Recognition: unknown
Fine-Tuning Small Reasoning Models for Quantum Field Theory
Pith reviewed 2026-05-10 03:19 UTC · model grok-4.3
The pith
Fine-tuning 7B reasoning models on synthetic and human-adapted Quantum Field Theory problems improves performance on QFT tasks and shows some generalization to other physics domains.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors establish that the first academic fine-tuning of 7B-parameter reasoning models specifically for Quantum Field Theory, using a combination of over 2,500 synthetic problems generated by their pipeline and curated human-authored problems, produces measurable gains in problem-solving accuracy under both reinforcement learning and supervised fine-tuning, with partial generalization to other physics domains and visible evolution in the patterns of reasoning errors.
What carries the argument
The data generation pipeline that both creates synthetic verifiable QFT problems and converts existing human problems into training-ready format.
If this is right
- Accuracy on QFT problems rises after both RL and SFT stages.
- Some of the acquired capability transfers to reasoning tasks in other physics domains.
- Analysis of model chains-of-thought shows how specific types of reasoning errors decrease during training.
- The released pipeline, dataset, and 200 million tokens of QFT reasoning traces enable further experiments by others.
Where Pith is reading between the lines
- The same pipeline could be reused to create training data for other advanced physics topics such as general relativity or particle phenomenology.
- Models trained this way might eventually be tested on open-ended research-style questions rather than closed textbook problems.
- Public release of the verifiable problems and traces provides a benchmark resource that future studies of LLM physics reasoning can build upon.
Load-bearing premise
That performance gains reflect the development of transferable QFT reasoning rather than the models learning to match patterns in the generated training set.
What would settle it
If a fresh set of QFT problems that require derivations outside the style and content of the training examples shows no accuracy improvement after fine-tuning, the claim that genuine reasoning ability was acquired would be undermined.
Figures


















read the original abstract
Despite the growing application of Large Language Models (LLMs) to theoretical physics, there is little academic exploration into how domain-specific physics reasoning ability develops while training these models. To investigate this, we perform the first academic fine-tuning study of small (7B-parameter) reasoning models dedicated specifically to theoretical physics. Because open-source verifiable training data required to train such capabilities is scarce, we developed a robust data generation pipeline that can both create synthetic problems and make existing human-authored problems suitable for model training. Selecting Quantum Field Theory (QFT) as our primary domain, we generated over 2,500 synthetic problems alongside a curated collection of human-adapted problems sourced from arXiv and standard pedagogical resources. We conduct both Reinforcement Learning (RL) and Supervised Fine-Tuning (SFT) experiments, benchmarking performance gains as well as generalization to other physics domains. We perform an extensive analysis of model chains-of-though before and after fine-tuning, to understand how reasoning errors evolve during RL and SFT. Finally, we publicly release our data pipeline, verifiable QFT training data, and $\sim$200M tokens of QFT reasoning traces.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims to conduct the first academic fine-tuning study of 7B-parameter reasoning models for Quantum Field Theory (QFT). It introduces a data generation pipeline producing over 2,500 synthetic verifiable QFT problems plus curated human-adapted problems from arXiv and textbooks, performs both Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) experiments, benchmarks performance gains and generalization to other physics domains, analyzes evolution of chain-of-thought reasoning errors, and publicly releases the pipeline, training data, and ~200M tokens of reasoning traces.
Significance. If the reported gains and generalization hold under rigorous evaluation, the work would be significant for establishing a reproducible foundation for domain-specific fine-tuning in theoretical physics. The public release of the data pipeline, verifiable QFT problems, and reasoning traces is a clear strength that enables follow-on research and addresses the scarcity of open training resources in this area.
major comments (2)
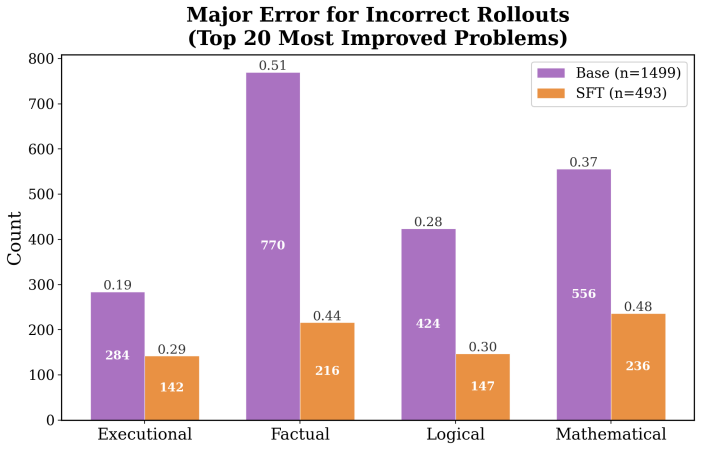
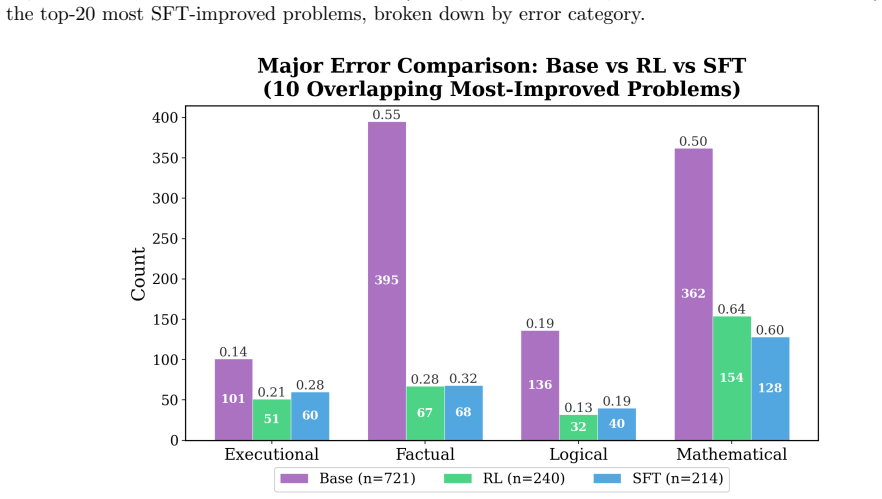
- [§5] §5 (Experiments and Results): The benchmarking of performance gains and generalization to other physics domains is described at a high level but lacks concrete quantitative metrics (e.g., accuracy, pass rates, or error reductions with standard deviations), baseline comparisons, or statistical tests. This makes it impossible to assess whether observed improvements exceed what would be expected from pattern matching on the synthetic data.
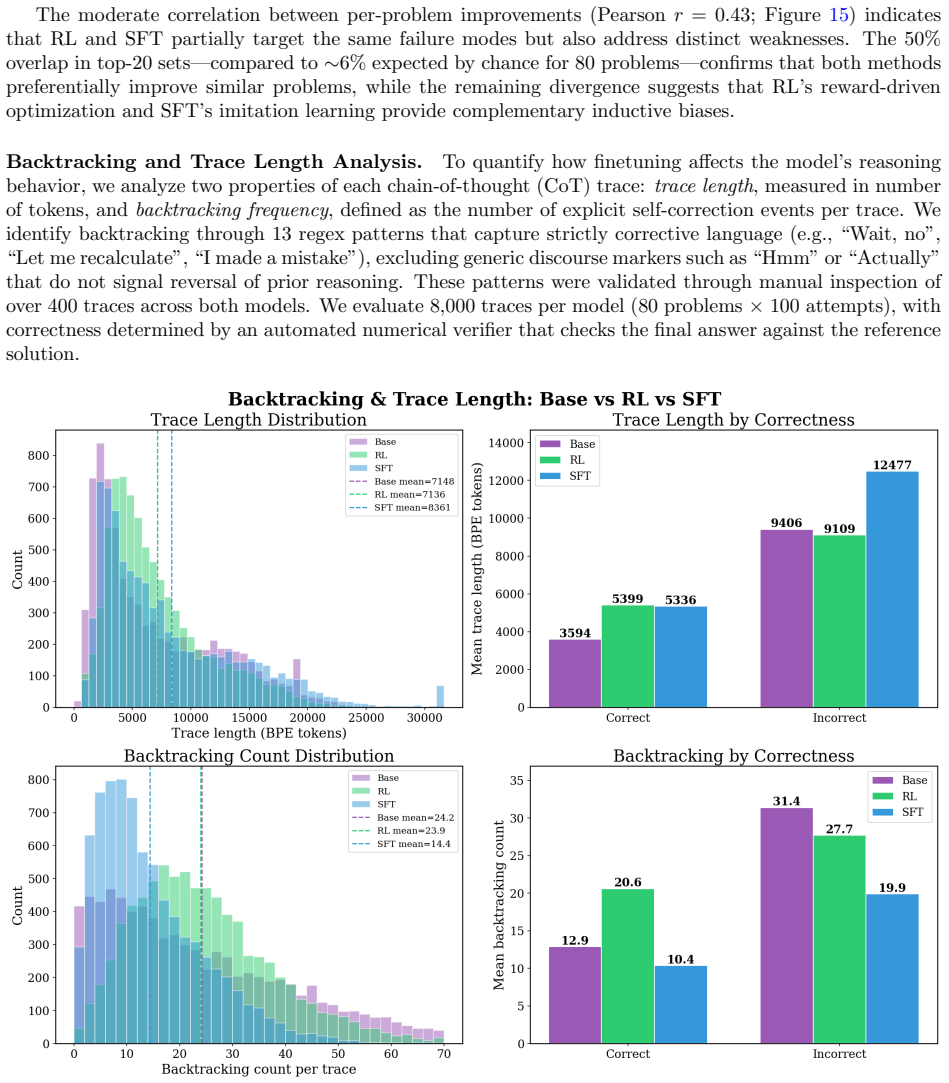
- [§6] §6 (Chain-of-Thought Analysis): The analysis of how reasoning errors evolve during SFT and RL is primarily qualitative. Without quantitative categorization of error types (e.g., algebraic mistakes vs. conceptual misunderstandings) or before/after success rates on held-out problems, it is difficult to substantiate the claim that fine-tuning produces transferable QFT understanding rather than superficial adaptations to the training distribution.
minor comments (2)
- The abstract would be strengthened by including one or two key quantitative results (e.g., percentage improvement on QFT benchmarks) to allow readers to immediately gauge the magnitude of the reported gains.
- [Data Release] Ensure that the released dataset documentation explicitly describes the verification procedure for synthetic problems and any human review steps applied to arXiv-sourced material.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments, which highlight opportunities to strengthen the quantitative rigor of our evaluation. We address each major comment below and commit to revisions that provide the requested metrics and analyses without altering the core claims of the work.
read point-by-point responses
-
Referee: [§5] §5 (Experiments and Results): The benchmarking of performance gains and generalization to other physics domains is described at a high level but lacks concrete quantitative metrics (e.g., accuracy, pass rates, or error reductions with standard deviations), baseline comparisons, or statistical tests. This makes it impossible to assess whether observed improvements exceed what would be expected from pattern matching on the synthetic data.
Authors: We acknowledge that the presentation in §5 is currently summarized at a high level. In the revised manuscript we will add explicit quantitative results, including accuracy and pass rates on held-out QFT problems, generalization metrics to other physics domains, comparisons against the base 7B model and additional baselines, standard deviations from repeated runs, and statistical significance tests. These additions will enable direct assessment of whether gains exceed pattern matching on the synthetic distribution. revision: yes
-
Referee: [§6] §6 (Chain-of-Thought Analysis): The analysis of how reasoning errors evolve during SFT and RL is primarily qualitative. Without quantitative categorization of error types (e.g., algebraic mistakes vs. conceptual misunderstandings) or before/after success rates on held-out problems, it is difficult to substantiate the claim that fine-tuning produces transferable QFT understanding rather than superficial adaptations to the training distribution.
Authors: We agree that the CoT analysis would be strengthened by quantitative support. We will expand §6 to include a categorized breakdown of error types with counts and percentages before and after fine-tuning, together with success rates on held-out problems. This will provide clearer evidence regarding the nature of the observed improvements. While some interpretive aspects of reasoning evolution remain qualitative, the added metrics will make the section substantially more rigorous. revision: partial
Circularity Check
No significant circularity in empirical fine-tuning study
full rationale
This is a purely empirical machine-learning paper describing a data generation pipeline for synthetic and human-adapted QFT problems, followed by SFT and RL fine-tuning experiments on 7B models, with benchmarking of performance gains, generalization to other domains, and CoT analysis. No mathematical derivations, equations, or first-principles results are claimed whose outputs are defined in terms of their own inputs or fitted parameters. Central claims rest on measured experimental outcomes and a public data release rather than internal self-definitions, self-citation chains, or renamed known results. The study is self-contained against external benchmarks (model performance before/after fine-tuning) with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
free parameters (1)
- Fine-tuning hyperparameters (learning rate, batch size, RL reward scaling, etc.)
axioms (1)
- domain assumption Synthetic data generated by the pipeline can train transferable QFT reasoning capabilities
Reference graph
Works this paper leans on
-
[1]
Aitor Lewkowycz et al.Solving Quantitative Reasoning Problems with Language Models. 2022. arXiv: 2206.14858 [cs.CL].url:https://arxiv.org/abs/2206.14858
work page internal anchor Pith review arXiv 2022
-
[2]
Ross Taylor et al.Galactica: A Large Language Model for Science. 2022. arXiv:2211.09085 [cs.CL]. url:https://arxiv.org/abs/2211.09085
work page internal anchor Pith review arXiv 2022
- [3]
- [4]
- [5]
-
[6]
Xinyu Zhang et al.PhysReason: A Comprehensive Benchmark towards Physics-Based Reasoning
- [7]
- [8]
- [9]
-
[10]
Paul Tschisgale et al. “Evaluating GPT- and reasoning-based large language models on Physics Olympiad problems: Surpassing human performance and implications for educational assessment”. In: Physical Review Physics Education Research21.2 (Aug. 2025).issn: 2469-9896.doi:10.1103/6fmx- bsnl.url:http://dx.doi.org/10.1103/6fmx-bsnl
-
[11]
Haining Pan et al. “Quantum many-body physics calculations with large language models”. In:Com- munications Physics8.1 (Jan. 2025).issn: 2399-3650.doi:10.1038/s42005- 025- 01956- y.url: http://dx.doi.org/10.1038/s42005-025-01956-y
-
[12]
Learning-at-Criticality in Large Language Models for Quantum Field Theory and Beyond
Xiansheng Cai et al. “Learning-at-Criticality in Large Language Models for Quantum Field Theory and Beyond”. In:Chinese Physics Letters42.12 (Nov. 2025), p. 120002.issn: 1741-3540.doi:10. 1088/0256-307x/42/12/120002.url:http://dx.doi.org/10.1088/0256-307X/42/12/120002. 32
-
[13]
Kristian G. Barman et al. “Large physics models: towards a collaborative approach with large language models and foundation models”. In:The European Physical Journal C85.9 (Sept. 2025).issn: 1434- 6052.doi:10.1140/epjc/s10052-025-14707-8.url:http://dx.doi.org/10.1140/epjc/s10052- 025-14707-8
work page doi:10.1140/epjc/s10052-025-14707-8.url:http://dx.doi.org/10.1140/epjc/s10052- 2025
- [14]
- [15]
-
[16]
Solving olympiad geometry without human demonstrations
T. H. Trinh, Y. Wu, Q. V. Le, et al. “Solving olympiad geometry without human demonstrations”. In: Nature625 (2024), pp. 476–482.url:https://www.nature.com/articles/s41586-023-06747-5
2024
-
[17]
2024.url:https : / / deepmind
AlphaProof and AlphaGeometry TEams.Ai achieves silver-medal standard solving International Mathematical Olympiad Problems. 2024.url:https : / / deepmind . google / discover / blog / ai - solves-imo-problems-at-silver-medal-level/
2024
-
[18]
Yichen Huang and Lin F. Yang.Winning Gold at IMO 2025 with a Model-Agnostic Verification-and- Refinement Pipeline. 2025. arXiv:2507.15855 [cs.AI].url:https://arxiv.org/abs/2507.15855
- [19]
- [20]
-
[21]
Minhui Zhu et al.Probing the Critical Point (CritPt) of AI Reasoning: a Frontier Physics Research Benchmark. 2025. arXiv:2509.26574 [cs.AI].url:https://arxiv.org/abs/2509.26574
work page internal anchor Pith review arXiv 2025
- [22]
- [23]
- [24]
- [25]
-
[26]
Yutaro Yamada et al.The AI Scientist-v2: Workshop-Level Automated Scientific Discovery via Agen- tic Tree Search. 2025. arXiv:2504.08066 [cs.AI].url:https://arxiv.org/abs/2504.08066
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [27]
- [28]
-
[29]
VCR: A Cone of Experience Driven Synthetic Data Generation Framework for Mathematical Reasoning
Sannyuya Liu et al. “VCR: A Cone of Experience Driven Synthetic Data Generation Framework for Mathematical Reasoning”. In:Proceedings of the AAAI Conference on Artificial Intelligence39.23 (2025), pp. 24650–24658.doi:10.1609/aaai.v39i23.34645.url:https://ojs.aaai.org/index. php/AAAI/article/view/34645
work page doi:10.1609/aaai.v39i23.34645.url:https://ojs.aaai.org/index 2025
- [30]
- [31]
-
[32]
Orchestrating Synthetic Data with Reasoning
Tim R. Davidson et al. “Orchestrating Synthetic Data with Reasoning”. In:Will Synthetic Data Fi- nally Solve the Data Access Problem?2025.url:https://openreview.net/forum?id=VOoeogZbMb
2025
-
[33]
Tongyi DeepResearch Team et al.Tongyi DeepResearch Technical Report. 2025. arXiv:2510.24701 [cs.CL].url:https://arxiv.org/abs/2510.24701
work page internal anchor Pith review arXiv 2025
- [34]
-
[35]
Suriya Gunasekar et al.Textbooks Are All You Need. 2023. arXiv:2306.11644 [cs.CL].url:https: //arxiv.org/abs/2306.11644
work page internal anchor Pith review arXiv 2023
-
[36]
Yuanzhi Li et al.Textbooks Are All You Need II: phi-1.5 technical report. 2023. arXiv:2309.05463 [cs.CL].url:https://arxiv.org/abs/2309.05463
work page internal anchor Pith review arXiv 2023
-
[37]
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean.Distilling the Knowledge in a Neural Network. 2015. arXiv:1503.02531 [stat.ML].url:https://arxiv.org/abs/1503.02531
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[38]
Subhabrata Mukherjee et al.Orca: Progressive Learning from Complex Explanation Traces of GPT-4
- [39]
- [40]
-
[41]
Yuxian Gu et al.MiniLLM: On-Policy Distillation of Large Language Models. 2026. arXiv:2306. 08543 [cs.CL].url:https://arxiv.org/abs/2306.08543
work page internal anchor Pith review arXiv 2026
-
[42]
Daya Guo et al. “DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning”. In: Nature645.8081 (Sept. 2025), 633638.issn: 1476-4687.doi:10.1038/s41586- 025- 09422- z.url: http://dx.doi.org/10.1038/s41586-025-09422-z
- [43]
-
[44]
Hoang Anh Just, Myeongseob Ko, and Ruoxi Jia.Distilling Reasoning into Student LLMs: Local Naturalness for Selecting Teacher Data. 2025. arXiv:2510.03988 [cs.LG].url:https://arxiv. org/abs/2510.03988
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
arXiv preprint arXiv:2503.03730 , year=
David D. Baek and Max Tegmark.Towards Understanding Distilled Reasoning Models: A Represen- tational Approach. 2025. arXiv:2503.03730 [cs.LG].url:https://arxiv.org/abs/2503.03730
-
[46]
Hunter Lightman et al.Let’s Verify Step by Step. 2023. arXiv:2305.20050 [cs.LG].url:https: //arxiv.org/abs/2305.20050
work page internal anchor Pith review arXiv 2023
-
[47]
Jonathan Uesato et al.Solving math word problems with process- and outcome-based feedback. 2022. arXiv:2211.14275 [cs.LG].url:https://arxiv.org/abs/2211.14275
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[48]
Zhihong Shao et al.DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models. 2024. arXiv:2402.03300 [cs.CL].url:https://arxiv.org/abs/2402.03300
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [49]
- [50]
- [51]
- [52]
- [53]
-
[54]
Zhenru Zhang et al.The Lessons of Developing Process Reward Models in Mathematical Reasoning
- [55]
-
[56]
Peiyi Wang et al.Math-Shepherd: Verify and Reinforce LLMs Step-by-step without Human Annota- tions. 2024. arXiv:2312.08935 [cs.AI].url:https://arxiv.org/abs/2312.08935
work page internal anchor Pith review arXiv 2024
- [57]
- [58]
- [59]
- [60]
-
[61]
DeepSeek-AI.DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
-
[62]
arXiv:2501.12948 [cs.CL].url:https://arxiv.org/abs/2501.12948
work page internal anchor Pith review Pith/arXiv arXiv
-
[63]
Qwen Team.Qwen3 Technical Report. 2025. arXiv:2505.09388 [cs.CL].url:https://arxiv.org/ abs/2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[64]
Olympiad-Level Formal Mathematical Reasoning with Reinforcement Learn- ing
Thomas Hubert et al. “Olympiad-Level Formal Mathematical Reasoning with Reinforcement Learn- ing”. In:Nature(2025).url:https://www.nature.com/articles/s41586-025-09833-y
2025
-
[65]
Zee.Quantum field theory in a nutshell
A. Zee.Quantum field theory in a nutshell. 2003.isbn: 978-0-691-14034-6
2003
-
[66]
Peskin and Daniel V
Michael E. Peskin and Daniel V. Schroeder.An Introduction to quantum field theory. Reading, USA: Addison-Wesley, 1995.isbn: 978-0-201-50397-5, 978-0-429-50355-9, 978-0-429-49417-8.doi:10.1201/ 9780429503559
1995
-
[67]
Steven Weinberg.The Quantum theory of fields. Vol. 1: Foundations. Cambridge University Press, June 2005.isbn: 978-0-521-67053-1, 978-0-511-25204-4.doi:10.1017/CBO9781139644167
-
[68]
Voja Radovanovic.Problem book in quantum field theory. 2008
2008
-
[69]
Oxford, UK: Oxford University Press, 1984.isbn: 978-0-19-851961-4, 978-0-19-851961-4
Ta-Pei [0000-0002-1137-0969] Cheng and Ling-Fong [0000-0002-8035-3329] Li.Gauge Theory of El- ementary Particle Physics. Oxford, UK: Oxford University Press, 1984.isbn: 978-0-19-851961-4, 978-0-19-851961-4
1984
-
[70]
Massachusetts Institute of Technology: MIT OpenCourseWare
Hong Liu.8.323 Relativistic Quantum Field Theory I. Massachusetts Institute of Technology: MIT OpenCourseWare. Spring 2023. License: Creative Commons BY-NC-SA. 2023.url:https://ocw. mit.edu/courses/8-323-relativistic-quantum-field-theory-i-spring-2023/
2023
-
[71]
Massachusetts Institute of Technology: MIT OpenCourseWare
Hong Liu.8.324 Relativistic Quantum Field Theory II. Massachusetts Institute of Technology: MIT OpenCourseWare. Fall 2010. License: Creative Commons BY-NC-SA. 2010.url:https://ocw.mit. edu/courses/8-324-relativistic-quantum-field-theory-ii-fall-2010/
2010
-
[72]
Massachusetts Institute of Technology: MIT OpenCourseWare
Frank Wilczek.8.325 Relativistic Quantum Field Theory III. Massachusetts Institute of Technology: MIT OpenCourseWare. Spring 2003. License: Creative Commons BY-NC-SA. 2003.url:https : //ocw.mit.edu/courses/8-325-relativistic-quantum-field-theory-iii-spring-2003/
2003
-
[73]
P. Blasiak et al. “Combinatorics and Boson normal ordering: A gentle introduction”. In: (2007).doi: 10.1119/1.2723799. eprint:arXiv:0704.3116
-
[74]
Jean-Yves Ollitrault. “Relativistic hydrodynamics for heavy-ion collisions”. In: (2007).doi:10.1088/ 0143-0807/29/2/010. eprint:arXiv:0708.2433
-
[75]
Raphael Bousso. “TASI Lectures on the Cosmological Constant”. In: (2007).doi:10.1007/s10714- 007-0557-5. eprint:arXiv:0708.4231
-
[76]
Roberto Emparan and Harvey S. Reall. “Black Holes in Higher Dimensions”. In: (2008).doi:10. 12942/lrr-2008-6. eprint:arXiv:0801.3471
- [77]
-
[78]
Stefan Vandoren and Peter van Nieuwenhuizen.Lectures on instantons. 2008. eprint:arXiv:0802. 1862. 35
2008
-
[79]
Ruth Gregory. “Braneworld black holes”. In: (2008).doi:10.1007/978-3-540-88460-6_7. eprint: arXiv:0804.2595
-
[80]
Higher order gravity theories and their black hole solutions
Christos Charmousis. “Higher order gravity theories and their black hole solutions”. In: (2008).doi: 10.1007/978-3-540-88460-6_8. eprint:arXiv:0805.0568
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.