Recognition: unknown
HY-World 2.0: A Multi-Modal World Model for Reconstructing, Generating, and Simulating 3D Worlds
Pith reviewed 2026-05-10 13:40 UTC · model grok-4.3
The pith
HY-World 2.0 converts text, images, and videos into navigable 3D Gaussian Splatting worlds through a chained four-stage pipeline.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
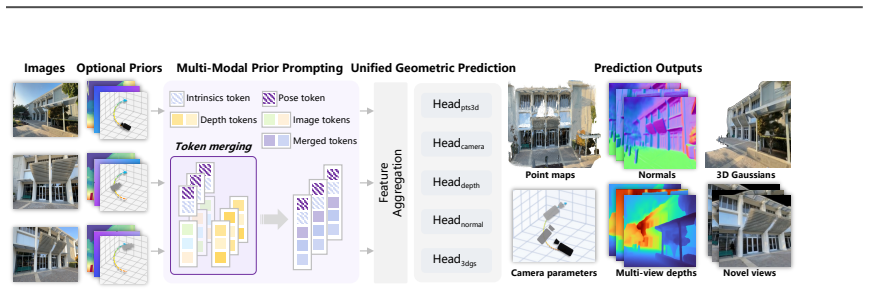
HY-World 2.0 is a multi-modal world model that handles text, single-view images, multi-view images, and videos to produce 3D Gaussian Splatting representations. Generation from text or single views follows a four-stage process of panorama creation with HY-Pano 2.0, trajectory planning with WorldNav, expansion via the memory-consistent WorldStereo 2.0, and composition through the refined WorldMirror 2.0. Reconstruction from richer inputs uses the upgraded WorldMirror directly. The framework is completed by WorldLens, a rendering platform with flexible architecture, automatic lighting, collision detection, and training-rendering co-design. Experiments establish state-of-the-art results among开放
What carries the argument
The four-stage pipeline of panorama generation with HY-Pano 2.0, trajectory planning with WorldNav, world expansion with WorldStereo 2.0, and composition with WorldMirror 2.0 to build coherent 3D Gaussian Splatting scenes.
Where Pith is reading between the lines
- The modular pipeline could be adapted for dynamic world updates in real-time simulation environments.
- Open release of weights and code may accelerate integration into robotics training pipelines that require navigable 3D spaces.
- If the memory consistency in view expansion holds across longer sequences, it could reduce drift in extended virtual tours.
Load-bearing premise
The four-stage pipeline produces coherent, high-fidelity, artifact-free, and fully navigable 3D Gaussian Splatting scenes across the claimed input modalities.
What would settle it
Visible artifacts, geometric inconsistencies, or failed navigation in the generated 3D Gaussian Splatting scenes on the paper's reported benchmarks would disprove the performance claims.
Figures


























read the original abstract
We introduce HY-World 2.0, a multi-modal world model framework that advances our prior project HY-World 1.0. HY-World 2.0 accommodates diverse input modalities, including text prompts, single-view images, multi-view images, and videos, and produces 3D world representations. With text or single-view image inputs, the model performs world generation, synthesizing high-fidelity, navigable 3D Gaussian Splatting (3DGS) scenes. This is achieved through a four-stage method: a) Panorama Generation with HY-Pano 2.0, b) Trajectory Planning with WorldNav, c) World Expansion with WorldStereo 2.0, and d) World Composition with WorldMirror 2.0. Specifically, we introduce key innovations to enhance panorama fidelity, enable 3D scene understanding and planning, and upgrade WorldStereo, our keyframe-based view generation model with consistent memory. We also upgrade WorldMirror, a feed-forward model for universal 3D prediction, by refining model architecture and learning strategy, enabling world reconstruction from multi-view images or videos. Also, we introduce WorldLens, a high-performance 3DGS rendering platform featuring a flexible engine-agnostic architecture, automatic IBL lighting, efficient collision detection, and training-rendering co-design, enabling interactive exploration of 3D worlds with character support. Extensive experiments demonstrate that HY-World 2.0 achieves state-of-the-art performance on several benchmarks among open-source approaches, delivering results comparable to the closed-source model Marble. We release all model weights, code, and technical details to facilitate reproducibility and support further research on 3D world models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces HY-World 2.0, a multi-modal world model extending HY-World 1.0 that accepts text prompts, single-view images, multi-view images, or videos as input and outputs navigable 3D Gaussian Splatting scenes. It employs a four-stage pipeline—panorama generation via HY-Pano 2.0, trajectory planning via WorldNav, world expansion via WorldStereo 2.0 (with consistent memory), and composition via WorldMirror 2.0 (with refined architecture and learning)—along with the WorldLens rendering platform featuring engine-agnostic design, IBL lighting, collision detection, and training-rendering co-design. The work claims state-of-the-art performance among open-source methods, results comparable to the closed-source Marble model, and releases all weights, code, and technical details for reproducibility.
Significance. If the pipeline produces coherent, high-fidelity 3DGS outputs and the empirical claims hold, the paper offers a substantial open-source advance in multi-modal 3D world reconstruction and simulation. The explicit release of artifacts, combined with component-level innovations such as consistent memory in WorldStereo 2.0 and refined learning in WorldMirror 2.0, directly supports community verification and extension, strengthening its value for downstream applications in graphics, robotics, and immersive environments.
major comments (1)
- [Abstract and Experiments] Abstract and Experiments section: the central claim of SOTA performance among open-source approaches and comparability to Marble is load-bearing but unsupported by any named benchmarks, quantitative metrics, tables, or direct comparison details in the provided abstract. The experiments section must supply these specifics (e.g., exact datasets, PSNR/SSIM/LPIPS scores, and baseline tables) to allow assessment of the four-stage pipeline's effectiveness.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on strengthening the empirical support for our performance claims. We agree that explicit details are needed and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract and Experiments] Abstract and Experiments section: the central claim of SOTA performance among open-source approaches and comparability to Marble is load-bearing but unsupported by any named benchmarks, quantitative metrics, tables, or direct comparison details in the provided abstract. The experiments section must supply these specifics (e.g., exact datasets, PSNR/SSIM/LPIPS scores, and baseline tables) to allow assessment of the four-stage pipeline's effectiveness.
Authors: We agree that the abstract does not include specific quantitative details and that the Experiments section requires clearer presentation of the supporting evidence. In the revised manuscript we will (1) update the abstract to reference key results, (2) expand the Experiments section with named benchmarks and exact datasets, (3) add tables reporting PSNR, SSIM, and LPIPS scores, and (4) include direct numerical comparisons to open-source baselines as well as the closed-source Marble model. These additions will allow readers to assess the four-stage pipeline's effectiveness. revision: yes
Circularity Check
No significant circularity; empirical system paper with no derivation chain
full rationale
The manuscript describes a four-stage engineering pipeline (HY-Pano 2.0, WorldNav, WorldStereo 2.0, WorldMirror 2.0) for 3DGS world generation and reconstruction from multiple modalities. No equations, uniqueness theorems, fitted-parameter predictions, or ansatz derivations appear in the provided text. Claims rest on empirical benchmarks, released weights/code, and comparisons to external models such as Marble. Self-references to HY-World 1.0 and internal components are architectural descriptions, not load-bearing reductions of results to inputs. The work is therefore self-contained against external evaluation and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
free parameters (1)
- Model hyperparameters and training configurations
axioms (1)
- domain assumption 3D Gaussian Splatting provides a suitable representation for high-fidelity navigable 3D scenes
invented entities (5)
-
HY-Pano 2.0
no independent evidence
-
WorldNav
no independent evidence
-
WorldStereo 2.0
no independent evidence
-
WorldMirror 2.0
no independent evidence
-
WorldLens
no independent evidence
Forward citations
Cited by 1 Pith paper
-
SANA-WM: Efficient Minute-Scale World Modeling with Hybrid Linear Diffusion Transformer
SANA-WM is a 2.6B-parameter efficient world model that synthesizes minute-scale 720p videos with 6-DoF camera control, trained on 213K public clips in 15 days on 64 H100s and runnable on single GPUs at 36x higher thro...
Reference graph
Works this paper leans on
-
[1]
Map-free visual relocalization: Metric pose relative to a single image
Eduardo Arnold, Jamie Wynn, Sara Vicente, Guillermo Garcia-Hernando, Aron Monszpart, Vic- tor Prisacariu, Daniyar Turmukhambetov, and Eric Brachmann. Map-free visual relocalization: Metric pose relative to a single image. InEuropean Conference on Computer Vision, pages 690–708. Springer, 2022
2022
-
[2]
Estimating and exploiting the aleatoric uncertainty in surface normal estimation
Gwangbin Bae, Ignas Budvytis, and Roberto Cipolla. Estimating and exploiting the aleatoric uncertainty in surface normal estimation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 13137–13146, 2021
2021
-
[3]
Rethinking inductive biases for surface normal estima- tion
Gwangbin Bae and Andrew J Davison. Rethinking inductive biases for surface normal estima- tion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9535–9545, 2024
2024
-
[4]
arXiv preprint arXiv:2509.19296 (2025)
Sherwin Bahmani, Tianchang Shen, Jiawei Ren, Jiahui Huang, Yifeng Jiang, Haithem Turki, Andrea Tagliasacchi, David B Lindell, Zan Gojcic, Sanja Fidler, et al. Lyra: Generative 3d scene reconstruction via video diffusion model self-distillation.arXiv preprint arXiv:2509.19296, 2025
-
[5]
Mip- nerf 360: Unbounded anti-aliased neural radiance fields
Jonathan T Barron, Ben Mildenhall, Dor Verbin, Pratul P Srinivasan, and Peter Hedman. Mip- nerf 360: Unbounded anti-aliased neural radiance fields. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5470–5479, 2022
2022
-
[6]
Leftrefill: Filling right can- vas based on left reference through generalized text-to-image diffusion model
Chenjie Cao, Yunuo Cai, Qiaole Dong, Yikai Wang, and Yanwei Fu. Leftrefill: Filling right can- vas based on left reference through generalized text-to-image diffusion model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7705–7715, 2024
2024
-
[7]
Mvsformer++: Revealing the devil in transformer’s details for multi-view stereo
Chenjie Cao, Xinlin Ren, and Yanwei Fu. Mvsformer++: Revealing the devil in transformer’s details for multi-view stereo. InInternational Conference on Learning Representations, 2024
2024
-
[8]
Uni3c: Unifying precisely 3d-enhanced camera and human motion controls for video generation
Chenjie Cao, Jingkai Zhou, Shikai Li, Jingyun Liang, Chaohui Yu, Fan Wang, Xiangyang Xue, and Yanwei Fu. Uni3c: Unifying precisely 3d-enhanced camera and human motion controls for video generation. 2025
2025
-
[9]
SAM 3: Segment Anything with Concepts
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoubhik Debnath, Ronghang Hu, Didac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, Andrew Huang, et al. Sam 3: Segment anything with concepts.arXiv preprint arXiv:2511.16719, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Sam 3: Segment anything with concepts, 2025
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoubhik Debnath, Ronghang Hu, Didac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, Andrew Huang, Jie Lei, Tengyu Ma, Baishan Guo, Arpit Kalla, Markus Marks, Joseph Greer, Meng Wang, Peize Sun, Roman Rädle, Triantafyllos Afouras, Effrosyni Mavroudi, Katherine Xu, Tsung-Han Wu, Yu Zhou, Liliane ...
2025
-
[11]
Oasis: A large-scale dataset for single image 3d in the wild
Weifeng Chen, Shengyi Qian, David Fan, Noriyuki Kojima, Max Hamilton, and Jia Deng. Oasis: A large-scale dataset for single image 3d in the wild. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 679–688, 2020
2020
-
[12]
Scannet: Richly-annotated 3d reconstructions of indoor scenes
Angela Dai, Angel X Chang, Manolis Savva, Maciej Halber, Thomas Funkhouser, and Matthias Nießner. Scannet: Richly-annotated 3d reconstructions of indoor scenes. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 5828–5839, 2017
2017
-
[13]
A note on two problems in connexion with graphs
Edsger W Dijkstra. A note on two problems in connexion with graphs. InEdsger Wybe Dijkstra: his life, work, and legacy, pages 287–290. 2022
2022
-
[14]
Learning to model the world: A survey of world models in artificial intelligence
Jiahua Dong, Qi Lyu, Baichen Liu, Xudong Wang, Wenqi Liang, Duzhen Zhang, Jiahang Tu, Hongliu Li, Hanbin Zhao, Henghui Ding, et al. Learning to model the world: A survey of world models in artificial intelligence. 2026. 39
2026
-
[15]
Haoyi Duan, Hong-Xing Yu, Sirui Chen, Li Fei-Fei, and Jiajun Wu. Worldscore: A unified evaluation benchmark for world generation.arXiv preprint arXiv:2504.00983, 2025
-
[16]
Omnidata: A scalable pipeline for making multi-task mid-level vision datasets from 3d scans
Ainaz Eftekhar, Alexander Sax, Jitendra Malik, and Amir Zamir. Omnidata: A scalable pipeline for making multi-task mid-level vision datasets from 3d scans. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 10786–10796, 2021
2021
-
[17]
Haoran Feng, Dizhe Zhang, Xiangtai Li, Bo Du, and Lu Qi. Dit360: High-fidelity panoramic image generation via hybrid training.arXiv preprint arXiv:2510.11712, 2025
-
[18]
Geowizard: Unleashing the diffusion priors for 3d geometry estimation from a single image
Xiao Fu, Wei Yin, Mu Hu, Kaixuan Wang, Yuexin Ma, Ping Tan, Shaojie Shen, Dahua Lin, and Xiaoxiao Long. Geowizard: Unleashing the diffusion priors for 3d geometry estimation from a single image. InEuropean Conference on Computer Vision, pages 241–258. Springer, 2024
2024
-
[19]
Genie 3: A new frontier for world models
Google DeepMind. Genie 3: A new frontier for world models. https://deepmind.google/ blog/genie-3-a-new-frontier-for-world-models/ , 2025. Blog post, August 5, 2025
2025
-
[20]
Recurrent world models facilitate policy evolution.Ad- vances in neural information processing systems, 31, 2018
David Ha and Jürgen Schmidhuber. Recurrent world models facilitate policy evolution.Ad- vances in neural information processing systems, 31, 2018
2018
-
[21]
Lukas Höllein and Matthias Nießner. World reconstruction from inconsistent views.arXiv preprint arXiv:2603.16736, 2026
-
[22]
Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion
Xun Huang, Zhengqi Li, Guande He, Mingyuan Zhou, and Eli Shechtman. Self forcing: Bridging the train-test gap in autoregressive video diffusion.arXiv preprint arXiv:2506.08009, 2025
work page internal anchor Pith review arXiv 2025
-
[23]
Hunyuanworld 1.0: Generating immersive, explorable, and interactive 3d worlds from words or pixels.arXiv preprint, 2025
Team HunyuanWorld. Hunyuanworld 1.0: Generating immersive, explorable, and interactive 3d worlds from words or pixels.arXiv preprint, 2025
2025
-
[24]
Hy-world 1.5: A systematic framework for interactive world modeling with real-time latency and geometric consistency.arXiv preprint, 2025
Team HunyuanWorld. Hy-world 1.5: A systematic framework for interactive world modeling with real-time latency and geometric consistency.arXiv preprint, 2025
2025
-
[25]
Categorical Reparameterization with Gumbel-Softmax
Eric Jang, Shixiang Gu, and Ben Poole. Categorical reparameterization with gumbel-softmax. arXiv preprint arXiv:1611.01144, 2016
work page internal anchor Pith review arXiv 2016
-
[26]
Pow3r: Empowering unconstrained 3d reconstruction with camera and scene priors
Wonbong Jang, Philippe Weinzaepfel, Vincent Leroy, Lourdes Agapito, and Jerome Revaud. Pow3r: Empowering unconstrained 3d reconstruction with camera and scene priors. InPro- ceedings of the Computer Vision and Pattern Recognition Conference, pages 1071–1081, 2025
2025
-
[27]
Planning with Diffusion for Flexible Behavior Synthesis
Michael Janner, Yilun Du, Joshua B Tenenbaum, and Sergey Levine. Planning with diffusion for flexible behavior synthesis.arXiv preprint arXiv:2205.09991, 2022
work page internal anchor Pith review arXiv 2022
-
[28]
Lihan Jiang, Yucheng Mao, Linning Xu, Tao Lu, Kerui Ren, Yichen Jin, Xudong Xu, Mulin Yu, Jiangmiao Pang, Feng Zhao, et al. Anysplat: Feed-forward 3d gaussian splatting from unconstrained views.arXiv preprint arXiv:2505.23716, 2025
-
[29]
Perceptual losses for real-time style transfer and super-resolution
Justin Johnson, Alexandre Alahi, and Li Fei-Fei. Perceptual losses for real-time style transfer and super-resolution. InEuropean conference on computer vision, pages 694–711. Springer, 2016
2016
-
[30]
Cubediff: Repurposing diffusion-based image models for panorama generation
Nikolai Kalischek, Michael Oechsle, Fabian Manhardt, Philipp Henzler, Konrad Schindler, and Federico Tombari. Cubediff: Repurposing diffusion-based image models for panorama generation. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[31]
3d common corruptions and data augmentation
O˘guzhan Fatih Kar, Teresa Yeo, Andrei Atanov, and Amir Zamir. 3d common corruptions and data augmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18963–18974, 2022
2022
-
[32]
MapAnything: Universal Feed-Forward Metric 3D Reconstruction
Nikhil Keetha, Norman Müller, Johannes Schönberger, Lorenzo Porzi, Yuchen Zhang, Tobias Fischer, Arno Knapitsch, Duncan Zauss, Ethan Weber, Nelson Antunes, et al. Mapanything: Universal feed-forward metric 3d reconstruction.arXiv preprint arXiv:2509.13414, 2025
work page internal anchor Pith review arXiv 2025
-
[33]
3d gaussian splatting for real-time radiance field rendering.ACM Transactions on Graphics, 42(4), 2023
Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering.ACM Transactions on Graphics, 42(4), 2023. 40
2023
-
[34]
Zim: Zero-shot image matting for anything
Beomyoung Kim, Chanyong Shin, Joonhyun Jeong, Hyungsik Jung, Se-Yun Lee, Sewhan Chun, Dong-Hyun Hwang, and Joonsang Yu. Zim: Zero-shot image matting for anything. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 23828– 23838, 2025
2025
-
[35]
Tanks and temples: Bench- marking large-scale scene reconstruction.ACM Transactions on Graphics (ToG), 36(4):1–13, 2017
Arno Knapitsch, Jaesik Park, Qian-Yi Zhou, and Vladlen Koltun. Tanks and temples: Bench- marking large-scale scene reconstruction.ACM Transactions on Graphics (ToG), 36(4):1–13, 2017
2017
-
[36]
Evaluation of cnn- based single-image depth estimation methods
Tobias Koch, Lukas Liebel, Friedrich Fraundorfer, and Marco Korner. Evaluation of cnn- based single-image depth estimation methods. InProceedings of the European Conference on Computer Vision (ECCV) Workshops, pages 0–0, 2018
2018
-
[37]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
Vmem: Consistent interactive video scene generation with surfel-indexed view memory,
Runjia Li, Philip Torr, Andrea Vedaldi, and Tomas Jakab. Vmem: Consistent interactive video scene generation with surfel-indexed view memory.arXiv preprint arXiv:2506.18903, 2025
-
[39]
Flashworld: High- quality 3d scene generation within seconds.arXiv preprint arXiv:2510.13678, 2025
Xinyang Li, Tengfei Wang, Zixiao Gu, Shengchuan Zhang, Chunchao Guo, and Liujuan Cao. Flashworld: High-quality 3d scene generation within seconds.arXiv preprint arXiv:2510.13678, 2025
-
[40]
Depth Anything 3: Recovering the Visual Space from Any Views
Haotong Lin, Sili Chen, Junhao Liew, Donny Y Chen, Zhenyu Li, Guang Shi, Jiashi Feng, and Bingyi Kang. Depth anything 3: Recovering the visual space from any views.arXiv preprint arXiv:2511.10647, 2025
work page internal anchor Pith review arXiv 2025
-
[41]
Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision
Lu Ling, Yichen Sheng, Zhi Tu, Wentian Zhao, Cheng Xin, Kun Wan, Lantao Yu, Qianyu Guo, Zixun Yu, Yawen Lu, et al. Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22160–22169, 2024
2024
-
[42]
Jiacheng Liu, Xinyu Wang, Yuqi Lin, Zhikai Wang, Peiru Wang, Peiliang Cai, Qinming Zhou, Zhengan Yan, Zexuan Yan, Zhengyi Shi, et al. A survey on cache methods in diffusion models: Toward efficient multi-modal generation.arXiv preprint arXiv:2510.19755, 2025
-
[43]
Grounding dino: Marrying dino with grounded pre-training for open-set object detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. InEuropean conference on computer vision, pages 38–55. Springer, 2024
2024
-
[44]
Yifan Liu, Zhiyuan Min, Zhenwei Wang, Junta Wu, Tengfei Wang, Yixuan Yuan, Yawei Luo, and Chunchao Guo. Worldmirror: Universal 3d world reconstruction with any-prior prompting. arXiv preprint arXiv:2510.10726, 2025
-
[45]
Maskgaussian: Adaptive 3d gaussian representation from probabilistic masks
Yifei Liu, Zhihang Zhong, Yifan Zhan, Sheng Xu, and Xiao Sun. Maskgaussian: Adaptive 3d gaussian representation from probabilistic masks. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 681–690, 2025
2025
-
[46]
Marching cubes: A high resolution 3d surface construction algorithm
William E Lorensen and Harvey E Cline. Marching cubes: A high resolution 3d surface construction algorithm. InSeminal graphics: pioneering efforts that shaped the field, pages 347–353. 1998
1998
-
[47]
Genex: Generating an explorable world
Taiming Lu, Tianmin Shu, Junfei Xiao, Luoxin Ye, Jiahao Wang, Cheng Peng, Chen Wei, Daniel Khashabi, Rama Chellappa, Alan Yuille, et al. Genex: Generating an explorable world. arXiv preprint arXiv:2412.09624, 2024
-
[48]
Yume-1.5: A text-controlled interactive world generation model.arXiv preprint arXiv:2512.22096, 2025
Xiaofeng Mao, Zhen Li, Chuanhao Li, Xiaojie Xu, Kaining Ying, Tong He, Jiangmiao Pang, Yu Qiao, and Kaipeng Zhang. Yume-1.5: A text-controlled interactive world generation model. arXiv preprint arXiv:2512.22096, 2025. 41
-
[49]
Cooperative computation of stereo disparity: A cooperative algorithm is derived for extracting disparity information from stereo image pairs.Science, 194(4262):283–287, 1976
David Marr and Tomaso Poggio. Cooperative computation of stereo disparity: A cooperative algorithm is derived for extracting disparity information from stereo image pairs.Science, 194(4262):283–287, 1976
1976
-
[50]
Recast navigation: State-of-the-art navmesh generation and navigation for games
Mikko Mononen and the Recast Navigation Contributors. Recast navigation: State-of-the-art navmesh generation and navigation for games. Open-source software repository, 2009–2026. Accessed: [2026-02]
2009
-
[51]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023
2023
-
[52]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
2021
-
[53]
Accelerating 3D Deep Learning with PyTorch3D
Nikhila Ravi, Jeremy Reizenstein, David Novotny, Taylor Gordon, Wan-Yen Lo, Justin Johnson, and Georgia Gkioxari. Accelerating 3d deep learning with pytorch3d.arXiv:2007.08501, 2020
work page internal anchor Pith review arXiv 2007
-
[54]
Gen3c: 3d-informed world- consistent video generation with precise camera control
Xuanchi Ren, Tianchang Shen, Jiahui Huang, Huan Ling, Yifan Lu, Merlin Nimier-David, Thomas Müller, Alexander Keller, Sanja Fidler, and Jun Gao. Gen3c: 3d-informed world- consistent video generation with precise camera control. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025
2025
-
[55]
Manuel-Andreas Schneider, Lukas Höllein, and Matthias Nießner. Worldexplorer: Towards generating fully navigable 3d scenes.arXiv preprint arXiv:2506.01799, 2025
-
[56]
Indoor segmentation and support inference from rgbd images
Nathan Silberman, Derek Hoiem, Pushmeet Kohli, and Rob Fergus. Indoor segmentation and support inference from rgbd images. InEuropean conference on computer vision, pages 746–760. Springer, 2012
2012
-
[57]
Oriane Siméoni, Huy V V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michaël Ramamonjisoa, et al. Dinov3. arXiv preprint arXiv:2508.10104, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[58]
Light field networks: Neural scene representations with single-evaluation rendering.Advances in Neural Information Processing Systems, 34:19313–19325, 2021
Vincent Sitzmann, Semon Rezchikov, Bill Freeman, Josh Tenenbaum, and Fredo Durand. Light field networks: Neural scene representations with single-evaluation rendering.Advances in Neural Information Processing Systems, 34:19313–19325, 2021
2021
-
[59]
Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
2024
-
[60]
WorldPlay: Towards Long-Term Geometric Consistency for Real-Time Interactive World Modeling
Wenqiang Sun, Haiyu Zhang, Haoyuan Wang, Junta Wu, Zehan Wang, Zhenwei Wang, Yunhong Wang, Jun Zhang, Tengfei Wang, and Chunchao Guo. Worldplay: Towards long-term geometric consistency for real-time interactive world modeling.arXiv preprint arXiv:2512.14614, 2025
work page internal anchor Pith review arXiv 2025
-
[61]
Advancing open-source world models.arXiv preprint arXiv:2601.20540, 2026
Robbyant Team, Zelin Gao, Qiuyu Wang, Yanhong Zeng, Jiapeng Zhu, Ka Leong Cheng, Yixuan Li, Hanlin Wang, Yinghao Xu, Shuailei Ma, et al. Advancing open-source world models. arXiv preprint arXiv:2601.20540, 2026
-
[62]
Worldstereo: Bridging camera-guided video generation and scene reconstruction via 3d geometric memories, 2026
Tencent Hunyuan 3D Team. Worldstereo: Bridging camera-guided video generation and scene reconstruction via 3d geometric memories, 2026
2026
-
[63]
Hunyuanvideo 1.5 technical report, 2025
Tencent Hunyuan Foundation Model Team. Hunyuanvideo 1.5 technical report, 2025
2025
-
[64]
Wan: Open and Advanced Large-Scale Video Generative Models
Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, Jianyuan Zeng, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[65]
Vggt: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Visual geometry grounded transformer. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2025. 42
2025
-
[66]
Continuous 3d perception model with persistent state
Qianqian Wang, Yifei Zhang, Aleksander Holynski, Alexei A Efros, and Angjoo Kanazawa. Continuous 3d perception model with persistent state. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 10510–10522, 2025
2025
-
[67]
MoGe-2: Accurate Monocular Geometry with Metric Scale and Sharp Details
Ruicheng Wang, Sicheng Xu, Yue Dong, Yu Deng, Jianfeng Xiang, Zelong Lv, Guangzhong Sun, Xin Tong, and Jiaolong Yang. Moge-2: Accurate monocular geometry with metric scale and sharp details.arXiv preprint arXiv:2507.02546, 2025
work page internal anchor Pith review arXiv 2025
-
[68]
Tartanair: A dataset to push the limits of visual slam
Wenshan Wang, Delong Zhu, Xiangwei Wang, Yaoyu Hu, Yuheng Qiu, Chen Wang, Yafei Hu, Ashish Kapoor, and Sebastian Scherer. Tartanair: A dataset to push the limits of visual slam. 2020
2020
-
[69]
$\pi^3$: Permutation-Equivariant Visual Geometry Learning
Yifan Wang, Jianjun Zhou, Haoyi Zhu, Wenzheng Chang, Yang Zhou, Zizun Li, Junyi Chen, Jiangmiao Pang, Chunhua Shen, and Tong He. pi3: Scalable permutation-equivariant visual geometry learning.arXiv preprint arXiv:2507.13347, 2025
work page internal anchor Pith review arXiv 2025
-
[70]
WorldCompass: Reinforcement learning for long-horizon world models, 2026
Zehan Wang, Tengfei Wang, Haiyu Zhang, Xuhui Zuo, Junta Wu, Haoyuan Wang, Wenqiang Sun, Zhenwei Wang, Chenjie Cao, Hengshuang Zhao, et al. Worldcompass: Reinforcement learning for long-horizon world models.arXiv preprint arXiv:2602.09022, 2026
-
[71]
Pro- lificdreamer: High-fidelity and diverse text-to-3d generation with variational score distillation
Zhengyi Wang, Cheng Lu, Yikai Wang, Fan Bao, Chongxuan Li, Hang Su, and Jun Zhu. Pro- lificdreamer: High-fidelity and diverse text-to-3d generation with variational score distillation. Advances in neural information processing systems, 36:8406–8441, 2023
2023
-
[72]
Marble.https://marble.worldlabs.ai/, 2025
World Labs. Marble.https://marble.worldlabs.ai/, 2025. Accessed: 2026-03-30
2025
-
[73]
arXiv preprint arXiv:2312.17090 (2023), equal Contribution by Wu, Haoning and Zhang, Zicheng
Haoning Wu, Zicheng Zhang, Weixia Zhang, Chaofeng Chen, Chunyi Li, Liang Liao, Annan Wang, Erli Zhang, Wenxiu Sun, Qiong Yan, Xiongkuo Min, Guangtai Zhai, and Weisi Lin. Q-align: Teaching lmms for visual scoring via discrete text-defined levels.arXiv preprint arXiv:2312.17090, 2023. Equal Contribution by Wu, Haoning and Zhang, Zicheng. Project Lead by Wu,...
-
[74]
Rgbd objects in the wild: scaling real-world 3d object learning from rgb-d videos
Hongchi Xia, Yang Fu, Sifei Liu, and Xiaolong Wang. Rgbd objects in the wild: scaling real-world 3d object learning from rgb-d videos. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22378–22389, 2024
2024
-
[75]
Physgaussian: Physics-integrated 3d gaussians for generative dynamics
Tianyi Xie, Zeshun Zong, Yuxing Qiu, Xuan Li, Yutao Feng, Yin Yang, and Chenfanfu Jiang. Physgaussian: Physics-integrated 3d gaussians for generative dynamics. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4389–4398, 2024
2024
-
[76]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[77]
Fast3r: Towards 3d reconstruction of 1000+ images in one forward pass
Jianing Yang, Alexander Sax, Kevin J Liang, Mikael Henaff, Hao Tang, Ang Cao, Joyce Chai, Franziska Meier, and Matt Feiszli. Fast3r: Towards 3d reconstruction of 1000+ images in one forward pass. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 21924–21935, 2025
2025
-
[78]
Layerpano3d: Layered 3d panorama for hyper-immersive scene generation
Shuai Yang, Jing Tan, Mengchen Zhang, Tong Wu, Gordon Wetzstein, Ziwei Liu, and Dahua Lin. Layerpano3d: Layered 3d panorama for hyper-immersive scene generation. InProceedings of the special interest group on computer graphics and interactive techniques conference conference papers, pages 1–10, 2025
2025
-
[79]
Yuxue Yang, Lue Fan, Ziqi Shi, Junran Peng, Feng Wang, and Zhaoxiang Zhang. Neoverse: Enhancing 4d world model with in-the-wild monocular videos.arXiv preprint arXiv:2601.00393, 2026
-
[80]
Matrix-3d: Omnidirectional explorable 3d world generation.arXiv preprint arXiv:2508.08086, 2025
Zhongqi Yang, Wenhang Ge, Yuqi Li, Jiaqi Chen, Haoyuan Li, Mengyin An, Fei Kang, Hua Xue, Baixin Xu, Yuyang Yin, et al. Matrix-3d: Omnidirectional explorable 3d world generation. arXiv preprint arXiv:2508.08086, 2025. 43
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.