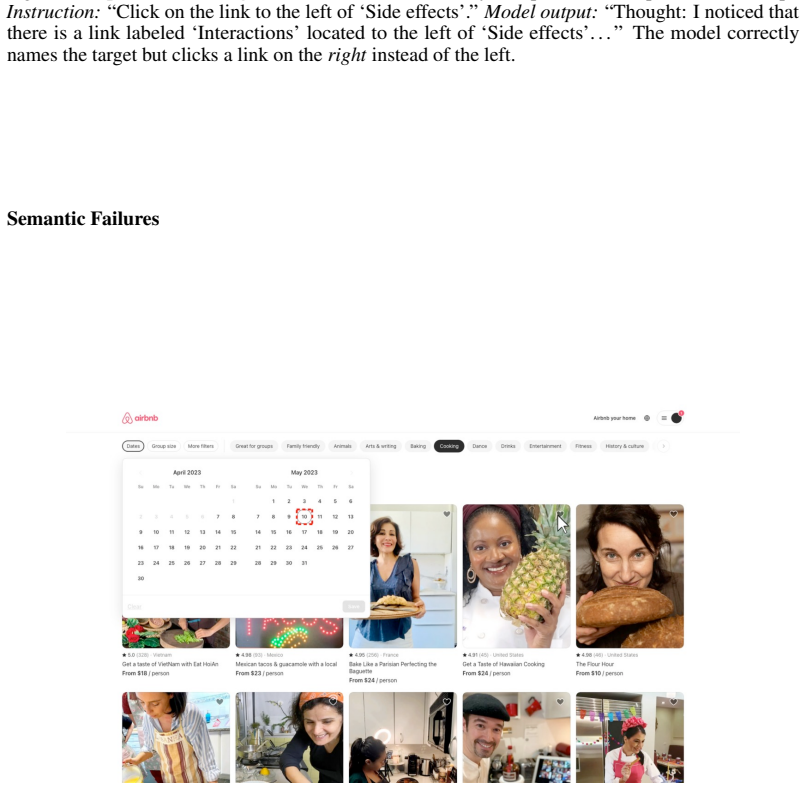
Recognition: unknown
GUI-Perturbed: Domain Randomization Reveals Systematic Brittleness in GUI Grounding Models
Pith reviewed 2026-05-10 13:35 UTC · model grok-4.3
The pith
GUI grounding models suffer large accuracy drops when instructions require relational spatial reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By varying visual scenes and instructions along independent axes, the GUI-Perturbed framework isolates specific weaknesses in GUI grounding: relational instructions cause systematic accuracy collapse in all tested 7B models, a 70 percent browser zoom produces statistically significant degradation, and rank-8 LoRA fine-tuning with augmented data degrades performance instead of improving it. This provides diagnostic information on capabilities like spatial reasoning and visual robustness that aggregate benchmarks cannot supply.
What carries the argument
GUI-Perturbed, the controlled perturbation framework that independently varies visual scenes and instructions to measure grounding robustness.
If this is right
- Standard benchmarks that use a single fixed instruction per screenshot overestimate model capabilities.
- GUI grounding models lack reliable performance on instructions requiring spatial relations between elements.
- Visual changes such as browser zoom levels can significantly affect model accuracy in grounding tasks.
- Simple data augmentation and low-rank fine-tuning may not address the brittleness and can even reduce performance.
- Diagnostic signals from separate perturbation axes can guide targeted improvements in spatial reasoning and calibration.
Where Pith is reading between the lines
- Real-world GUI applications would likely encounter similar instruction variations, making current models unreliable without changes in training or evaluation.
- Future benchmarks should routinely include controlled perturbations along visual and linguistic axes to better predict deployment performance.
- Alternative training approaches beyond standard LoRA on augmented data may be needed to build robustness to relational instructions.
- The released dataset and pipeline could support development of models that handle varied user phrasings more consistently.
Load-bearing premise
The specific perturbations chosen, such as relational instructions and particular zoom levels, represent the variations that matter most in actual GUI usage.
What would settle it
Testing the three models or similar ones on the released GUI-Perturbed dataset with relational instructions and observing whether accuracy remains above 85 percent or drops as reported.
Figures
















read the original abstract
GUI grounding models report over 85% accuracy on standard benchmarks, yet drop 27-56 percentage points when instructions require spatial reasoning rather than direct element naming. Current benchmarks miss this because they evaluate each screenshot once with a single fixed instruction. We introduce GUI-Perturbed, a controlled perturbation framework that independently varies visual scenes and instructions to measure grounding robustness. Evaluating three 7B models from the same architecture lineage, we find that relational instructions cause systematic accuracy collapse across all models, a 70% browser zoom produces statistically significant degradation, and rank-8 LoRA fine-tuning with augmented data degrades performance rather than improving it. By perturbing along independent axes, GUI-Perturbed isolates which specific capability axes are affected-spatial reasoning, visual robustness, reasoning calibration-providing diagnostic signal that aggregate benchmarks cannot. We release the dataset, augmentation pipeline, and a fine-tuned model.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GUI-Perturbed, a controlled perturbation framework that independently varies visual scenes (e.g., browser zoom) and instructions (direct element naming vs. relational/spatial) to diagnose robustness in GUI grounding models. It reports that three 7B models suffer 27-56pp accuracy drops on relational instructions, statistically significant degradation at 70% zoom, and that rank-8 LoRA fine-tuning on augmented data worsens rather than improves performance. The framework and released dataset/pipeline are positioned as providing diagnostic axes (spatial reasoning, visual robustness, calibration) missing from standard single-instruction benchmarks.
Significance. If the perturbations successfully isolate the claimed capability axes, the work is significant for revealing systematic brittleness in GUI grounding that aggregate benchmarks overlook, with direct implications for real-world GUI agents. The release of the dataset, augmentation pipeline, and fine-tuned model is a concrete strength that supports reproducibility and follow-on work.
major comments (3)
- [Perturbation Framework] The central claim that relational instructions cause accuracy collapse specifically due to spatial reasoning requirements is load-bearing. The perturbation framework description does not report matching or controlling for instruction length, token count, syntactic complexity, parse-tree depth, or lexical difficulty between direct and relational variants. If relational phrasings are longer or more complex on average, the 27-56pp drop may reflect general instruction-following brittleness rather than a targeted spatial-reasoning failure.
- [Experimental Setup and Results] Full details on exact perturbation generation (including how relational instructions and zoom levels are constructed) and any exclusion criteria are required to confirm the reported statistical significance and rule out post-hoc selection. This directly affects the soundness of the cross-model consistency claims.
- [Fine-tuning Experiments] The finding that rank-8 LoRA fine-tuning with augmented data degrades performance (rather than improving it) is a key negative result. More information on the augmentation process, data mixture, and training details is needed to interpret whether this reflects true brittleness or an artifact of the fine-tuning protocol.
minor comments (2)
- [Abstract and §1] The abstract and introduction would benefit from explicitly naming the three 7B models evaluated and their base checkpoints for reproducibility.
- [Figures and Tables] Figure and table captions should explicitly state the perturbation axes, metrics (e.g., accuracy delta), and statistical tests used so that readers can interpret results without cross-referencing the main text.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our perturbation framework, experimental details, and fine-tuning results. We address each major comment below with clarifications and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Perturbation Framework] The central claim that relational instructions cause accuracy collapse specifically due to spatial reasoning requirements is load-bearing. The perturbation framework description does not report matching or controlling for instruction length, token count, syntactic complexity, parse-tree depth, or lexical difficulty between direct and relational variants. If relational phrasings are longer or more complex on average, the 27-56pp drop may reflect general instruction-following brittleness rather than a targeted spatial-reasoning failure.
Authors: We agree that explicit controls for linguistic factors are necessary to isolate spatial reasoning. Our instruction generation used parallel template families (direct naming vs. relational/spatial descriptions) applied to the same UI elements, with an effort to keep surface forms comparable; however, we did not report aggregate statistics on token counts or parse complexity. In revision we will add a supplementary table reporting mean token length, word count, dependency parse depth, and lexical diversity for both instruction classes across the full dataset. This will allow direct assessment of whether the observed drops exceed what would be expected from complexity alone. The high performance on direct instructions and the consistency of the relational drop across three independently trained 7B models provide supporting evidence for a spatial-specific effect, but the added metrics will make the claim more robust. revision: yes
-
Referee: [Experimental Setup and Results] Full details on exact perturbation generation (including how relational instructions and zoom levels are constructed) and any exclusion criteria are required to confirm the reported statistical significance and rule out post-hoc selection. This directly affects the soundness of the cross-model consistency claims.
Authors: We will expand the Methods section with complete generation procedures: the exact template sets for relational instructions, the browser-level CSS and viewport scaling used to produce the 70% zoom condition, and the full list of exclusion criteria (e.g., screenshots containing overlapping clickable regions, rendering failures, or elements outside the viewport after perturbation). Statistical significance was obtained via pre-specified paired t-tests on matched screenshot-instruction pairs; no post-hoc filtering of results occurred. The released augmentation pipeline already contains the generation scripts; we will also include a detailed pseudocode description and the precise exclusion rules in the revised manuscript to eliminate any ambiguity. revision: yes
-
Referee: [Fine-tuning Experiments] The finding that rank-8 LoRA fine-tuning with augmented data degrades performance (rather than improving it) is a key negative result. More information on the augmentation process, data mixture, and training details is needed to interpret whether this reflects true brittleness or an artifact of the fine-tuning protocol.
Authors: We will add a dedicated appendix with the full fine-tuning protocol: the exact data mixture ratios (original vs. perturbed samples), the specific perturbation variants included in augmentation, LoRA configuration (rank 8, alpha, dropout), optimizer, learning rate schedule, batch size, number of epochs, and early-stopping criteria. Validation loss curves and per-epoch accuracy on held-out perturbed test sets will also be reported. The consistent degradation across multiple random seeds and the fact that direct-instruction performance remained stable while relational performance declined suggest the result reflects genuine brittleness rather than a training artifact; the additional details will allow readers to reproduce and interpret the outcome. revision: yes
Circularity Check
No circularity: purely empirical evaluation with direct measurements
full rationale
The paper introduces GUI-Perturbed as a controlled perturbation framework and evaluates three models via direct accuracy measurements on relational vs. direct instructions, zoom levels, and fine-tuning. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text or abstract. Central claims rest on observed percentage-point drops and statistical significance from experiments, not on any reduction to inputs by construction. This matches the reader's assessment of an empirical study without self-referential logic.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Perturbations along visual and instruction axes are representative of real-world GUI variations and do not introduce unrelated artifacts.
Reference graph
Works this paper leans on
-
[1]
K. Cheng et al. SeeClick: Harnessing gui grounding for advanced visual gui agents.arXiv preprint arXiv:2401.10935, 2024. doi: 10.48550/arXiv.2401.10935
-
[2]
K. Li et al. ScreenSpot-Pro: Gui grounding for professional high-resolution computer use. arXiv preprint arXiv:2504.07981, 2025. doi: 10.48550/arXiv.2504.07981
-
[3]
OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments
T. Xie et al. OSWorld: Benchmarking multimodal agents for open-ended tasks in real computer environments.arXiv preprint arXiv:2404.07972, 2024. doi: 10.48550/arXiv.2404.07972
work page internal anchor Pith review doi:10.48550/arxiv.2404.07972 2024
-
[4]
Boyu Gou, Ruohan Wang, Boyuan Zheng, Yanan Xie, Cheng Chang, Yiheng Shu, Huan Sun, and Yu Su
X. Deng et al. Mind2Web: Towards a generalist agent for the web.arXiv preprint arXiv:2306.06070, 2023. doi: 10.48550/arXiv.2306.06070
-
[5]
Gui-robust: A comprehensive dataset for test- ing gui agent robustness in real-world anomalies,
J. Yang et al. GUI-Robust: A comprehensive dataset for testing gui agent robustness in real- world anomalies.arXiv preprint arXiv:2506.14477, 2025. doi: 10.48550/arXiv.2506.14477
-
[6]
H. H. Zhao, K. Yang, W. Yu, D. Gao, and M. Z. Shou. WorldGUI: An interactive benchmark for desktop gui automation from any starting point.arXiv preprint arXiv:2502.08047, 2026. doi: 10.48550/arXiv.2502.08047
-
[7]
Domain randomization for transferring deep neural networks from simulation to the real world,
J. Tobin, R. Fong, A. Ray, J. Schneider, W. Zaremba, and P. Abbeel. Domain randomization for transferring deep neural networks from simulation to the real world. InIEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2017. doi: 10.48550/arXiv.1703.06907
-
[8]
S. Bai et al. Qwen2.5-VL technical report.arXiv preprint arXiv:2502.13923, 2025. doi: 10.48550/arXiv.2502.13923
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2502.13923 2025
-
[9]
UI-TARS: Pioneering Automated GUI Interaction with Native Agents
Y . Qin et al. UI-TARS: Pioneering automated gui interaction with native agents.arXiv preprint arXiv:2501.12326, 2025. doi: 10.48550/arXiv.2501.12326
-
[10]
Y . Yang et al. GTA1: Gui test-time scaling agent.arXiv preprint arXiv:2507.05791, 2025. doi: 10.48550/arXiv.2507.05791
-
[11]
E. J. Hu et al. LoRA: Low-rank adaptation of large language models.arXiv preprint arXiv:2106.09685, 2021. doi: 10.48550/arXiv.2106.09685
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2106.09685 2021
-
[12]
Mind2web 2: Evaluating agentic search with agent-as-a-judge
Boyu Gou et al. Mind2web 2: Evaluating agentic search with agent-as-a-judge. InThe Thirty- ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2025. URLhttps://openreview.net/forum?id=AUaW6DS9si
2025
-
[13]
arXiv preprint arXiv:2401.13649 , year=
Jing Yu Koh, Robert Lo, Lawrence Jang, Vikram Duvvur, Ming Chong Lim, Po-Yu Huang, Graham Neubig, Shuyan Zhou, Ruslan Salakhutdinov, and Daniel Fried. Visualwebarena: Evaluating multimodal agents on realistic visual web tasks.arXiv preprint arXiv:2401.13649, 2024
-
[14]
World of bits: An open-domain platform for web-based agents
Tianlin Shi, Andrej Karpathy, Linxi Fan, Jonathan Hernandez, and Percy Liang. World of bits: An open-domain platform for web-based agents. InProceedings of the 34th International Conference on Machine Learning, pages 3135–3144. PMLR, 2017
2017
-
[15]
T. Xie et al. Scaling computer-use grounding via user interface decomposition and synthesis. arXiv preprint arXiv:2505.13227, 2025. doi: 10.48550/arXiv.2505.13227
-
[16]
T. Xue et al. An illusion of progress? assessing the current state of web agents.arXiv preprint arXiv:2504.01382, 2025. doi: 10.48550/arXiv.2504.01382
-
[17]
Opencua: Open foundations for computer-use agents.arXiv preprint arXiv:2508.09123, 2025
X. Wang et al. OpenCUA: Open foundations for computer-use agents.arXiv preprint arXiv:2508.09123, 2025. doi: 10.48550/arXiv.2508.09123
-
[18]
Aria-ui: Visual grounding for gui instruc- tions.arXiv preprint arXiv:2412.16256, 2024
Yuhao Yang, Yue Wang, Dongxu Li, Ziyang Luo, Bei Chen, Chao Huang, and Junnan Li. Aria-ui: Visual grounding for gui instructions.arXiv preprint arXiv:2412.16256, 2024
-
[19]
Omniact: A dataset and benchmark for enabling multimodal generalist autonomous agents for desktop and web, 2024
Raghav Kapoor, Yash Parag Butala, Melisa Russak, Jing Yu Koh, Kiran Kamble, Waseem Alshikh, and Ruslan Salakhutdinov. Omniact: A dataset and benchmark for enabling multimodal generalist autonomous agents for desktop and web, 2024. 19
2024
-
[20]
Widget captioning: Generating natural language description for mobile user interface elements
Yang Li, Gang Li, Luheng He, Jingjie Zheng, Hong Li, and Zhiwei Guan. Widget captioning: Generating natural language description for mobile user interface elements. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 5495–5510, 2020
2020
-
[21]
Rodriguez, Montek Kalsi, Rabiul Awal, Nicolas Chapados, M
Shravan Nayak, Xiangru Jian, Kevin Qinghong Lin, Juan A. Rodriguez, Montek Kalsi, Rabiul Awal, Nicolas Chapados, M. Tamer Özsu, Aishwarya Agrawal, David Vazquez, Christopher Pal, Perouz Taslakian, Spandana Gella, and Sai Rajeswar. Ui-vision: A desktop-centric gui benchmark for visual perception and interaction, 2025. URLhttps://arxiv.org/abs/2503. 15661
2025
-
[22]
OS-ATLAS: A Foundation Action Model for Generalist GUI Agents
Z. Wu et al. OS-ATLAS: A foundation action model for generalist gui agents.arXiv preprint arXiv:2410.23218, 2024. doi: 10.48550/arXiv.2410.23218
work page internal anchor Pith review doi:10.48550/arxiv.2410.23218 2024
- [23]
-
[24]
doi: 10.48550/arXiv.2601.21961
-
[25]
F., Cheng, K.-T., and Chen, M.-H
S.-Y . Liu et al. DoRA: Weight-decomposed low-rank adaptation.arXiv preprint arXiv:2402.09353, 2024. doi: 10.48550/arXiv.2402.09353
-
[26]
Y . Peng, P. Wang, J. Liu, and S. Chen. GLAD: Generalizable tuning for vision-language models. arXiv preprint arXiv:2507.13089, 2025. doi: 10.48550/arXiv.2507.13089
-
[27]
T. Xue et al. EvoCUA: Evolving computer use agents via learning from scalable synthetic experience.arXiv preprint arXiv:2601.15876, 2026. doi: 10.48550/arXiv.2601.15876
-
[28]
H. Li et al. SpatialLadder: Progressive training for spatial reasoning in vision-language models. arXiv preprint arXiv:2510.08531, 2025. doi: 10.48550/arXiv.2510.08531
-
[29]
W. Kang, B. Lei, G. Liu, C. Ding, and Y . Yan. GuirlVG: Incentivize gui visual grounding via empirical exploration on reinforcement learning.arXiv preprint arXiv:2508.04389, 2025. doi: 10.48550/arXiv.2508.04389. 20 A Failure Mode Taxonomy We present qualitative examples for each failure mode identified in table 8. Each example includes the instruction, mo...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.