Recognition: 3 theorem links
· Lean TheoremRectified Schr\"odinger Bridge Matching for Few-Step Visual Navigation
Pith reviewed 2026-05-10 19:20 UTC · model grok-4.3
The pith
A single velocity network works across all regularization strengths in Schrödinger Bridge policies, enabling 3-step visual navigation at 92% success.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We prove that the conditional velocity field's functional form is invariant across the entire ε-spectrum, enabling a single network to serve all regularization strengths, and that reducing ε linearly decreases the conditional velocity variance, enabling more stable coarse-step ODE integration. Anchored to a learned conditional prior that shortens transport distance, RSBM operates at an intermediate ε that balances multimodal coverage and path straightness, achieving over 94% cosine similarity and 92% success rate in merely 3 integration steps without distillation or multi-stage training.
What carries the argument
Rectified Schrödinger Bridge Matching (RSBM) framework controlled by the entropic regularization parameter ε, which exploits velocity structure invariance between standard Schrödinger Bridges and deterministic optimal transport.
If this is right
- One network trained at any single ε can be reused for every other regularization strength.
- Coarse-step ODE integration becomes stable because velocity variance drops linearly with ε.
- Generative policies reach real-time latency while retaining multimodal action distributions.
- No distillation or multi-stage training is required to reach few-step performance.
Where Pith is reading between the lines
- The same invariance could let practitioners switch ε on the fly during deployment to trade off exploration and efficiency.
- Similar rectification might shorten sampling in other bridge-based or flow-matching models used for robotic control.
- The approach may extend to non-visual high-dimensional control tasks where long-horizon multimodal actions are needed.
Load-bearing premise
A learned conditional prior reliably shortens transport distance and the velocity structure invariance holds in practice for high-dimensional visual observations without extra training or adjustments.
What would settle it
Measuring whether cosine similarity between predicted and ground-truth actions falls below 90% or success rate falls below 80% when the trained network is evaluated with only three integration steps on new visual navigation environments.
Figures
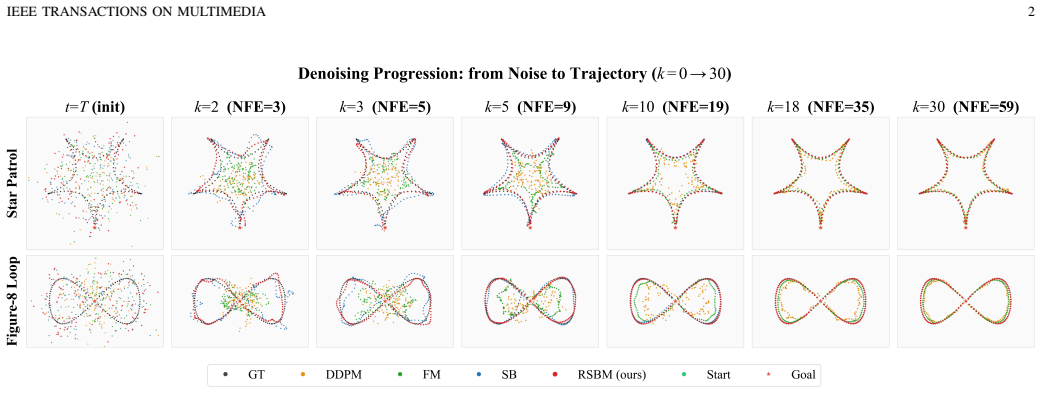




read the original abstract
Visual navigation is a core challenge in Embodied AI, requiring autonomous agents to translate high-dimensional sensory observations into continuous, long-horizon action trajectories. While generative policies based on diffusion models and Schr\"odinger Bridges (SB) effectively capture multimodal action distributions, they require dozens of integration steps due to high-variance stochastic transport, posing a critical barrier for real-time robotic control. We propose Rectified Schr\"odinger Bridge Matching (RSBM), a framework that exploits a shared velocity-field structure between standard Schr\"odinger Bridges ($\varepsilon=1$, maximum-entropy transport) and deterministic Optimal Transport ($\varepsilon\to 0$, as in Conditional Flow Matching), controlled by a single entropic regularization parameter $\varepsilon$. We prove two key results: (1) the conditional velocity field's functional form is invariant across the entire $\varepsilon$-spectrum (Velocity Structure Invariance), enabling a single network to serve all regularization strengths; and (2) reducing $\varepsilon$ linearly decreases the conditional velocity variance, enabling more stable coarse-step ODE integration. Anchored to a learned conditional prior that shortens transport distance, RSBM operates at an intermediate $\varepsilon$ that balances multimodal coverage and path straightness. Empirically, while standard bridges require $\geq 10$ steps to converge, RSBM achieves over 94% cosine similarity and 92% success rate in merely 3 integration steps -- without distillation or multi-stage training -- substantially narrowing the gap between high-fidelity generative policies and the low-latency demands of Embodied AI.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Rectified Schrödinger Bridge Matching (RSBM) for few-step visual navigation. It claims to prove that the conditional velocity field's functional form is invariant across the ε-spectrum of Schrödinger Bridges (Velocity Structure Invariance) and that reducing ε linearly decreases conditional velocity variance, enabling stable coarse-step ODE integration. Anchored to a learned conditional prior that shortens transport distance, RSBM operates at intermediate ε and reports over 94% cosine similarity and 92% success rate in 3 integration steps without distillation or multi-stage training.
Significance. If the invariance and variance-reduction results hold and generalize beyond the reported setting, the work could meaningfully advance real-time deployment of generative policies in Embodied AI by closing the gap between high-fidelity multimodal action modeling and low-latency control requirements.
major comments (2)
- [§3] §3 (Method/Theoretical Analysis): The proof of Velocity Structure Invariance is asserted to hold independently across the ε-spectrum, but the derivation details are not fully expanded; it is unclear whether the invariance is shown to be independent of the specific form of the learned conditional prior or reduces to a property of the chosen reference measure.
- [§4] §4 (Experiments): The reported 94% cosine similarity and 92% success rate in 3 steps are presented without ablations that isolate the learned conditional prior's contribution to transport-distance shortening versus the ε-variance reduction alone, nor direct comparisons to standard SB at the same step count; this leaves the central empirical claim dependent on an unverified precondition.
minor comments (2)
- Notation for the conditional velocity field v_ε and the prior could be introduced with an explicit equation early in the text for clarity.
- Figure captions and axis labels in the navigation results should explicitly state the number of integration steps and ε values used.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential impact of RSBM on real-time generative policies in Embodied AI. We address each major comment below and have revised the manuscript accordingly to strengthen both the theoretical exposition and the empirical validation.
read point-by-point responses
-
Referee: [§3] §3 (Method/Theoretical Analysis): The proof of Velocity Structure Invariance is asserted to hold independently across the ε-spectrum, but the derivation details are not fully expanded; it is unclear whether the invariance is shown to be independent of the specific form of the learned conditional prior or reduces to a property of the chosen reference measure.
Authors: We appreciate this observation. The proof of Velocity Structure Invariance (Theorem 1 in §3.2) establishes that the functional form of the conditional velocity field remains identical across the ε-spectrum because it follows directly from the Girsanov change of measure between the reference Wiener process and the Schrödinger Bridge marginals; the derivation is independent of the particular learned conditional prior π(x0,x1) and holds for any reference measure whose drift satisfies the required martingale property. To improve clarity, we have expanded the proof in the revised §3.2 with all intermediate steps (including the explicit computation of the Radon-Nikodym derivative and the resulting velocity expression) and added a remark explicitly stating its independence from the form of the conditional prior. revision: yes
-
Referee: [§4] §4 (Experiments): The reported 94% cosine similarity and 92% success rate in 3 steps are presented without ablations that isolate the learned conditional prior's contribution to transport-distance shortening versus the ε-variance reduction alone, nor direct comparisons to standard SB at the same step count; this leaves the central empirical claim dependent on an unverified precondition.
Authors: We agree that isolating the two mechanisms strengthens the central claim. While the original experiments already include overall comparisons of RSBM against standard SB (showing the latter requires ≥10 steps), we did not provide explicit ablations that turn the learned prior on/off or fix ε=1 while varying step count. In the revised manuscript we have added (i) a new ablation table in §4.3 that reports 3-step performance with and without the learned conditional prior at the same intermediate ε, and (ii) direct head-to-head results for standard SB at exactly 3 integration steps. These additions confirm that both the prior-induced distance shortening and the ε-variance reduction are necessary for the reported performance. revision: yes
Circularity Check
No significant circularity detected in the derivation chain.
full rationale
The abstract presents two explicit mathematical proofs (Velocity Structure Invariance of the conditional velocity field across the full ε-spectrum, and linear decrease in conditional velocity variance with ε) as independent derivations that justify using a single network and coarser ODE steps. These are not shown to reduce by construction to fitted parameters or self-citations. The anchoring to a learned conditional prior is stated as a design premise that shortens transport distance, but the performance claims (94% cosine similarity, 92% success in 3 steps) are reported as empirical outcomes rather than predictions forced from the prior by definition. No load-bearing step in the provided text equates a result to its own inputs via renaming, ansatz smuggling, or uniqueness imported from prior self-work. The framework remains self-contained with external experimental validation.
Axiom & Free-Parameter Ledger
free parameters (1)
- ε
axioms (1)
- domain assumption Conditional velocity field functional form remains invariant across all ε values
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 1 (Velocity Structure Invariance). ... the logarithmic derivative of the standard deviation satisfies d log σ_ε,t / dt = (1−2s_t)/[t(1−s_t)], which is independent of ε.
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Proposition 1 (Velocity Variance Reduction). Var[v*_t | a0,aT] = ε · (1−2s_t)^2 / (1−s_t) · I_D
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Anchored to a learned conditional prior that shortens transport distance
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Consistency models,
Y . Song, P. Dhariwal, M. Chen, and I. Sutskever, “Consistency models,” inInternational Conference on Machine Learning. PMLR, 2023, pp. 32 211–32 252
2023
-
[2]
Flow straight and fast: Learning to gen- erate and transfer data with rectified flow,
X. Liu, C. Gong, and Q. Liu, “Flow straight and fast: Learning to gen- erate and transfer data with rectified flow,” inInternational Conference on Learning Representations, 2023
2023
-
[3]
A survey on map-based localization techniques for autonomous vehicles,
A. Chalvatzaras, I. Pratikakis, and A. A. Amanatiadis, “A survey on map-based localization techniques for autonomous vehicles,”IEEE Transactions on intelligent vehicles, vol. 8, no. 2, pp. 1574–1596, 2022
2022
-
[4]
Survey of robot 3d path planning algorithms,
L. Yang, J. Qi, D. Song, J. Xiao, J. Han, and Y . Xia, “Survey of robot 3d path planning algorithms,”Journal of Control Science and Engineering, vol. 2016, no. 1, p. 7426913, 2016
2016
-
[5]
A survey on visual navigation for artificial agents with deep reinforcement learning,
F. Zeng, C. Wang, and S. S. Ge, “A survey on visual navigation for artificial agents with deep reinforcement learning,”Ieee Access, vol. 8, pp. 135 426–135 442, 2020
2020
-
[6]
Visual navigation in real-world indoor environments using end-to-end deep reinforcement learning,
J. Kulh ´anek, E. Derner, and R. Babuˇska, “Visual navigation in real-world indoor environments using end-to-end deep reinforcement learning,” IEEE Robotics and Automation Letters, vol. 6, no. 3, pp. 4345–4352, 2021
2021
-
[7]
A behavioral approach to visual navigation with graph localization networks,
K. Chen, J. P. De Vicente, G. Sepulveda, F. Xia, A. Soto, M. V ´azquez, and S. Savarese, “A behavioral approach to visual navigation with graph localization networks,”arXiv preprint arXiv:1903.00445, 2019
-
[8]
Vision-based goal-conditioned policies for underwater navigation in the presence of obstacles,
T. Manderson, J. C. G. Higuera, S. Wapnick, J.-F. Tremblay, F. Shkurti, D. Meger, and G. Dudek, “Vision-based goal-conditioned policies for underwater navigation in the presence of obstacles,”arXiv preprint arXiv:2006.16235, 2020
-
[9]
Vint: A foundation model for visual navigation.arXiv preprint arXiv:2306.14846, 2023
D. Shah, A. Sridhar, N. Dashora, K. Stachowicz, K. Black, N. Hirose, and S. Levine, “Vint: A foundation model for visual navigation,”arXiv preprint arXiv:2306.14846, 2023
-
[10]
Igl- nav: Incremental 3d gaussian localization for image-goal navigation,
W. Guo, X. Xu, H. Yin, Z. Wang, J. Feng, J. Zhou, and J. Lu, “Igl- nav: Incremental 3d gaussian localization for image-goal navigation,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 6808–6817
2025
-
[11]
Gaussnav: Gaussian splatting for visual navigation,
X. Lei, M. Wang, W. Zhou, and H. Li, “Gaussnav: Gaussian splatting for visual navigation,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 47, no. 5, pp. 4108–4121, 2025
2025
-
[12]
Implicit behavioral cloning,
P. Florence, C. Lynch, A. Zeng, O. A. Ramirez, A. Wahid, L. Downs, A. Wong, J. Lee, I. Mordatch, and J. Tompson, “Implicit behavioral cloning,” inConference on robot learning. PMLR, 2022, pp. 158–168
2022
-
[13]
Behavior transformers: Cloningkmodes with one stone,
N. M. Shafiullah, Z. Cui, A. A. Altanzaya, and L. Pinto, “Behavior transformers: Cloningkmodes with one stone,”Advances in neural information processing systems, vol. 35, pp. 22 955–22 968, 2022
2022
-
[14]
Motion planning diffusion: Learning and planning of robot motions with diffu- sion models,
J. Carvalho, A. T. Le, M. Baierl, D. Koert, and J. Peters, “Motion planning diffusion: Learning and planning of robot motions with diffu- sion models,” in2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2023, pp. 1916–1923
2023
-
[15]
3d diffuser actor: Policy diffusion with 3d scene representations, 2024
T.-W. Ke, N. Gkanatsios, and K. Fragkiadaki, “3d diffuser ac- tor: Policy diffusion with 3d scene representations,”arXiv preprint arXiv:2402.10885, 2024
-
[16]
Diffusion models for reinforcement learning: A survey.arXiv preprint arXiv:2311.01223, 2023
Z. Zhu, H. Zhao, H. He, Y . Zhong, S. Zhang, H. Guo, T. Chen, and W. Zhang, “Diffusion models for reinforcement learning: A survey,” arXiv preprint arXiv:2311.01223, 2023
-
[17]
A. Ajay, Y . Du, A. Gupta, J. Tenenbaum, T. Jaakkola, and P. Agrawal, “Is conditional generative modeling all you need for decision-making?” arXiv preprint arXiv:2211.15657, 2022
-
[18]
Planning with Diffusion for Flexible Behavior Synthesis
M. Janner, Y . Du, J. B. Tenenbaum, and S. Levine, “Planning with diffu- sion for flexible behavior synthesis,”arXiv preprint arXiv:2205.09991, 2022
work page internal anchor Pith review arXiv 2022
-
[19]
Nomad: Goal masked diffusion policies for navigation and exploration,
A. Sridhar, D. Shah, C. Glossop, and S. Levine, “Nomad: Goal masked diffusion policies for navigation and exploration,” in2024 IEEE Inter- national Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 63–70
2024
-
[20]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” Advances in neural information processing systems, vol. 33, pp. 6840– 6851, 2020
2020
-
[21]
Deep unsupervised learning using nonequilibrium thermodynamics,
J. Sohl-Dickstein, E. Weiss, N. Maheswaranathan, and S. Ganguli, “Deep unsupervised learning using nonequilibrium thermodynamics,” in International Conference on Machine Learning, 2015, pp. 2256–2265
2015
-
[22]
Aligned diffusion Schr ¨odinger bridges,
V . R. Somnath, M. Pariset, Y .-P. Hsieh, M. R. Martinez, A. Krause, and C. Bunne, “Aligned diffusion Schr ¨odinger bridges,” inUncertainty in Artificial Intelligence. PMLR, 2023, pp. 1985–1995
2023
-
[23]
Simulating diffusion bridges with score matching,
J. Heng, V . De Bortoli, A. Doucet, and J. Thornton, “Simulating diffusion bridges with score matching,”Biometrika, vol. 112, no. 4, p. asaf048, 2025
2025
-
[24]
Let us build bridges: Understanding and extending diffusion generative models
X. Liu, L. Wu, M. Ye, and Q. Liu, “Let us build bridges: Under- standing and extending diffusion generative models,”arXiv preprint arXiv:2208.14699, 2022
-
[25]
Bbdm: Image-to-image trans- lation with brownian bridge diffusion models,
B. Li, K. Xue, B. Liu, and Y .-K. Lai, “Bbdm: Image-to-image trans- lation with brownian bridge diffusion models,” inProceedings of the IEEE/CVF conference on computer vision and pattern Recognition, 2023, pp. 1952–1961
2023
-
[26]
Denoising diffusion bridge models.arXiv preprint arXiv:2309.16948, 2023
L. Zhou, A. Lou, S. Khanna, and S. Ermon, “Denoising diffusion bridge models,”arXiv preprint arXiv:2309.16948, 2023
-
[27]
Diffusion Schr¨odinger bridge matching,
Y . Shi, V . De Bortoli, A. Campbell, and A. Doucet, “Diffusion Schr¨odinger bridge matching,” inAdvances in Neural Information Processing Systems, vol. 36, 2023
2023
-
[28]
Generalized Schr ¨odinger bridge matching,
G.-H. Liu, Y . Lipman, M. Nickel, B. Karrer, E. A. Theodorou, and R. T. Q. Chen, “Generalized Schr ¨odinger bridge matching,” inInterna- tional Conference on Learning Representations, 2024
2024
-
[29]
Light and optimal Schr¨odinger bridge matching,
N. Gushchin, S. Kholkin, E. Burnaev, and A. Korotin, “Light and optimal Schr¨odinger bridge matching,”arXiv preprint arXiv:2402.03207, 2024
-
[30]
N. Gushchin, D. Selikhanovych, and A. Korotin, “Adversarial Schr¨odinger bridge matching,”arXiv preprint arXiv:2405.06474, 2024
-
[31]
Prior does matter: Visual navigation via denoising diffusion bridge models,
H. Ren, Y . Zeng, Z. Bi, Z. Wan, J. Huang, and H. Cheng, “Prior does matter: Visual navigation via denoising diffusion bridge models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025, pp. 12 100–12 110
2025
-
[32]
arXiv preprint arXiv:2402.15852 (2024) 13
J. Zhang, K. Wang, R. Xu, G. Zhou, Y . Hong, X. Fang, Q. Wu, Z. Zhang, and H. Wang, “Navid: Video-based vlm plans the next step for vision- and-language navigation,”arXiv preprint arXiv:2402.15852, 2024
-
[33]
Flownav: Combining flow matching and depth priors for efficient navigation,
S. Gode, A. Nayak, D. N. Oliveira, M. Krawez, C. Schmid, and W. Burgard, “Flownav: Combining flow matching and depth priors for efficient navigation,” in2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2025, pp. 17 762–17 768
2025
-
[34]
Stepnav: Structured trajectory priors for efficient and multimodal visual navigation,
X. Luo, A. Wu, H. Han, X. Wan, W. Zhang, L. Shu, and R. Wang, “Stepnav: Structured trajectory priors for efficient and multimodal visual navigation,”arXiv preprint arXiv:2602.02590, 2026
-
[35]
arXiv preprint arXiv:2307.03672 , year=
A. Tong, N. Malkin, K. Fatras, L. Atanackovic, Y . Zhang, G. Huguet, G. Wolf, and Y . Bengio, “Simulation-free Schr¨odinger bridges via score and flow matching,”arXiv preprint arXiv:2307.03672, 2023
-
[36]
Switched flow matching: Eliminating singularities via switching odes,
Q. Zhu and W. Lin, “Switched flow matching: Eliminating singularities via switching odes,”arXiv preprint arXiv:2405.11605, 2024
-
[37]
Entropic and displacement interpolation: a computational approach using the Hilbert metric,
Y . Chen, T. Georgiou, and M. Pavon, “Entropic and displacement interpolation: a computational approach using the Hilbert metric,”SIAM Journal on Applied Mathematics, vol. 76, no. 6, pp. 2375–2396, 2016
2016
-
[38]
Score-Based Generative Modeling through Stochastic Differential Equations
Y . Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, and B. Poole, “Score-based generative modeling through stochastic differ- ential equations,”arXiv preprint arXiv:2011.13456, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[39]
Flow matching for generative modeling,
Y . Lipman, R. T. Chen, H. Ben-Hamu, M. Nickel, and M. Le, “Flow matching for generative modeling,” inInternational Conference on Learning Representations, 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.