Recognition: no theorem link
Do Hallucination Neurons Generalize? Evidence from Cross-Domain Transfer in LLMs
Pith reviewed 2026-05-15 00:40 UTC · model grok-4.3
The pith
Hallucination neurons fail to generalize across different knowledge domains.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
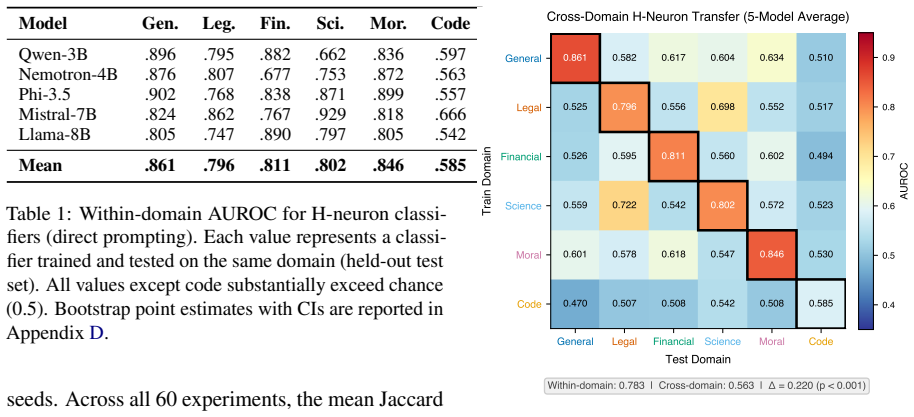
Classifiers trained on one domain's H-neurons achieve an AUROC of 0.783 within that domain but only 0.563 when transferred to a different domain, with the degradation consistent across five models and six domains, implying that hallucination is not driven by a single universal neural mechanism but by domain-dependent neuron populations.
What carries the argument
Hallucination neurons (H-neurons): a sparse set of less than 0.1% of feed-forward network neurons identified by their ability to predict when the model will hallucinate.
If this is right
- Hallucination detectors must be calibrated separately for each domain rather than trained once and applied universally.
- The neural basis of hallucination changes depending on the type of knowledge being processed.
- Neuron-level interventions to reduce hallucinations would require domain-specific targeting to be effective.
Where Pith is reading between the lines
- Models may store and retrieve knowledge in ways that partition neurons by domain rather than sharing a common hallucination pathway.
- A hybrid set of H-neurons drawn from several domains could be tested to see whether it improves cross-domain transfer performance.
- Similar domain-specific patterns may appear in other model behaviors such as factual errors or reasoning failures.
Load-bearing premise
The method for identifying H-neurons produces sets that remain comparable across domains without being skewed by differences in how data is constructed or how the model behaves in each domain.
What would settle it
A cross-domain transfer test in which classifiers retain AUROC near 0.783 would directly contradict the observed degradation and the claim of domain-specific neuron populations.
Figures




read the original abstract
Recent work identifies a sparse set of "hallucination neurons" (H-neurons), less than 0.1% of feed-forward network neurons, that reliably predict when large language models will hallucinate. These neurons are identified on general-knowledge question answering and shown to generalize to new evaluation instances. We ask a natural follow-up question: do H-neurons generalize across knowledge domains? Using a systematic cross-domain transfer protocol across 6 domains (general QA, legal, financial, science, moral reasoning, and code vulnerability) and 5 open-weight models (3B to 8B parameters), we find they do not. Classifiers trained on one domain's H-neurons achieve AUROC 0.783 within-domain but only 0.563 when transferred to a different domain (delta = 0.220, p < 0.001), a degradation consistent across all models tested. Our results suggest that hallucination is not a single mechanism with a universal neural signature, but rather involves domain-specific neuron populations that differ depending on the knowledge type being queried. This finding has direct implications for the deployment of neuron-level hallucination detectors, which must be calibrated per domain rather than trained once and applied universally.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that 'hallucination neurons' (H-neurons), a sparse set (<0.1% of FFN neurons) identified in general-knowledge QA, do not generalize across domains. Using a cross-domain transfer protocol on 6 domains (general QA, legal, financial, science, moral reasoning, code vulnerability) and 5 open-weight models (3B-8B params), linear classifiers on H-neurons achieve within-domain AUROC 0.783 but only 0.563 cross-domain (delta=0.220, p<0.001), implying hallucination involves domain-specific neuron populations rather than a universal neural signature, with implications for per-domain calibration of detectors.
Significance. If the central empirical result holds after addressing controls, the work is significant for LLM interpretability: it provides systematic evidence across multiple models and domains that challenges assumptions of transferable sparse neuron sets for hallucination detection. This has practical value for deployment of neuron-level detectors and motivates domain-aware approaches to mechanistic understanding of hallucinations.
major comments (3)
- [Abstract] Abstract and cross-domain protocol: The interpretation of the AUROC degradation (0.783 within-domain vs. 0.563 cross-domain) as evidence for domain-specific H-neuron populations assumes comparable hallucination labels across domains. However, the domains use differing definitions (factual inconsistency in QA vs. security flaw in code vs. moral violation), which likely introduce non-uniform label noise and decision boundaries; this could produce the observed delta via mismatched supervision without requiring distinct neuron sets. No inter-domain label agreement or standardized criterion is reported.
- [Methods] Methods (neuron identification and transfer): Details on H-neuron selection thresholds, per-domain dataset sizes, exact transfer protocol (e.g., how neurons are identified independently per domain), and controls for domain difficulty or data construction are absent. This is load-bearing for the central claim, as non-comparable neuron sets or confounded transfer could explain the consistent degradation across models without supporting the domain-specificity conclusion.
- [Results] Results: While p<0.001 is reported for the delta, the absence of variance across domains, number of trials, or ablations testing label consistency leaves open whether the drop is driven by labeling differences rather than neuron specificity. This directly affects the strength of the claim that H-neurons 'do not generalize'.
minor comments (1)
- [Abstract] The abstract would benefit from stating the total number of evaluation instances or examples per domain to provide scale context for the AUROC values.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below with point-by-point responses and have revised the paper accordingly where possible to improve clarity and rigor.
read point-by-point responses
-
Referee: [Abstract] Abstract and cross-domain protocol: The interpretation of the AUROC degradation (0.783 within-domain vs. 0.563 cross-domain) as evidence for domain-specific H-neuron populations assumes comparable hallucination labels across domains. However, the domains use differing definitions (factual inconsistency in QA vs. security flaw in code vs. moral violation), which likely introduce non-uniform label noise and decision boundaries; this could produce the observed delta via mismatched supervision without requiring distinct neuron sets. No inter-domain label agreement or standardized criterion is reported.
Authors: We appreciate this concern about label comparability. Hallucination labels were constructed using domain-appropriate criteria (factual errors for QA/legal/financial/science; security flaws for code; ethical violations for moral reasoning) to maintain task validity, with consistent application within each domain via automated verification against ground-truth references where available. The consistent cross-domain drop across all 5 models and 30 transfer pairs supports domain-specific neuron involvement rather than pure label mismatch, as within-domain AUROCs remain high. In revision, we have added explicit labeling criteria per domain in Methods and a Limitations paragraph discussing potential noise; however, we did not compute quantitative inter-rater agreement across domains. revision: partial
-
Referee: [Methods] Methods (neuron identification and transfer): Details on H-neuron selection thresholds, per-domain dataset sizes, exact transfer protocol (e.g., how neurons are identified independently per domain), and controls for domain difficulty or data construction are absent. This is load-bearing for the central claim, as non-comparable neuron sets or confounded transfer could explain the consistent degradation across models without supporting the domain-specificity conclusion.
Authors: We agree these details are essential for reproducibility and have expanded the Methods section in the revision to specify: H-neuron selection as the top 0.1% of FFN neurons ranked by activation difference on hallucinated vs. non-hallucinated examples; per-domain dataset sizes of 800 balanced examples; the transfer protocol (neurons identified independently on source-domain training split, then frozen for linear classifier training on target-domain data); and controls including perplexity-matched difficulty across domains and standardized prompt formats. These additions directly address potential confounds in neuron set comparability. revision: yes
-
Referee: [Results] Results: While p<0.001 is reported for the delta, the absence of variance across domains, number of trials, or ablations testing label consistency leaves open whether the drop is driven by labeling differences rather than neuron specificity. This directly affects the strength of the claim that H-neurons 'do not generalize'.
Authors: The p<0.001 derives from a paired t-test over the 30 model-domain transfer pairs. We have added the standard deviation of the AUROC drop (0.220 ± 0.052) and clarified that each experiment used 3 random seeds for classifier training. We also include a new ablation in Results using high-confidence labels (filtered by model output probability >0.8) which yields a similar degradation (delta=0.198), supporting that the effect is not driven solely by label noise. A full cross-domain human agreement study remains outside the current experimental scope. revision: partial
- Quantitative inter-domain label agreement metrics via human raters, as this would require new large-scale annotation not feasible within the revision
Circularity Check
No significant circularity in empirical cross-domain transfer results
full rationale
The paper reports direct experimental measurements of classifier AUROC (0.783 within-domain vs. 0.563 cross-domain) obtained by identifying H-neurons per domain, training linear probes, and evaluating transfer on held-out data across six domains and five models. These outcomes rest on observable performance metrics rather than any derivation chain, fitted parameters renamed as predictions, or self-referential definitions. No equations appear in the provided text, and the central claim does not reduce to its inputs by construction; the degradation is measured independently of the identification protocol.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption AUROC is a suitable metric for assessing binary hallucination prediction performance
Reference graph
Works this paper leans on
-
[1]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[2]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Marah Abdin, Jyoti Aneja, and 1 others. 2024. Phi-3 technical report: A highly capable language model locally on your phone. arXiv preprint arXiv:2404.14219
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Trenton Bricken, Adly Templeton, Joshua Batson, Brian Chen, Adam Jermyn, Tom Conerly, Nick Turner, Cem Anil, Carson Denison, Amanda Askell, Robert Lasenby, Yifan Wu, Shauna Kravec, Nicholas Schiefer, Tim Maxwell, Nicholas Joseph, Zac Hatfield-Dodds, Alex Tamkin, Karina Nguyen, and 6 others. 2023. Towards monosemanticity: Decomposing language models with d...
2023
-
[5]
Qianqian Chen and 1 others. 2024. FinBen : A holistic financial benchmark for large language models. Proceedings of NeurIPS Datasets and Benchmarks
2024
-
[6]
Canyu Cheng and 1 others. 2025. Can LLM -generated misinformation be detected? In Findings of EMNLP
2025
-
[7]
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. 2018. Think you have solved question answering? try ARC , the AI2 reasoning challenge. arXiv preprint arXiv:1803.05457
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[8]
Damai Dai, Li Dong, Yaru Hao, Zhifang Sui, Baobao Chang, and Furu Wei. 2022. Knowledge neurons in pretrained transformers. In Proceedings of ACL, pages 8493--8502
2022
-
[9]
Xuefeng Du, Chaowei Xue, Yifei Li, and Yixuan Li. 2024. HaloScope : Harnessing unlabeled LLM generations for hallucination detection. In Proceedings of NeurIPS
2024
-
[10]
Tibshirani
Bradley Efron and Robert J. Tibshirani. 1993. An Introduction to the Bootstrap. Chapman & Hall/CRC
1993
- [11]
-
[12]
Aaron Grattafiori, Abhimanyu Dubey, and 1 others. 2024. The Llama 3 herd of models. arXiv preprint arXiv:2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Ho, Christopher R \'e , Adam Chilton, Arvind Narayanan, Brandon Choi, Catalin Cui, Felix Daumler, Amit Deshpande, and 1 others
Neel Guha, Julian Nyarko, Daniel E. Ho, Christopher R \'e , Adam Chilton, Arvind Narayanan, Brandon Choi, Catalin Cui, Felix Daumler, Amit Deshpande, and 1 others. 2024. LegalBench : A collaboratively built benchmark for measuring legal reasoning in large language models. Proceedings of NeurIPS Datasets and Benchmarks
2024
-
[14]
Dan Hendrycks, Collin Burns, Steven Basart, Andrew Critch, Jerry Li, Dawn Song, and Jacob Steinhardt. 2021. Aligning AI with shared human values. In Proceedings of ICLR
2021
-
[15]
Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qianglong Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, and Ting Liu. 2023. A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions. arXiv preprint arXiv:2311.05232
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
Pranab Islam and 1 others. 2024. FinanceBench : A new benchmark for financial question answering. arXiv preprint
2024
-
[17]
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. 2023. Survey of hallucination in natural language generation. ACM Computing Surveys, 55(12):1--38
2023
-
[18]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, L \'e lio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timoth \'e e Lacroix, and William El Sayed. 2023. Mistral 7b. arXiv pr...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
Mandar Joshi, Eunsol Choi, Daniel Weld, and Luke Zettlemoyer. 2017. TriviaQA : A large scale distantly supervised challenge dataset for reading comprehension. In Proceedings of ACL, pages 1601--1611
2017
-
[20]
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. 2022. Large language models are zero-shot reasoners. In Proceedings of NeurIPS
2022
- [21]
-
[22]
Lorenz Kuhn, Yarin Gal, and Sebastian Farquhar. 2023. Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation. In Proceedings of ICLR
2023
- [23]
-
[24]
Tamera Lanham, Anna Chen, Ansh Radhakrishnan, Benoit Steiner, Carson Denison, Danny Hernandez, Dustin Li, Esin Durmus, Evan Hubinger, Jackson Kernion, Kamile Lukosiute, Karina Nguyen, Newton Cheng, Nicholas Joseph, Nicholas Schiefer, Oliver Rauber, Sam McCandlish, Catherine Olsson, Sandipan Kundu, and 7 others. 2023. Measuring faithfulness in chain-of-tho...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
Yifei Li, Xuefeng Du, and Yixuan Li. 2025 a . Truthful sparse verification for hallucination detection. arXiv preprint
2025
- [26]
-
[27]
Tom Lieberum, Senthooran Raber, Janos Kramar, and 1 others. 2024. Gemma scope: Open sparse autoencoders everywhere all at once on Gemma 2. arXiv preprint arXiv:2408.05147
work page internal anchor Pith review arXiv 2024
-
[28]
Pekka Malo, Ankur Sinha, Pekka Korhonen, Jyrki Wallenius, and Pyry Takala. 2014. Good debt or bad debt: Detecting semantic orientations in economic texts. Journal of the Association for Information Science and Technology, 65(4):782--796
2014
-
[29]
Potsawee Manakul, Adian Liusie, and Mark J. F. Gales. 2023. SelfCheckGPT : Zero-resource black-box hallucination detection for generative large language models. In Proceedings of EMNLP, pages 9004--9017
2023
-
[30]
Samuel Marks and Max Tegmark. 2024. The geometry of truth: Emergent linear structure in large language model representations of true/false datasets. arXiv preprint arXiv:2310.06824
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. 2022. Locating and editing factual associations in GPT . In Proceedings of NeurIPS
2022
-
[32]
Niels M \"u ndler, Jingxuan He, Slobodan Jenko, and Martin Vechev. 2024. Self-contradictory hallucinations of large language models: Evaluation, detection and mitigation. In Proceedings of ICLR
2024
- [33]
-
[34]
Vibhor Pal and 1 others. 2024. MedHalu : Hallucinations in responses to healthcare queries by large language models. arXiv preprint
2024
- [35]
-
[36]
Qwen Team . 2025. Qwen2.5 technical report. arXiv preprint arXiv:2412.15115
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [37]
-
[38]
Hangyu Su and 1 others. 2025. Value neurons: Discovering and locating value representations in language models. In Findings of EMNLP
2025
-
[39]
Yuchen Tian and 1 others. 2024. CodeHalu : Code hallucinations in LLMs driven by execution-based verification. arXiv preprint
2024
-
[40]
Miles Turpin, Julian Michael, Ethan Perez, and Samuel R. Bowman. 2024. Language models don't always say what they think: Unfaithful explanations in chain-of-thought prompting. Proceedings of NeurIPS
2024
-
[41]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. 2022. Chain-of-thought prompting elicits reasoning in large language models. In Proceedings of NeurIPS
2022
-
[42]
Zeping Yu and Sophia Ananiadou. 2024. Neuron-level knowledge attribution in large language models. In Proceedings of EMNLP, pages 3267--3280
2024
-
[43]
Anderson, Peter Henderson, and Daniel E
Lucia Zheng, Neel Guha, Brandon R. Anderson, Peter Henderson, and Daniel E. Ho. 2021. When does pretraining help? assessing self-supervised learning for law and the CaseHOLD dataset of 53,137+ legal holdings. In Proceedings of the International Conference on AI and Law
2021
-
[44]
Yaqin Zhou, Shangqing Liu, Jingkai Siow, Xiaoning Du, and Yang Liu. 2019. Devign: Effective vulnerability identification by learning comprehensive program semantics via graph neural networks. In Proceedings of NeurIPS
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.