Recognition: 2 theorem links
· Lean TheoremHM-Bench: A Comprehensive Benchmark for Multimodal Large Language Models in Hyperspectral Remote Sensing
Pith reviewed 2026-05-10 18:01 UTC · model grok-4.3
The pith
HM-Bench reveals that multimodal large language models struggle with complex spatial-spectral reasoning on hyperspectral remote sensing images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce HM-Bench with 19,337 question-answer pairs across 13 task categories and a dual-modality framework that renders hyperspectral cubes as PCA-based composite images plus structured textual reports; evaluations of 18 MLLMs demonstrate significant difficulties on complex spatial-spectral reasoning tasks and show that visual inputs outperform textual ones.
What carries the argument
Dual-modality evaluation framework that converts raw hyperspectral cubes into PCA-based composite images and structured textual reports for input to existing MLLMs.
If this is right
- Visual inputs should be prioritized over text-only descriptions when designing MLLM pipelines for hyperspectral remote sensing tasks.
- Current models will require architectural changes or targeted training data to handle joint spatial-spectral reasoning effectively.
- HM-Bench can serve as a standardized testbed for measuring future progress in remote-sensing MLLMs.
Where Pith is reading between the lines
- Native support for raw hyperspectral data in future MLLMs could bypass the information loss introduced by PCA and text proxies.
- The benchmark gap suggests that adding more hyperspectral examples to pre-training corpora may be necessary to close performance differences.
- Extending HM-Bench to include temporal sequences or multi-date imagery would expose additional challenges in change-detection reasoning.
Load-bearing premise
Converting raw hyperspectral cubes into PCA-based composite images and structured textual reports provides a faithful proxy for evaluating MLLMs' native ability to perceive and reason over the original hyperspectral data.
What would settle it
Retraining one of the evaluated MLLMs on raw hyperspectral cubes and observing substantially higher accuracy on the same HM-Bench questions would indicate that the reported difficulties stem from input representation rather than fundamental model limitations.
Figures















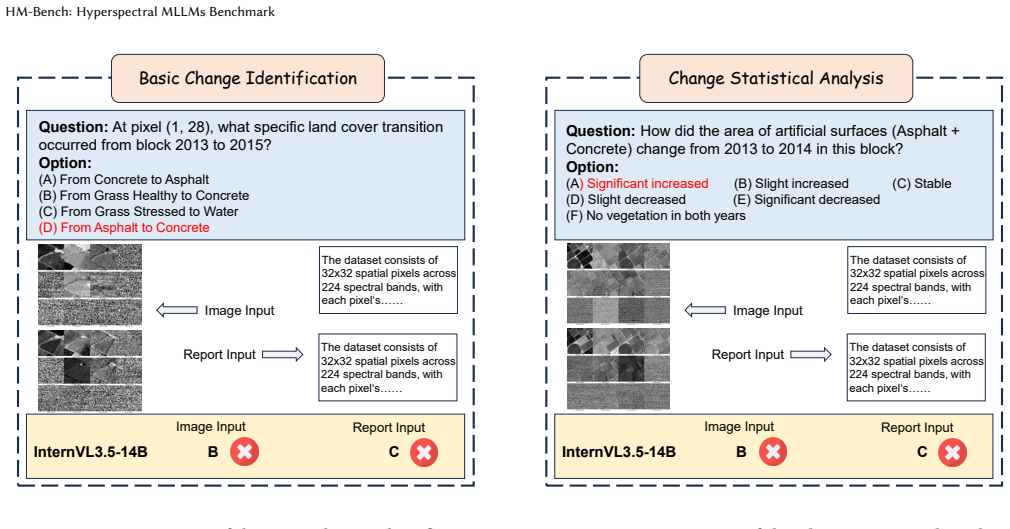
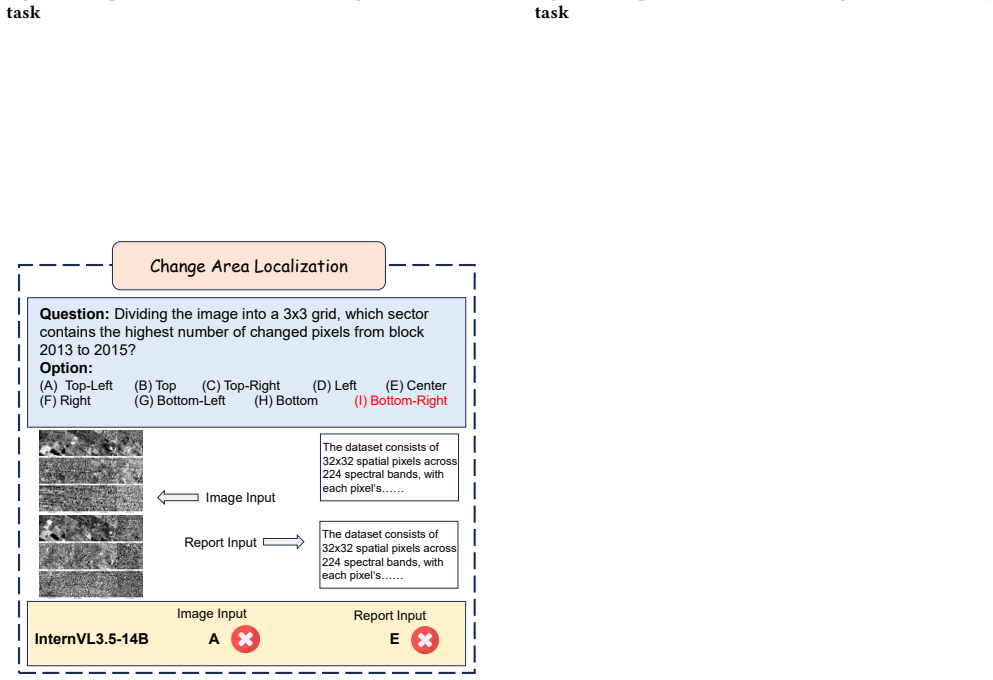
read the original abstract
While multimodal large language models (MLLMs) have made significant strides in natural image understanding, their ability to perceive and reason over hyperspectral image (HSI) remains underexplored, which is a vital modality in remote sensing. The high dimensionality and intricate spectral-spatial properties of HSI pose unique challenges for models primarily trained on RGB data.To address this gap, we introduce Hyperspectral Multimodal Benchmark (HM-Bench), the first benchmark designed specifically to evaluate MLLMs in HSI understanding. We curate a large-scale dataset of 19,337 question-answer pairs across 13 task categories, ranging from basic perception to spectral reasoning. Given that existing MLLMs are not equipped to process raw hyperspectral cubes natively, we propose a dual-modality evaluation framework that transforms HSI data into two complementary representations: PCA-based composite images and structured textual reports. This approach facilitates a systematic comparison of different representation for model performance. Extensive evaluations on 18 representative MLLMs reveal significant difficulties in handling complex spatial-spectral reasoning tasks. Furthermore, our results demonstrate that visual inputs generally outperform textual inputs, highlighting the importance of grounding in spectral-spatial evidence for effective HSI understanding. Dataset and appendix can be accessed at https://github.com/HuoRiLi-Yu/HM-Bench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HM-Bench, the first benchmark for evaluating MLLMs on hyperspectral image (HSI) understanding in remote sensing. It curates 19,337 QA pairs across 13 task categories (from basic perception to spectral reasoning) and proposes a dual-modality framework that converts raw HSI cubes into PCA-based 3-channel composite images and structured textual reports. Evaluations of 18 representative MLLMs show significant difficulties with complex spatial-spectral reasoning tasks and that visual inputs generally outperform textual inputs, underscoring the value of spectral-spatial grounding.
Significance. If the dataset construction and proxy representations are shown to be faithful, this benchmark would provide a much-needed resource for assessing and improving MLLMs in a modality critical to remote sensing, where high-dimensional spectral data poses unique challenges beyond standard RGB training. The scale (nearly 20k pairs) and breadth of tasks, combined with the empirical finding on visual vs. textual performance, could guide future model development toward better native HSI perception.
major comments (3)
- [§3] §3 (Dataset Curation and Task Definition): The generation process for the 19,337 QA pairs, including question formulation, answer verification, and controls for annotation bias or automated labeling artifacts, is described at too high a level. Without these details it is impossible to assess whether the reported performance gaps and task difficulties reflect genuine model limitations or artifacts of the benchmark construction.
- [§3.3] §3.3 (Dual-Modality Representation): The central claim that MLLMs exhibit difficulties in spatial-spectral reasoning and that visual inputs outperform textual ones rests on the PCA composites and textual reports being adequate proxies. The manuscript provides no analysis demonstrating that the top three principal components preserve the spectral signatures required for the spectral-reasoning subset of tasks; if critical band-specific information is lost, the observed gaps may simply reflect the impoverished input rather than limitations in native HSI perception.
- [§4] §4 (Experimental Setup and Task Definitions): The 13 task categories lack precise, reproducible definitions and representative examples. This omission is load-bearing because the headline result—that models struggle with “complex spatial-spectral reasoning”—cannot be interpreted or replicated without knowing exactly what each category requires (e.g., which tasks truly demand full spectral resolution versus what can be solved from an RGB-like composite).
minor comments (3)
- [Table 2] Table 2 and Figure 3: Performance numbers for visual and textual modalities should be presented side-by-side within the same table or figure to facilitate direct comparison of the claimed visual advantage.
- [§2] Related Work: The discussion of prior MLLM benchmarks in remote sensing is brief; adding citations to recent works on spectral or multispectral VQA would better situate the novelty of HM-Bench.
- [Abstract] The GitHub link in the abstract is useful, but the manuscript should state the exact license and any usage restrictions for the released dataset and code.
Simulated Author's Rebuttal
We thank the referee for the constructive and insightful comments on our manuscript. We have addressed each of the major comments below and will incorporate the suggested revisions to improve the clarity and reproducibility of the paper.
read point-by-point responses
-
Referee: [§3] §3 (Dataset Curation and Task Definition): The generation process for the 19,337 QA pairs, including question formulation, answer verification, and controls for annotation bias or automated labeling artifacts, is described at too high a level. Without these details it is impossible to assess whether the reported performance gaps and task difficulties reflect genuine model limitations or artifacts of the benchmark construction.
Authors: We agree with the referee that more detailed information on the dataset curation process is required to allow proper assessment of the benchmark. In the revised manuscript, we will provide an expanded description in Section 3, detailing the question formulation using a combination of template-based generation informed by remote sensing experts and automated tools, the verification process involving cross-checking with ground truth data from spectral libraries and manual inspection by two domain experts for a subset of 2,000 pairs, and controls for bias including the use of multiple data sources and exclusion of ambiguous questions. We will also add a subsection on potential artifacts and how they were mitigated. These additions will ensure the performance results can be confidently attributed to model capabilities. revision: yes
-
Referee: [§3.3] §3.3 (Dual-Modality Representation): The central claim that MLLMs exhibit difficulties in spatial-spectral reasoning and that visual inputs outperform textual ones rests on the PCA composites and textual reports being adequate proxies. The manuscript provides no analysis demonstrating that the top three principal components preserve the spectral signatures required for the spectral-reasoning subset of tasks; if critical band-specific information is lost, the observed gaps may simply reflect the impoverished input rather than limitations in native HSI perception.
Authors: This is a valid concern regarding the faithfulness of the proxy representations. We will revise Section 3.3 to include a quantitative analysis of spectral preservation. Specifically, we will report the cumulative variance explained by the top three principal components (typically over 95% in our datasets) and provide examples of spectral signature reconstruction error for pixels involved in spectral reasoning tasks. Additionally, we will discuss that while some fine-grained band information may be lost, the PCA composites retain the primary spatial-spectral structures necessary for the tasks, and the superior performance of visual over textual inputs supports the value of this representation. We will also note this as a limitation and suggest future work on native HSI MLLMs. revision: yes
-
Referee: [§4] §4 (Experimental Setup and Task Definitions): The 13 task categories lack precise, reproducible definitions and representative examples. This omission is load-bearing because the headline result—that models struggle with “complex spatial-spectral reasoning”—cannot be interpreted or replicated without knowing exactly what each category requires (e.g., which tasks truly demand full spectral resolution versus what can be solved from an RGB-like composite).
Authors: We acknowledge that the task definitions need to be more precise to support replication and interpretation of results. In the revised paper, we will expand Section 4 with formal definitions for each of the 13 categories, specifying the input requirements, expected reasoning, and whether full spectral resolution is necessary (e.g., for 'spectral signature identification' it requires specific band values not available in RGB composites). We will also include a table with representative QA examples for each category, drawn from the dataset, to illustrate the complexity levels. This will clarify why certain tasks pose greater challenges for current MLLMs. revision: yes
Circularity Check
No circularity: empirical benchmark with no derivations or fitted predictions
full rationale
The paper introduces HM-Bench by curating 19,337 QA pairs across 13 categories and evaluating 18 MLLMs on PCA-composite images plus structured text reports. No equations, parameter fitting, predictions, or first-principles derivations exist that could reduce to inputs by construction. Claims about model difficulties and visual-vs-textual performance rest on direct empirical measurements of the chosen proxies rather than self-referential logic, self-citation of uniqueness results, or renaming of known patterns. The dual-modality framework is an explicit design choice, not a hidden tautology.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Existing MLLMs trained primarily on RGB data are not equipped to process raw hyperspectral cubes natively
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we propose a dual-modality evaluation framework that transforms HSI data into two complementary representations: PCA-based composite images and structured textual reports
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Extensive evaluations on 18 representative MLLMs reveal significant difficulties in handling complex spatial-spectral reasoning tasks
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Flo- rencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shya- mal Anadkat, et al. 2023. Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Jun- yang Lin, Chang Zhou, and Jingren Zhou. 2023. Qwen-vl: A versatile vision- language model for understanding, localization. Text Reading, and Beyond 2, 1 (2023), 1
2023
-
[3]
Marion Baumgardner, Larry Biehl, and David Landgrebe. 2015. 220 band aviris hyperspectral image data set: June 12, 1992 indian pine test site 3. (No Title) (2015)
2015
-
[4]
Davide Caffagni, Federico Cocchi, Luca Barsellotti, Nicholas Moratelli, Sara Sarto, Lorenzo Baraldi, Marcella Cornia, and Rita Cucchiara. 2024. The revolu- tion of multimodal large language models: A survey. Findings of the association for computational linguistics: ACL 2024 (2024), 13590–13618
2024
-
[5]
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. 2024. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 24185–24198
2024
-
[6]
Federico Cocchi, Nicholas Moratelli, Davide Caffagni, Sara Sarto, Lorenzo Baraldi, Marcella Cornia, and Rita Cucchiara. 2025. Llava-more: A comparative study of llms and visual backbones for enhanced visual instruction tuning. In Proceedings of the IEEE/CVF International Conference on Computer Vision . 4278– 4288
2025
-
[7]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. 2025. Gemini 2.5: Pushing the frontier with advanced reasoning, multi- modality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [8]
-
[9]
Murillo Edson de Carvalho Souza and Li Weigang. 2025. Grok, Gemini, ChatGPT and DeepSeek: Comparison and applications in conversational artificial intelli- gence. Inteligencia Artificial 2, 1 (2025)
2025
-
[10]
Christian Debes, Andreas Merentitis, Roel Heremans, Jürgen Hahn, Nikolaos Frangiadakis, Tim Van Kasteren, Wenzhi Liao, Rik Bellens, Aleksandra Pižurica, Sidharta Gautama, et al. 2014. Hyperspectral and LiDAR data fusion: Outcome of the 2013 GRSS data fusion contest. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing 7, 6 (201...
2014
- [11]
- [12]
-
[13]
Chaoyou Fu, Peixian Chen, Yunhang Shen, Yulei Qin, Mengdan Zhang, Xu Lin, Jinrui Yang, Xiawu Zheng, Ke Li, Xing Sun, et al. 2023. Mme: A comprehensive evaluation benchmark for multimodal large language models. arXiv preprint arXiv:2306.13394 (2023)
work page internal anchor Pith review arXiv 2023
-
[14]
Junyao Ge, Xu Zhang, Yang Zheng, Kaitai Guo, and Jimin Liang. 2025. RSTeller: Scaling up visual language modeling in remote sensing with rich linguistic se- mantics from openly available data and large language models. ISPRS Journal of Photogrammetry and Remote Sensing 226 (2025), 146–163
2025
-
[15]
Jiaming Han, Kaixiong Gong, Yiyuan Zhang, Jiaqi Wang, Kaipeng Zhang, Dahua Lin, Yu Qiao, Peng Gao, and Xiangyu Yue. 2024. Onellm: One framework to align all modalities with language. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . 26584–26595
2024
-
[16]
Danfeng Hong, Zhu Han, Jing Yao, Lianru Gao, Bing Zhang, Antonio Plaza, and Jocelyn Chanussot. 2021. SpectralFormer: Rethinking hyperspectral image clas- sification with transformers. IEEE Transactions on Geoscience and Remote Sensing 60 (2021), 1–15
2021
-
[17]
Danfeng Hong, Jingliang Hu, Jing Yao, Jocelyn Chanussot, and Xiao Xiang Zhu
-
[18]
ISPRS Journal of Pho- togrammetry and Remote Sensing 178 (2021), 68–80
Multimodal remote sensing benchmark datasets for land cover classifica- tion with a shared and specific feature learning model. ISPRS Journal of Pho- togrammetry and Remote Sensing 178 (2021), 68–80
2021
-
[19]
Danfeng Hong, Chenyu Li, Xuyang Li, Gustau Camps-Valls, and Jocelyn Chanus- sot. 2026. Foundation Models in Remote Sensing: Evolving from unimodality to multimodality. IEEE Geoscience and Remote Sensing Magazine (2026)
2026
-
[20]
Wenyi Hong, Wenmeng Yu, Xiaotao Gu, Guo Wang, Guobing Gan, Haomiao Tang, Jiale Cheng, Ji Qi, Junhui Ji, Lihang Pan, et al. 2025. Glm-4.5 v and glm-4.1 v-thinking: Towards versatile multimodal reasoning with scalable reinforcement learning. arXiv preprint arXiv:2507.01006 (2025)
work page internal anchor Pith review arXiv 2025
-
[21]
Sikang Hou, Hongye Shi, Xianghai Cao, Xiaohua Zhang, and Licheng Jiao. 2021. Hyperspectral imagery classification based on contrastive learning. IEEE Trans- actions on Geoscience and Remote Sensing 60 (2021), 1–13
2021
-
[22]
Shaohan Huang, Li Dong, Wenhui Wang, Yaru Hao, Saksham Singhal, Shuming Ma, Tengchao Lv, Lei Cui, Owais Khan Mohammed, Barun Patra, et al. 2023. Lan- guage is not all you need: Aligning perception with language models. Advances in Neural Information Processing Systems 36 (2023), 72096–72109
2023
- [23]
-
[24]
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Keming Lu, et al. 2024. Qwen2. 5-coder technical report. arXiv preprint arXiv:2409.12186 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [25]
-
[26]
Xudong Kang, Puhong Duan, and Shutao Li. 2020. Hyperspectral image visual- ization with edge-preserving filtering and principal component analysis. Infor- mation Fusion 57 (2020), 130–143
2020
-
[27]
Salman Khan, Muzammal Naseer, Munawar Hayat, Syed Waqas Zamir, Fa- had Shahbaz Khan, and Mubarak Shah. 2022. Transformers in vision: A survey. ACM computing surveys (CSUR) 54, 10s (2022), 1–41
2022
-
[28]
Kartik Kuckreja, Muhammad Sohail Danish, Muzammal Naseer, Abhijit Das, Salman Khan, and Fahad Shahbaz Khan. 2024. Geochat: Grounded large vision- language model for remote sensing. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition . 27831–27840
2024
-
[29]
Bohao Li, Yuying Ge, Yixiao Ge, Guangzhi Wang, Rui Wang, Ruimao Zhang, and Ying Shan. 2024. Seed-bench: Benchmarking multimodal large language mod- els. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 13299–13308
2024
-
[30]
Feng Li, Renrui Zhang, Hao Zhang, Yuanhan Zhang, Bo Li, Wei Li, Zejun Ma, and Chunyuan Li. 2024. Llava-next-interleave: Tackling multi-image, video, and 3d in large multimodal models. arXiv preprint arXiv:2407.07895 (2024)
work page internal anchor Pith review arXiv 2024
-
[31]
Jiaojiao Li, Shunyao Zi, Rui Song, Yunsong Li, Yinlin Hu, and Qian Du. 2022. A stepwise domain adaptive segmentation network with covariate shift alleviation for remote sensing imagery. IEEE Transactions on Geoscience and Remote Sensing 60 (2022), 1–15
2022
- [32]
-
[33]
Shutao Li, Weiwei Song, Leyuan Fang, Yushi Chen, Pedram Ghamisi, and Jon Atli Benediktsson. 2019. Deep learning for hyperspectral image classification: An overview. IEEE transactions on geoscience and remote sensing 57, 9 (2019), 6690– 6709
2019
-
[34]
Xiang Li, Jian Ding, and Mohamed Elhoseiny. 2024. Vrsbench: A versatile vision- language benchmark dataset for remote sensing image understanding. Advances in Neural Information Processing Systems 37 (2024), 3229–3242
2024
-
[35]
Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, and Yong Jae Lee. 2024. Llavanext: Improved reasoning, ocr, and world knowledge
2024
-
[36]
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, et al. 2024. Mmbench: Is your multi-modal model an all-around player?. In European conference on com- puter vision. Springer, 216–233
2024
-
[37]
Heras, Francisco Argüello, and Mauro Dalla Mura
Javier López-Fandiño, Dora B. Heras, Francisco Argüello, and Mauro Dalla Mura
-
[38]
International Journal of Parallel Programming 47, 2 (2019), 272–292
GPU framework for change detection in multitemporal hyperspectral im- ages. International Journal of Parallel Programming 47, 2 (2019), 272–292
2019
-
[39]
Haoyu Lu, Wen Liu, Bo Zhang, Bingxuan Wang, Kai Dong, Bo Liu, Jingxiang Sun, Tongzheng Ren, Zhuoshu Li, Hao Yang, et al. 2024. Deepseek-vl: towards real- world vision-language understanding. arXiv preprint arXiv:2403.05525 (2024)
work page internal anchor Pith review arXiv 2024
-
[40]
Andrzej Maćkiewicz and Waldemar Ratajczak. 1993. Principal components anal- ysis (PCA). Computers & Geosciences 19, 3 (1993), 303–342
1993
-
[41]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sand- hini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al
-
[42]
In International conference on machine learning
Learning transferable visual models from natural language supervision. In International conference on machine learning . PmLR, 8748–8763
-
[43]
Behnood Rasti, Danfeng Hong, Renlong Hang, Pedram Ghamisi, Xudong Kang, Jocelyn Chanussot, and Jon Atli Benediktsson. 2020. Feature extraction for hy- perspectral imagery: The evolution from shallow to deep: Overview and toolbox. IEEE Geoscience and Remote Sensing Magazine 8, 4 (2020), 60–88
2020
-
[44]
Marina Sánchez-Torrón, Daria Akselrod, and Jason Rauchwerk. 2026. To Write or to Automate Linguistic Prompts, That Is the Question. arXiv preprint arXiv:2603.25169 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[45]
Risa Shinoda, Nakamasa Inoue, Hirokatsu Kataoka, Masaki Onishi, and Yoshi- taka Ushiku. 2025. Agrobench: Vision-language model benchmark in agricul- ture. In Proceedings of the IEEE/CVF International Conference on Computer Vision . 7634–7644
2025
-
[46]
Mary B Stuart, Andrew JS McGonigle, and Jon R Willmott. 2019. Hyperspec- tral imaging in environmental monitoring: A review of recent developments and technological advances in compact field deployable systems. Sensors 19, 14 (2019), 3071
2019
-
[47]
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. 2023. Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[48]
Kimi Team, Angang Du, Bohong Yin, Bowei Xing, Bowen Qu, Bowen Wang, Cheng Chen, Chenlin Zhang, Chenzhuang Du, Chu Wei, et al. 2025. Kimi-vl technical report. arXiv preprint arXiv:2504.07491 (2025)
work page internal anchor Pith review arXiv 2025
- [49]
- [50]
-
[51]
Fengxiang Wang, Hongzhen Wang, Zonghao Guo, Di Wang, Yulin Wang, Ming- shuo Chen, Qiang Ma, Long Lan, Wenjing Yang, Jing Zhang, et al. 2025. Xlrs- bench: Could your multimodal llms understand extremely large ultra-high- resolution remote sensing imagery?. In Proceedings of the Computer Vision and Pattern Recognition Conference. 14325–14336
2025
- [52]
-
[53]
Zhiyu Wu, Xiaokang Chen, Zizheng Pan, Xingchao Liu, Wen Liu, Damai Dai, Huazuo Gao, Yiyang Ma, Chengyue Wu, Bingxuan Wang, et al. 2024. Deepseek- vl2: Mixture-of-experts vision-language models for advanced multimodal under- standing. arXiv preprint arXiv:2412.10302 (2024)
work page internal anchor Pith review arXiv 2024
-
[54]
Yonghao Xu, Bo Du, Liangpei Zhang, Daniele Cerra, Miguel Pato, Emiliano Car- mona, Saurabh Prasad, Naoto Yokoya, Ronny Hänsch, and Bertrand Le Saux
-
[55]
IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing 12, 6 (2019), 1709–1724
Advanced multi-sensor optical remote sensing for urban land use and land cover classification: Outcome of the 2018 IEEE GRSS data fusion contest. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing 12, 6 (2019), 1709–1724
2018
-
[56]
CEN Yi, Lifu Zhang, Xia Zhang, W ANG Yueming, QI Wenchao, TANG Senlin, and Peng Zhang. 2020. Aerial hyperspectral remote sensing classification dataset of Xiongan New Area (Matiwan Village). National Remote Sensing Bulletin 24, 11 (2020), 1299–1306
2020
-
[57]
Shukang Yin, Chaoyou Fu, Sirui Zhao, Ke Li, Xing Sun, Tong Xu, and Enhong Chen. 2024. A survey on multimodal large language models. National Science Review 11, 12 (2024), nwae403
2024
-
[58]
Kaining Ying, Fanqing Meng, Jin Wang, Zhiqian Li, Han Lin, Yue Yang, Hao Zhang, Wenbo Zhang, Yuqi Lin, Shuo Liu, et al. 2024. Mmt-bench: A compre- hensive multimodal benchmark for evaluating large vision-language models to- wards multitask agi. arXiv preprint arXiv:2404.16006 (2024)
-
[59]
Yang Zhan, Zhitong Xiong, and Yuan Yuan. 2025. Skyeyegpt: Unifying remote sensing vision-language tasks via instruction tuning with large language model. ISPRS Journal of Photogrammetry and Remote Sensing 221 (2025), 64–77
2025
-
[60]
Xu Zhang, Jiabin Fang, Zhuoming Ding, Jin Yuan, Xuan Liu, Qianjun Zhang, and Zhiyong Li. 2026. Cross-modal Context-aware Learning for Visual Prompt Guided Multimodal Image Understanding in Remote Sensing. IEEE Transactions on Geoscience and Remote Sensing (2026)
2026
-
[61]
Xia Zhang, Yanli Sun, Kun Shang, Lifu Zhang, and Shudong Wang. 2016. Crop classification based on feature band set construction and object-oriented ap- proach using hyperspectral images. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing 9, 9 (2016), 4117–4128
2016
-
[62]
Yi-Fan Zhang, Huanyu Zhang, Haochen Tian, Chaoyou Fu, Shuangqing Zhang, Junfei Wu, Feng Li, Kun Wang, Qingsong Wen, Zhang Zhang, et al. 2024. Mme- realworld: Could your multimodal llm challenge high-resolution real-world sce- narios that are difficult for humans? arXiv preprint arXiv:2408.13257 (2024)
-
[63]
Yanfei Zhong, Xin Hu, Chang Luo, Xinyu Wang, Ji Zhao, and Liangpei Zhang
-
[64]
Remote Sensing of Environment 250 (2020), 112012
WHU-Hi: UA V-borne hyperspectral with high spatial resolution (H2) benchmark datasets and classifier for precise crop identification based on deep convolutional neural network with CRF. Remote Sensing of Environment 250 (2020), 112012
2020
-
[65]
Zilong Zhong, Jonathan Li, Zhiming Luo, and Michael Chapman. 2017. Spectral– spatial residual network for hyperspectral image classification: A 3-D deep learn- ing framework. IEEE transactions on geoscience and remote sensing 56, 2 (2017), 847–858
2017
-
[66]
Baichuan Zhou, Haote Yang, Dairong Chen, Junyan Ye, Tianyi Bai, Jinhua Yu, Songyang Zhang, Dahua Lin, Conghui He, and Weijia Li. 2025. Urbench: A com- prehensive benchmark for evaluating large multimodal models in multi-view urban scenarios. In Proceedings of the AAAI Conference on Artificial Intelligence , Vol. 39. 10707–10715
2025
-
[67]
Hyperspectral unmixing: ground truth labeling, datasets, benchmark performances and survey
Feiyun Zhu. 2017. Hyperspectral unmixing: ground truth labeling, datasets, benchmark performances and survey. arXiv preprint arXiv:1708.05125 (2017). HM-Bench: Hyperspectral MLLMs Benchmark Appendix This appendix supplements the proposed HM-Bench with details excluded from the main paper due to space constraints. The appen- dix is organized into six secti...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.