Recognition: unknown
ViPS: Video-informed Pose Spaces for Auto-Rigged Meshes
Pith reviewed 2026-05-10 05:35 UTC · model grok-4.3
The pith
Video diffusion priors can be distilled into a universal, controllable pose space for arbitrary auto-rigged meshes that matches models trained on synthetic 4D data and generalizes zero-shot to new species and skeletal topologies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ViPS is a feed-forward framework that discovers the latent distribution of valid articulations for auto-rigged meshes by distilling motion priors from a pretrained video diffusion model. Differentiable geometric validators applied to the skinned mesh enforce asset-specific validity without manual regularizers. The model learns a smooth, compact, and controllable pose space that supports diverse sampling, manifold projection for inverse kinematics, and temporally coherent trajectories for keyframing. The distilled 3D pose samples also serve as semantic proxies for guiding video diffusion, closing the loop between generative 2D priors and structured 3D kinematic control. Evaluations show that,
What carries the argument
Distillation of motion priors from a pretrained 2D video diffusion model into a distribution over rig parameters, guided by differentiable geometric validators on the skinned mesh.
Load-bearing premise
Motion knowledge encoded in a 2D video diffusion model can be transferred reliably into a distribution over arbitrary 3D rig parameters, and geometric validators on the skinned mesh are enough to guarantee validity without asset-specific manual rules.
What would settle it
A controlled test in which ViPS produces anatomically invalid poses or self-intersections on a held-out mesh species while a model trained on artist 4D data does not, or where zero-shot performance on an unseen skeletal topology drops below that of a retrained baseline.
Figures





read the original abstract
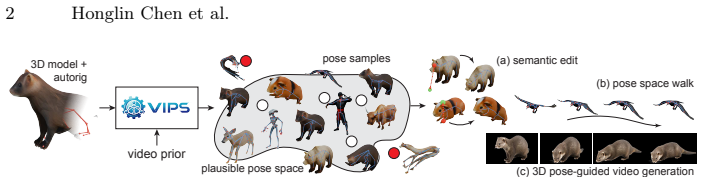
Kinematic rigs provide a structured interface for articulating 3D meshes, but they lack an inherent representation of the plausible manifold of joint configurations for a given asset. Without such a pose space, stochastic sampling or manual manipulation of raw rig parameters often leads to semantic or geometric violations, such as anatomical hyperextension and non-physical self-intersections. We propose Video-informed Pose Spaces (ViPS), a feed-forward framework that discovers the latent distribution of valid articulations for auto-rigged meshes by distilling motion priors from a pretrained video diffusion model. Unlike existing methods that rely on scarce artist-authored 4D datasets, ViPS transfers generative video priors into a universal distribution over a given rig parameterization. Differentiable geometric validators applied to the skinned mesh enforce asset-specific validity without requiring manual regularizers. Our model learns a smooth, compact, and controllable pose space that supports diverse sampling, manifold projection for inverse kinematics, and temporally coherent trajectories for keyframing. Furthermore, the distilled 3D pose samples serve as precise semantic proxies for guiding video diffusion, effectively closing the loop between generative 2D priors and structured 3D kinematic control. Our evaluations show that ViPS, trained solely on video priors, matches the performance of state-of-the-art methods trained on synthetic artist-created 4D data in both plausibility and diversity. Most importantly, as a universal model, ViPS demonstrates robust zero-shot generalization to out-of-distribution species and unseen skeletal topologies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ViPS, a feed-forward framework that distills motion priors from a pretrained 2D video diffusion model to discover the latent distribution of valid joint configurations for auto-rigged 3D meshes. It employs differentiable geometric validators (self-intersection, joint limits) applied after skinning to enforce asset-specific validity without manual regularizers. The resulting pose space supports diverse sampling, manifold projection for inverse kinematics, and temporally coherent trajectories. The central claims are that ViPS matches the plausibility and diversity of SOTA methods trained on synthetic artist-created 4D data, and that it achieves robust zero-shot generalization to out-of-distribution species and unseen skeletal topologies as a universal model.
Significance. If the zero-shot generalization and performance-matching claims hold, the work would be significant for reducing dependence on scarce 4D animation datasets and enabling pose-space modeling for arbitrary auto-rigged assets. The closed-loop use of distilled 3D samples to guide video diffusion and the reliance on differentiable validators rather than hand-crafted regularizers are notable strengths. The approach could broaden access to structured kinematic control in generative graphics pipelines.
major comments (2)
- [Abstract and §3] Abstract and §3 (Method): The zero-shot generalization claim to unseen skeletal topologies is load-bearing for the 'universal model' assertion, yet the architecture description provides no explicit mechanism (e.g., graph neural network encoding of the rig skeleton, per-joint topology conditioning, or bone-length features) for embedding arbitrary rig structures. Without such conditioning, it is unclear how the feed-forward network avoids assigning probability mass to kinematically invalid configurations that generic post-skinning validators may miss, as highlighted by the stress-test concern.
- [§4] §4 (Experiments): The evaluations assert matching SOTA performance and robust zero-shot results but report no quantitative metrics, ablation studies on validator components, or concrete details on the unseen topologies tested (e.g., specific species, number of bones differing from training rigs, or failure cases). This absence makes it impossible to verify whether the video priors plus validators suffice for the claimed generalization, undermining the central empirical support.
minor comments (2)
- [Abstract] Abstract: The phrase 'our evaluations show' lacks forward references to specific figures, tables, or result subsections; adding these would improve readability.
- Notation: The definition of the rig parameter space and how the video diffusion prior is mapped to it could be stated more formally (e.g., with an explicit equation for the distilled distribution) to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment point-by-point below, clarifying our approach and committing to revisions where the manuscript can be strengthened.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Method): The zero-shot generalization claim to unseen skeletal topologies is load-bearing for the 'universal model' assertion, yet the architecture description provides no explicit mechanism (e.g., graph neural network encoding of the rig skeleton, per-joint topology conditioning, or bone-length features) for embedding arbitrary rig structures. Without such conditioning, it is unclear how the feed-forward network avoids assigning probability mass to kinematically invalid configurations that generic post-skinning validators may miss, as highlighted by the stress-test concern.
Authors: We thank the referee for this important observation. The current §3 describes ViPS as a feed-forward network that ingests raw rig parameters and relies on the combination of distilled video priors plus post-skinning differentiable validators (self-intersection and joint-limit checks) to shape the learned distribution. No graph neural network or explicit per-joint topology conditioning is present in the architecture. While the video priors and validators have enabled the observed zero-shot behavior in our tests, we agree that the lack of explicit rig-structure embedding leaves the generalization mechanism under-specified. We will revise §3 to add a detailed description of the input parameterization, an accompanying diagram, and an ablation examining the contribution of relative bone-length normalization to generalization. revision: yes
-
Referee: [§4] §4 (Experiments): The evaluations assert matching SOTA performance and robust zero-shot results but report no quantitative metrics, ablation studies on validator components, or concrete details on the unseen topologies tested (e.g., specific species, number of bones differing from training rigs, or failure cases). This absence makes it impossible to verify whether the video priors plus validators suffice for the claimed generalization, undermining the central empirical support.
Authors: The referee correctly identifies that the current §4 provides only high-level assertions without supporting quantitative tables, ablations, or specifics on the zero-shot test rigs. We will expand the experiments section in the revision to include: (i) quantitative metrics (e.g., plausibility scores, diversity measures, and direct comparisons to 4D-trained baselines), (ii) ablations isolating each validator component, and (iii) concrete details on the unseen topologies (species, bone-count differences from training rigs, and observed failure modes). These additions will directly address the verifiability concern. revision: yes
Circularity Check
No circularity: derivation relies on external pretrained video model and independent geometric validators
full rationale
The paper's core derivation transfers motion priors from an external pretrained 2D video diffusion model into a rig-parameter distribution, then applies differentiable validators (self-intersection, joint limits) post-skinning. No quoted equations or steps reduce a claimed prediction to a fitted input by construction, nor does any load-bearing premise rest on a self-citation chain whose validity is internal to the paper. Zero-shot generalization to unseen topologies is presented as an empirical outcome of training rather than a definitional equivalence. The framework is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Software (2026),https://firefly.adobe.com , accessed: 2026-01-18
Adobe: Adobe firefly. Software (2026),https://firefly.adobe.com , accessed: 2026-01-18
2026
-
[2]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2024), https://vveicao.github.io/projects/Motion2VecSets/
Cao, W., Luo, C., Zhang, B., Nießner, M., Tang, J.: Motion2vecsets: 4d latent vector set diffusion for non-rigid shape reconstruction and tracking. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2024), https://vveicao.github.io/projects/Motion2VecSets/
2024
-
[3]
SAM 3D: 3Dfy Anything in Images
Chen, X., Chu, F.J., Gleize, P., Liang, K.J., Sax, A., Tang, H., Wang, W., Guo, M., Hardin, T., Li, X., et al.: Sam 3d: 3dfy anything in images. arXiv preprint arXiv:2511.16624 (2025)
work page internal anchor Pith review arXiv 2025
-
[4]
In: SIGGRAPH (2025)
Deng, Y., Zhang, Y., Geng, C., Wu, S., Wu, J.: Anymate: A dataset and baselines for learning 3d object rigging. In: SIGGRAPH (2025)
2025
-
[5]
Dutt, N.S., Muralikrishnan, S., Mitra, N.J.: Diffusion 3d features (diff3f): Decorating untexturedshapeswithdistilledsemanticfeatures.In:ProceedingsoftheIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 4494–4504 (June 2024)
2024
-
[6]
SIGGRAPH (2025)
Gat, I., Raab, S., Tevet, G., Reshef, Y., Bermano, A.H., Cohen-Or, D.: Anytop: Character animation diffusion with any topology. SIGGRAPH (2025)
2025
-
[7]
Advances in neural information processing systems33, 6840–6851 (2020)
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. Advances in neural information processing systems33, 6840–6851 (2020)
2020
-
[8]
In: NeurIPS Workshop on Deep Generative Models and Downstream Applications (2021)
Ho, J., Salimans, T.: Classifier-free diffusion guidance. In: NeurIPS Workshop on Deep Generative Models and Downstream Applications (2021)
2021
- [9]
-
[10]
Kavan, L., Collins, S., Žára, J., O’Sullivan, C.: Geometric skinning with approximate dual quaternion blending. SIGGRAPH pp. 105:1–105:10 (2008).https://doi.org/ 10.1145/1399504.1360717
-
[11]
ACM Transactions on Graphics (SIGGRAPH)26(3), #64, 1–8 (2007)
Kilian, M., Mitra, N.J., Pottmann, H.: Geometric modeling in shape space. ACM Transactions on Graphics (SIGGRAPH)26(3), #64, 1–8 (2007)
2007
-
[12]
Labs, B.F.: FLUX.2: Frontier Visual Intelligence.https://bfl.ai/blog/flux-2 (2025)
2025
-
[13]
In: Proceedings of the 1999 symposium on Interactive 3D graphics
Lengyel, J.E.: Compression of time-dependent geometry. In: Proceedings of the 1999 symposium on Interactive 3D graphics. pp. 89–95 (1999) 16 Honglin Chen et al
1999
-
[14]
In: Proceedings of the 27th Annual Conference on Computer Graphics and Interactive Techniques (2000)
Lewis, J.P., Cordner, M., Fong, N.: Pose space deformation: a unified approach to shape interpolation and skeleton-driven deformation. In: Proceedings of the 27th Annual Conference on Computer Graphics and Interactive Techniques (2000)
2000
-
[15]
ACM Transactions on Graphics (TOG)41(4), 138 (2022)
Li, P., Aberman, K., Zhang, Z., Hanocka, R., Sorkine-Hornung, O.: Ganimator: Neural motion synthesis from a single sequence. ACM Transactions on Graphics (TOG)41(4), 138 (2022)
2022
-
[16]
Particulate: Feed-Forward 3D Object Articulation.arXiv preprint arXiv:2512.11798,
Li, R., Yao, Y., Zheng, C., Rupprecht, C., Lasenby, J., Wu, S., Vedaldi, A.: Par- ticulate: Feed-forward 3d object articulation. arXiv preprint arXiv:2512.11798 (2025)
-
[17]
ACM Trans
Lipman, Y., Cohen-Or, D., Gal, R., Levin, D.: Volume and shape preservation via moving frame manipulation. ACM Trans. Graph.26(1), 5–es (Jan 2007)
2007
-
[18]
ACM TOG44(4), 1–12 (2025)
Liu, I., Xu, Z., Yifan, W., Tan, H., Xu, Z., Wang, X., Su, H., Shi, Z.: Riganything: Template-free autoregressive rigging for diverse 3d assets. ACM TOG44(4), 1–12 (2025)
2025
-
[19]
Singapo: Single image controlled generation of articulated parts in objects,
Liu, J., Iliash, D., Chang, A.X., Savva, M., Mahdavi-Amiri, A.: SINGAPO: Sin- gle image controlled generation of articulated parts in object. arXiv preprint arXiv:2410.16499 (2024)
-
[20]
In: ICLR (2025), https://arxiv.org/abs/2510.18489
Liu, J., Kong, L., Zhou, M., Chen, J., Xu, D.: Mono4dgs-hdr: High dynamic range 4d gaussian splatting from alternating-exposure monocular videos. In: ICLR (2025), https://arxiv.org/abs/2510.18489
-
[21]
In: ICCV (2025)
Lu, J., Lin, J., Dou, H., Zeng, A., Deng, Y., Liu, X., Cai, Z., Yang, L., Zhang, Y., Wang, H., Liu, Z.: Dposer-x: Diffusion model as robust 3d whole-body human pose prior. In: ICCV (2025)
2025
-
[22]
Advances in neural information processing systems (2025)
Luo, Z., Ran, H., Lu, L.: Instant4d: 4d gaussian splatting in minutes. Advances in neural information processing systems (2025)
2025
-
[23]
In: Proceedings on Graphics interface’88
Magnenat-Thalmann, N., Laperrière, R., Thalmann, D.: Joint-dependent local deformations for hand animation and object grasping. In: Proceedings on Graphics interface’88. pp. 26–33 (1989)
1989
-
[24]
In: Proceedings of the 16th ACM SIGGRAPH Conference on Motion, Interaction and Games (2023)
Maiorca, A., Bohy, H., Yoon, Y., Dutoit, T.: Objective evaluation metric for motion generative models: Validating fréchet motion distance on foot skating and over- smoothing artifacts. In: Proceedings of the 16th ACM SIGGRAPH Conference on Motion, Interaction and Games (2023)
2023
-
[25]
In: ACM SIGGRAPH 2022 Posters (2022)
Maiorca, A., Yoon, Y., Dutoit, T.: Evaluating the quality of a synthesized motion with the fréchet motion distance. In: ACM SIGGRAPH 2022 Posters (2022)
2022
-
[26]
Advances in neural information processing systems28(2015)
Maystre, L., Grossglauser, M.: Fast and accurate inference of plackett–luce models. Advances in neural information processing systems28(2015)
2015
-
[27]
In: Proc
Mo, C., Hu, K., Long, C., Yuan, D., Wang, Z.: Motion keyframe interpolation for any human skeleton via temporally consistent point cloud sampling and reconstruction. In: Proc. ECCV. p. 159–175 (2024)
2024
-
[28]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (2025)
Mou, L., Lei, J., Wang, C., Liu, L., Daniilidis, K.: Dimo: Diverse 3d motion generation for arbitrary objects. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (2025)
2025
- [29]
-
[30]
In: NeurIPS work- shop: AI for non-human animal communication (2025)
Noronha, I., Chowdhury, A., Bharti, S., Kaur, U.: Quadforecaster: Diffusion-based quadruped pose prediction for animal communication analysis. In: NeurIPS work- shop: AI for non-human animal communication (2025)
2025
-
[31]
Software (2026),https://openai.com/index/sora-2/, accessed: 2026-01-18 ViPS: Video-informed Pose Spaces 17
OpenAI: Sora 2. Software (2026),https://openai.com/index/sora-2/, accessed: 2026-01-18 ViPS: Video-informed Pose Spaces 17
2026
-
[32]
Transactions on Machine Learning Research Journal pp
Oquab, M., Darcet, T., Moutakanni, T., Vo, H., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., et al.: Dinov2: Learning robust visual features without supervision. Transactions on Machine Learning Research Journal pp. 1–31 (2024)
2024
-
[33]
Pandey, K., Hold-Geoffroy, Y., Gadelha, M., Mitra, N.J., Singh, K., Guerrero, P.: Motion modes: What could happen next? In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 2030–2039 (2025)
2030
-
[34]
ACM Trans
Park, K., Sinha, U., Hedman, P., Barron, J.T., Bouaziz, S., Goldman, D.B., Martin- Brualla, R., Seitz, S.M.: Hypernerf: a higher-dimensional representation for topo- logically varying neural radiance fields. ACM Trans. Graph.40(6) (Dec 2021)
2021
-
[35]
In: CVPR (2020)
Pumarola, A., Corona, E., Pons-Moll, G., Moreno-Noguer, F.: D-nerf: Neural radiance fields for dynamic scenes. In: CVPR (2020)
2020
-
[36]
Articulate anymesh: Open-vocabulary 3d articu- lated objects modeling,
Qiu, X., Yang, J., Wang, Y., Chen, Z., Wang, Y., Wang, T.H., Xian, Z., Gan, C.: Articulate anymesh: Open-vocabulary 3d articulated objects modeling. arXiv preprint arXiv:2502.02590 (2025)
-
[37]
Journal of machine learning research21(140), 1–67 (2020)
Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y., Li, W., Liu, P.J.: Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of machine learning research21(140), 1–67 (2020)
2020
- [38]
-
[39]
In: CVPR (2026)
Sabathier, R., Novotny, D., Mitra, N.J., Monnier, T.: Actionmesh: Animated 3d mesh generation with temporal 3d diffusion. In: CVPR (2026)
2026
-
[40]
Song, C., Li, X., Yang, F., Xu, Z., Wei, J., Liu, F., Feng, J., Lin, G., Zhang, J.: Puppeteer: Rig and animate your 3d models. In: Adv. Neural Inform. Process. Syst. (2025)
2025
-
[41]
In: International Conference on Learning Representations (ICLR) (2021)
Song, J., Meng, C., Ermon, S.: Denoising diffusion implicit models. In: International Conference on Learning Representations (ICLR) (2021)
2021
-
[42]
ACM Trans- actions on graphics (TOG)23(3), 399–405 (2004)
Sumner, R.W., Popović, J.: Deformation transfer for triangle meshes. ACM Trans- actions on graphics (TOG)23(3), 399–405 (2004)
2004
-
[43]
THU-ML: TurboDiffusion: 100–200× acceleration for video diffusion models.https: //github.com/thu-ml/TurboDiffusion (2025), gitHub repository, accessed 2026- 01-18
2025
-
[44]
In: ECCV (2022)
Tiwari, G., Antic, D., Lenssen, J.E., Sarafianos, N., Tung, T., Pons-Moll, G.: Pose-ndf: Modeling human pose manifolds with neural distance fields. In: ECCV (2022)
2022
-
[45]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.W., Chen, D., Yu, F., Zhao, H., Yang, J., Zeng, J., Wang, J., Zhang, J., Zhou, J., Wang, J., Chen, J., Zhu, K., Zhao, K., Yan, K., Huang, L., Feng, M., Zhang, N., Li, P., Wu, P., Chu, R., Feng, R., Zhang, S., Sun, S., Fang, T., Wang, T., Gui, T., Weng, T., Shen, T., Lin, W., Wang, W., Wang, W., Zhou, W.,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Wang, W., Gao, Z., Gu, L., Pu, H., Cui, L., Wei, X., Liu, Z., Jing, L., Ye, S., Shao, J., et al.: Internvl3.5: Advancing open-source multimodal models in versatility, reasoning, and efficiency. arXiv preprint arXiv:2508.18265 (2025)
work page internal anchor Pith review arXiv 2025
-
[47]
In: CVPR (2024) 18 Honglin Chen et al
Weng, Y., Wen, B., Tremblay, J., Blukis, V., Fox, D., Guibas, L., Birchfield, S.: Neural implicit representation for building digital twins of unknown articulated objects. In: CVPR (2024) 18 Honglin Chen et al
2024
-
[48]
Video models are zero-shot learners and reasoners
Wiedemer, T., Li, Y., Vicol, P., Gu, S.S., Matarese, N., Swersky, K., Kim, B., Jaini, P., Geirhos, R.: Video models are zero-shot learners and reasoners. arXiv preprint arXiv:2509.20328 (2025)
work page internal anchor Pith review arXiv 2025
-
[49]
What’s in the image? a deep-dive into the vision of vision language models
Wu, D., Liu, F., Hung, Y.H., Qian, Y., Zhan, X., Duan, Y.: 4d-fly: Fast 4d recon- struction from a single monocular video. In: Proc. CVPR. pp. 16663–16673 (06 2025).https://doi.org/10.1109/CVPR52734.2025.01553
-
[50]
ACM TOG39(4), 58–1 (2020)
Xu, Z., Zhou, Y., Kalogerakis, E., Landreth, C., Singh, K.: Rignet: neural rigging for articulated characters. ACM TOG39(4), 58–1 (2020)
2020
-
[51]
Xu, Z., Li, Z., Dong, Z., Zhou, X., Newcombe, R., Lv, Z.: 4dgt: Learning a 4d gaussian transformer using real-world monocular videos. In: Adv. Neural Inform. Process. Syst. (2025)
2025
-
[52]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Yang, Z., Teng, J., Zheng, W., Ding, M., Huang, S., Xu, J., Yang, Y., Hong, W., Zhang, X., Feng, G., et al.: Cogvideox: Text-to-video diffusion models with an expert transformer. arXiv preprint arXiv:2408.06072 (2024)
work page internal anchor Pith review arXiv 2024
-
[53]
Advances in Neural Information Processing Systems (2024)
Ye, Z., Liu, J.W., Jia, J., Sun, S., Shou, M.Z.: Skinned motion retargeting with dense geometric interaction perception. Advances in Neural Information Processing Systems (2024)
2024
-
[54]
arXiv preprint (2025)
Yenphraphai, J., Mirzaei, A., Chen, J., Zou, J., Tulyakov, S., Yeh, R.A., Wonka, P., Wang, C.: Shapegen4d: Towards high quality 4d shape generation from videos. arXiv preprint (2025)
2025
-
[55]
In: ACM TOG
Yu, Y., Zhou, K., Xu, D., Shi, X., Bao, H., Guo, B., Shum, H.Y.: Mesh editing with poisson-based gradient field manipulation. In: ACM TOG. pp. 644–651 (2004)
2004
-
[56]
arXiv preprint arXiv:2601.06378 (2026) 5, 16
Zhang, H., Luo, J., Wan, B., Zhao, Y., Li, Z., Vasilkovsky, M., Wang, C., Wang, J., Ahuja, N., Zhou, B.: Rigmo: Unifying rig and motion learning for generative animation. arXiv preprint arXiv:2601.06378 (2026)
-
[57]
In: ICCV (2025)
Zhang, H., Xu, H., Feng, C., Jampani, V., Ahuja, N.: Physrig: Differentiable physics- based skinning and rigging framework for realistic articulated object modeling. In: ICCV (2025)
2025
-
[58]
In: The Twelfth International Conference on Learning Representations (ICLR) (2024)
Zhang, J., Huang, S., Tu, Z., Chen, X., Zhan, X., Yu, G., Shan, Y.: Tapmo: Shape- aware motion generation of skeleton-free characters. In: The Twelfth International Conference on Learning Representations (ICLR) (2024)
2024
-
[59]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Zhang, J., Weng, J., Kang, D., Zhao, F., Huang, S., Zhe, X., Bao, L., Shan, Y., Wang, J., Tu, Z.: Skinned motion retargeting with residual perception of motion semantics & geometry. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13864–13872 (2023)
2023
-
[60]
Motiondiffuse: Text-driven human motion generation with diffusion model
Zhang, M., Cai, Z., Pan, L., Hong, F., Guo, X., Yang, L., Liu, Z.: Motiondif- fuse: Text-driven human motion generation with diffusion model. arXiv preprint arXiv:2208.15001 (2022) ViPS: Video-informed Pose Spaces for Auto-Rigged Meshes Supplementary Material Honglin Chen1,2∗ , Karran Pandey3 , Rundi Wu1 , Matheus Gadelha2 , Yannick Hold-Geoffroy2 , Ayush...
-
[61]
EXACT SUBJECT : Use the pro vi de d object / species name as the subject ; do NOT change it to a d i f f e r e n t species / object
-
[62]
FULL - BODY / FULL - OBJECT ( CR IT IC AL ) : The ENTIRE subject must be visible from end to end ( e . g . , head - to - toe / nose - to - tail / top - to - bottom ) . A b s o l u t e l y NO cropping , NO cut - off limbs / ears / tail , NO partial framing . Keep the subject ce nt er ed with ge ner ou s margins
-
[63]
WIDE SHOT ( C RI TI CA L ) : Use a wide shot with the camera pulled back enough to g u a r a n t e e the whole subject fits c o m f o r t a b l y in frame , with extra space around it
-
[64]
NO ground plane , NO visible floor line , NO horizon
B A C K G R O U N D : Solid pure white studio b a c k g r o u n d . NO ground plane , NO visible floor line , NO horizon
-
[65]
Avoid harsh cast shadows ; keep r e f l e c t i o n s minimal
L IG HT IN G : Even , soft , s h a d o w l e s s studio li gh ti ng . Avoid harsh cast shadows ; keep r e f l e c t i o n s minimal
-
[66]
ViPS: Video-informed Pose Spaces – Supplementary Material 7
NO NEW E LE ME NTS : Do NOT i n t r o d u c e any other objects , humans , animals , props , text , logos , watermarks , scenery , or clutter . ViPS: Video-informed Pose Spaces – Supplementary Material 7
-
[67]
Use side or front three - quarter v i e w p o i n t ; AVOID direct front or rear views . D i v e r s i t y r e q u i r e m e n t s ( across prompts for the same subject ) : - Vary v i e w p o i n t ( side / front three - quarter ) , slight tilt angle ( e s p e c i a l l y for animals ) , and pose / o r i e n t a t i o n while ALWAYS keeping full - body / ...
-
[68]
Do NOT replace it with a d i f f e r e n t motion
** Use the P rov id ed Motion EXACTLY :** The prompt MUST des cr ib e the target motion f a i t h f u l l y . Do NOT replace it with a d i f f e r e n t motion . Do NOT add extra actions beyond what is stated
-
[69]
Do NOT invent new colors , accessories , markings , clothing , species , or extra objects
** Keep A p p e a r a n c e C O N S I S T E N T :** Use the pr ov id ed a p p e a r a n c e d e s c r i p t i o n as - is . Do NOT invent new colors , accessories , markings , clothing , species , or extra objects
-
[70]
If s o m e t h i n g is not m e n t i o n e d in the appearance , it must not appear in the prompt
** NO NEW EL EM EN TS ( VERY STRICT ) :** Do NOT i n t r o d u c e any new objects , humans , animals , props , accessories , text , logos , extra scenery items , or a d d i t i o n a l en ti tie s not e x p l i c i t l y present in the p ro vid ed a p p e a r a n c e d e s c r i p t i o n . If s o m e t h i n g is not m e n t i o n e d in the appearance ...
-
[71]
No new items in the scene
** B a c k g r o u n d & L ig ht in g :** Keep the b a c k g r o u n d simple and stable , c o n s i s t e n t with the p ro vid ed a p p e a r a n c e . No new items in the scene
-
[72]
pan " ,
** Camera Be ha vio r :** ST RI CT LY STATIC FULL BODY SHOT . Tripod - locked . The entire object visible at all times . ** Single shot , no transitions , no cuts .** NO camera m ov eme nt . Avoid words like " pan " , " zoom " , " track " , " dolly " , " close - up " , " follow " , " cut " , " scene change " , " t r a n s i t i o n " , " montage "
-
[73]
** Natural Physics :** Motion should have r e a l i s t i c weight and timing a p p r o p r i a t e to the object
-
[74]
Photorealistic , 4 k , high f id eli ty
** Style Default :** If no style is specified , default to " Photorealistic , 4 k , high f id eli ty ."
-
[75]
8 Honglin Chen et al
** Length :** 60 -90 words . 8 Honglin Chen et al. Output ONLY the final prompt . No quotes . No bullet points . No extra c o m m e n t a r y . Object ( appearance , keep exact ) : < appearance_text > Target Motion ( must use exact ) : < motion_text > Camera C o n s t r a i n t ( must use exact ) : Static Full Body Shot ( Tripod View ) . The entire object...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.