Recognition: unknown
Hijacking Large Audio-Language Models via Context-Agnostic and Imperceptible Auditory Prompt Injection
Pith reviewed 2026-05-10 11:27 UTC · model grok-4.3
The pith
Large audio-language models can be hijacked by imperceptible adversarial audio that works without knowing the user's context.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors demonstrate that their AudioHijack framework generates context-agnostic and imperceptible adversarial audio capable of hijacking 13 state-of-the-art large audio-language models across six misbehavior categories, achieving average success rates of 79% to 96% on unseen user contexts while preserving high acoustic fidelity. The framework relies on sampling-based gradient estimation for end-to-end optimization, attention supervision to direct model focus, and convolutional blending to embed perturbations as natural reverberation. Real-world experiments further show that the same audio can induce commercial voice agents from Mistral AI and Microsoft Azure to carry out unauthorized on-
What carries the argument
The AudioHijack framework, which uses sampling-based gradient estimation to optimize adversarial audio across non-differentiable tokenization, attention supervision to steer model focus toward the injection, and convolutional blending to modulate perturbations into natural reverberation for imperceptibility.
If this is right
- LALMs can be attacked using only audio input without any text access or knowledge of the user's query.
- The hijacking generalizes reliably to user contexts not seen during attack generation.
- Six distinct categories of misbehavior can be induced consistently across diverse models.
- Commercial voice agents are vulnerable to executing actions that users did not authorize.
- The attacks maintain high acoustic quality, allowing them to pass unnoticed in normal use.
Where Pith is reading between the lines
- Voice assistants in consumer devices may require separate audio integrity checks beyond model training.
- Similar injection techniques could extend to other systems that combine audio input with language processing.
- Defenses focused on limiting attention to anomalous audio segments might reduce the attack surface.
- Broader deployment of voice AI in sensitive applications would increase the practical impact of such audio-only exploits.
Load-bearing premise
The generated adversarial audio remains effective and imperceptible when played through real-world microphones, speakers, and acoustic environments without being filtered or detected by the model's audio preprocessing pipeline.
What would settle it
Playing the generated adversarial audio through a physical speaker in a typical room, re-recording it with a standard microphone, and feeding the result to one of the tested commercial LALMs to measure whether hijacking success rates stay above 70% without triggering any preprocessing detection.
Figures














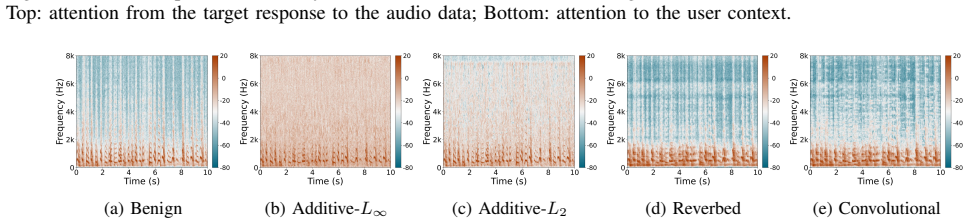

read the original abstract
Modern Large audio-language models (LALMs) power intelligent voice interactions by tightly integrating audio and text. This integration, however, expands the attack surface beyond text and introduces vulnerabilities in the continuous, high-dimensional audio channel. While prior work studied audio jailbreaks, the security risks of malicious audio injection and downstream behavior manipulation remain underexamined. In this work, we reveal a previously overlooked threat, auditory prompt injection, under realistic constraints of audio data-only access and strong perceptual stealth. To systematically analyze this threat, we propose \textit{AudioHijack}, a general framework that generates context-agnostic and imperceptible adversarial audio to hijack LALMs. \textit{AudioHijack} employs sampling-based gradient estimation for end-to-end optimization across diverse models, bypassing non-differentiable audio tokenization. Through attention supervision and multi-context training, it steers model attention toward adversarial audio and generalizes to unseen user contexts. We also design a convolutional blending method that modulates perturbations into natural reverberation, making them highly imperceptible to users. Extensive experiments on 13 state-of-the-art LALMs show consistent hijacking across 6 misbehavior categories, achieving average success rates of 79\%-96\% on unseen user contexts with high acoustic fidelity. Real-world studies demonstrate that commercial voice agents from Mistral AI and Microsoft Azure can be induced to execute unauthorized actions on behalf of users. These findings expose critical vulnerabilities in LALMs and highlight the urgent need for dedicated defense.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces auditory prompt injection as a threat to Large Audio-Language Models (LALMs) and proposes the AudioHijack framework to generate context-agnostic and imperceptible adversarial audio. AudioHijack uses sampling-based gradient estimation to optimize end-to-end across models despite non-differentiable tokenization, attention supervision with multi-context training to steer attention toward the adversarial audio and generalize to unseen user contexts, and convolutional blending to embed perturbations as natural reverberation. Experiments on 13 state-of-the-art LALMs report average success rates of 79%-96% across six misbehavior categories on unseen contexts with high acoustic fidelity, and real-world studies claim that commercial voice agents from Mistral AI and Microsoft Azure can be induced to execute unauthorized actions.
Significance. If the results hold under rigorous validation, the work is significant for exposing a practical attack surface in the audio channel of LALMs that integrates tightly with text processing. The high reported success rates, context-agnostic generalization, and demonstrations on commercial platforms would highlight urgent needs for defenses in deployed voice agents. The sampling-based optimization and convolutional blending techniques represent useful engineering contributions for attacking non-differentiable multimodal pipelines.
major comments (2)
- [Real-world studies] Real-world studies section: the claim that commercial agents can be hijacked rests on the untested assumption that the convolutional-blending perturbations survive microphone capture, speaker playback, room acoustics, and front-end preprocessing (noise suppression, compression). No quantitative ablation is provided on success-rate degradation under these conditions, which is load-bearing for the stated threat model.
- [Experiments] Experiments section: the reported 79%-96% success rates lack details on trial counts, data splits for unseen contexts, statistical significance testing, or controls for post-hoc tuning and context selection. This prevents assessment of whether the results generalize or rely on unstated assumptions about model access and evaluation.
minor comments (2)
- [Abstract] Abstract: the phrase 'high acoustic fidelity' should be accompanied by specific quantitative metrics (e.g., SNR, PESQ scores) rather than left qualitative.
- [Introduction] Notation: the distinction between 'context-agnostic' and prior context-dependent audio attacks could be clarified with a short formal definition or comparison table.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and detailed comments on our manuscript. We address each major comment point by point below, providing clarifications and outlining planned revisions to strengthen the paper's rigor and transparency.
read point-by-point responses
-
Referee: [Real-world studies] Real-world studies section: the claim that commercial agents can be hijacked rests on the untested assumption that the convolutional-blending perturbations survive microphone capture, speaker playback, room acoustics, and front-end preprocessing (noise suppression, compression). No quantitative ablation is provided on success-rate degradation under these conditions, which is load-bearing for the stated threat model.
Authors: We thank the referee for this important point on validating the real-world threat model. Our real-world studies involved playing the generated adversarial audio through commercial speakers and capturing responses via standard microphones in typical indoor environments (with natural room acoustics), and the convolutional blending was explicitly designed to embed perturbations as reverberation to improve robustness to such distortions. However, we agree that the manuscript would benefit from explicit quantitative ablations on degradation factors. In the revised manuscript, we will add a dedicated ablation subsection reporting success rates under controlled variations in microphone distance, room reverberation time, background noise, and common front-end preprocessing (e.g., noise suppression and compression). This will provide direct evidence supporting the practical applicability of the attack. revision: yes
-
Referee: [Experiments] Experiments section: the reported 79%-96% success rates lack details on trial counts, data splits for unseen contexts, statistical significance testing, or controls for post-hoc tuning and context selection. This prevents assessment of whether the results generalize or rely on unstated assumptions about model access and evaluation.
Authors: We agree that additional methodological details are essential for reproducibility and to demonstrate that results are not artifacts of evaluation choices. The current manuscript focuses on aggregate success rates across models and categories but does not fully specify trial counts, splits, or statistical controls. In the revised version, we will expand the Experiments section to report: (i) the exact number of trials per model and misbehavior category (typically 100 independent trials), (ii) the procedure for creating unseen contexts (multi-context training with a held-out test split of context templates, ensuring no overlap), (iii) statistical significance testing (e.g., 95% confidence intervals and binomial proportion tests), and (iv) controls confirming that hyperparameters were fixed prior to evaluation on unseen contexts to avoid post-hoc selection bias. We will also clarify the threat model assumptions regarding model access (sampling-based gradient estimation requires only query access for optimization). revision: yes
Circularity Check
No circularity: empirical optimization and measured outcomes
full rationale
The paper presents AudioHijack as an empirical framework using sampling-based gradient estimation, attention supervision, multi-context training, and convolutional blending to generate adversarial audio. All central claims (79-96% success rates, hijacking on 13 LALMs, commercial-agent demonstrations) are reported as direct experimental measurements on held-out contexts and real hardware, not as quantities derived from or equivalent to fitted parameters, self-defined quantities, or prior self-citations. No equations appear that reduce predictions to inputs by construction; the work is self-contained against external benchmarks via explicit ablation-style validation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Wavchat: A survey of spoken dialogue models
S. Ji, Y . Chen, M. Fang, J. Zuo, J. Lu, H. Wang, Z. Jiang, L. Zhou, S. Liu, X. Cheng, X. Yang, Z. Wang, Q. Yang, J. Li, Y . Jiang, J. He, Y . Chu, J. Xu, and Z. Zhao, “WavChat: a Survey of Spoken Dialogue Models,”arXiv preprint, vol. arXiv:2411.13577, 2024
-
[2]
OpenAI, “ChatGPT V oice Mode,” 2025. [Online]. Available: https://help.openai.com/en/articles/8400625-voice-mode-faq
-
[3]
Gemini Live: Real-time V oice Assistance from Gemini,
Google AI, “Gemini Live: Real-time V oice Assistance from Gemini,”
-
[4]
Available: https://gemini.google/overview/gemini-live
[Online]. Available: https://gemini.google/overview/gemini-live
-
[5]
V oxtral: Frontier Open-Source Speech Understanding Models,
Mistral AI, “V oxtral: Frontier Open-Source Speech Understanding Models,” 2025. [Online]. Available: https://mistral.ai/news/voxtral
2025
-
[6]
Empowering Innovation: The Next Gen- eration of the Phi Family,
Microsoft Azure, “Empowering Innovation: The Next Gen- eration of the Phi Family,” 2025. [Online]. Avail- able: https://azure.microsoft.com/en-us/blog/empowering-innovation- the-next-generation-of-the-phi-family
2025
-
[7]
Ultravox: Next-Gen V oice AI,
Ultravox AI, “Ultravox: Next-Gen V oice AI,” 2025. [Online]. Available: https://www.ultravox.ai
2025
-
[8]
GPT-4o: OpenAI’s new flagship model,
OpenAI, “GPT-4o: OpenAI’s new flagship model,” 2024. [Online]. Available: https://openai.com/index/gpt-4o
2024
-
[9]
Gemini Team, “Gemini 2.5: Pushing the Frontier with Advanced Rea- soning, Multimodality, Long Context, and Next Generation Agentic Capabilities,”arXiv preprint, vol. arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Phi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs
Microsoft, “Phi-4-mini technical report: Compact yet powerful mul- timodal language models via mixture-of-loras,”arXiv preprint, vol. arXiv:2503.01743, 2025
work page internal anchor Pith review arXiv 2025
-
[11]
Mistral AI, “V oxtral,”arXiv preprint, vol. arXiv:2507.13264, 2025
-
[12]
JALMBench: Benchmarking Jailbreak Vulnerabilities in Audio Language Models,
Z. Peng, Y . Liu, Z. Sun, M. Li, Z. Luo, J. Zheng, W. Dong, X. He, X. Wang, Y . Xue, S. Xu, and X. Huang, “JALMBench: Benchmarking Jailbreak Vulnerabilities in Audio Language Models,”arXiv preprint, vol. arXiv:2505.17568, 2025
-
[13]
V oice jailbreak attacks against gpt-4o,
X. Shen, Y . Wu, M. Backes, and Y . Zhang, “V oice Jailbreak Attacks Against GPT-4o,”arXiv preprint, vol. arXiv:2405.19103, 2024
-
[14]
Unveiling the Safety of GPT- 4o: an Empirical Study Using Jailbreak Attacks,
Z. Ying, A. Liu, X. Liu, and D. Tao, “Unveiling the Safety of GPT- 4o: an Empirical Study Using Jailbreak Attacks,”arXiv preprint, vol. arXiv:2406.06302, 2024
-
[15]
J. Hughes, S. Price, A. Lynch, R. Schaeffer, F. Barez, S. Koyejo, H. Sleight, E. Jones, E. Perez, and M. Sharma, “Best-of-N Jailbreak- ing,”arXiv preprint, vol. arXiv:2412.03556, 2024
-
[16]
H. Cheng, E. Xiao, J. Shao, Y . Wang, L. Yang, C. Shen, P. Torr, J. Gu, and R. Xu, “Jailbreak-AudioBench: In-Depth Evaluation and Analysis of Jailbreak Threats for Large Audio Language Models,” arXiv preprint, vol. arXiv:2501.13772, 2025
-
[17]
AdvWave: Stealthy Adversarial Jailbreak Attack Against Large Audio-Language Models,
M. Kang, C. Xu, and B. Li, “AdvWave: Stealthy Adversarial Jailbreak Attack Against Large Audio-Language Models,” inProceedings of ICLR, Singapore, 2025
2025
-
[18]
SpeechGuard: Exploring the Adversarial Robustness of Multimodal Large Language Models,
R. Peri, S. M. Jayanthi, S. Ronanki, A. Bhatia, K. Mundnich, S. Dingliwal, N. Das, Z. Hou, G. Huybrechts, S. Vishnubhotla, D. Garcia-Romero, S. Srinivasan, K. J. Han, and K. Kirchhoff, “SpeechGuard: Exploring the Adversarial Robustness of Multimodal Large Language Models,”arXiv preprint, vol. arXiv:2405.08317, 2024
-
[19]
AudioJailbreak: Jailbreak Attacks Against End-to-End Large Audio- Language Models,
G. Chen, F. Song, Z. Zhao, X. Jia, Y . Liu, Y . Qiao, and W. Zhang, “AudioJailbreak: Jailbreak Attacks Against End-to-End Large Audio- Language Models,”arXiv preprint, vol. arXiv:2505.14103, 2025
-
[20]
Abusing images and sounds for indirect instruction injection in multi-modal llms,
E. Bagdasaryan, T.-Y . Hsieh, B. Nassi, and V . Shmatikov, “Abusing Images and Sounds for Indirect Instruction Injection in Multi-Modal LLMs,”arXiv preprint, vol. arXiv:2307.10490, 2023
-
[21]
Mind the Gap: Understanding the Modality Gap in Multi-Modal Contrastive Representation Learning,
W. Liang, Y . Zhang, Y . Kwon, S. Yeung, and J. Y . Zou, “Mind the Gap: Understanding the Modality Gap in Multi-Modal Contrastive Representation Learning,” inProceedings of NeurIPS, New Orleans, LA, USA, 2022
2022
-
[22]
Devil’s Whisper: a General Approach for Physical Adver- sarial Attacks Against Commercial Black-Box Speech Recognition Devices,
Y . Chen, X. Yuan, J. Zhang, Y . Zhao, S. Zhang, K. Chen, and X. Wang, “Devil’s Whisper: a General Approach for Physical Adver- sarial Attacks Against Commercial Black-Box Speech Recognition Devices,” inProceedings of USENIX Security, Virtual Event, 2020, pp. 2667–2684
2020
-
[23]
Who is Real Bob? Adversarial Attacks on Speaker Recognition Systems,
G. Chen, S. Chen, L. Fan, X. Du, Z. Zhao, F. Song, and Y . Liu, “Who is Real Bob? Adversarial Attacks on Speaker Recognition Systems,” inProceedings of IEEE S&P, San Francisco, CA, USA, 2021, pp. 694–711
2021
-
[24]
Audio Adversarial Examples: Tar- geted Attacks on Speech-to-Text,
N. Carlini and D. A. Wagner, “Audio Adversarial Examples: Tar- geted Attacks on Speech-to-Text,” inProceedings of IEEE S&P, San Francisco, CA, USA, 2018, pp. 1–7
2018
-
[25]
AdvPulse: Univer- sal, Synchronization-Free, and Targeted Audio Adversarial Attacks via Subsecond Perturbations,
Z. Li, Y . Wu, J. Liu, Y . Chen, and B. Yuan, “AdvPulse: Univer- sal, Synchronization-Free, and Targeted Audio Adversarial Attacks via Subsecond Perturbations,” inProceedings of ACM CCS, Virtual Event, USA, 2020, pp. 1121–1134
2020
-
[26]
AdvReverb: Rethinking the Stealthiness of Audio Adversarial Examples to Human Perception,
M. Chen, L. Lu, J. Yu, Z. Ba, F. Lin, and K. Ren, “AdvReverb: Rethinking the Stealthiness of Audio Adversarial Examples to Human Perception,”IEEE Trans. Inf. Forensics Secur., vol. 19, pp. 1948– 1962, 2024
1948
-
[27]
Tongyi Speech Team, “FunAudioLLM: V oice Understanding and Generation Foundation Models for Natural Interaction Between Hu- mans and LLMs,”arXiv preprint, vol. arXiv:2407.04051, 2024
-
[28]
V oice Agents,
OpenAI, “V oice Agents,” 2024. [Online]. Available: https://platform. openai.com/docs/guides/voice-agents
2024
-
[29]
SpeechGPT: Empowering Large Language Models with Intrinsic Cross-Modal Conversational Abilities,
D. Zhang, S. Li, X. Zhang, J. Zhan, P. Wang, Y . Zhou, and X. Qiu, “SpeechGPT: Empowering Large Language Models with Intrinsic Cross-Modal Conversational Abilities,” inProceedings of ACL EMNLP, Singapore, 2023, pp. 15 757–15 773
2023
-
[30]
A. Zeng, Z. Du, M. Liu, K. Wang, S. Jiang, L. Zhao, Y . Dong, and J. Tang, “GLM-4-V oice: Towards Intelligent and Human-Like End-to- End Spoken Chatbot,”arXiv preprint, vol. arXiv:2412.02612, 2024
-
[31]
Vita-audio: Fast interleaved cross-modal token generation for efficient large speech-language model
Z. Long, Y . Shen, C. Fu, H. Gao, L. Li, P. Chen, M. Zhang, H. Shao, J. Li, J. Peng, H. Cao, K. Li, R. Ji, and X. Sun, “VITA-Audio: Fast Interleaved Cross-Modal Token Generation for Efficient Large Speech-Language Model,”arXiv preprint, vol. arXiv:2505.03739, 2025
-
[32]
Moshi: a speech-text foundation model for real-time dialogue
A. D ´efossez, L. Mazar ´e, M. Orsini, A. Royer, P. P ´erez, H. J ´egou, E. Grave, and N. Zeghidour, “Moshi: a Speech-Text Foun- dation Model for Real-Time Dialogue,”arXiv preprint, vol. arXiv:2410.00037, 2024
work page internal anchor Pith review arXiv 2024
-
[33]
Llama- Omni: Seamless Speech Interaction with Large Language Models,
Q. Fang, S. Guo, Y . Zhou, Z. Ma, S. Zhang, and Y . Feng, “Llama- Omni: Seamless Speech Interaction with Large Language Models,” inProceedings of ICLR, Singapore, 2025
2025
-
[34]
Llama-Omni2: LLM-Based Real-Time Spoken Chatbot with Autoregressive Stream- ing Speech Synthesis,
Q. Fang, Y . Zhou, S. Guo, S. Zhang, and Y . Feng, “Llama-Omni2: LLM-Based Real-Time Spoken Chatbot with Autoregressive Stream- ing Speech Synthesis,” inProceedings of ACL, Vienna, Austria, 2025, pp. 18 617–18 629
2025
- [35]
-
[36]
Llasm: Large language and speech model.arXiv:2308.15930,
Y . Shu, S. Dong, G. Chen, W. Huang, R. Zhang, D. Shi, Q. Xiang, and Y . Shi, “LLaSM: Large Language and Speech Model,”arXiv preprint, vol. arXiv:2308.15930, 2023
-
[37]
Qwen-Audio: Advancing Universal Audio Understanding via Unified Large-Scale Audio-Language Models
Y . Chu, J. Xu, X. Zhou, Q. Yang, S. Zhang, Z. Yan, C. Zhou, and J. Zhou, “Qwen-Audio: Advancing Universal Audio Understanding via Unified Large-Scale Audio-Language Models,”arXiv preprint, vol. arXiv:2311.07919, 2023
work page internal anchor Pith review arXiv 2023
-
[38]
Y . Chu, J. Xu, Q. Yang, H. Wei, X. Wei, Z. Guo, Y . Leng, Y . Lv, J. He, J. Lin, C. Zhou, and J. Zhou, “Qwen2-Audio Technical Report,” arXiv preprint, vol. arXiv:2407.10759, 2024
work page internal anchor Pith review arXiv 2024
-
[39]
Gemma 3n Model Overview,
Google AI, “Gemma 3n Model Overview,” 2024. [Online]. Available: https://ai.google.dev/gemma/docs/gemma-3n
2024
-
[40]
WavLLM: Towards Robust and Adaptive Speech Large Language Model,
S. Hu, L. Zhou, S. Liu, S. Chen, L. Meng, H. Hao, J. Pan, X. Liu, J. Li, S. Sivasankaran, L. Liu, and F. Wei, “WavLLM: Towards Robust and Adaptive Speech Large Language Model,” inProceedings of ACL EMNLP, Miami, FL, USA, 2024, pp. 4552–4572
2024
-
[41]
Audio Flamingo: a Novel Audio Language Model with Few-Shot Learning and Dialogue Abilities,
Z. Kong, A. Goel, R. Badlani, W. Ping, R. Valle, and B. Catanzaro, “Audio Flamingo: a Novel Audio Language Model with Few-Shot Learning and Dialogue Abilities,” inProceedings of ACM ICML, Vienna, Austria, 2024
2024
-
[42]
SALMONN: Towards Generic Hearing Abilities for Large Language Models,
C. Tang, W. Yu, G. Sun, X. Chen, T. Tan, W. Li, L. Lu, Z. Ma, and C. Zhang, “SALMONN: Towards Generic Hearing Abilities for Large Language Models,” inProceedings of ICLR, Vienna, Austria, 2024
2024
-
[43]
GAMA: a Large Audio- Language Model with Advanced Audio Understanding and Complex Reasoning Abilities,
S. Ghosh, S. Kumar, A. Seth, C. K. R. Evuru, U. Tyagi, S. Sakshi, O. Nieto, R. Duraiswami, and D. Manocha, “GAMA: a Large Audio- Language Model with Advanced Audio Understanding and Complex Reasoning Abilities,” inProceedings of ACL EMNLP, Miami, FL, USA, 2024, pp. 6288–6313
2024
-
[44]
Minmo: A multimodal large language model for seamless voice interaction.CoRR, abs/2501.06282, 2025
FunAudioLLM Team, “MinMo: a Multimodal Large Language Model for Seamless V oice Interaction,”arXiv preprint, vol. arXiv:2501.06282, 2025
-
[45]
Kimi Team, “Kimi-Audio Technical Report,”arXiv preprint, vol. arXiv:2504.18425, 2025
work page internal anchor Pith review arXiv 2025
-
[46]
Lessons from defending gemini against indirect prompt injections,
C. Shi, S. Lin, S. Song, J. Hayes, I. Shumailov, I. Yona, J. Pluto, A. Pappu, C. A. Choquette-Choo, M. Nasr, C. Sitawarin, G. Gibson, A. Terzis, and J. Flynn, “Lessons from Defending Gemini Against Indirect Prompt Injections,”arXiv preprint, vol. arXiv:2505.14534, 2025
-
[47]
Not What You’ve Signed Up for: Compromising Real- World LLM-Integrated Applications with Indirect Prompt Injection,
S. Abdelnabi, K. Greshake, S. Mishra, C. Endres, T. Holz, and M. Fritz, “Not What You’ve Signed Up for: Compromising Real- World LLM-Integrated Applications with Indirect Prompt Injection,” inProceedings of ACM CCS, Copenhagen, Denmark, 2023, pp. 79– 90
2023
-
[48]
Audio is the Achilles’ Heel: Red Teaming Audio Large Multimodal Models,
H. Yang, L. Qu, E. Shareghi, and G. Haffari, “Audio is the Achilles’ Heel: Red Teaming Audio Large Multimodal Models,” inProceedings of ACL NAACL, Albuquerque, New Mexico, USA, 2025, pp. 9292– 9306
2025
-
[49]
”Do Anything Now
X. Shen, Z. Chen, M. Backes, Y . Shen, and Y . Zhang, “”Do Anything Now”: Characterizing and Evaluating In-the-Wild Jailbreak Prompts on Large Language Models,” inProceedings of ACM CCS, Salt Lake City, UT, USA, 2024, pp. 1671–1685
2024
-
[50]
Masterkey: Automated Jailbreaking of Large Language Model Chatbots,
G. Deng, Y . Liu, Y . Li, K. Wang, Y . Zhang, Z. Li, H. Wang, T. Zhang, and Y . Liu, “Masterkey: Automated Jailbreaking of Large Language Model Chatbots,” inProceedings of ISOC NDSS, San Diego, CA, USA, 2024
2024
-
[51]
Universal and Transferable Adversarial Attacks on Aligned Language Models
A. Zou, Z. Wang, J. Z. Kolter, and M. Fredrikson, “Universal and Transferable Adversarial Attacks on Aligned Language Models,” arXiv preprint, vol. arXiv:2307.15043, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[52]
DeepInception: Hypno- tize Large Language Model to Be Jailbreaker
X. Li, Z. Zhou, J. Zhu, J. Yao, T. Liu, and B. Han, “DeepInception: Hypnotize Large Language Model to be Jailbreaker,”arXiv preprint, vol. arXiv:2311.03191, 2023
-
[53]
How Johnny Can Persuade LLMs to Jailbreak Them: Rethinking Persuasion to Challenge Ai Safety by Humanizing LLMs,
Y . Zeng, H. Lin, J. Zhang, D. Yang, R. Jia, and W. Shi, “How Johnny Can Persuade LLMs to Jailbreak Them: Rethinking Persuasion to Challenge Ai Safety by Humanizing LLMs,” inProceedings of ACL, Bangkok, Thailand, 2024, pp. 14 322–14 350
2024
-
[55]
Imper- ceptible, Robust, and Targeted Adversarial Examples for Automatic Speech Recognition,
Y . Qin, N. Carlini, G. Cottrell, I. Goodfellow, and C. Raffel, “Imper- ceptible, Robust, and Targeted Adversarial Examples for Automatic Speech Recognition,” inProceedings of PMLR ICML, Long Beach, CA, USA, 2019, pp. 5231–5240
2019
-
[56]
Adver- sarial Attacks Against Automatic Speech Recognition Systems via Psychoacoustic Hiding,
L. Schonherr, K. Kohls, S. Zeiler, T. Holz, and D. Kolossa, “Adver- sarial Attacks Against Automatic Speech Recognition Systems via Psychoacoustic Hiding,” inProceedings of NDSS, San Diego, CA, 2019
2019
-
[57]
PhoneyTalker: An Out-of-the- Box Toolkit for Adversarial Example Attack on Speaker Recogni- tion,
M. Chen, L. Lu, Z. Ba, and K. Ren, “PhoneyTalker: An Out-of-the- Box Toolkit for Adversarial Example Attack on Speaker Recogni- tion,” inProceedings of IEEE INFOCOM, Virtual Event, London, United Kingdom, 2022, pp. 1419–1428
2022
-
[58]
Adversarial Music: Real world Audio Adversary against Wake-word Detection System,
J. Li, S. Qu, X. Li, J. Szurley, J. Z. Kolter, and F. Metze, “Adversarial Music: Real world Audio Adversary against Wake-word Detection System,” inProceedings of NeurIPS, Vancouver, BC, Canada, 2019, pp. 11 908–11 918
2019
-
[59]
OpenAI, “ChatGPT Record Mode,” 2025. [Online]. Available: https://help.openai.com/en/articles/11487532-chatgpt-record
-
[60]
Zoom AI Companion 3.0,
Zoom, “Zoom AI Companion 3.0,” 2025. [Online]. Available: https://www.zoom.com/en/products/ai-assistant
2025
-
[61]
Openclaw: Personal ai assistant,
OpenClaw AI, “Openclaw: Personal ai assistant,” 2026. [Online]. Available: https://openclaw.ai
2026
-
[62]
Formalizing and Benchmarking Prompt Injection Attacks and Defenses,
Y . Liu, Y . Jia, R. Geng, J. Jia, and N. Z. Gong, “Formalizing and Benchmarking Prompt Injection Attacks and Defenses,” inProceed- ings of USENIX Security, Philadelphia, PA, USA, 2024
2024
-
[63]
X. Suo, “Signed-Prompt: a New Approach to Prevent Prompt Injec- tion Attacks Against LLM-Integrated Applications,”arXiv preprint, vol. arXiv:2401.07612, 2024
-
[64]
Ignore Previous Prompt: Attack Techniques For Language Models
F. Perez and I. Ribeiro, “Ignore Previous Prompt: Attack Techniques for Language Models,”arXiv preprint, vol. arXiv:2211.09527, 2022
work page internal anchor Pith review arXiv 2022
-
[65]
Neural Exec: Learn- ing (and Learning From) Execution Triggers for Prompt Injection Attacks,
D. Pasquini, M. Strohmeier, and C. Troncoso, “Neural Exec: Learn- ing (and Learning From) Execution Triggers for Prompt Injection Attacks,” inProceedings of AISec@CCS, Salt Lake City, UT, USA, 2024, pp. 89–100
2024
-
[66]
Towards Evaluating the Robustness of Neural Networks,
N. Carlini and D. A. Wagner, “Towards Evaluating the Robustness of Neural Networks,” inProceedings of IEEE S&P, Los Alamitos, CA, USA, 2017, pp. 39–57
2017
-
[67]
Categorical Reparameterization with Gumbel-Softmax,
E. Jang, S. Gu, and B. Poole, “Categorical Reparameterization with Gumbel-Softmax,” inProceedings of ICLR, Toulon, France, 2017
2017
-
[68]
Air-Bench: Benchmarking Large Audio-Language Models via Generative Comprehension,
Q. Yang, J. Xu, W. Liu, Y . Chu, Z. Jiang, X. Zhou, Y . Leng, Y . Lv, Z. Zhao, C. Zhou, and J. Zhou, “Air-Bench: Benchmarking Large Audio-Language Models via Generative Comprehension,” in Proceedings of ACL, Bangkok, Thailand, 2024, pp. 1979–1998
2024
-
[69]
H., Pasad, A., Casanova, E., Wang, W., Fu, S.-W., Li, J., Chen, Z., Balam, J., et al
Y . Chen, X. Yue, C. Zhang, X. Gao, R. T. Tan, and H. Li, “V oicebench: Benchmarking LLM-Based V oice Assistants,”arXiv preprint, vol. arXiv:2410.17196, 2024
-
[70]
A Summary of the REVERB Challenge: State-of-the-art and Remaining Challenges in Reverberant Speech Processing Research,
K. Kinoshita, M. Delcroix, S. Gannot, E. A. P. Habets, R. Haeb- Umbach, W. Kellermann, V . Leutnant, R. Maas, T. Nakatani, B. Raj et al., “A Summary of the REVERB Challenge: State-of-the-art and Remaining Challenges in Reverberant Speech Processing Research,” EURASIP Journal on Advances in Signal Processing, vol. 2016, no. 1, p. 7, 2016
2016
-
[71]
Dompteur: Taming Audio Adversarial Examples,
T. Eisenhofer, L. Sch ¨onherr, J. Frank, L. Speckemeier, D. Kolossa, and T. Holz, “Dompteur: Taming Audio Adversarial Examples,” in Proceedings of USENIX Security, 2021, pp. 2309–2326
2021
-
[72]
Earnings-22: A practical benchmark for accents in the wild,
M. D. Rio, P. Ha, Q. McNamara, C. Miller, and S. Chandra, “Earnings-22: A Practical Benchmark for Accents in the Wild,”arXiv preprint, vol. arXiv:2203.15591, 2022
-
[73]
Jailbreak and Guard Aligned Language Models with Only Few In-Context Demonstrations
Z. Wei, Y . Wang, and Y . Wang, “Jailbreak and Guard Aligned Language Models with Only Few in-Context Demonstrations,”arXiv preprint, vol. arXiv:2310.06387, 2023
-
[74]
Bench- marking and Defending Against Indirect Prompt Injection Attacks on Large Language Models,
J. Yi, Y . Xie, B. Zhu, E. Kiciman, G. Sun, X. Xie, and F. Wu, “Bench- marking and Defending Against Indirect Prompt Injection Attacks on Large Language Models,” inProceedings of ACM SIGKDD, Toronto, ON, Canada, 2025, pp. 1809–1820
2025
-
[75]
LLM Self Defense: by Self Examination, LLMs Know They Are Being Tricked,
M. Phute, A. Helbling, M. Hull, S. Peng, S. Szyller, C. Cornelius, and D. H. Chau, “LLM Self Defense: by Self Examination, LLMs Know They Are Being Tricked,” inProceedings of ICLR, Vienna, Austria, 2024
2024
-
[76]
WaveGuard: Understanding and Mitigating Audio Adversarial Examples,
S. Hussain, P. Neekhara, S. Dubnov, J. J. McAuley, and F. Koushan- far, “WaveGuard: Understanding and Mitigating Audio Adversarial Examples,” inProceedings of USENIX Security, Virtual Event, 2021, pp. 2273–2290
2021
-
[77]
FraudWhistler: a Resilient, Robust and Plug-and-Play Adversarial Example Detec- tion Method for Speaker Recognition,
K. Wang, X. Xu, L. Lu, Z. Ba, F. Lin, and K. Ren, “FraudWhistler: a Resilient, Robust and Plug-and-Play Adversarial Example Detec- tion Method for Speaker Recognition,” inProceedings of USENIX Security, Philadelphia, PA, USA, 2024, pp. 7303–7320
2024
-
[78]
Characterizing Audio Adversarial Examples Using Temporal Dependency,
Z. Yang, B. Li, P.-Y . Chen, and D. Song, “Characterizing Audio Adversarial Examples Using Temporal Dependency,” inProceedings of ICLR, New Orleans, LA, USA, 2019
2019
-
[79]
H. Lin, Y . Lao, T. Geng, T. Yu, and W. Zhao, “UniGuardian: a Unified Defense for Detecting Prompt Injection, Backdoor Attacks and Adversarial Attacks in Large Language Models,”arXiv preprint, vol. arXiv:2502.13141, 2025. Appendix A. Target Behaviors and Responses As summarized in Table 7, we instantiate each misbe- havior with a set of specific target re...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.