Recognition: 2 theorem links
· Lean TheoremScientific Graphics Program Synthesis via Dual Self-Consistency Reinforcement Learning
Pith reviewed 2026-05-10 19:40 UTC · model grok-4.3
The pith
Dual self-consistency reinforcement learning lets an 8B model generate accurate TikZ code for scientific graphics and outperform much larger models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper shows that an Execution-Centric Data Engine can produce SciTikZ-230K strictly executable and visually aligned image-TikZ pairs across eleven disciplines, and that Dual Self-Consistency Reinforcement Learning with Round-Trip Verification can optimize a model to penalize degenerate outputs and raise overall consistency, allowing the resulting SciTikZer-8B model to reach state-of-the-art performance that surpasses Gemini-2.5-Pro and Qwen3-VL-235B-A22B-Instruct on both visual fidelity and structural logic.
What carries the argument
Dual Self-Consistency Reinforcement Learning optimization paradigm that applies Round-Trip Verification to penalize degenerate code and raise self-consistency in the generated TikZ programs.
If this is right
- High-quality executable image-TikZ datasets can be scaled across scientific domains to support further model training.
- Multifaceted benchmarks that separately score visual alignment and logical structure can become standard for graphics synthesis.
- Reinforcement learning with consistency verification can improve code output from multimodal models without requiring extreme parameter counts.
- Generated TikZ code can be used directly for precise rendering and editing of complex hierarchical scientific schematics.
Where Pith is reading between the lines
- The same round-trip verification pattern could be applied to synthesize code for other diagram languages or plotting libraries.
- Targeted consistency reinforcement may prove more efficient than raw scale for narrow-domain code generation tasks.
- Automated conversion of figures from published papers into editable code could become practical for reproducibility checks.
- Testing the trained model on figures extracted from recent journal articles would show whether the benchmark gains transfer to real research outputs.
Load-bearing premise
The Execution-Centric Data Engine produces image-TikZ pairs that are strictly executable and visually aligned, and the round-trip verification step in reinforcement learning improves consistency without introducing new biases or degenerate solutions.
What would settle it
Direct evaluation of SciTikZer-8B on SciTikZ-Bench showing lower scores than Gemini-2.5-Pro or Qwen3-VL-235B on combined visual-fidelity and structural-logic metrics would disprove the claimed superiority.
Figures










read the original abstract
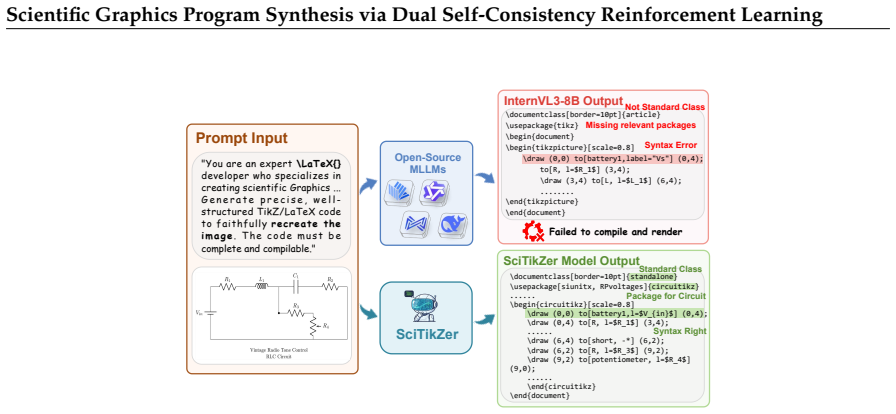
Graphics Program Synthesis is pivotal for interpreting and editing visual data, effectively facilitating the reverse-engineering of static visuals into editable TikZ code. While TikZ is the de facto standard for scientific schematics due to its programmatic flexibility, its requirement for rigorous spatial precision presents a significant challenge for Multimodal Large Language Models. Progress is currently stifled by two primary gaps: (1) Data Quality Gap: existing image-TikZ corpora often lack strict executability and reliable visual alignment; (2) Evaluation Gap: a lack of benchmarks for both structural and visual fidelity. To address these, we present a closed-loop framework featuring: SciTikZ-230K, a large-scale, high-quality dataset from our Execution-Centric Data Engine covering 11 diverse scientific disciplines; SciTikZ-Bench, a multifaceted benchmark spanning from basic geometric constructs to intricate hierarchical schematics to evaluate both visual fidelity and structural logic. To further broaden the scope of visual-code optimization methodology, we introduce a novel Dual Self-Consistency Reinforcement Learning optimization paradigm, which utilizes Round-Trip Verification to penalize degenerate code and boost overall self-consistency. Empowered by these, our trained model SciTikZer-8B achieves state-of-the-art performance, consistently outperforming proprietary giants like Gemini-2.5-Pro and massive models like Qwen3-VL-235B-A22B-Instruct.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to address data quality and evaluation gaps in graphics program synthesis by introducing an Execution-Centric Data Engine that produces the SciTikZ-230K dataset of executable image-TikZ pairs across 11 disciplines, the SciTikZ-Bench for assessing structural and visual fidelity, and a Dual Self-Consistency Reinforcement Learning paradigm that uses Round-Trip Verification to train SciTikZer-8B, which reportedly achieves SOTA by outperforming Gemini-2.5-Pro and Qwen3-VL-235B-A22B-Instruct.
Significance. If the closed-loop verification proves robust, the work would be significant by supplying a large-scale executable dataset and multifaceted benchmark that the field currently lacks, plus a novel RL objective for boosting self-consistency in code generation. These resources could enable more reliable training and assessment of MLLMs for precise scientific visualization reverse-engineering.
major comments (2)
- [§3] §3 (Execution-Centric Data Engine and SciTikZ-Bench): both the 230K training set and the benchmark are generated by the same engine, so any systematic rendering mismatch (coordinate drift, missing labels, style artifacts) would be invisible to Round-Trip Verification yet would inflate all reported metrics; the manuscript must show that verification detects such misalignments.
- [§4] §4 (Dual Self-Consistency RL and Round-Trip Verification): the claim that the RL objective reliably penalizes degenerate yet compilable solutions and boosts true visual fidelity lacks supporting ablations or analysis demonstrating it avoids semantic drift; without external real-world figures or human preference studies, the SOTA claim on SciTikZ-Bench rests on an untested internal loop.
minor comments (1)
- [Abstract] Abstract: the SOTA claim is stated without any quantitative metrics, error bars, or comparison details, which would allow readers to assess the headline result immediately.
Simulated Author's Rebuttal
We thank the referee for their detailed and insightful comments on our manuscript. We address each major comment below and outline the revisions we plan to make to improve the clarity and robustness of our work.
read point-by-point responses
-
Referee: [§3] §3 (Execution-Centric Data Engine and SciTikZ-Bench): both the 230K training set and the benchmark are generated by the same engine, so any systematic rendering mismatch (coordinate drift, missing labels, style artifacts) would be invisible to Round-Trip Verification yet would inflate all reported metrics; the manuscript must show that verification detects such misalignments.
Authors: We agree that this is an important consideration to ensure the reliability of our closed-loop system. The Execution-Centric Data Engine incorporates multiple checks for executability and visual alignment during generation. To directly address the concern, we will include in the revised manuscript an experiment that injects synthetic misalignments (such as coordinate drifts and missing elements) into TikZ code and demonstrates that the Round-Trip Verification successfully identifies and filters these cases, preventing them from affecting the metrics. revision: yes
-
Referee: [§4] §4 (Dual Self-Consistency RL and Round-Trip Verification): the claim that the RL objective reliably penalizes degenerate yet compilable solutions and boosts true visual fidelity lacks supporting ablations or analysis demonstrating it avoids semantic drift; without external real-world figures or human preference studies, the SOTA claim on SciTikZ-Bench rests on an untested internal loop.
Authors: We thank the referee for highlighting this. Our manuscript does include ablation studies in §4 comparing the Dual Self-Consistency RL against baselines and variants, showing consistent gains in both structural accuracy and visual similarity metrics on SciTikZ-Bench. These ablations help demonstrate the objective's effectiveness in penalizing degenerate solutions. However, we acknowledge that further analysis specifically targeting semantic drift would be beneficial. We will expand the ablation section in the revision to include additional metrics and case studies illustrating how the RL avoids semantic inconsistencies. Regarding external real-world figures and human preference studies, while SciTikZ-Bench draws from diverse scientific domains to simulate real-world scenarios, comprehensive human evaluations are resource-intensive and were not conducted in this work. We believe the multifaceted benchmark provides a strong proxy for visual fidelity. revision: partial
- Comprehensive human preference studies on external real-world figures, which would require significant additional experimental resources beyond the scope of this revision.
Circularity Check
No significant circularity detected
full rationale
The paper's core contributions—an Execution-Centric Data Engine for generating SciTikZ-230K, the SciTikZ-Bench, and the Dual Self-Consistency RL paradigm with Round-Trip Verification—are presented as empirical engineering steps leading to a trained model whose performance is measured on the benchmark. No equations, derivations, or claims reduce by construction to their own inputs (e.g., no fitted parameters renamed as predictions, no self-definitional loops, and no load-bearing self-citations of uniqueness theorems). The SOTA claim is an external empirical outcome relative to other models, not a tautological restatement of the training procedure. The internal generation of data and benchmark raises separate validity questions but does not constitute circularity under the defined patterns.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Dual Self-Consistency Reinforcement Learning ... Round-Trip Verification to penalize degenerate code and boost overall self-consistency
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
SciTikZ-230K ... Execution-Centric Data Engine
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
LMMs Meet Object-Centric Vision: Understanding, Segmentation, Editing and Generation
This review organizes literature on large multimodal models and object-centric vision into four themes—understanding, referring segmentation, editing, and generation—while summarizing paradigms, strategies, and challe...
Reference graph
Works this paper leans on
-
[1]
Claude sonnet 4.5 system card.https://www.anthropic.com/system-cards, 2025
Anthropic. Claude sonnet 4.5 system card.https://www.anthropic.com/system-cards, 2025
2025
-
[2]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond.arXiv preprint arXiv:2308.12966, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report.ar...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Jonas Belouadi, Anne Lauscher, and Steffen Eger. Automatikz: Text-guided synthesis of scientific vector graphics with tikz.arXiv preprint arXiv:2310.00367, 2023
-
[6]
Detikzify: Synthesizing graphics programs for scientific figures and sketches with tikz.Advances in Neural Information Processing Systems, 37:85074–85108, 2024
Jonas Belouadi, Simone Ponzetto, and Steffen Eger. Detikzify: Synthesizing graphics programs for scientific figures and sketches with tikz.Advances in Neural Information Processing Systems, 37:85074–85108, 2024
2024
-
[7]
Tikzero: Zero-shot text-guided graphics program synthesis
Jonas Belouadi, Eddy Ilg, Margret Keuper, Hideki Tanaka, Masao Utiyama, Raj Dabre, Steffen Eger, and Simone Ponzetto. Tikzero: Zero-shot text-guided graphics program synthesis. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 17793–17806, 2025
2025
-
[8]
Learning to synthesize graphics programs for geometric artworks
Qi Bing, Chaoyi Zhang, and Weidong Cai. Learning to synthesize graphics programs for geometric artworks. InInternational Conference on Pattern Recognition, pages 259–274. Springer, 2025
2025
-
[9]
Lukas Blecher, Guillem Cucurull, Thomas Scialom, Robert Stojnic, and M Ai. Nougat: Neural optical understanding for academic documents, 2023.arXiv preprint arXiv:2308.13418
-
[10]
Yang Chen, Yufan Shen, Wenxuan Huang, Sheng Zhou, Qunshu Lin, Xinyu Cai, Zhi Yu, Jiajun Bu, Botian Shi, and Yu Qiao. Learning only with images: Visual reinforcement learning with reasoning, rendering, and visual feedback.arXiv preprint arXiv:2507.20766, 2025
-
[11]
Zhe Chen, Weiyun Wang, Yue Cao, Yangzhou Liu, Zhangwei Gao, Erfei Cui, Jinguo Zhu, Shenglong Ye, Hao Tian, Zhaoyang Liu, et al. Expanding performance boundaries of open-source multimodal models with model, data, and test-time scaling.arXiv preprint arXiv:2412.05271, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Internvl: Scaling up vision foundation models and aligning for generic visual- linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vision foundation models and aligning for generic visual- linguistic tasks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 24185–24198, 2024
2024
-
[13]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Image-to-markup generation with coarse-to-fine attention
Yuntian Deng, Anssi Kanervisto, Jeffrey Ling, and Alexander M Rush. Image-to-markup generation with coarse-to-fine attention. InInternational Conference on Machine Learning, pages 980–989. PMLR, 2017
2017
-
[15]
Crystalbleu: precisely and efficiently measuring the similarity of code
Aryaz Eghbali and Michael Pradel. Crystalbleu: precisely and efficiently measuring the similarity of code. In Proceedings of the 37th IEEE/ACM International Conference on Automated Software Engineering, pages 1–12, 2022. 15 Scientific Graphics Program Synthesis via Dual Self-Consistency Reinforcement Learning
2022
-
[16]
GRIT: Teaching MLLMs to Think with Images
Yue Fan, Xuehai He, Diji Yang, Kaizhi Zheng, Ching-Chen Kuo, Yuting Zheng, Sravana Jyothi Narayanaraju, Xinze Guan, and Xin Eric Wang. Grit: Teaching mllms to think with images.arXiv preprint arXiv:2505.15879, 2025
work page internal anchor Pith review arXiv 2025
-
[17]
Rlef: Grounding code llms in execution feedback with reinforcement learning
Jonas Gehring, Kunhao Zheng, Jade Copet, Vegard Mella, Quentin Carbonneaux, Taco Cohen, and Gabriel Synnaeve. Rlef: Grounding code llms in execution feedback with reinforcement learning.arXiv preprint arXiv:2410.02089, 2024
-
[18]
Chartllama: A multimodal llm for chart understanding and generation, 2023
Yucheng Han, Chi Zhang, Xin Chen, Xu Yang, Zhibin Wang, Gang Yu, Bin Fu, and Hanwang Zhang. Chartllama: A multimodal llm for chart understanding and generation, 2023
2023
-
[19]
Dual learning for machine translation.Advances in neural information processing systems, 29, 2016
Di He, Yingce Xia, Tao Qin, Liwei Wang, Nenghai Yu, Tie-Yan Liu, and Wei-Ying Ma. Dual learning for machine translation.Advances in neural information processing systems, 29, 2016
2016
-
[20]
Visual sketchpad: Sketching as a visual chain of thought for multimodal language models.Advances in Neural Information Processing Systems, 37:139348–139379, 2024
Yushi Hu, Weijia Shi, Xingyu Fu, Dan Roth, Mari Ostendorf, Luke Zettlemoyer, Noah A Smith, and Ranjay Krishna. Visual sketchpad: Sketching as a visual chain of thought for multimodal language models.Advances in Neural Information Processing Systems, 37:139348–139379, 2024
2024
-
[21]
Vision-R1: Incentivizing Reasoning Capability in Multimodal Large Language Models
Wenxuan Huang, Bohan Jia, Zijie Zhai, Shaosheng Cao, Zheyu Ye, Fei Zhao, Zhe Xu, Yao Hu, and Shaohui Lin. Vision-r1: Incentivizing reasoning capability in multimodal large language models.arXiv preprint arXiv:2503.06749, 2025
work page internal anchor Pith review arXiv 2025
-
[22]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Self-training large language models for improved visual program synthesis with visual reinforcement
Zaid Khan, Vijay Kumar BG, Samuel Schulter, Yun Fu, and Manmohan Chandraker. Self-training large language models for improved visual program synthesis with visual reinforcement. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14344–14353, 2024
2024
-
[24]
Imagenet classification with deep convolutional neural networks.Advances in neural information processing systems, 25, 2012
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolutional neural networks.Advances in neural information processing systems, 25, 2012
2012
-
[25]
Tikzilla: Scaling text-to-tikz with high-quality data and reinforcement learning
REINFORCEMENT LEARNING. Tikzilla: Scaling text-to-tikz with high-quality data and reinforcement learning
-
[26]
Metal: A multi-agent framework for chart generation with test-time scaling, 2025
Bingxuan Li, Yiwei Wang, Jiuxiang Gu, Kai-Wei Chang, and Nanyun Peng. Metal: A multi-agent framework for chart generation with test-time scaling, 2025. URLhttps://arxiv.org/abs/2502.17651
-
[27]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Yanwei Li, Ziwei Liu, and Chunyuan Li. Llava-onevision: Easy visual task transfer.arXiv preprint arXiv:2408.03326, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Differentiable vector graphics rasterization for editing and learning.ACM Transactions on Graphics (TOG), 39(6):1–15, 2020
Tzu-Mao Li, Michal Luk ´aˇc, Micha ¨el Gharbi, and Jonathan Ragan-Kelley. Differentiable vector graphics rasterization for editing and learning.ACM Transactions on Graphics (TOG), 39(6):1–15, 2020
2020
-
[29]
Mmfinereason: Closing the multimodal reasoning gap via open data-centric methods, 2026
Honglin Lin, Zheng Liu, Yun Zhu, Chonghan Qin, Juekai Lin, Xiaoran Shang, Conghui He, Wentao Zhang, and Lijun Wu. Mmfinereason: Closing the multimodal reasoning gap via open data-centric methods, 2026. URLhttps://arxiv.org/abs/2601.21821
-
[30]
Deplot: One-shot visual language reasoning by plot-to-table translation
Fangyu Liu, Julian Eisenschlos, Francesco Piccinno, Syrine Krichene, Chenxi Pang, Kenton Lee, Mandar Joshi, Wenhu Chen, Nigel Collier, and Yasemin Altun. Deplot: One-shot visual language reasoning by plot-to-table translation. InFindings of the Association for Computational Linguistics: ACL 2023, pages 10381–10399, 2023
2023
-
[31]
Haoyu Liu, Daya Guo, Junzhao Zheng, J.L. Wang, et al. Deepseek-vl2: Mixture-of-experts vision-language models for advanced multimodal understanding.arXiv preprint arXiv:2412.13602, 2024
-
[32]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InProceedings of the 7th Interna- tional Conference on Learning Representations (ICLR). OpenReview.net, 2019. URL https://openreview.net/ forum?id=Bkg6RiCqY7
2019
-
[33]
Chart2code53: A large-scale diverse and complex dataset for enhancing chart-to-code generation
Tianhao Niu, Yiming Cui, Baoxin Wang, Xiao Xu, Xin Yao, Qingfu Zhu, Dayong Wu, Shijin Wang, and Wanxiang Che. Chart2code53: A large-scale diverse and complex dataset for enhancing chart-to-code generation. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 15839–15855, 2025. 16 Scientific Graphics Program Synth...
2025
-
[34]
Image2struct: A benchmark for evaluating vision-language models in extracting structured information from images, 2024
Josselin Somerville Roberts, Tony Lee, Chi Heem Wong, Michihiro Yasunaga, Yifan Mai, and Percy Liang. Image2struct: A benchmark for evaluating vision-language models in extracting structured information from images, 2024
2024
-
[35]
A., Zhang, H., Puri, A., Feizi, A., Pramanik, R., Wichmann, P., Mondal, A., Samsami, M
Juan A Rodriguez, Haotian Zhang, Abhay Puri, Aarash Feizi, Rishav Pramanik, Pascal Wichmann, Arnab Mondal, Mohammad Reza Samsami, Rabiul Awal, Perouz Taslakian, et al. Rendering-aware reinforcement learning for vector graphics generation, 2025.URL https://arxiv. org/abs/2505.20793
-
[36]
Sketch2diagram: Generating vector diagrams from hand-drawn sketches
Itsumi Saito, Haruto Yoshida, and Keisuke Sakaguchi. Sketch2diagram: Generating vector diagrams from hand-drawn sketches. In13th International Conference on Learning Representations, ICLR 2025, pages 52825– 52847. International Conference on Learning Representations, ICLR, 2025
2025
-
[37]
Vispath: Automated visualization code synthesis via multi-path reasoning and feedback-driven optimization.arXiv e-prints, pages arXiv–2502, 2025
Wonduk Seo, Seungyong Lee, Daye Kang, Zonghao Yuan, and Seunghyun Lee. Vispath: Automated visualization code synthesis via multi-path reasoning and feedback-driven optimization.arXiv e-prints, pages arXiv–2502, 2025
2025
-
[38]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Y Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models, 2024.URL https://arxiv. org/abs/2402.03300, 2(3):5, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
HybridFlow: A Flexible and Efficient RLHF Framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework.arXiv preprint arXiv: 2409.19256, 2024
work page internal anchor Pith review arXiv 2024
-
[40]
Eed: Extended edit distance measure for machine translation
Peter Stanchev, Weiyue Wang, and Hermann Ney. Eed: Extended edit distance measure for machine translation. InProceedings of the Fourth Conference on Machine Translation (Volume 2: Shared Task Papers, Day 1), pages 514–520, 2019
2019
-
[41]
Zhaochen Su, Linjie Li, Mingyang Song, Yunzhuo Hao, Zhengyuan Yang, Jun Zhang, Guanjie Chen, Jiawei Gu, Juntao Li, Xiaoye Qu, et al. Openthinkimg: Learning to think with images via visual tool reinforcement learning, 2025.URL https://arxiv. org/abs/2505.08617
-
[42]
Vipergpt: Visual inference via python execution for reasoning
D´ıdac Sur´ıs, Sachit Menon, and Carl Vondrick. Vipergpt: Visual inference via python execution for reasoning. InProceedings of the IEEE/CVF international conference on computer vision, pages 11888–11898, 2023
2023
-
[43]
Graph drawing in ti k z
Till Tantau. Graph drawing in ti k z. InInternational Symposium on Graph Drawing, pages 517–528. Springer, 2012
2012
-
[44]
Ke Wang, Junting Pan, Linda Wei, Aojun Zhou, Weikang Shi, Zimu Lu, Han Xiao, Yunqiao Yang, Houxing Ren, Mingjie Zhan, et al. Mathcoder-vl: Bridging vision and code for enhanced multimodal mathematical reasoning.arXiv preprint arXiv:2505.10557, 2025
-
[45]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Yang Fan, Kai Dang, Mengfei Du, Xuancheng Ren, Rui Men, Dayiheng Liu, Chang Zhou, Jingren Zhou, and Junyang Lin. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[46]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
Plot2code: A comprehensive benchmark for evaluating multi-modal large language models in code generation from scientific plots
Chengyue Wu, Zhixuan Liang, Yixiao Ge, Qiushan Guo, Zeyu Lu, Jiahao Wang, Ying Shan, and Ping Luo. Plot2code: A comprehensive benchmark for evaluating multi-modal large language models in code generation from scientific plots. InFindings of the Association for Computational Linguistics: NAACL 2025, pages 3006–3028, 2025
2025
-
[48]
Davinci: Reinforcing visual-structural syntax in mllms for generalized scientific diagram parsing
ZENG Xingchen, Zhewei Su, Hengming Zhang, Juyong Jiang, Jiazhi Xia, and Wei Zeng. Davinci: Reinforcing visual-structural syntax in mllms for generalized scientific diagram parsing. InThe Fourteenth International Conference on Learning Representations
-
[49]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025. 17 Scientific Graphics Program Synthesis via Dual Self-Consistency Reinforcement Learning
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[50]
Cheng Yang, Chufan Shi, Yaxin Liu, Bo Shui, Junjie Wang, Mohan Jing, Linran Xu, Xinyu Zhu, Siheng Li, Yuxiang Zhang, et al. Chartmimic: Evaluating lmm’s cross-modal reasoning capability via chart-to-code generation.arXiv preprint arXiv:2406.09961, 2024
-
[51]
Matplotagent: Method and evaluation for llm-based agentic scientific data visualization
Zhiyu Yang, Zihan Zhou, Shuo Wang, Xin Cong, Xu Han, Yukun Yan, Zhenghao Liu, Zhixing Tan, Pengyuan Liu, Dong Yu, et al. Matplotagent: Method and evaluation for llm-based agentic scientific data visualization. arXiv preprint arXiv:2402.11453, 2024
-
[52]
Weihao Zeng, Yuzhen Huang, Qian Liu, Wei Liu, Ke- qing He, Zejun Ma, and Junxian He
Hiroshi Yoshihara, Taiki Yamaguchi, and Yuichi Inoue. A practical two-stage recipe for mathematical llms: Maximizing accuracy with sft and efficiency with reinforcement learning.arXiv preprint arXiv:2507.08267, 2025
-
[53]
Sigmoid loss for language image pre-training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. InProceedings of the IEEE/CVF international conference on computer vision, pages 11975–11986, 2023
2023
-
[54]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 586–595, 2018
2018
-
[55]
Xuanle Zhao, Deyang Jiang, Zhixiong Zeng, Lei Chen, Haibo Qiu, Jing Huang, Yufeng Zhong, Liming Zheng, Yilin Cao, and Lin Ma. Vincicoder: Unifying multimodal code generation via coarse-to-fine visual reinforcement learning.arXiv preprint arXiv:2511.00391, 2025
-
[56]
Xuanle Zhao, Xuexin Liu, Haoyue Yang, Xianzhen Luo, Fanhu Zeng, Jianling Li, Qi Shi, and Chi Chen. Chartedit: How far are mllms from automating chart analysis? evaluating mllms’ capability via chart editing. arXiv preprint arXiv:2505.11935, 2025
-
[57]
Xuanle Zhao, Xianzhen Luo, Qi Shi, Chi Chen, Shuo Wang, Zhiyuan Liu, and Maosong Sun. Chartcoder: Advancing multimodal large language model for chart-to-code generation.arXiv preprint arXiv:2501.06598, 2025
-
[58]
Llamafactory: Unified efficient fine-tuning of 100+ language models
Yaowei Zheng, Richong Zhang, Junhao Zhang, Yanhan Ye, Zheyan Luo, Zhangchi Feng, and Yongqiang Ma. Llamafactory: Unified efficient fine-tuning of 100+ language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations), Bangkok, Thailand,
-
[59]
LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models
Association for Computational Linguistics. URLhttp://arxiv.org/abs/2403.13372
work page internal anchor Pith review arXiv
-
[60]
Easyr1: An efficient, scalable, multi-modality rl training framework.https://github.com/hiyouga/EasyR1, 2025
Yaowei Zheng, Junting Lu, Shenzhi Wang, Zhangchi Feng, Dongdong Kuang, and Yuwen Xiong. Easyr1: An efficient, scalable, multi-modality rl training framework.https://github.com/hiyouga/EasyR1, 2025
2025
-
[61]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479, 2025. 18 Scientific Graphics Program Synthesis via Dual Self-Consistency Reinforcement Learning Appendix ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[62]
5.Self-contained.Remove/disable external dependencies (\includegraphics,\input,.bib, file paths)
Layout fix (only if needed).If standalone wrapping shifts layout/clipping, apply minimal local fixes (e.g., border,baseline, missing libraries, minimal macro/color defs). 5.Self-contained.Remove/disable external dependencies (\includegraphics,\input,.bib, file paths). Image reference. <IMAGE START> {image} <IMAGE END> Code to standardize. <CODE START> {co...
-
[63]
correctness
Minimal edits.Fix only what the error indicates (e.g., missing packages/commands, missing files, fragment wrappers). Keep coordinates and drawing commands unchanged whenever possible. Compilation error excerpt. <ERROR START> {error} <ERROR END> Code to repair. <CODE START> {code} <CODE END> \documentclass[border=5pt]{standalone} \usepackage{tikz} \usetikz...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.