Recognition: unknown
ViVa: A Video-Generative Value Model for Robot Reinforcement Learning
Pith reviewed 2026-05-10 17:07 UTC · model grok-4.3
The pith
ViVa repurposes a pretrained video generator to estimate robot value by jointly predicting future proprioception and a scalar progress signal from the current state.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ViVa is a video-generative value model that, taking current observation and robot proprioception as input, jointly predicts future proprioception and a scalar value for the current state. By leveraging the spatiotemporal priors of a pretrained video generator, the approach grounds value estimation in anticipated embodiment dynamics, moving beyond static snapshots to intrinsically couple value with foresight. Integrated into RECAP, ViVa delivers substantial improvements on real-world box assembly, and qualitative checks across tasks show value signals that accurately track progress while generalizing to novel objects.
What carries the argument
A pretrained video generator repurposed to output both a future proprioception sequence and a scalar value estimate from the current visual observation and robot state.
If this is right
- Value signals become tied to predicted future states and therefore track task progress more accurately than static-image estimates.
- When inserted into an existing reinforcement learning framework like RECAP, the model produces measurable gains on physical box-assembly tasks.
- The same architecture generalizes to novel objects by drawing on priors learned from broad video corpora.
- Partial observability and delayed feedback in vision-language-action policies are mitigated because value now incorporates explicit foresight.
Where Pith is reading between the lines
- The same video-generator backbone could be tested as a dynamics model or planner in addition to its value role.
- Performance on a broader set of long-horizon manipulation benchmarks would clarify whether the foresight benefit is specific to assembly or applies more widely.
- If video priors already encode useful embodiment structure, similar repurposing might reduce the need for large robot-specific datasets in other learning modules.
Load-bearing premise
The spatiotemporal priors learned from general video data transfer effectively to robot proprioception sequences and produce reliable scalar value estimates for long-horizon manipulation without additional fine-tuning.
What would settle it
A controlled comparison showing that ViVa value estimates do not improve policy performance over standard VLM-based values on the same long-horizon assembly tasks, or that the predicted values fail to correlate with measured task progress.
Figures







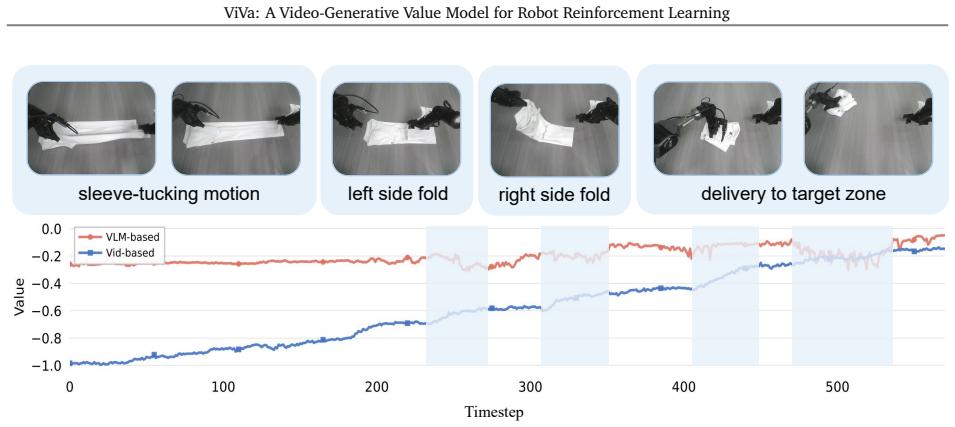



read the original abstract
Vision-language-action (VLA) models have advanced robot manipulation through large-scale pretraining, but real-world deployment remains challenging due to partial observability and delayed feedback. Reinforcement learning addresses this via value functions, which assess task progress and guide policy improvement. However, existing value models built on vision-language models (VLMs) struggle to capture temporal dynamics, undermining reliable value estimation in long-horizon tasks. In this paper, we propose ViVa, a video-generative value model that repurposes a pretrained video generator for value estimation. Taking the current observation and robot proprioception as input, ViVa jointly predicts future proprioception and a scalar value for the current state. By leveraging the spatiotemporal priors of a pretrained video generator, our approach grounds value estimation in anticipated embodiment dynamics, moving beyond static snapshots to intrinsically couple value with foresight. Integrated into RECAP, ViVa delivers substantial improvements on real-world box assembly. Qualitative analysis across all three tasks confirms that ViVa produces more reliable value signals, accurately reflecting task progress. By leveraging spatiotemporal priors from video corpora, ViVa also generalizes to novel objects, highlighting the promise of video-generative models for value estimation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ViVa, a video-generative value model for robot reinforcement learning. It repurposes a pretrained video generator to take current visual observations and robot proprioception as input and jointly output future proprioception sequences together with a scalar value estimate. This is integrated into the RECAP RL framework, with the central claim that spatiotemporal priors from general video data ground value estimation in anticipated embodiment dynamics, yielding substantial improvements on real-world box assembly, more reliable value signals that track task progress, and generalization to novel objects.
Significance. If the transfer of video priors to robot proprioception holds and the performance gains are robust, the work could meaningfully advance value-function design in long-horizon robot RL by replacing static VLM snapshots with dynamic, foresight-coupled estimates. The real-world deployment focus and claimed generalization are relevant to the field.
major comments (2)
- [Abstract and Experiments] Abstract and Experiments section: the abstract asserts 'substantial improvements' on real-world box assembly, 'qualitative analysis across all three tasks,' and generalization to novel objects, yet supplies no quantitative metrics, baselines, ablation studies, or error bars. Without these, it is impossible to assess whether the reported gains are statistically reliable or sensitive to post-hoc choices.
- [Method] Method section (model architecture and input handling): the central claim rests on the assumption that a video generator pretrained on general video corpora can directly ingest low-dimensional robot proprioception (joint positions/velocities) and produce reliable future sequences plus scalar values without fine-tuning or task-specific adaptation. No description is given of input embedding, output head for the scalar value, or any robot-data training, making the transfer step load-bearing and unverified.
minor comments (2)
- [Method] Clarify in the method how the scalar value is extracted from the video generator (separate linear head, reconstruction loss term, or other mechanism).
- [Experiments] Ensure all experimental figures include quantitative value curves or task-progress correlations rather than purely qualitative examples.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and will revise the manuscript to improve technical clarity and evidentiary support.
read point-by-point responses
-
Referee: [Abstract and Experiments] Abstract and Experiments section: the abstract asserts 'substantial improvements' on real-world box assembly, 'qualitative analysis across all three tasks,' and generalization to novel objects, yet supplies no quantitative metrics, baselines, ablation studies, or error bars. Without these, it is impossible to assess whether the reported gains are statistically reliable or sensitive to post-hoc choices.
Authors: We agree that the abstract and experiments section would be strengthened by explicit quantitative metrics, baselines, ablations, and error bars. The current manuscript emphasizes qualitative analysis of value signals and task progress across the three tasks, along with real-world deployment results, but we acknowledge that these elements alone do not fully address statistical reliability. In the revision we will add key quantitative performance numbers, baseline comparisons, and error bars to the abstract and expand the experiments section with the corresponding ablations and statistical details. revision: yes
-
Referee: [Method] Method section (model architecture and input handling): the central claim rests on the assumption that a video generator pretrained on general video corpora can directly ingest low-dimensional robot proprioception (joint positions/velocities) and produce reliable future sequences plus scalar values without fine-tuning or task-specific adaptation. No description is given of input embedding, output head for the scalar value, or any robot-data training, making the transfer step load-bearing and unverified.
Authors: The referee is correct that the Method section requires additional technical detail on the proprioception integration. The pretrained video generator is used to forecast future visual and proprioceptive sequences, with an attached scalar value head. We will expand the Method section to describe the proprioception embedding (projection of joint positions/velocities into the model's input space), the architecture of the value output head, and the training procedure used for the value component on robot data. This will make the transfer mechanism explicit and verifiable. revision: yes
Circularity Check
No significant circularity; value estimation grounded in external pretrained video priors
full rationale
The paper's core derivation repurposes an external pretrained video generator (trained on general video corpora) to jointly predict future proprioception sequences and a scalar value from current observations and robot proprioception. This grounds the value in anticipated dynamics via spatiotemporal priors without any self-definitional loop, fitted-input-as-prediction reduction, or load-bearing self-citation chain. No equations or steps in the abstract or described approach reduce the claimed foresight-coupled value to the inputs by construction; the method is presented as an application of an independent pretrained model, with performance claims tied to real-world box assembly experiments rather than internal consistency. The integration into RECAP is described as an empirical extension, not a self-justifying premise.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pretrained video generators encode transferable spatiotemporal priors for robot proprioception and manipulation dynamics
Reference graph
Works this paper leans on
-
[1]
Cosmos World Foundation Model Platform for Physical AI
Niket Agarwal, Arslan Ali, Maciej Bala, Yogesh Balaji, Erik Barker, Tiffany Cai, Prithvijit Chattopadhyay, Yongxin Chen, Yin Cui, Yifan Ding, et al. Cosmos world foundation model platform for physical ai.arXiv preprint arXiv:2501.03575, 2025. 5
work page internal anchor Pith review arXiv 2025
-
[2]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
All are worth words: A vit backbone for diffusion models
Fan Bao, Shen Nie, Kaiwen Xue, Yue Cao, Chongxuan Li, Hang Su, and Jun Zhu. All are worth words: A vit backbone for diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 22669–22679, 2023. 3
2023
-
[4]
Gen2Act: Human Video Generation in Novel Scenarios enables Generalizable Robot Manipulation
Homanga Bharadhwaj, Debidatta Dwibedi, Abhinav Gupta, Shubham Tulsiani, Carl Doersch, Ted Xiao, Dhruv Shah, Fei Xia, Dorsa Sadigh, and Sean Kirmani. Gen2act: Human video generation in novel scenarios enables generalizable robot manipulation.arXiv preprint arXiv:2409.16283, 2024. 4
work page internal anchor Pith review arXiv 2024
-
[5]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram Voleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023. 3
work page internal anchor Pith review arXiv 2023
-
[6]
Pix2video: Video editing using image diffusion
Duygu Ceylan, Chun-Hao P Huang, and Niloy J Mitra. Pix2video: Video editing using image diffusion. In Proceedings of the IEEE/CVF international conference on computer vision, pages 23206–23217, 2023. 3
2023
-
[7]
GR-2: A Generative Video-Language-Action Model with Web-Scale Knowledge for Robot Manipulation
Chi-Lam Cheang, Guangzeng Chen, Ya Jing, Tao Kong, Hang Li, Yifeng Li, Yuxiao Liu, Hongtao Wu, Jiafeng Xu, Yichu Yang, et al. Gr-2: A generative video-language-action model with web-scale knowledge for robot manipulation.arXiv preprint arXiv:2410.06158, 2024. 3
work page internal anchor Pith review arXiv 2024
-
[8]
Spa- tialvlm: Endowing vision-language models with spatial reasoning capabilities
Boyuan Chen, Zhuo Xu, Sean Kirmani, Brain Ichter, Dorsa Sadigh, Leonidas Guibas, and Fei Xia. Spa- tialvlm: Endowing vision-language models with spatial reasoning capabilities. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14455–14465, 2024. 2
2024
-
[9]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with ad- vanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Tenenbaum, Leslie Kaelbling, Andy Zeng, and Jonathan Tompson
Yilun Du, Mengjiao Yang, Pete Florence, Fei Xia, Ayzaan Wahid, Brian Ichter, Pierre Sermanet, Tianhe Yu, Pieter Abbeel, Joshua B Tenenbaum, et al. Video language planning.arXiv preprint arXiv:2310.10625,
-
[11]
Learning universal policies via text-guided video generation.Advances in neural information processing systems, 36:9156–9172, 2023
Yilun Du, Sherry Yang, Bo Dai, Hanjun Dai, Ofir Nachum, Josh Tenenbaum, Dale Schuurmans, and Pieter Abbeel. Learning universal policies via text-guided video generation.Advances in neural information processing systems, 36:9156–9172, 2023. 3
2023
-
[12]
Kevin Frans, Seohong Park, Pieter Abbeel, and Sergey Levine. Diffusion guidance is a controllable policy improvement operator.arXiv preprint arXiv:2505.23458, 2025. 3
-
[13]
Self- improving embodied foundation models.arXiv preprint, arXiv:2509.15155, 2025
Seyed Kamyar Seyed Ghasemipour, Ayzaan Wahid, Jonathan Tompson, Pannag Sanketi, and Igor Mor- datch. Self-improving embodied foundation models.arXiv preprint arXiv:2509.15155, 2025. 3
-
[14]
Dongchi Huang, Zhirui Fang, Tianle Zhang, Yihang Li, Lin Zhao, and Chunhe Xia. Co-rft: Efficient fine-tuning of vision-language-action models through chunked offline reinforcement learning.arXiv preprint arXiv:2508.02219, 2025. 3 14 ViVa: A Video-Generative Value Model for Robot Reinforcement Learning
-
[15]
Language models as zero-shot planners: Extracting actionable knowledge for embodied agents
Wenlong Huang, Pieter Abbeel, Deepak Pathak, and Igor Mordatch. Language models as zero-shot planners: Extracting actionable knowledge for embodied agents. InInternational conference on machine learning, pages 9118–9147. PMLR, 2022. 2
2022
-
[16]
$\pi^{*}_{0.6}$: a VLA That Learns From Experience
Physical Intelligence, Ali Amin, Raichelle Aniceto, Ashwin Balakrishna, Kevin Black, Ken Conley, Grace Connors, James Darpinian, Karan Dhabalia, Jared DiCarlo, et al.𝜋* 0.6: a vla that learns from experience. arXiv preprint arXiv:2511.14759, 2025. 2, 3, 7, 8
work page Pith review arXiv 2025
-
[17]
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, et al.𝜋0.5: a vision-language-action model with open-world generalization.arXiv preprint arXiv:2504.16054, 2025. 1, 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Scalable deep reinforcement learning for vision-based robotic manipulation
Dmitry Kalashnikov, Alex Irpan, Peter Pastor, Julian Ibarz, Alexander Herzog, Eric Jang, Deirdre Quillen, Ethan Holly, Mrinal Kalakrishnan, Vincent Vanhoucke, et al. Scalable deep reinforcement learning for vision-based robotic manipulation. InConference on robot learning, pages 651–673. PMLR, 2018. 3
2018
-
[19]
arXiv preprint arXiv:2512.22414 (2025)
Simar Kareer, Karl Pertsch, James Darpinian, Judy Hoffman, Danfei Xu, Sergey Levine, Chelsea Finn, and Suraj Nair. Emergence of human to robot transfer in vision-language-action models.arXiv preprint arXiv:2512.22414, 2025. 4
-
[20]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024. 1, 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Mastering stacking of diverse shapes with large-scale iterative reinforcement learning on real robots
Thomas Lampe, Abbas Abdolmaleki, Sarah Bechtle, Sandy H Huang, Jost Tobias Springenberg, Michael Bloesch, Oliver Groth, Roland Hafner, Tim Hertweck, Michael Neunert, et al. Mastering stacking of diverse shapes with large-scale iterative reinforcement learning on real robots. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 777...
2024
-
[23]
Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems
Sergey Levine, Aviral Kumar, George Tucker, and Justin Fu. Offline reinforcement learning: Tutorial, review, and perspectives on open problems.arXiv preprint arXiv:2005.01643, 2020. 3
work page internal anchor Pith review arXiv 2005
-
[24]
LLaVA-NeXT-Interleave: Tackling Multi-image, Video, and 3D in Large Multimodal Models
Feng Li, Renrui Zhang, Hao Zhang, Yuanhan Zhang, Bo Li, Wei Li, Zejun Ma, and Chunyuan Li. Llava-next-interleave: Tackling multi-image, video, and 3d in large multimodal models.arXiv preprint arXiv:2407.07895, 2024. 2
work page internal anchor Pith review arXiv 2024
-
[25]
Qixiu Li, Yaobo Liang, Zeyu Wang, Lin Luo, Xi Chen, Mozheng Liao, Fangyun Wei, Yu Deng, Sicheng Xu, Yizhong Zhang, et al. Cogact: A foundational vision-language-action model for synergizing cognition and action in robotic manipulation.arXiv preprint arXiv:2411.19650, 2024. 3
work page Pith review arXiv 2024
-
[26]
Wei Li, Renshan Zhang, Rui Shao, Jie He, and Liqiang Nie. Cogvla: Cognition-aligned vision-language- action model via instruction-driven routing & sparsification.arXiv preprint arXiv:2508.21046, 2025. 1
-
[27]
What matters in building vision–language–action models for generalist robots
Xinghang Li, Peiyan Li, Long Qian, Minghuan Liu, Dong Wang, Jirong Liu, Bingyi Kang, Xiao Ma, Xinlong Wang, Di Guo, et al. What matters in building vision–language–action models for generalist robots. Nature Machine Intelligence, pages 1–15, 2026. 1
2026
-
[28]
Video generators are robot policies.arXiv preprint arXiv:2508.00795, 2025
Junbang Liang, Pavel Tokmakov, Ruoshi Liu, Sruthi Sudhakar, Paarth Shah, Rares Ambrus, and Carl Vondrick. Video generators are robot policies.arXiv preprint arXiv:2508.00795, 2025. 5 15 ViVa: A Video-Generative Value Model for Robot Reinforcement Learning
-
[29]
RDT-1B: a Diffusion Foundation Model for Bimanual Manipulation
Songming Liu, Lingxuan Wu, Bangguo Li, Hengkai Tan, Huayu Chen, Zhengyi Wang, Ke Xu, Hang Su, and Jun Zhu. Rdt-1b: a diffusion foundation model for bimanual manipulation.arXiv preprint arXiv:2410.07864, 2024. 3
work page internal anchor Pith review arXiv 2024
-
[30]
Serl: A software suite for sample-efficient robotic reinforcement learning
Jianlan Luo, Zheyuan Hu, Charles Xu, You Liang Tan, Jacob Berg, Archit Sharma, Stefan Schaal, Chelsea Finn, Abhishek Gupta, and Sergey Levine. Serl: A software suite for sample-efficient robotic reinforcement learning. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 16961–16969. IEEE, 2024. 3
2024
-
[31]
Liv: Language- image representations and rewards for robotic control
Yecheng Jason Ma, Vikash Kumar, Amy Zhang, Osbert Bastani, and Dinesh Jayaraman. Liv: Language- image representations and rewards for robotic control. InInternational Conference on Machine Learning, pages 23301–23320. PMLR, 2023. 3
2023
-
[32]
Vision language models are in-context value learners
Yecheng Jason Ma, Joey Hejna, Chuyuan Fu, Dhruv Shah, Jacky Liang, Zhuo Xu, Sean Kirmani, Peng Xu, Danny Driess, Ted Xiao, et al. Vision language models are in-context value learners. InThe Thirteenth International Conference on Learning Representations, 2024. 2, 3
2024
-
[33]
Iris: Implicit reinforcement without interaction at scale for learning control from offline robot manipulation data
Ajay Mandlekar, Fabio Ramos, Byron Boots, Silvio Savarese, Li Fei-Fei, Animesh Garg, and Dieter Fox. Iris: Implicit reinforcement without interaction at scale for learning control from offline robot manipulation data. In2020 IEEE International Conference on Robotics and Automation (ICRA), pages 4414–4420. IEEE,
-
[34]
SmolVLM: Redefining small and efficient multimodal models
Andrés Marafioti, Orr Zohar, Miquel Farré, Merve Noyan, Elie Bakouch, Pedro Cuenca, Cyril Zakka, Loubna Ben Allal, Anton Lozhkov, Nouamane Tazi, et al. Smolvlm: Redefining small and efficient multimodal models.arXiv preprint arXiv:2504.05299, 2025. 2
work page internal anchor Pith review arXiv 2025
-
[35]
Alan: Autonomously exploring robotic agents in the real world.arXiv preprint arXiv:2302.06604, 2023
Russell Mendonca, Shikhar Bahl, and Deepak Pathak. Alan: Autonomously exploring robotic agents in the real world.arXiv preprint arXiv:2302.06604, 2023. 3
-
[36]
Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0
Abby O’Neill, Abdul Rehman, Abhiram Maddukuri, Abhishek Gupta, Abhishek Padalkar, Abraham Lee, Acorn Pooley, Agrim Gupta, Ajay Mandlekar, Ajinkya Jain, et al. Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 6892–6903. IEEE, 2024. 3
2024
-
[37]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023. 3
2023
-
[38]
Diffdance: Cascaded human motion diffusion model for dance generation
Qiaosong Qi, Le Zhuo, Aixi Zhang, Yue Liao, Fei Fang, Si Liu, and Shuicheng Yan. Diffdance: Cascaded human motion diffusion model for dance generation. InProceedings of the 31st ACM International Conference on Multimedia, pages 1374–1382, 2023. 3
2023
-
[39]
A reduction of imitation learning and structured prediction to no-regret online learning
Stéphane Ross, Geoffrey Gordon, and Drew Bagnell. A reduction of imitation learning and structured prediction to no-regret online learning. InProceedings of the fourteenth international conference on artificial intelligence and statistics, pages 627–635. JMLR Workshop and Conference Proceedings, 2011. 3
2011
-
[40]
arXiv preprint arXiv:2505.04769 (2025)
Ranjan Sapkota, Yang Cao, Konstantinos I Roumeliotis, and Manoj Karkee. Vision-language-action (vla) models: Concepts, progress, applications and challenges.arXiv preprint arXiv:2505.04769, 2025. 1
-
[41]
Archit Sharma, Ahmed M Ahmed, Rehaan Ahmad, and Chelsea Finn. Self-improving robots: End-to-end autonomous visuomotor reinforcement learning.arXiv preprint arXiv:2303.01488, 2023. 3
-
[42]
Make-A-Video: Text-to-Video Generation without Text-Video Data
Uriel Singer, Adam Polyak, Thomas Hayes, Xi Yin, Jie An, Songyang Zhang, Qiyuan Hu, Harry Yang, Oron Ashual, Oran Gafni, et al. Make-a-video: Text-to-video generation without text-video data.arXiv preprint arXiv:2209.14792, 2022. 3 16 ViVa: A Video-Generative Value Model for Robot Reinforcement Learning
work page internal anchor Pith review arXiv 2022
-
[43]
MIT press Cambridge, 1998
Richard S Sutton, Andrew G Barto, et al.Reinforcement learning: An introduction, volume 1. MIT press Cambridge, 1998. 2, 3
1998
-
[44]
arXiv preprint arXiv:2510.19430 (2025)
GigaBrain Team, Angen Ye, Boyuan Wang, Chaojun Ni, Guan Huang, Guosheng Zhao, Haoyun Li, Jie Li, Jiagang Zhu, Lv Feng, et al. Gigabrain-0: A world model-powered vision-language-action model.arXiv preprint arXiv:2510.19430, 2025. 7
-
[45]
GigaBrain Team, Boyuan Wang, Chaojun Ni, Guan Huang, Guosheng Zhao, Hao Li, Jie Li, Jindi Lv, Jingyu Liu, Lv Feng, et al. Gigabrain-0.5 m*: a vla that learns from world model-based reinforcement learning. arXiv preprint arXiv:2602.12099, 2026. 1
-
[46]
Octo: An Open-Source Generalist Robot Policy
Octo Model Team, Dibya Ghosh, Homer Walke, Karl Pertsch, Kevin Black, Oier Mees, Sudeep Dasari, Joey Hejna, Tobias Kreiman, Charles Xu, et al. Octo: An open-source generalist robot policy.arXiv preprint arXiv:2405.12213, 2024. 3
work page internal anchor Pith review arXiv 2024
-
[47]
Ruben Villegas, Mohammad Babaeizadeh, Pieter-Jan Kindermans, Hernan Moraldo, Han Zhang, Moham- mad Taghi Saffar, Santiago Castro, Julius Kunze, and Dumitru Erhan. Phenaki: Variable length video generation from open domain textual description.arXiv preprint arXiv:2210.02399, 2022. 3
-
[48]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025. 5
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
Unleashing Large-Scale Video Generative Pre-training for Visual Robot Manipulation
Hongtao Wu, Ya Jing, Chilam Cheang, Guangzeng Chen, Jiafeng Xu, Xinghang Li, Minghuan Liu, Hang Li, and Tao Kong. Unleashing large-scale video generative pre-training for visual robot manipulation. arXiv preprint arXiv:2312.13139, 2023. 3
work page internal anchor Pith review arXiv 2023
-
[50]
Learning interactive real-world simulators.arXiv preprint arXiv:2310.06114, 2023
Mengjiao Yang, Yilun Du, Kamyar Ghasemipour, Jonathan Tompson, Dale Schuurmans, and Pieter Abbeel. Learning interactive real-world simulators.arXiv preprint arXiv:2310.06114, 1(2):6, 2023. 3
-
[51]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer.arXiv preprint arXiv:2408.06072, 2024. 3
work page internal anchor Pith review arXiv 2024
-
[52]
Gigaworld-policy: An efficient action- centered world–action model, 2026
Angen Ye, Boyuan Wang, Chaojun Ni, Guan Huang, Guosheng Zhao, Hao Li, Hengtao Li, Jie Li, Jindi Lv, Jingyu Liu, et al. Gigaworld-policy: An efficient action-centered world–action model.arXiv preprint arXiv:2603.17240, 2026. 3
-
[53]
World Action Models are Zero-shot Policies
Seonghyeon Ye, Yunhao Ge, Kaiyuan Zheng, Shenyuan Gao, Sihyun Yu, George Kurian, Suneel Indupuru, You Liang Tan, Chuning Zhu, Jiannan Xiang, et al. World action models are zero-shot policies.arXiv preprint arXiv:2602.15922, 2026. 3
work page internal anchor Pith review arXiv 2026
-
[54]
Shaopeng Zhai, Qi Zhang, Tianyi Zhang, Fuxian Huang, Haoran Zhang, Ming Zhou, Shengzhe Zhang, Litao Liu, Sixu Lin, and Jiangmiao Pang. A vision-language-action-critic model for robotic real-world reinforcement learning.arXiv preprint arXiv:2509.15937, 2025. 3
-
[55]
Sigmoid loss for language image pre- training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre- training. InProceedings of the IEEE/CVF international conference on computer vision, pages 11975–11986,
-
[56]
arXiv:2502.09268 [cs.RO] https://arxiv.org/abs/2502.09268
Hongyin Zhang, Pengxiang Ding, Shangke Lyu, Ying Peng, and Donglin Wang. Gevrm: Goal-expressive video generation model for robust visual manipulation.arXiv preprint arXiv:2502.09268, 2025. 3 17 ViVa: A Video-Generative Value Model for Robot Reinforcement Learning
-
[57]
Taste- rob: Advancing video generation of task-oriented hand-object interaction for generalizable robotic manipulation
Hongxiang Zhao, Xingchen Liu, Mutian Xu, Yiming Hao, Weikai Chen, and Xiaoguang Han. Taste- rob: Advancing video generation of task-oriented hand-object interaction for generalizable robotic manipulation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 27683– 27693, 2025. 4
2025
-
[58]
Open-Sora: Democratizing Efficient Video Production for All
Zangwei Zheng, Xiangyu Peng, Tianji Yang, Chenhui Shen, Shenggui Li, Hongxin Liu, Yukun Zhou, Tianyi Li, and Yang You. Open-sora: Democratizing efficient video production for all.arXiv preprint arXiv:2412.20404, 2024. 3
work page internal anchor Pith review arXiv 2024
-
[59]
Siyuan Zhou, Yilun Du, Jiaben Chen, Yandong Li, Dit-Yan Yeung, and Chuang Gan. Robodreamer: Learning compositional world models for robot imagination.arXiv preprint arXiv:2404.12377, 2024. 3
-
[60]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[61]
Rt-2: Vision-language-action models transfer web knowledge to robotic control
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. InConference on Robot Learning, pages 2165–2183. PMLR, 2023. 1, 2 18
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.