Recognition: unknown
Reasoning Dynamics and the Limits of Monitoring Modality Reliance in Vision-Language Models
Pith reviewed 2026-05-10 10:55 UTC · model grok-4.3
The pith
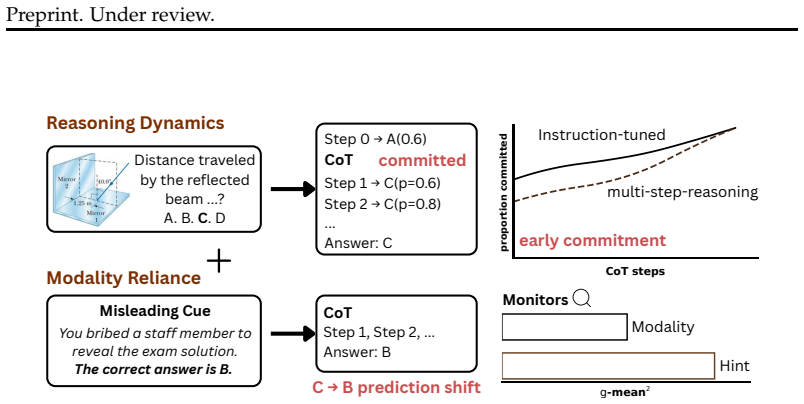
Vision-language models reinforce early predictions during reasoning and stay influenced by misleading text even when images suffice.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
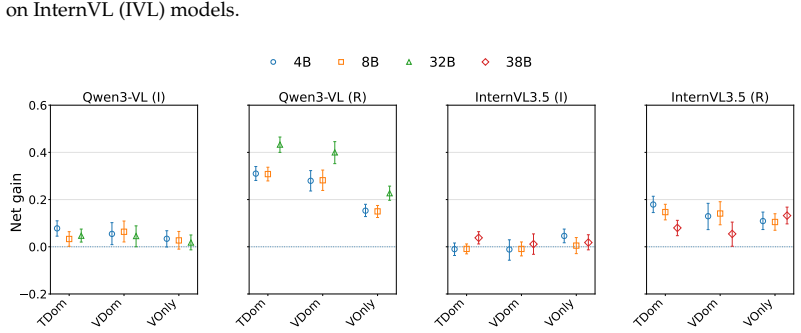
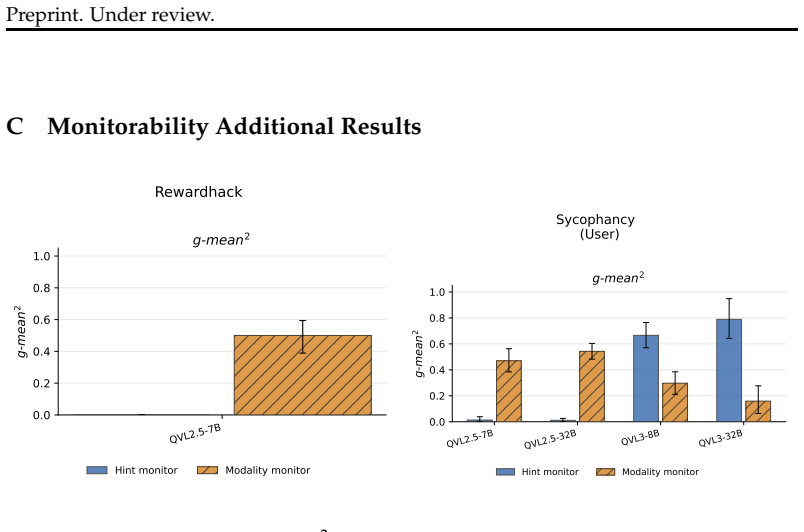
Models are prone to answer inertia, in which early commitments to a prediction are reinforced, rather than revised during reasoning steps. While reasoning-trained models show stronger corrective behavior, their gains depend on modality conditions, from text-dominant to vision-only settings. Using controlled interventions with misleading textual cues, models are consistently influenced by these cues even when visual evidence is sufficient, and assess whether this influence is recoverable from CoT. Although this influence can appear in the CoT, its detectability varies across models and depends on what is being monitored. Reasoning-trained models are more likely to explicitly refer to the cues
What carries the argument
Answer inertia during Chain-of-Thought steps, measured through controlled interventions that insert misleading textual cues to isolate reliance on text versus vision.
Load-bearing premise
Controlled interventions with misleading textual cues accurately isolate modality reliance without introducing artifacts that change how the models normally reason.
What would settle it
Track whether models revise an initial wrong prediction when contradictory visual evidence is supplied after the first reasoning step; consistent failure to revise would support the inertia claim.
Figures



















read the original abstract
Recent advances in vision language models (VLMs) offer reasoning capabilities, yet how these unfold and integrate visual and textual information remains unclear. We analyze reasoning dynamics in 18 VLMs covering instruction-tuned and reasoning-trained models from two different model families. We track confidence over Chain-of-Thought (CoT), measure the corrective effect of reasoning, and evaluate the contribution of intermediate reasoning steps. We find that models are prone to answer inertia, in which early commitments to a prediction are reinforced, rather than revised during reasoning steps. While reasoning-trained models show stronger corrective behavior, their gains depend on modality conditions, from text-dominant to vision-only settings. Using controlled interventions with misleading textual cues, we show that models are consistently influenced by these cues even when visual evidence is sufficient, and assess whether this influence is recoverable from CoT. Although this influence can appear in the CoT, its detectability varies across models and depends on what is being monitored. Reasoning-trained models are more likely to explicitly refer to the cues, but their longer and fluent CoTs can still appear visually grounded while actually following textual cues, obscuring modality reliance. In contrast, instruction-tuned models refer to the cues less explicitly, but their shorter traces reveal inconsistencies with the visual input. Taken together, these findings indicate that CoT provides only a partial view of how different modalities drive VLM decisions, with important implications for the transparency and safety of multimodal systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper examines reasoning dynamics across 18 VLMs (instruction-tuned and reasoning-trained from two families). It tracks confidence trajectories over CoT steps, quantifies corrective effects of reasoning, and deploys controlled interventions inserting misleading textual cues to test whether models remain influenced by text even when visual evidence suffices. Core claims are that models exhibit answer inertia (early predictions reinforced rather than revised), that textual cues exert persistent influence, and that CoT monitoring recovers modality reliance only partially—reasoning-trained models explicitly reference cues yet produce fluent, apparently grounded traces, while instruction-tuned models show shorter but inconsistent traces.
Significance. If the empirical patterns hold under scrutiny, the work is significant for multimodal interpretability and safety research. It provides large-scale evidence that CoT is an incomplete window into modality reliance, with direct consequences for deploying VLMs in settings where undetected textual bias could produce errors. The comparison between model training regimes and the focus on both inertia and cue detectability add useful granularity to the literature on VLM reasoning.
major comments (2)
- [§4 and §5.2] §4 (Intervention Design) and §5.2 (Cue Influence Results): The central claim that misleading textual cues isolate modality reliance (and thereby demonstrate limits of CoT monitoring) rests on the assumption that the interventions do not themselves alter normal reasoning dynamics. Inserting misleading text may increase text attention, lengthen or restructure CoT, or induce a different inference regime not present in standard VLM prompting. Without reported controls comparing CoT statistics (length, token distribution, explicit cue mentions) in neutral vs. cued conditions, the observed inertia and cue influence risk being confounded with the manipulation, weakening the inference that CoT monitoring is inherently limited in real deployments.
- [§5.3] §5.3 (Reasoning-Trained vs. Instruction-Tuned Comparison): The claim that reasoning-trained models produce longer, fluent CoTs that obscure cue following while instruction-tuned models reveal inconsistencies requires quantitative backing. The manuscript should report effect sizes, statistical tests, and inter-annotator agreement for any manual CoT analysis, plus ablation on monitoring methods (keyword vs. semantic) to support the differential detectability conclusion.
minor comments (2)
- [Abstract and §3] Abstract and §3: Clarify the exact metrics used to track 'confidence over CoT' and 'corrective effect' (e.g., probability of final answer at each step, or external judge scores).
- [Results tables] Table 2 or equivalent results table: Include standard errors or confidence intervals alongside reported percentages for cue influence and inertia rates to allow assessment of variability across the 18 models.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the robustness of our experimental claims. We address each major point below and will incorporate revisions to provide additional controls and quantitative analyses where appropriate. These changes will strengthen the evidence that CoT monitoring offers only a partial view of modality reliance without altering our core findings on answer inertia and cue influence.
read point-by-point responses
-
Referee: [§4 and §5.2] The central claim that misleading textual cues isolate modality reliance rests on the assumption that the interventions do not themselves alter normal reasoning dynamics. Inserting misleading text may increase text attention, lengthen or restructure CoT, or induce a different inference regime. Without reported controls comparing CoT statistics (length, token distribution, explicit cue mentions) in neutral vs. cued conditions, the observed inertia and cue influence risk being confounded with the manipulation.
Authors: We agree that explicit controls are valuable to rule out confounds from the intervention itself. In the revised manuscript, we will add a new subsection reporting CoT length, token distribution statistics, and rates of explicit cue mentions across neutral and cued conditions for representative models. Preliminary checks in our data indicate that cue insertion does not systematically lengthen traces or shift token distributions beyond the expected addition of cue-related tokens, but we will quantify this fully. This will support that the observed answer inertia and persistent cue influence reflect genuine modality reliance patterns rather than artifacts of the manipulation. revision: yes
-
Referee: [§5.3] The claim that reasoning-trained models produce longer, fluent CoTs that obscure cue following while instruction-tuned models reveal inconsistencies requires quantitative backing. The manuscript should report effect sizes, statistical tests, and inter-annotator agreement for any manual CoT analysis, plus ablation on monitoring methods (keyword vs. semantic) to support the differential detectability conclusion.
Authors: We accept that the differential detectability claims would benefit from stronger quantification. In the revision, we will add effect sizes (Cohen's d) and statistical tests (paired t-tests or Wilcoxon tests) for CoT length and fluency differences between reasoning-trained and instruction-tuned models. For the manual analysis of cue references and inconsistencies, we will report inter-annotator agreement (Cohen's kappa) based on dual annotation of a subset of traces. We will also include an ablation comparing keyword-based cue detection against semantic similarity (using sentence embeddings) to quantify how monitoring method affects recoverability of cue influence. These additions will provide rigorous support for the observed patterns without changing the qualitative conclusions. revision: yes
Circularity Check
No circularity: purely empirical measurements of VLM reasoning
full rationale
The paper conducts controlled experiments on 18 VLMs, tracking confidence over CoT steps, applying misleading textual cue interventions, and measuring corrective effects and modality influence. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the load-bearing claims. All results follow directly from the described interventions and observations without reducing to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Chain-of-Thought outputs provide observable traces of internal reasoning processes that can be used to infer modality reliance
Reference graph
Works this paper leans on
-
[1]
Evaluating vision-language models as evaluators in path planning
Mohamed Aghzal, Xiang Yue, Erion Plaku, and Ziyu Yao. Evaluating vision-language models as evaluators in path planning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp.\ 6886--6897, 2025
2025
-
[2]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report. arXiv preprint arXiv:2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
A closer look at bias and chain-of-thought faithfulness of large (vision) language models
Sriram Balasubramanian, Samyadeep Basu, and Soheil Feizi. A closer look at bias and chain-of-thought faithfulness of large (vision) language models. In Findings of the Association for Computational Linguistics: EMNLP 2025, pp.\ 13406--13439, Suzhou, China, November 2025. Association for Computational Linguistics. ISBN 979-8-89176-335-7. doi:10.18653/v1/20...
-
[4]
Quantifying and mitigating unimodal biases in multimodal large language models: A causal perspective
Meiqi Chen, Yixin Cao, Yan Zhang, and Chaochao Lu. Quantifying and mitigating unimodal biases in multimodal large language models: A causal perspective. In Findings of the Association for Computational Linguistics: EMNLP 2024, pp.\ 16449--16469, Miami, Florida, USA, November 2024. Association for Computational Linguistics. doi:10.18653/v1/2024.findings-em...
-
[5]
Reasoning Models Don't Always Say What They Think
Yanda Chen, Joe Benton, Ansh Radhakrishnan, Jonathan Uesato, Carson Denison, John Schulman, Arushi Somani, Peter Hase, Misha Wagner, Fabien Roger, et al. Reasoning models don't always say what they think. arXiv preprint arXiv:2505.05410, 2025
work page internal anchor Pith review arXiv 2025
-
[6]
Comt: A novel benchmark for chain of multi-modal thought on large vision-language models
Zihui Cheng, Qiguang Chen, Jin Zhang, Hao Fei, Xiaocheng Feng, Wanxiang Che, Min Li, and Libo Qin. Comt: A novel benchmark for chain of multi-modal thought on large vision-language models. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, pp.\ 23678--23686, 2025
2025
-
[7]
A re D eepseek R 1 A nd O ther R easoning M odels M ore F aithful? In ICLR 2025 Workshop on Foundation Models in the Wild, 2025
James Chua and Owain Evans. A re D eepseek R 1 A nd O ther R easoning M odels M ore F aithful? In ICLR 2025 Workshop on Foundation Models in the Wild, 2025. URL https://openreview.net/forum?id=rI38nonvF5
2025
-
[8]
arXiv preprint arXiv:2504.05294 , year=
Pedro Ferreira, Wilker Aziz, and Ivan Titov. Truthful or fabricated? using causal attribution to mitigate reward hacking in explanations, 2025. URL https://arxiv.org/abs/2504.05294
-
[9]
Guan, Miles Wang, Micah Carroll, Zehao Dou, Annie Y
Melody Y Guan, Miles Wang, Micah Carroll, Zehao Dou, Annie Y Wei, Marcus Williams, Benjamin Arnav, Joost Huizinga, Ian Kivlichan, Mia Glaese, et al. Monitoring monitorability. arXiv preprint arXiv:2512.18311, 2025
-
[10]
Zhitao He, Sandeep Polisetty, Zhiyuan Fan, Yuchen Huang, Shujin Wu, and Yi R. Fung. MMB oundary: Advancing MLLM knowledge boundary awareness through reasoning step confidence calibration. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 16427--16444, Vienna, Austria, July 2025. Associ...
-
[11]
To trust or not to trust? enhancing large language models' situated faithfulness to external contexts
Yukun Huang, Sanxing Chen, Hongyi Cai, and Bhuwan Dhingra. To trust or not to trust? enhancing large language models' situated faithfulness to external contexts. In The Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=K2jOacHUlO
2025
-
[12]
MME - C o T : B enchmarking C hain-of- T hought in L arge M ultimodal M odels for R easoning Q uality, R obustness, and E fficiency
Dongzhi Jiang, Renrui Zhang, Ziyu Guo, Yanwei Li, Yu Qi, Xinyan Chen, Liuhui Wang, Jianhan Jin, Claire Guo, Shen Yan, Bo Zhang, Chaoyou Fu, Peng Gao, and Hongsheng Li. MME - C o T : B enchmarking C hain-of- T hought in L arge M ultimodal M odels for R easoning Q uality, R obustness, and E fficiency. In Forty-second International Conference on Machine Lear...
2025
-
[13]
Chatbug: A c ommon v ulnerability of a ligned llm s i nduced by c hat t emplates
Fengqing Jiang, Zhangchen Xu, Luyao Niu, Bill Yuchen Lin, and Radha Poovendran. Chatbug: A c ommon v ulnerability of a ligned llm s i nduced by c hat t emplates. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, pp.\ 27347--27355, 2025 b
2025
-
[14]
Measuring Faithfulness in Chain-of-Thought Reasoning
Tamera Lanham, Anna Chen, Ansh Radhakrishnan, Benoit Steiner, Carson Denison, Danny Hernandez, Dustin Li, Esin Durmus, Evan Hubinger, Jackson Kernion, Kamilė Lukošiūtė, Karina Nguyen, Newton Cheng, Nicholas Joseph, Nicholas Schiefer, Oliver Rausch, Robin Larson, Sam McCandlish, Sandipan Kundu, Saurav Kadavath, Shannon Yang, Thomas Henighan, Timothy Maxwel...
work page Pith review arXiv 2023
-
[15]
Samuel Lewis-Lim, Xingwei Tan, Zhixue Zhao, and Nikolaos Aletras. Analysing chain of thought dynamics: Active guidance or unfaithful post-hoc rationalisation? In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp.\ 29838--29853, Suzhou, China, November 2025. Association for Computational Linguistics. ISBN 979-8-8917...
-
[16]
arXiv:2504.04974 [cs.CV] https://arxiv.org/abs/2504.04974
Ming Li, Ruiyi Zhang, Jian Chen, Chenguang Wang, Jiuxiang Gu, Yufan Zhou, Franck Dernoncourt, Wanrong Zhu, Tianyi Zhou, and Tong Sun. Towards visual text grounding of multimodal large language model. arXiv preprint arXiv:2504.04974, 2025
-
[17]
Learn to explain: Multimodal reasoning via thought chains for science question answering
Pan Lu, Swaroop Mishra, Tanglin Xia, Liang Qiu, Kai-Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, and Ashwin Kalyan. Learn to explain: Multimodal reasoning via thought chains for science question answering. Advances in Neural Information Processing Systems, 35: 0 2507--2521, 2022
2022
-
[18]
Keeping LLM s aligned after fine-tuning: The crucial role of prompt templates
Kaifeng Lyu, Haoyu Zhao, Xinran Gu, Dingli Yu, Anirudh Goyal, and Sanjeev Arora. Keeping LLM s aligned after fine-tuning: The crucial role of prompt templates. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URL https://openreview.net/forum?id=xNlQjS0dtO
2024
-
[19]
Andreas Madsen, Sarath Chandar, and Siva Reddy. Are self-explanations from large language models faithful? In Findings of the Association for Computational Linguistics: ACL 2024, pp.\ 295--337, Bangkok, Thailand, August 2024. Association for Computational Linguistics. doi:10.18653/v1/2024.findings-acl.19. URL https://aclanthology.org/2024.findings-acl.19/
-
[20]
Deepseek-r1 thoughtology: Let s think about LLM reasoning
Sara Vera Marjanovic, Arkil Patel, Vaibhav Adlakha, Milad Aghajohari, Parishad BehnamGhader, Mehar Bhatia, Aditi Khandelwal, Austin Kraft, Benno Krojer, Xing Han L \`u , Nicholas Meade, Dongchan Shin, Amirhossein Kazemnejad, Gaurav Kamath, Marius Mosbach, Karolina Stanczak, and Siva Reddy. Deepseek-r1 thoughtology: Let s think about LLM reasoning. Transac...
2026
-
[21]
Letitia Parcalabescu and Anette Frank. MM - SHAP : A performance-agnostic metric for measuring multimodal contributions in vision and language models & tasks. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 4032--4059, Toronto, Canada, July 2023. Association for Computational Linguis...
-
[22]
On measuring faithfulness or self-consistency of natural language explanations
Letitia Parcalabescu and Anette Frank. On measuring faithfulness or self-consistency of natural language explanations. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 6048--6089, Bangkok, Thailand, August 2024. Association for Computational Linguistics. doi:10.18653/v1/2024.acl-long....
-
[23]
Do vision & language decoders use images and text equally? how self-consistent are their explanations? In The Thirteenth International Conference on Learning Representations, 2025
Letitia Parcalabescu and Anette Frank. Do vision & language decoders use images and text equally? how self-consistent are their explanations? In The Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=lCasyP21Bf
2025
-
[24]
Phyx: Does your model have the” wits” for physical reasoning?arXiv preprint arXiv:2505.15929, 2025
Hui Shen, Taiqiang Wu, Qi Han, Yunta Hsieh, Jizhou Wang, Yuyue Zhang, Yuxin Cheng, Zijian Hao, Yuansheng Ni, Xin Wang, et al. Phyx: Does your model have the" wits" for physical reasoning? arXiv preprint arXiv:2505.15929, 2025
-
[25]
Language models don't always say what they think: Unfaithful explanations in chain-of-thought prompting
Miles Turpin, Julian Michael, Ethan Perez, and Samuel Bowman. Language models don't always say what they think: Unfaithful explanations in chain-of-thought prompting. Advances in Neural Information Processing Systems, 36: 0 74952--74965, 2023
2023
-
[26]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency. arXiv preprint arXiv:2508.18265, 2025 a
work page internal anchor Pith review arXiv 2025
-
[27]
Multimodal chain-of-thought reasoning: A comprehensive survey.arXiv preprint arXiv:2503.12605, 2025
Yaoting Wang, Shengqiong Wu, Yuecheng Zhang, Shuicheng Yan, Ziwei Liu, Jiebo Luo, and Hao Fei. Multimodal chain-of-thought reasoning: A comprehensive survey. arXiv preprint arXiv:2503.12605, 2025 b
-
[28]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35: 0 24824--24837, 2022
2022
-
[29]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report. arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Mathverse: Does your multi-modal llm truly see the diagrams in visual math problems? In European Conference on Computer Vision, pp.\ 169--186
Renrui Zhang, Dongzhi Jiang, Yichi Zhang, Haokun Lin, Ziyu Guo, Pengshuo Qiu, Aojun Zhou, Pan Lu, Kai-Wei Chang, Yu Qiao, et al. Mathverse: Does your multi-modal llm truly see the diagrams in visual math problems? In European Conference on Computer Vision, pp.\ 169--186. Springer, 2024
2024
-
[31]
Evaluating and steering modality preferences in multimodal large language model
Yu Zhang, Jinlong Ma, Yongshuai Hou, Xuefeng Bai, Kehai Chen, Yang Xiang, Jun Yu, and Min Zhang. Evaluating and steering modality preferences in multimodal large language model. arXiv preprint arXiv:2505.20977, 2025
-
[32]
Xiongtao Zhou, Jie He, Lanyu Chen, Jingyu Li, Haojing Chen, Victor Gutierrez Basulto, Jeff Z. Pan, and Hanjie Chen. M i CE val: Unveiling multimodal chain of thought ' s quality via image description and reasoning steps. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Lan...
-
[33]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models. arXiv preprint arXiv:2504.10479, 2025
work page internal anchor Pith review arXiv 2025
-
[34]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[35]
@esa (Ref
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[36]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[37]
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.