Recognition: unknown
Imperfectly Cooperative Human-AI Interactions: Comparing the Impacts of Human and AI Attributes in Simulated and User Studies
Pith reviewed 2026-05-10 09:36 UTC · model grok-4.3
The pith
AI transparency influences real human interactions more than personality traits, unlike in simulations where both factors weigh similarly.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
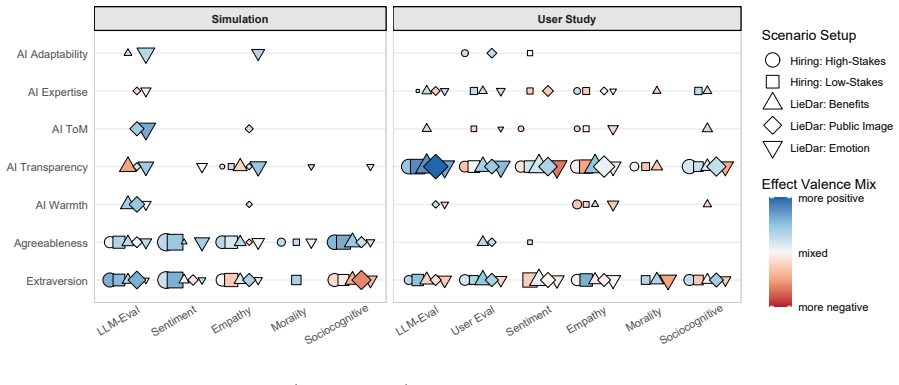
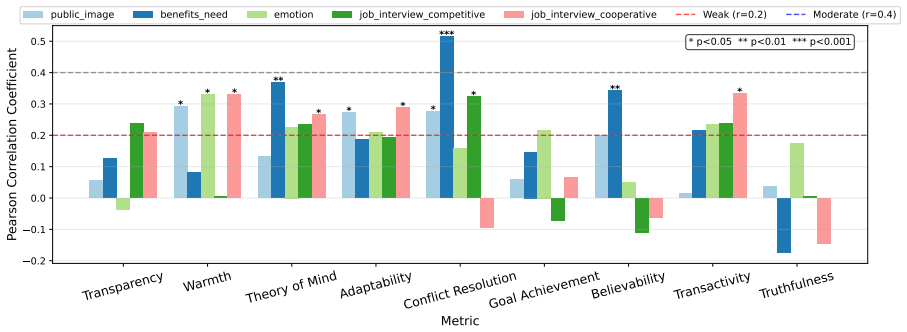
Causal discovery on the paired datasets establishes that personality traits and AI attributes exert comparable influence on interaction quality in the simulated imperfectly cooperative scenarios, yet in the parallel human-subject experiments AI attributes—particularly chain-of-thought transparency—become markedly more impactful, with additional variation across the hiring and transaction scenario categories.
What carries the argument
Causal discovery analysis that jointly models scenario outcomes, communication traces, and questionnaire measures to isolate relative causal contributions of Extraversion, Agreeableness, Adaptability, Expertise, and Transparency.
If this is right
- AI agents intended for real imperfectly cooperative settings should prioritize explicit reasoning transparency over other design attributes.
- Personality-trait matching or adaptation may deliver smaller returns in actual use than simulation results suggest.
- Separate design guidelines are needed for negotiation versus transactional contexts because the two scenario types produce distinct causal patterns.
- Evaluations limited to task performance miss the communication and relational effects captured by the integrated analysis.
- Development pipelines that rely exclusively on simulation risk over-weighting features whose impact shrinks when humans are involved.
Where Pith is reading between the lines
- The simulation-reality gap suggests that transparency mechanisms should be prototyped and measured directly with users rather than tuned inside simulated environments.
- Similar mismatches may appear in other high-stakes domains such as medical or legal assistance, where users must decide how much to trust an AI whose goals are only partially aligned.
- One testable extension is whether making specific internal states visible (for example, confidence estimates or alternative options considered) produces measurable gains in cooperation metrics.
- The work points toward a broader need for hybrid evaluation protocols that treat human-subject data as the primary source for causal claims about user-facing AI.
Load-bearing premise
The causal discovery procedure correctly attributes outcome differences to measured personality traits versus AI attributes without unmeasured confounders or systematic differences between how simulated agents and real humans form decisions.
What would settle it
Repeating the human experiment with a new participant pool or applying a different causal inference technique that yields no reliable difference in the relative strength of transparency versus personality would undermine the reported divergence.
Figures










read the original abstract
AI design characteristics and human personality traits each impact the quality and outcomes of human-AI interactions. However, their relative and joint impacts are underexplored in imperfectly cooperative scenarios, where people and AI only have partially aligned goals and objectives. This study compares a purely simulated dataset comprising 2,000 simulations and a parallel human subjects experiment involving 290 human participants to investigate these effects across two scenario categories: (1) hiring negotiations between human job candidates and AI hiring agents; and (2) human-AI transactions wherein AI agents may conceal information to maximize internal goals. We examine user Extraversion and Agreeableness alongside AI design characteristics, including Adaptability, Expertise, and chain-of-thought Transparency. Our causal discovery analysis extends performance-focused evaluations by integrating scenario-based outcomes, communication analysis, and questionnaire measures. Results reveal divergences between purely simulated and human study datasets, and between scenario types. In simulation experiments, personality traits and AI attributes were comparatively influential. Yet, with actual human subjects, AI attributes -- particularly transparency -- were much more impactful. We discuss how these divergences vary across different interaction contexts, offering crucial insights for the future of human-centered AI agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript compares a simulated dataset of 2,000 human-AI interactions with a human subjects experiment involving 290 participants in two imperfectly cooperative scenarios: hiring negotiations and transactions with potential information concealment. Using causal discovery, it examines the relative impacts of human personality traits (Extraversion and Agreeableness) and AI design attributes (Adaptability, Expertise, and Transparency), reporting divergences where simulations show balanced influence but human data highlight AI attributes, particularly transparency, as more impactful.
Significance. If the reported divergences hold under rigorous validation, the work is significant for highlighting the gap between simulated and real human-AI interactions in non-fully cooperative settings. It suggests that AI transparency plays an outsized role in actual user experiences, informing the design of AI agents that better account for human factors in imperfect cooperation. The integration of scenario outcomes, communication analysis, and questionnaires extends beyond performance metrics.
major comments (3)
- Abstract: The abstract states the main finding but supplies no details on statistical controls, exclusion criteria, effect sizes, or how causal discovery was validated, making it impossible to judge whether the reported divergences are supported by the data.
- Results (causal discovery analysis): The analysis does not specify the algorithm used (e.g., PC, GES, NOTEARS) or provide sensitivity checks for unmeasured confounders such as trust, risk aversion, or prior AI exposure, which could open back-door paths and undermine the claim that AI attributes are more impactful in human data compared to simulations.
- Methods: There is no explicit comparison of conditional independence structures between the simulated and human datasets, which is necessary to ensure that differences reflect attribute effects rather than mismatches in decision processes.
minor comments (1)
- Abstract: Consider adding a brief mention of the sample sizes (2,000 simulations and 290 participants) for immediate context on scale.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments, which have helped us identify areas for improvement in clarity and rigor. We address each major comment point by point below and have revised the manuscript accordingly to strengthen the presentation of our methods, results, and abstract.
read point-by-point responses
-
Referee: Abstract: The abstract states the main finding but supplies no details on statistical controls, exclusion criteria, effect sizes, or how causal discovery was validated, making it impossible to judge whether the reported divergences are supported by the data.
Authors: We agree that the abstract would benefit from greater specificity to allow readers to assess the findings more readily. In the revised version, we have expanded the abstract to reference the sample sizes (2,000 simulations and 290 participants), note the use of causal discovery with validation via sensitivity analyses, and indicate key effect size patterns. Full details on exclusion criteria (attention checks and incomplete responses), statistical controls, and causal discovery validation procedures remain in the Methods and Results sections, but we now include a brief reference to them in the abstract to improve accessibility without exceeding length constraints. revision: yes
-
Referee: Results (causal discovery analysis): The analysis does not specify the algorithm used (e.g., PC, GES, NOTEARS) or provide sensitivity checks for unmeasured confounders such as trust, risk aversion, or prior AI exposure, which could open back-door paths and undermine the claim that AI attributes are more impactful in human data compared to simulations.
Authors: We appreciate this observation and have revised the Results section to explicitly name the causal discovery algorithm employed (NOTEARS, chosen for its suitability with mixed continuous and categorical variables in our interaction data). We have also added sensitivity analyses that incorporate available proxy measures for potential unmeasured confounders, including trust (from post-interaction questionnaires), risk aversion (from validated scales), and prior AI exposure (from demographic items). These checks demonstrate that the core finding—greater impact of AI attributes, especially transparency, in human data—remains stable. We acknowledge that not all possible confounders can be fully ruled out and discuss this limitation in the revised text. revision: yes
-
Referee: Methods: There is no explicit comparison of conditional independence structures between the simulated and human datasets, which is necessary to ensure that differences reflect attribute effects rather than mismatches in decision processes.
Authors: We concur that such a comparison strengthens the validity of cross-dataset inferences. The revised Methods and Results sections now include an explicit side-by-side analysis of the conditional independence structures discovered in the simulated versus human datasets. This takes the form of a supplementary table listing shared and divergent independence relations, accompanied by discussion showing that the primary divergences in causal influence (e.g., transparency dominance in human data) align with attribute effects rather than fundamental differences in underlying decision processes. This addition helps substantiate the reported simulation-human gaps. revision: yes
Circularity Check
No circularity: purely empirical comparison of simulated and human datasets
full rationale
The paper performs an empirical study comparing a 2,000-simulation dataset against data from 290 human participants across two scenario types, using causal discovery to assess relative impacts of personality traits (Extraversion, Agreeableness) and AI attributes (Adaptability, Expertise, Transparency). No derivations, equations, or parameter fittings are presented as independent predictions; results follow directly from applying standard causal discovery methods to the collected measures and outcomes. The work contains no self-definitional constructs, fitted-input-as-prediction steps, or load-bearing self-citations that reduce the central claims to tautologies. The analysis is self-contained against external benchmarks of the two datasets.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Causal discovery algorithms can recover meaningful causal structure from the collected simulation and questionnaire data
Reference graph
Works this paper leans on
-
[1]
William Agnew, A. Stevie Bergman, Jennifer Chien, Mark Díaz, Seliem El-Sayed, Jaylen Pittman, Shakir Mohamed, and Kevin R. McKee. 2024. https://doi.org/10.1145/3613904.3642703 The illusion of artificial inclusion . In Proceedings of the CHI Conference on Human Factors in Computing Systems, CHI ’24, page 1–12. ACM
-
[2]
Evgeni Aizenberg, Matthew J Dennis, and Jeroen van den Hoven. 2025. Examining the assumptions of ai hiring assessments and their impact on job seekers’ autonomy over self-representation. AI & society, 40(2):919--927
2025
-
[3]
Marie-Noelle Albert and Salah Koubaa. 2025. https://doi.org/10.3389/fhumd.2025.1554731 The coopetition of human intelligence and artificial intelligence through the prism of irrationality . Frontiers in Human Dynamics, 7. Publisher: Frontiers
-
[4]
Sai Saketh Aluru, Binny Mathew, Punyajoy Saha, and Animesh Mukherjee. 2021. https://doi.org/10.1007/978-3-030-67670-4_26 A Deep Dive into Multilingual Hate Speech Classification . In Machine Learning and Knowledge Discovery in Databases . Applied Data Science and Demo Track , pages 423--439, Cham. Springer International Publishing
-
[5]
Flexible Coding of in-depth Interviews: A Twenty- rst Century Approach
Lisa P. Argyle, Ethan C. Busby, Nancy Fulda, Joshua R. Gubler, Christopher Rytting, and David Wingate. 2023. https://doi.org/10.1017/pan.2023.2 Out of one, many: Using language models to simulate human samples . Political Analysis, 31(3):337–351
-
[6]
Tita A. Bach, Jenny K. Kristiansen, Aleksandar Babic, and Alon Jacovi. 2024. https://doi.org/10.1109/ACCESS.2024.3437190 Unpacking Human - AI Interaction in Safety - Critical Industries : A Systematic Literature Review . IEEE Access, 12:106385--106414. Conference Name: IEEE Access
- [7]
-
[8]
Gagan Bansal, Besmira Nushi, Ece Kamar, Daniel S Weld, Walter S Lasecki, and Eric Horvitz. 2019. Updates in human-AI teams: Understanding and addressing the performance/compatibility tradeoff. Proc. Conf. AAAI Artif. Intell., 33(01):2429--2437
2019
-
[9]
Alejandro Barredo Arrieta, Natalia Díaz-Rodríguez, Javier Del Ser, Adrien Bennetot, Siham Tabik, Alberto Barbado, Salvador Garcia, Sergio Gil-Lopez, Daniel Molina, Richard Benjamins, Raja Chatila, and Francisco Herrera. 2020. https://doi.org/10.1016/j.inffus.2019.12.012 Explainable Artificial Intelligence ( XAI ): Concepts , taxonomies, opportunities and ...
-
[10]
Paul Beaumont, Ben Horsburgh, Philip Pilgerstorfer, Angel Droth, Richard Oentaryo, Steven Ler, Hiep Nguyen, Gabriel Azevedo Ferreira, Zain Patel, and Wesley Leong. 2021. CausalNex
2021
-
[11]
Graham Caron and Shashank Srivastava. 2022. https://doi.org/10.48550/arXiv.2212.10276 Identifying and Manipulating the Personality Traits of Language Models . Preprint, arXiv:2212.10276
-
[12]
Erin K. Chiou and John D. Lee. 2023. https://doi.org/10.1177/00187208211009995 Trusting Automation : Designing for Responsivity and Resilience . Human Factors: The Journal of the Human Factors and Ergonomics Society, 65(1):137--165
-
[13]
Nazli Cila. 2022. Designing human-agent collaborations: Commitment, responsiveness, and support. In Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems, pages 1--18
2022
-
[14]
Myke C. Cohen, Matthew A. Peel, Matthew J. Scalia, Matthew M. Willett, Erin K. Chiou, Jamie C. Gorman, and Nancy J. Cooke. 2023. https://doi.org/10.1177/21695067231196240 Anthropomorphism Moderates the Relationships of Dispositional , Perceptual , and Behavioral Trust in a Robot Teammate . In Proceedings of the Human Factors and Ergonomics Society Annual ...
-
[15]
Cohen, Zhe Su, Hsien-Te Kao, Daniel Nguyen, Spencer Lynch, Maarten Sap, and Svitlana Volkova
Myke C. Cohen, Zhe Su, Hsien-Te Kao, Daniel Nguyen, Spencer Lynch, Maarten Sap, and Svitlana Volkova. 2025. https://doi.org/10.48550/arXiv.2506.15928 Exploring Big Five Personality and AI Capability Effects in LLM - Simulated Negotiation Dialogues . arXiv preprint. ArXiv:2506.15928 [cs]
-
[16]
Nancy J. Cooke, Myke C. Cohen, Walter C. Fazio, Laura H. Inderberg, Craig J. Johnson, Glenn J. Lematta, Matthew Peel, and Aaron Teo. 2024. https://doi.org/10.1177/00187208231162449 From Teams to Teamness : Future Directions in the Science of Team Cognition . Human Factors: The Journal of the Human Factors and Ergonomics Society, 66(6):1669--1680
-
[17]
Can Cui, Yunsheng Ma, Xu Cao, Wenqian Ye, and Ziran Wang. 2023. https://doi.org/10.1145/3583740.3626806 Human- Autonomy Teaming on Autonomous Vehicles with Large Language Model-Enabled Human Digital Twins . In 2023 IEEE / ACM Symposium on Edge Computing ( SEC ) , pages 319--324
-
[18]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. https://doi.org/10.48550/arXiv.1810.04805 BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding . Preprint, arXiv:1810.04805
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1810.04805 2019
-
[19]
Danica Dillion, Niket Tandon, Yuling Gu, and Kurt Gray. 2023. https://api.semanticscholar.org/CorpusID:258569852 Can ai language models replace human participants? Trends in Cognitive Sciences, 27:597--600
2023
-
[20]
Yifan Duan, Yihong Tang, Xuefeng Bai, Kehai Chen, Juntao Li, and Min Zhang. 2025. https://doi.org/10.48550/arXiv.2502.20859 The Power of Personality : A Human Simulation Perspective to Investigate Large Language Model Agents . Preprint, arXiv:2502.20859
-
[21]
Mica R Endsley. 2023. Supporting human-ai teams: Transparency, explainability, and situation awareness. Computers in Human Behavior, 140:107574
2023
- [22]
- [23]
-
[24]
Ivar Frisch and Mario Giulianelli. 2024. https://doi.org/10.48550/arXiv.2402.02896 LLM Agents in Interaction : Measuring Personality Consistency and Linguistic Alignment in Interacting Populations of Large Language Models . Preprint, arXiv:2402.02896
-
[25]
Justin Garten, Reihane Boghrati, Joe Hoover, Kate M Johnson, and Morteza Dehghani. 2016. Morality between the lines: Detecting moral sentiment in text. In Proceedings of IJCAI 2016 Workshop on Computational Modeling of Attitudes
2016
-
[26]
P. A. Hancock, Theresa T. Kessler, Alexandra D. Kaplan, Kimberly Stowers, J. Christopher Brill, Deborah R. Billings, Kristin E. Schaefer, and James L. Szalma. 2023. https://doi.org/10.3389/fpsyg.2023.1081086 How and why humans trust: A meta-analysis and elaborated model . Frontiers in Psychology, 14
-
[27]
Peter A. Hancock, Deborah R. Billings, Kristin E. Schaefer, Jessie Y. C. Chen, Ewart J. de Visser , and Raja Parasuraman. 2011. https://doi.org/10.1177/0018720811417254 A Meta-Analysis of Factors Affecting Trust in Human-Robot Interaction . Human Factors: The Journal of the Human Factors and Ergonomics Society, 53(5):517--527
-
[28]
Laura Hanu and Unitary team . 2020. https://doi.org/10.5281/zenodo.7925667 Detoxify
-
[29]
Thomas F Heston and Justin Gillette. 2025. https://doi.org/10.7759/cureus.84706 Large Language Models Demonstrate Distinct Personality Profiles . Cureus
-
[30]
Sirui Hong, Mingchen Zhuge, Jiaqi Chen, Xiawu Zheng, Yuheng Cheng, Ceyao Zhang, Jinlin Wang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, Chenyu Ran, Lingfeng Xiao, Chenglin Wu, and Jürgen Schmidhuber. 2024. https://arxiv.org/abs/2308.00352 Metagpt: Meta programming for a multi-agent collaborative framework . Preprint, arXiv:2308.00352
work page internal anchor Pith review arXiv 2024
-
[31]
Yin Jou Huang and Rafik Hadfi. 2024. https://doi.org/10.18653/v1/2024.findings-emnlp.605 How Personality Traits Influence Negotiation Outcomes ? A Simulation based on Large Language Models . In Findings of the Association for Computational Linguistics : EMNLP 2024 , pages 10336--10351, Miami, Florida, USA. Association for Computational Linguistics
-
[32]
Xu, Tianyue Ou, Shuyan Zhou, Jeffrey P
Faria Huq, Zora Zhiruo Wang, Frank F. Xu, Tianyue Ou, Shuyan Zhou, Jeffrey P. Bigham, and Graham Neubig. 2025. https://doi.org/10.18653/v1/2025.naacl-demo.17 Cowpilot: A framework for autonomous and human-agent collaborative web navigation . In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational L...
-
[33]
Sai Mounika Inavolu. 2024. Exploring ai-driven customer service: Evolution, architectures, opportunities, challenges and future directions. International Journal of Engineering and Advanced Technology, 13(3):156--163
2024
-
[34]
Oliver P John, Eileen M Donahue, and Robert L Kentle. 1991. Big five inventory. Journal of personality and social psychology
1991
-
[35]
Michael Knop, Sebastian Weber, Marius Mueller, and Bjoern Niehaves. 2022. https://doi.org/10.2196/28639 Human Factors and Technological Characteristics Influencing the Interaction of Medical Professionals With Artificial Intelligence – Enabled Clinical Decision Support Systems : Literature Review . JMIR Human Factors, 9(1):e28639
-
[36]
Trust in automation: Designing for appro- priate reliance
John D. Lee and Katrina A. See. 2004. https://doi.org/10.1518/hfes.46.1.50_30392 Trust in Automation : Designing for Appropriate Reliance . Human Factors, 46(1):50--80
-
[37]
Young-Jun Lee, Chae-Gyun Lim, and Ho-Jin Choi. 2022. Does GPT-3 Generate Empathetic Dialogues ? A Novel In-Context Example Selection Method and Automatic Evaluation Metric for Empathetic Dialogue Generation . In Proceedings of the 29th International Conference on Computational Linguistics , pages 669--683, Gyeongju, Republic of Korea. International Commit...
2022
-
[38]
Rui Li, Heming Xia, Xinfeng Yuan, Qingxiu Dong, Lei Sha, Wenjie Li, and Zhifang Sui. 2025. https://doi.org/10.18653/v1/2025.findings-acl.813 How far are LLM s from being our digital twins? a benchmark for persona-based behavior chain simulation . In Findings of the Association for Computational Linguistics: ACL 2025, pages 15738--15763, Vienna, Austria. A...
-
[39]
Claire Liang, Julia Proft, Erik Andersen, and Ross A. Knepper. 2019. https://doi.org/10.1145/3290605.3300325 Implicit communication of actionable information in human-ai teams . In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, CHI '19, page 1–13, New York, NY, USA. Association for Computing Machinery
-
[40]
Yuxuan Lu, Jing Huang, Yan Han, Bingsheng Yao, Sisong Bei, Jiri Gesi, Yaochen Xie, Zheshen, Wang, Qi He, and Dakuo Wang. 2025. https://arxiv.org/abs/2503.20749 Prompting is not all you need! evaluating llm agent simulation methodologies with real-world online customer behavior data . Preprint, arXiv:2503.20749
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
MacCallum, Shaobo Zhang, Kristopher J
Robert C. MacCallum, Shaobo Zhang, Kristopher J. Preacher, and Derek D. Rucker. 2002. https://doi.org/10.1037/1082-989x.7.1.19 On the practice of dichotomization of quantitative variables . Psychological Methods, 7(1):19--40
-
[42]
Robert R McCrae and Oliver P John. 1992. An introduction to the five-factor model and its applications. Journal of personality, 60(2):175--215
1992
-
[43]
Daniel Nguyen, Myke C. Cohen, Hsien-Te Kao, Grant Engberson, Louis Penafiel, Spencer Lynch, Robert McCormack, Laura Cassani, and Svitlana Volkova. 2025. https://doi.org/10.1075/is.24052.ngu Exploratory models of human- AI teams: Leveraging human digital twins to investigate trust development . Interaction Studies, 26(2):267--297
-
[44]
Spatola Nicolas. 2025. https://doi.org/10.1016/j.chbah.2025.100169 To Be competitive or not to be competitive: How performance goals shape human- AI and human-human collaboration . Computers in Human Behavior: Artificial Humans, 5:100169
- [45]
- [46]
-
[47]
Joon Sung Park, Lindsay Popowski, Carrie Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein. 2022. Social simulacra: Creating populated prototypes for social computing systems. In Proceedings of the 35th Annual ACM Symposium on User Interface Software and Technology, pages 1--18
2022
-
[48]
LLM Agents Grounded in Self-Reports Enable General-Purpose Simulation of Individuals
Joon Sung Park, Carolyn Q. Zou, Aaron Shaw, Benjamin Mako Hill, Carrie Cai, Meredith Ringel Morris, Robb Willer, Percy Liang, and Michael S. Bernstein. 2024. https://arxiv.org/abs/2411.10109 Generative agent simulations of 1,000 people . Preprint, arXiv:2411.10109
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[49]
Judea Pearl and Dana Mackenzie. 2018. The Book of Why : The New Science of Cause and Effect , 1st edition edition. Basic Books, New York
2018
-
[50]
Petrov, Gregory Serapio-Garc \'i a , and Jason Rentfrow
Nikolay B. Petrov, Gregory Serapio-Garc \'i a , and Jason Rentfrow. 2024. https://doi.org/10.48550/arXiv.2405.07248 Limited Ability of LLMs to Simulate Human Psychological Behaviours : A Psychometric Analysis . Preprint, arXiv:2405.07248
-
[51]
Muhammad Raees, Inge Meijerink, Ioanna Lykourentzou, Vassilis-Javed Khan, and Konstantinos Papangelis. 2024. https://doi.org/10.1016/j.ijhcs.2024.103301 From explainable to interactive AI : A literature review on current trends in human- AI interaction . International Journal of Human-Computer Studies, 189:103301
-
[52]
Hannah Rashkin, Eunsol Choi, Jin Yea Jang, Svitlana Volkova, and Yejin Choi. 2017. https://doi.org/10.18653/v1/D17-1317 Truth of Varying Shades : Analyzing Language in Fake News and Political Fact-Checking . In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing , pages 2931--2937, Copenhagen, Denmark. Association for Co...
-
[53]
Hannah Rashkin, Sameer Singh, and Yejin Choi. 2016. https://doi.org/10.48550/arXiv.1506.02739 Connotation Frames : A Data-Driven Investigation . Preprint, arXiv:1506.02739
-
[54]
Bhadresh Savani. 2024. DistilBERT for emotion recognition
2024
-
[55]
Shadish, Thomas D
William R. Shadish, Thomas D. Cook, and Donald T. Campbell. 2001. Experimental and Quasi-Experimental Designs for Generalized Causal Inference. Houghton Mifflin, Boston
2001
- [56]
-
[57]
Ashish Sharma, Sudha Rao, Chris Brockett, Akanksha Malhotra, Nebojsa Jojic, and Bill Dolan. 2024. https://doi.org/10.18653/v1/2024.eacl-long.119 Investigating agency of LLM s in human- AI collaboration tasks . In Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1968-...
-
[58]
Ben Shneiderman. 2020. https://doi.org/10.1080/10447318.2020.1741118 Human- Centered Artificial Intelligence : Reliable , Safe & Trustworthy . International Journal of Human–Computer Interaction, 36(6):495--504. Publisher: Taylor & Francis \_eprint: https://doi.org/10.1080/10447318.2020.1741118
-
[59]
Zhe Su, Xuhui Zhou, Sanketh Rangreji, Anubha Kabra, Julia Mendelsohn, Faeze Brahman, and Maarten Sap. 2025. https://doi.org/10.18653/v1/2025.naacl-long.595 AI - L ie D ar : Examine the trade-off between utility and truthfulness in LLM agents . In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational...
-
[60]
Qiyang Sun, Yupei Li, Emran Alturki, Sunil Munthumoduku Krishna Murthy, and Björn W. Schuller. 2024. https://doi.org/10.48550/arXiv.2412.15114 Towards Friendly AI : A Comprehensive Review and New Perspectives on Human - AI Alignment . arXiv preprint. ArXiv:2412.15114 [cs]
-
[61]
S Volkova, M Glenski, E Ayton, E Saldanha, J Mendoza, D Arendt, Z Shaw, K Cronk, S Smith, and M Greaves. 2021. https://arxiv.org/abs/27036529 Machine Intelligence to Detect , Characterise , and Defend against Influence Operations in the Information Environment . Journal of Information Warfare, 20(2):42--66
-
[62]
Svitlana Volkova, Dustin Arendt, Emily Saldanha, Maria Glenski, Ellyn Ayton, Joseph Cottam, Sinan Aksoy, Brett Jefferson, and Karthnik Shrivaram. 2023. https://doi.org/10.1007/s10588-021-09351-y Explaining and predicting human behavior and social dynamics in simulated virtual worlds: Reproducibility, generalizability, and robustness of causal discovery me...
-
[63]
Svitlana Volkova, Daniel Nguyen, Louis Penafiel, Hsien-Te Kao, Myke Cohen, Grant Engberson, Laura Cassani, Mohammed Almutairi, Charles Chiang, Nandini Banerjee, Matthew Belcher, Trenton W. Ford, Michael G. Yankoski, Tim Weninger, Diego Gomez-Zara, and Summer Rebensky. 2025. https://doi.org/10.1007/978-3-031-92970-0_20 VirTLab : Augmented Intelligence for ...
-
[64]
Chengxing Xie, Canyu Chen, Feiran Jia, Ziyu Ye, Shiyang Lai, Kai Shu, Jindong Gu, Adel Bibi, Ziniu Hu, David Jurgens, James Evans, Philip Torr, Bernard Ghanem, and Guohao Li. 2024. https://arxiv.org/abs/2402.04559 Can large language model agents simulate human trust behavior? Preprint, arXiv:2402.04559
-
[65]
Asaf Yehudai, Lilach Eden, Alan Li, Guy Uziel, Yilun Zhao, Roy Bar-Haim, Arman Cohan, and Michal Shmueli-Scheuer. 2025. https://arxiv.org/abs/2503.16416 Survey on evaluation of llm-based agents . Preprint, arXiv:2503.16416
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[66]
Building cooperative embodied agents modularly with large language models
Hongxin Zhang, Weihua Du, Jiaming Shan, Qinhong Zhou, Yilun Du, Joshua B. Tenenbaum, Tianmin Shu, and Chuang Gan. 2024 a . https://arxiv.org/abs/2307.02485 Building cooperative embodied agents modularly with large language models . Preprint, arXiv:2307.02485
-
[67]
Jifan Zhang, Henry Sleight, Andi Peng, John Schulman, and Esin Durmus. 2025. https://doi.org/10.48550/arXiv.2510.07686 Stress- Testing Model Specs Reveals Character Differences among Language Models . Preprint, arXiv:2510.07686
- [68]
-
[69]
Xuhui Zhou, Zhe Su, Sophie Feng, Jiaxu Zhou, Jen-tse Huang, Hsien-Te Kao, Spencer Lynch, Svitlana Volkova, Tongshuang Wu, Anita Woolley, Hao Zhu, and Maarten Sap. 2025. https://doi.org/10.18653/v1/2025.naacl-demo.30 SOTOPIA -s4: a user-friendly system for flexible, customizable, and large-scale social simulation . In Proceedings of the 2025 Conference of ...
-
[70]
Xuhui Zhou, Hao Zhu, Leena Mathur, Ruohong Zhang, Haofei Yu, Zhengyang Qi, Louis-Philippe Morency, Yonatan Bisk, Daniel Fried, Graham Neubig, and Maarten Sap. 2024. https://doi.org/10.48550/arXiv.2310.11667 SOTOPIA : Interactive Evaluation for Social Intelligence in Language Agents . Preprint, arXiv:2310.11667
-
[71]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[72]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.