Recognition: unknown
Latent-Compressed Variational Autoencoder for Video Diffusion Models
Pith reviewed 2026-05-10 15:18 UTC · model grok-4.3
The pith
Removing high-frequency components from video latent representations improves reconstruction quality in variational autoencoders at fixed compression ratios.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
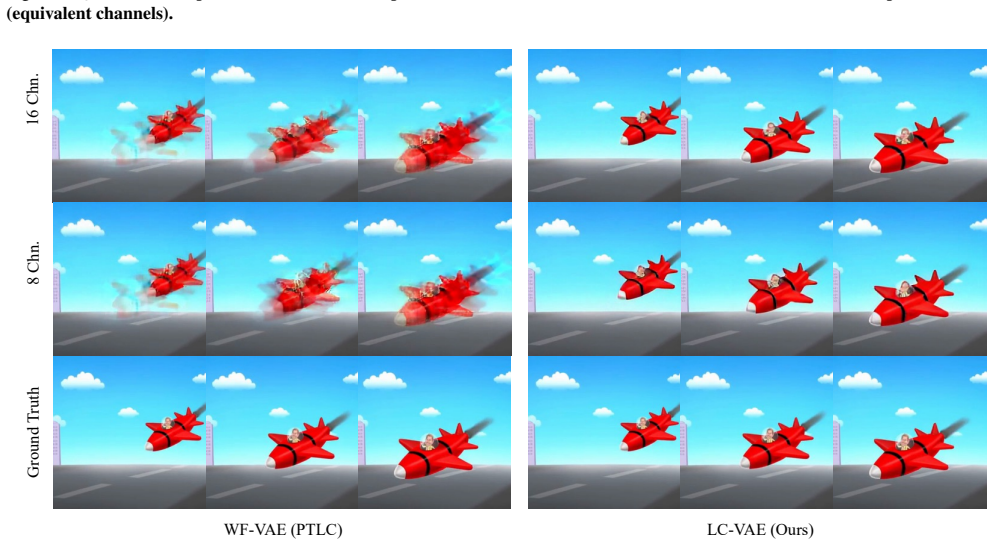
The authors establish that a latent compression method which removes high-frequency components in video latent representations, rather than directly reducing the number of channels, achieves superior video reconstruction quality compared to strong baselines while maintaining the same overall compression ratio. This directly tackles the observed conflict where high channel counts support good VAE reconstruction yet impair downstream diffusion performance.
What carries the argument
High-frequency removal applied directly to video latent representations, which discards selected frequency components to compress the latent tensor without lowering its channel dimension.
If this is right
- Latent diffusion models receive higher-quality inputs and therefore train to stronger generative performance.
- Video reconstruction remains more accurate at any given compression ratio.
- The same memory and compute budget for the diffusion stage can be retained without sacrificing encoding fidelity.
- Downstream tasks that depend on the latent space inherit the improved reconstruction without additional channel overhead.
Where Pith is reading between the lines
- The frequency-selective approach may transfer to image or audio latent models facing similar channel-count versus fidelity trade-offs.
- Combining high-frequency removal with existing quantization or pruning steps could produce further compression gains.
- Empirical tests across motion-heavy versus static video datasets would clarify whether the benefit depends on content statistics.
- The result suggests that latent-space dimensionality is less critical for perceptual quality than the distribution of energy across frequencies.
Load-bearing premise
High-frequency components in the latent space can be removed without losing the information required for high-fidelity video reconstruction or introducing artifacts that degrade the diffusion model's performance.
What would settle it
A controlled reconstruction experiment on held-out video sequences in which the proposed compressed latents yield lower PSNR or higher perceptual distortion than a baseline VAE that simply uses fewer channels at the identical compression ratio.
Figures














read the original abstract
Video variational autoencoders (VAEs) used in latent diffusion models typically require a sufficiently large number of latent channels to ensure high-quality video reconstruction. However, recent studies have revealed that an excessive number of latent channels can impede the convergence of latent diffusion models and deteriorate their generative performance, even when reconstruction quality remains high. We propose a latent compression method that removes high-frequency components in video latent representations rather than directly reducing the number of channels, which often compromises reconstruction fidelity. Experimental results demonstrate that the proposed method achieves superior video reconstruction quality compared to strong baselines while maintaining the same overall compression ratio.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a latent compression technique for video variational autoencoders (VAEs) used in latent diffusion models. Instead of directly reducing the number of latent channels (which can degrade reconstruction fidelity), the method removes high-frequency components from the latent representations while preserving the overall compression ratio. The central empirical claim is that this yields superior video reconstruction quality relative to strong baselines.
Significance. If the reported experimental gains hold under rigorous controls, the work would offer a practical alternative for balancing latent-space compression against reconstruction fidelity in video diffusion pipelines. This addresses a documented tension between VAE capacity and downstream generative training stability, and could inform latent design choices in future video generation systems.
minor comments (2)
- [Abstract] Abstract: the claim of 'superior video reconstruction quality' is stated without any numerical metrics, error bars, dataset names, or baseline identifiers. Adding a single sentence with key quantitative results (e.g., PSNR/SSIM deltas and the exact compression ratio) would strengthen the abstract.
- The manuscript should explicitly state the precise definition of 'overall compression ratio' (bits per pixel, channel reduction factor, or latent dimensionality) and confirm that it is matched exactly between the proposed method and all baselines.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our manuscript and the recommendation for minor revision. The summary correctly identifies the core contribution: a frequency-based latent compression technique for video VAEs that preserves reconstruction quality better than channel-reduction baselines at equivalent compression ratios. No major comments were provided in the report.
Circularity Check
No significant circularity detected
full rationale
The paper advances an empirical method for latent compression in video VAEs by removing high-frequency components rather than reducing channel count, with the central claim resting on experimental comparisons of reconstruction quality against baselines at fixed compression ratios. No derivation chain, first-principles prediction, or uniqueness theorem is asserted; the approach is presented as a practical alternative motivated by observed trade-offs in prior work, without any step that reduces by construction to fitted inputs, self-citations, or renamed empirical patterns. The argument is self-contained as an experimental proposal.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption High-frequency components in latent space can be removed without significant loss of reconstructible video information.
Reference graph
Works this paper leans on
-
[1]
Cosmos World Foundation Model Platform for Physical AI
Niket Agarwal, Arslan Ali, Maciej Bala, Yogesh Balaji, Erik Barker, Tiffany Cai, Prithvijit Chattopadhyay, Yongxin Chen, Yin Cui, Yifan Ding, et al. Cosmos world foundation model platform for physical ai.arXiv preprint arXiv:2501.03575,
work page internal anchor Pith review arXiv
-
[2]
Frozen in time: A joint video and image encoder for end-to- end retrieval
Max Bain, Arsha Nagrani, G¨ul Varol, and Andrew Zisserman. Frozen in time: A joint video and image encoder for end-to- end retrieval. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 1728–1738, 2021. 5, 6
2021
-
[3]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023. 2, 3, 5, 6
work page internal anchor Pith review arXiv 2023
-
[4]
Video generation models as world simulators
Tim Brooks, Bill Peebles, Connor Holmes, Will DePue, Yufei Guo, Leo Jing, David Schnurr, Joe Taylor, Troy Luhman, Eric Luhman, et al. Video generation models as world simulators. OpenAI Blog, 1(8):1, 2024. 1, 3
2024
-
[5]
Deep compression autoencoder for efficient high-resolution diffusion models
Junyu Chen, Han Cai, Junsong Chen, Enze Xie, Shang Yang, Haotian Tang, Muyang Li, Yao Lu, and Song Han. Deep com- pression autoencoder for efficient high-resolution diffusion models.arXiv preprint arXiv:2410.10733, 2024. 2
-
[6]
Dc-videogen: Efficient video gen- eration with deep compression video autoencoder,
Junyu Chen, Wenkun He, Yuchao Gu, Yuyang Zhao, Jincheng Yu, Junsong Chen, Dongyun Zou, Yujun Lin, Zhekai Zhang, Muyang Li, et al. Dc-videogen: Efficient video generation with deep compression video autoencoder.arXiv preprint arXiv:2509.25182, 2025. 2
-
[7]
Dc-ae 1.5: Accelerating dif- fusion model convergence with structured latent space
Junyu Chen, Dongyun Zou, Wenkun He, Junsong Chen, Enze Xie, Song Han, and Han Cai. Dc-ae 1.5: Accelerating dif- fusion model convergence with structured latent space. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 19628–19637, 2025. 2, 4, 7
2025
-
[8]
Od- vae: An omni-dimensional video compressor for improving latent video diffusion model
Liuhan Chen, Zongjian Li, Bin Lin, Bin Zhu, Qian Wang, Shenghai Yuan, Xing Zhou, Xinhua Cheng, and Li Yuan. Od- vae: An omni-dimensional video compressor for improving latent video diffusion model. In2025 IEEE International Conference on Multimedia and Expo (ICME), pages 1–6. IEEE, 2025. 5, 6
2025
-
[9]
Panda-70m: Captioning 70m videos with multiple cross- modality teachers
Tsai-Shien Chen, Aliaksandr Siarohin, Willi Menapace, Eka- terina Deyneka, Hsiang-wei Chao, Byung Eun Jeon, Yuwei Fang, Hsin-Ying Lee, Jian Ren, Ming-Hsuan Yang, et al. Panda-70m: Captioning 70m videos with multiple cross- modality teachers. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 13320–13331, 2024. 5, 6
2024
-
[10]
Taming transformers for high-resolution image synthesis
Patrick Esser, Robin Rombach, and Bjorn Ommer. Taming transformers for high-resolution image synthesis. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12873–12883, 2021. 5
2021
-
[11]
Video generation arena leader- board
Hugging Face. Video generation arena leader- board. https : / / huggingface . co / spaces / ArtificialAnalysis / Video - Generation - Arena-Leaderboard, 2025. Accessed: 2025-11-11. 3
2025
-
[12]
Seedance 1.0: Exploring the Boundaries of Video Generation Models
Yu Gao, Haoyuan Guo, Tuyen Hoang, Weilin Huang, Lu Jiang, Fangyuan Kong, Huixia Li, Jiashi Li, Liang Li, Xiaojie Li, et al. Seedance 1.0: Exploring the boundaries of video generation models.arXiv preprint arXiv:2506.09113, 2025. 3
work page internal anchor Pith review arXiv 2025
-
[13]
Generative adversarial nets.Advances in Neural Information Processing Systems, 27, 2014
Ian J Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets.Advances in Neural Information Processing Systems, 27, 2014. 5
2014
-
[14]
An introduction to wavelets.IEEE computa- tional science and engineering, 2(2):50–61, 1995
Amara Graps. An introduction to wavelets.IEEE computa- tional science and engineering, 2(2):50–61, 1995. 2
1995
-
[15]
AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning
Yuwei Guo, Ceyuan Yang, Anyi Rao, Zhengyang Liang, Yao- hui Wang, Yu Qiao, Maneesh Agrawala, Dahua Lin, and Bo Dai. Animatediff: Animate your personalized text-to-image diffusion models without specific tuning.arXiv preprint arXiv:2307.04725, 2023. 2
work page internal anchor Pith review arXiv 2023
-
[16]
LTX-Video: Realtime Video Latent Diffusion
Yoav HaCohen, Nisan Chiprut, Benny Brazowski, Daniel Shalem, Dudu Moshe, Eitan Richardson, Eran Levin, Guy Shiran, Nir Zabari, Ori Gordon, et al. Ltx-video: Realtime video latent diffusion.arXiv preprint arXiv:2501.00103, 2024. 2, 3
work page internal anchor Pith review arXiv 2024
-
[17]
Philippe Hansen-Estruch, David Yan, Ching-Yao Chung, Orr Zohar, Jialiang Wang, Tingbo Hou, Tao Xu, Sriram Vish- wanath, Peter Vajda, and Xinlei Chen. Learnings from scaling visual tokenizers for reconstruction and generation.arXiv preprint arXiv:2501.09755, 2025. 2
-
[18]
Latent Video Diffusion Models for High-Fidelity Long Video Generation
Yingqing He, Tianyu Yang, Yong Zhang, Ying Shan, and Qifeng Chen. Latent video diffusion models for high-fidelity long video generation.arXiv preprint arXiv:2211.13221,
work page internal anchor Pith review arXiv
-
[19]
simple diffusion: End-to-end diffusion for high resolution images
Emiel Hoogeboom, Jonathan Heek, and Tim Salimans. simple diffusion: End-to-end diffusion for high resolution images. InProceedings of the International Conference on Machine Learning, pages 13213–13232. PMLR, 2023. 1
2023
-
[20]
Image quality metrics: Psnr vs
Alain Hore and Djemel Ziou. Image quality metrics: Psnr vs. ssim. InProceedings of the International Conference on Pattern Recognition, pages 2366–2369. IEEE, 2010. 5
2010
-
[21]
The Kinetics Human Action Video Dataset
Will Kay, Joao Carreira, Karen Simonyan, Brian Zhang, Chloe Hillier, Sudheendra Vijayanarasimhan, Fabio Viola, Tim Green, Trevor Back, Paul Natsev, et al. The kinetics hu- man action video dataset.arXiv preprint arXiv:1705.06950,
work page internal anchor Pith review arXiv
-
[22]
Adam: A Method for Stochastic Optimization
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Auto-Encoding Variational Bayes
Diederik P Kingma and Max Welling. Auto-encoding varia- tional Bayes.arXiv preprint arXiv:1312.6114, 2013. 1
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[24]
Videopoet: A large language model for zero-shot video generation,
Dan Kondratyuk, Lijun Yu, Xiuye Gu, Jos´e Lezama, Jonathan Huang, Grant Schindler, Rachel Hornung, Vighnesh Birodkar, Jimmy Yan, Ming-Chang Chiu, et al. Videopoet: A large language model for zero-shot video generation.arXiv preprint arXiv:2312.14125, 2023. 3
-
[25]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603, 2024. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Video autoencoder: self-supervised disentanglement of static 3d structure and motion
Zihang Lai, Sifei Liu, Alexei A Efros, and Xiaolong Wang. Video autoencoder: self-supervised disentanglement of static 3d structure and motion. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 9730– 9740, 2021. 2
2021
-
[27]
Wf-vae: Enhancing video vae by wavelet-driven energy flow for latent video diffusion model
Zongjian Li, Bin Lin, Yang Ye, Liuhan Chen, Xinhua Cheng, Shenghai Yuan, and Li Yuan. Wf-vae: Enhancing video vae by wavelet-driven energy flow for latent video diffusion model. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, pages 17778–17788,
-
[28]
Open-sora plan: Open-source large video generation model.arXiv preprint arXiv:2412.00131,
Bin Lin, Yunyang Ge, Xinhua Cheng, Zongjian Li, Bin Zhu, Shaodong Wang, Xianyi He, Yang Ye, Shenghai Yuan, Li- uhan Chen, et al. Open-sora plan: Open-source large video generation model.arXiv preprint arXiv:2412.00131, 2024. 3, 5
-
[29]
Hi-vae: Ef- ficient video autoencoding with global and detailed motion
Huaize Liu, Wenzhang Sun, Qiyuan Zhang, Donglin Di, Biao Gong, Hao Li, Chen Wei, and Changqing Zou. Hi-vae: Ef- ficient video autoencoding with global and detailed motion. arXiv preprint arXiv:2506.07136, 2025. 2
-
[30]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017. 5
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[31]
Latte: Latent diffusion transformer for video generation.Transactions on Machine Learning Research, 2025
Xin Ma, Yaohui Wang, Xinyuan Chen, Gengyun Jia, Ziwei Liu, Yuan-Fang Li, Cunjian Chen, and Yu Qiao. Latte: Latent diffusion transformer for video generation.Transactions on Machine Learning Research, 2025. 3, 5, 7, 8
2025
-
[32]
OpenVid-1M: A Large-Scale High-Quality Dataset for Text-to-video Generation
Kepan Nan, Rui Xie, Penghao Zhou, Tiehan Fan, Zhen- heng Yang, Zhijie Chen, Xiang Li, Jian Yang, and Ying Tai. Openvid-1m: A large-scale high-quality dataset for text-to- video generation.arXiv preprint arXiv:2407.02371, 2024. 7
work page internal anchor Pith review arXiv 2024
-
[33]
Movie Gen: A Cast of Media Foundation Models
Adam Polyak, Amit Zohar, Andrew Brown, Andros Tjandra, Animesh Sinha, Ann Lee, Apoorv Vyas, Bowen Shi, Chih- Yao Ma, Ching-Yao Chuang, et al. Movie gen: A cast of media foundation models.arXiv preprint arXiv:2410.13720,
work page internal anchor Pith review arXiv
-
[34]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10684–10695, 2022. 1, 2, 5, 6
2022
-
[35]
Temporal generative adversarial nets with singular value clipping
Masaki Saito, Eiichi Matsumoto, and Shunta Saito. Temporal generative adversarial nets with singular value clipping. In Proceedings of the IEEE International Conference on Com- puter Vision, pages 2830–2839, 2017. 5
2017
-
[36]
The JPEG 2000 still image compression standard
Athanassios Skodras, Charilaos Christopoulos, and Touradj Ebrahimi. The JPEG 2000 still image compression standard. IEEE Signal Processing Magazine, 18(5):36–58, 2002. 3
2000
-
[37]
Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2
Ivan Skorokhodov, Sergey Tulyakov, and Mohamed Elho- seiny. Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3626–3636, 2022. 5
2022
-
[38]
Improving the diffusability of autoencoders.arXiv preprint arXiv:2502.14831, 2025
Ivan Skorokhodov, Sharath Girish, Benran Hu, Willi Mena- pace, Yanyu Li, Rameen Abdal, Sergey Tulyakov, and Aliak- sandr Siarohin. Improving the diffusability of autoencoders. arXiv preprint arXiv:2502.14831, 2025. 2, 3, 4, 7
-
[39]
UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild
Khurram Soomro, Amir Roshan Zamir, and Mubarak Shah. Ucf101: A dataset of 101 human actions classes from videos in the wild.arXiv preprint arXiv:1212.0402, 2012. 5, 7
work page internal anchor Pith review arXiv 2012
-
[40]
Yanru Sun, Emadeldeen Eldele, Zongxia Xie, Yucheng Wang, Wenzhe Niu, Qinghua Hu, Chee Keong Kwoh, and Min Wu. Adapting LLMs to time series forecasting via temporal het- erogeneity modeling and semantic alignment.arXiv preprint arXiv:2508.07195, 2025. 3, 4, 2
-
[41]
Kamrul Hasan Talukder and Koichi Harada. Haar wavelet based approach for image compression and quality assess- ment of compressed image.arXiv preprint arXiv:1010.4084,
-
[42]
FVD: A new metric for video generation
Thomas Unterthiner, Sjoerd van Steenkiste, Karol Kurach, Rapha¨el Marinier, Marcin Michalski, and Sylvain Gelly. FVD: A new metric for video generation. InICLR Workshop on Deep Generative Models for Highly Structured Data, 2019. 5
2019
-
[43]
Attention is all you need.Advances in Neural Information Processing Systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in Neural Information Processing Systems, 30, 2017. 2
2017
-
[44]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Image quality assessment: from error visibility to structural similarity.IEEE Transactions on Image Processing, 13(4):600–612, 2004
Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Simoncelli. Image quality assessment: from error visibility to structural similarity.IEEE Transactions on Image Processing, 13(4):600–612, 2004. 5
2004
-
[46]
Improved video V AE for latent video diffusion model
Pingyu Wu, Kai Zhu, Yu Liu, Liming Zhao, Wei Zhai, Yang Cao, and Zheng-Jun Zha. Improved video V AE for latent video diffusion model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18124–18133, 2025. 2
2025
-
[47]
H3ae: High compression, high speed, and high quality autoencoder for video diffusion models
Yushu Wu, Yanyu Li, Ivan Skorokhodov, Anil Kag, Willi Menapace, Sharath Girish, Aliaksandr Siarohin, Yanzhi Wang, and Sergey Tulyakov. H3ae: High compression, high speed, and high quality autoencoder for video diffusion models. arXiv preprint arXiv:2504.10567, 2025. 2
-
[48]
Learning to generate time-lapse videos using multi-stage dy- namic generative adversarial networks
Wei Xiong, Wenhan Luo, Lin Ma, Wei Liu, and Jiebo Luo. Learning to generate time-lapse videos using multi-stage dy- namic generative adversarial networks. InProceedings of the IEEE Conference on Computer Vision and Pattern Recogni- tion, pages 2364–2373, 2018. 5, 7
2018
-
[49]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiao- han Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer.arXiv preprint arXiv:2408.06072, 2024. 1, 2
work page internal anchor Pith review arXiv 2024
-
[50]
Language Model Beats Diffusion -- Tokenizer is Key to Visual Generation
Lijun Yu, Jos´e Lezama, Nitesh B Gundavarapu, Luca Ver- sari, Kihyuk Sohn, David Minnen, Yong Cheng, Vighnesh Birodkar, Agrim Gupta, Xiuye Gu, et al. Language model beats diffusion–tokenizer is key to visual generation.arXiv preprint arXiv:2310.05737, 2023. 2, 3
work page internal anchor Pith review arXiv 2023
-
[51]
Sihyun Yu, Weili Nie, De-An Huang, Boyi Li, Jinwoo Shin, and Anima Anandkumar. Efficient video diffusion models via content-frame motion-latent decomposition.arXiv preprint arXiv:2403.14148, 2024. 2
-
[52]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 586–595, 2018. 5
2018
-
[53]
A survey on perceptually optimized video coding
Yun Zhang, Linwei Zhu, Gangyi Jiang, Sam Kwong, and C- C Jay Kuo. A survey on perceptually optimized video coding. ACM Computing Surveys, 55(12):1–37, 2023. 3
2023
-
[54]
Cv- vae: A compatible video vae for latent generative video mod- els.Advances in Neural Information Processing Systems, 37: 12847–12871, 2024
Sijie Zhao, Yong Zhang, Xiaodong Cun, Shaoshu Yang, Muyao Niu, Xiaoyu Li, Wenbo Hu, and Ying Shan. Cv- vae: A compatible video vae for latent generative video mod- els.Advances in Neural Information Processing Systems, 37: 12847–12871, 2024. 5, 6
2024
-
[55]
Open-Sora: Democratizing Efficient Video Production for All
Zangwei Zheng, Xiangyu Peng, Tianji Yang, Chenhui Shen, Shenggui Li, Hongxin Liu, Yukun Zhou, Tianyi Li, and Yang You. Open-sora: Democratizing efficient video production for all.arXiv preprint arXiv:2412.20404, 2024. 1, 2, 5, 6
work page internal anchor Pith review arXiv 2024
-
[56]
Yuan Zhou, Qiuyue Wang, Yuxuan Cai, and Huan Yang. Alle- gro: Open the black box of commercial-level video generation model.arXiv preprint arXiv:2410.15458, 2024. 2, 3 Latent-Compressed Variational Autoencoder for Video Diffusion Models Supplementary Material Contents A . Training Details 1 B . Multi-Level Wavelet Transform of Latent 1 C . Latent Frequenc...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.