohit Bansal, Christopher Potts, and Adina Williams. Dynabench: Rethinking benchmarking in nlp, 2021. URL https://arxiv....
-
[16]
Fine- tuning vision-language-action models: Optimizing speed and success, 2025
Moo Jin Kim, Chelsea Finn, and Percy Liang. Fine- tuning vision-language-action models: Optimizing speed and success, 2025. URL https://arxiv.org/abs/2502. 19645
2025
-
[17]
Brenden M. Lake, Tomer D. Ullman, Joshua B. Tenen- baum, and Samuel J. Gershman. Building machines that learn and think like people, 2016. URL https: //arxiv.org/abs/1604.00289
-
[18]
Chengshu Li, Ruohan Zhang, Josiah Wong, Cem Gok- men, Sanjana Srivastava, Roberto Mart ´ın-Mart´ın, Chen Wang, Gabrael Levine, Wensi Ai, Benjamin Martinez, Hang Yin, Michael Lingelbach, Minjune Hwang, Ayano Hiranaka, Sujay Garlanka, Arman Aydin, Sharon Lee, Jiankai Sun, Mona Anvari, Manasi Sharma, Dhruva Bansal, Samuel Hunter, Kyu-Young Kim, Alan Lou, Cal...
-
[19]
Evaluating Real-World Robot Manipulation Policies in Simulation
Xuanlin Li, Kyle Hsu, Jiayuan Gu, Karl Pertsch, Oier Mees, Homer Rich Walke, Chuyuan Fu, Ishikaa Lunawat, Isabel Sieh, Sean Kirmani, Sergey Levine, Jiajun Wu, Chelsea Finn, Hao Su, Quan Vuong, and Ted Xiao. Evaluating real-world robot manipulation policies in sim- ulation, 2024. URL https://arxiv.org/abs/2405.05941
work page internal anchor Pith review arXiv 2024
-
[20]
Code as Policies: Language Model Programs for Embodied Control
Jacky Liang, Wenlong Huang, Fei Xia, Peng Xu, Karol Hausman, Brian Ichter, Pete Florence, and Andy Zeng. Code as policies: Language model programs for embod- ied control, 2023. URL https://arxiv.org/abs/2209.07753
work page internal anchor Pith review arXiv 2023
-
[21]
Eu- rekaverse: Environment curriculum generation via large language models, 2024
William Liang, Sam Wang, Hung-Ju Wang, Osbert Bas- tani, Dinesh Jayaraman, and Yecheng Jason Ma. Eu- rekaverse: Environment curriculum generation via large language models, 2024. URL https://arxiv.org/abs/2411. 01775
2024
-
[22]
LIBERO: Benchmarking Knowledge Transfer for Lifelong Robot Learning
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning, 2023. URL https://arxiv.org/abs/2306.03310
work page internal anchor Pith review arXiv 2023
-
[23]
Eureka: Human- level reward design via coding large language models,
Yecheng Jason Ma, William Liang, Guanzhi Wang, De- An Huang, Osbert Bastani, Dinesh Jayaraman, Yuke Zhu, Linxi Fan, and Anima Anandkumar. Eureka: Human- level reward design via coding large language models,
-
[24]
URL https://arxiv.org/abs/2310.12931
work page internal anchor Pith review arXiv
-
[25]
Tongzhou Mu, Zhan Ling, Fanbo Xiang, Derek Yang, Xuanlin Li, Stone Tao, Zhiao Huang, Zhiwei Jia, and Hao Su. Maniskill: Generalizable manipulation skill benchmark with large-scale demonstrations, 2021. URL https://arxiv.org/abs/2107.14483
-
[26]
RoboCasa: Large-Scale Simulation of Everyday Tasks for Generalist Robots
Soroush Nasiriany, Abhiram Maddukuri, Lance Zhang, Adeet Parikh, Aaron Lo, Abhishek Joshi, Ajay Man- dlekar, and Yuke Zhu. Robocasa: Large-scale simulation of everyday tasks for generalist robots, 2024. URL https://arxiv.org/abs/2406.02523
work page internal anchor Pith review arXiv 2024
-
[27]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
NVIDIA, :, Johan Bjorck, Fernando Casta ˜neda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi ”Jim” Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, Joel Jang, Zhenyu Jiang, Jan Kautz, Kaushil Kundalia, Lawrence Lao, Zhiqi Li, Zongyu Lin, Kevin Lin, Guilin Liu, Edith Llontop, Loic Magne, Ajay Mandlekar, Avnish Narayan, Soroush Nasiriany, Scott Reed,...
work page internal anchor Pith review arXiv 2025
-
[28]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fer- nandez, Daniel Haziza, Francisco Massa, Alaaeldin El- Nouby, Mahmoud Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Herv ´e Jegou, Julien Mairal, P...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
arXiv preprint arXiv:2402.08191 (2024) 14
Wilbert Pumacay, Ishika Singh, Jiafei Duan, Ranjay Krishna, Jesse Thomason, and Dieter Fox. The colos- seum: A benchmark for evaluating generalization for robotic manipulation, 2024. URL https://arxiv.org/abs/ 2402.08191
-
[30]
Differentiable gpu- parallelized task and motion planning.arXiv preprint arXiv:2411.11833, 2024
William Shen, Caelan Garrett, Nishanth Kumar, Ankit Goyal, Tucker Hermans, Leslie Pack Kaelbling, Tom ´as Lozano-P´erez, and Fabio Ramos. Differentiable gpu- parallelized task and motion planning.arXiv preprint arXiv:2411.11833, 2024
-
[31]
Starvla: A lego-like codebase for vision-language-action model developing
starVLA Contributors. Starvla: A lego-like codebase for vision-language-action model developing. GitHub repos- itory, 2025. URL https://github.com/starVLA/starVLA
2025
-
[32]
Gensim: Generating robotic simulation tasks via large language models,
Lirui Wang, Yiyang Ling, Zhecheng Yuan, Mohit Shrid- har, Chen Bao, Yuzhe Qin, Bailin Wang, Huazhe Xu, and Xiaolong Wang. Gensim: Generating robotic sim- ulation tasks via large language models.arXiv preprint arXiv:2310.01361, 2023
-
[33]
Roboeval: Where robotic manipulation meets structured and scalable evaluation,
Yi Ru Wang, Carter Ung, Grant Tannert, Jiafei Duan, Josephine Li, Amy Le, Rishabh Oswal, Markus Grotz, Wilbert Pumacay, Yuquan Deng, Ranjay Krishna, Dieter Fox, and Siddhartha Srinivasa. Roboeval: Where robotic manipulation meets structured and scalable evaluation,
-
[34]
URL https://arxiv.org/abs/2507.00435
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
Yufei Wang, Zhou Xian, Feng Chen, Tsun-Hsuan Wang, Yian Wang, Katerina Fragkiadaki, Zackory Erickson, David Held, and Chuang Gan. Robogen: Towards un- leashing infinite data for automated robot learning via generative simulation, 2024. URL https://arxiv.org/abs/ 2311.01455. APPENDIX Contents A System Explanation Expanded . . . . . . . . . . . . . . . . . ...
-
[36]
I think that I would like to use this system frequently
-
[37]
I found the system unnecessarily complex
-
[38]
I thought the system was easy to use
-
[39]
I think that I would need the support of a technical person to be able to use this system
-
[40]
I found the various functions in this system were well integrated
-
[41]
I thought there was too much inconsistency in this system
-
[42]
I would imagine that most people would learn to use this system very quickly
-
[43]
I found the system very cumbersome to use
-
[44]
I felt very confident using the system
-
[45]
Overall, which system did you prefer for task generation?
I needed to learn a lot of things before I could get going with this system. TABLE V: System Usability Scale (SUS) questionnaire items. Items 2, 4, 6, 8, and 10 are reverse-scored. NASA Task Load Index (TLX):The NASA-TLX is a multidimensional assessment tool for measuring perceived workload [8]. We used an unweighted version with five subscales rated on 7...
-
[46]
Does _success() check ALL conditions implied by the task?
-
[47]
Are there missing checks (e.g., ordering, colors, positions)?
-
[48]
Are there extra checksnotrequired by the task?
-
[49]
alignment_score
Is the logic sound (correct comparisons, thresholds)? ## Output Format RespondwithONLY a valid JSONobject: { "alignment_score": <0-100 integer>, "aligned": <trueifscore >= 80, false otherwise>, "missing_checks": ["list of missing checks"], "extra_checks": ["list of unnecessary checks"], "logic_issues": ["list of logical problems"], "reasoning": "brief exp...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.