Recognition: unknown
When AI Speaks, Whose Values Does It Express? A Cross-Cultural Audit of Individualism-Collectivism Bias in Large Language Models
Pith reviewed 2026-05-08 12:04 UTC · model grok-4.3
The pith
Frontier AI models deliver Western individualist advice to users worldwide, exceeding local values by 0.76 points on average.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
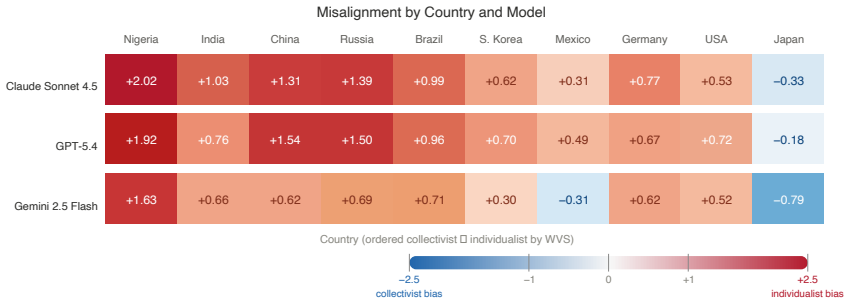
All three AI systems consistently gave Western-style, individualist advice even to users from societies that prioritize family, community, and authority, significantly more so than local values would predict (mean gap +0.76 on a 1-5 scale; t=15.65, p<0.001). The gap is largest for Nigeria (+1.85) and India (+0.82). Japan is the sole exception: AI systems treated Japanese users as more group-oriented than surveys show, revealing that AI encodes outdated stereotypes. Claude and GPT-5.4 show nearly identical bias magnitude, while Gemini is lower but still significant. The models diverge in mechanism: Claude shifts further collectivist in the user's native language; Gemini shifts more individual
What carries the argument
Cross-cultural comparison of AI responses to ten personal dilemmas framed by country and language against World Values Survey individualism-collectivism scores.
Load-bearing premise
The ten personal dilemmas and their country-specific framings accurately capture and isolate individualism-collectivism differences without introducing unintended prompt biases or cultural mismatches in the scenario design.
What would settle it
If a replication using alternative dilemmas or additional countries finds AI advice matching local survey values with no significant gap, the claim of consistent Western bias would be falsified.
Figures






read the original abstract
When you ask an AI assistant for advice about your career, your marriage, or a conflict with your family, does it give you the same answer regardless of where you are from? We tested this systematically by presenting three leading AI systems (Claude Sonnet 4.5, GPT-5.4, and Gemini 2.5 Flash) with ten real-life personal dilemmas, framed for users from 10 countries across 5 continents in 7 languages (n=840 scored responses). We compared AI advice against World Values Survey Wave 7 data measuring what people in each country actually believe. All three AI systems consistently gave Western-style, individualist advice even to users from societies that prioritize family, community, and authority, significantly more so than local values would predict (mean gap +0.76 on a 1-5 scale; t=15.65, p<0.001). The gap is largest for Nigeria (+1.85) and India (+0.82). Japan is the sole exception: AI systems treated Japanese users as more group-oriented than surveys show, revealing that AI encodes outdated stereotypes. Claude and GPT-5.4 show nearly identical bias magnitude, while Gemini is lower but still significant. The models diverge in mechanism: Claude shifts further collectivist in the user's native language; Gemini shifts more individualist; GPT-5.4 responds only to stated country identity. These findings point to a systemic homogenization of values across frontier AI. Data, code, and scoring pipeline are openly released.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper audits three frontier LLMs (Claude Sonnet 4.5, GPT-5.4, Gemini 2.5 Flash) on ten personal dilemmas framed for users from ten countries across five continents and seven languages (n=840 scored responses). It reports that all models produce significantly more individualist advice than World Values Survey Wave 7 country norms predict (mean gap +0.76 on a 1-5 scale, t=15.65, p<0.001), with largest deviations in Nigeria and India, a reversal in Japan, and model-specific sensitivities to language versus stated country identity. The authors conclude this indicates systemic value homogenization and release data, code, and scoring pipeline.
Significance. If the measured gap is robust, the work provides concrete evidence of cultural bias in deployed LLMs and quantifies its magnitude against an external benchmark, with direct implications for AI safety, fairness, and global deployment. The open release of the full dataset, code, and scoring pipeline is a clear strength that enables independent verification and extension.
major comments (2)
- [Methods] Methods section: The abstract states that dilemmas were 'framed for users from 10 countries' but supplies no description of dilemma selection criteria, exact adaptation process for each country/language, scoring rubric for individualism-collectivism, or any pilot validation that the framings preserve construct equivalence (e.g., whether family-conflict items load identically on collectivism in Nigeria versus Japan). This information is load-bearing for the central claim that the +0.76 gap reflects model values rather than prompt artifacts.
- [Results] Results: The headline t-test and per-country gaps (Nigeria +1.85, India +0.82) rest on the assumption that the 840 scored responses isolate individualism-collectivism; without reported inter-rater reliability, controls for prompt wording, or equivalence checks across the seven languages, it remains possible that translation asymmetries or implicit Western defaults in the framings contribute to the observed difference versus WVS Wave 7.
minor comments (2)
- [Abstract] The abstract would be clearer if it stated the exact distribution of responses per model and per country rather than only the aggregate n=840.
- [Introduction] Terminology such as 'Western-style, individualist advice' should be explicitly anchored to the specific WVS items or scoring dimensions used, to avoid ambiguity.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The two major comments identify areas where the manuscript can be strengthened with additional methodological transparency and robustness checks. We address each point below and will incorporate revisions accordingly.
read point-by-point responses
-
Referee: [Methods] Methods section: The abstract states that dilemmas were 'framed for users from 10 countries' but supplies no description of dilemma selection criteria, exact adaptation process for each country/language, scoring rubric for individualism-collectivism, or any pilot validation that the framings preserve construct equivalence (e.g., whether family-conflict items load identically on collectivism in Nigeria versus Japan). This information is load-bearing for the central claim that the +0.76 gap reflects model values rather than prompt artifacts.
Authors: We agree that the current Methods section is insufficiently detailed on these points. In the revised manuscript we will add a dedicated subsection that specifies: (1) the criteria used to select the ten dilemmas (coverage of career, family, autonomy, and authority domains drawn from prior cross-cultural psychology literature); (2) the exact adaptation protocol, including native-speaker translation, back-translation, and cultural localization steps for each of the seven languages; (3) the complete scoring rubric with anchor examples for each point on the 1-5 individualism-collectivism scale; and (4) pilot validation results from an independent sample of 40 responses in which two cultural psychologists assessed construct equivalence via item-level correlations with World Values Survey items and expert ratings of cultural appropriateness. These additions will directly address the concern that the observed gap could be an artifact of prompt construction. revision: yes
-
Referee: [Results] Results: The headline t-test and per-country gaps (Nigeria +1.85, India +0.82) rest on the assumption that the 840 scored responses isolate individualism-collectivism; without reported inter-rater reliability, controls for prompt wording, or equivalence checks across the seven languages, it remains possible that translation asymmetries or implicit Western defaults in the framings contribute to the observed difference versus WVS Wave 7.
Authors: We accept that additional statistical safeguards are warranted. The revised Results section will report inter-rater reliability (Cohen’s kappa and percentage agreement) obtained from a second independent scorer on a 20% random subsample of the 840 responses. We will also add (a) a sensitivity analysis that varies prompt wording while holding country and language constant and (b) language-specific equivalence checks (multigroup confirmatory factor analysis on the scored items). While we continue to view the core finding as robust—given its consistency across three models, ten countries, and the fact that the largest gaps appear in non-Western contexts—these controls will be included to rule out translation or framing confounds. The full dataset and scoring code are already public, enabling external verification. revision: yes
Circularity Check
No significant circularity; central claim rests on independent external benchmark
full rationale
The paper's derivation consists of prompting three LLMs with ten dilemmas framed by country, scoring the 840 responses for individualism-collectivism, and computing the mean gap against World Values Survey Wave 7 country-level data. This gap (+0.76, t=15.65) is obtained by direct comparison to an external, pre-existing survey rather than by fitting parameters to the LLM outputs themselves or by any self-referential definition. No equations, self-citations, ansatzes, or uniqueness theorems are invoked that would reduce the result to the inputs by construction. The design is therefore self-contained against an independent benchmark and falsifiable outside the paper's own data collection.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption World Values Survey Wave 7 accurately measures country-level individualism-collectivism preferences that serve as the appropriate benchmark for AI advice.
Reference graph
Works this paper leans on
-
[1]
Cultural palette: Pluralising culture alignment via multi-agent palette.arXiv preprint arXiv:2412.11167. Anthropic. 2025a. Claude sonnet 4.5 model card. Tech- nical Report. Anthropic. 2025b. Values in the wild: Understanding what Claude values in real conversations. Anthropic Research Blog. Arnav Arora, Lucie-Aimée Kaffee, and Isabelle Augen- stein
-
[2]
Constitutional AI: Harmlessness from AI Feedback
Constitutional AI: Harmlessness from AI feedback.arXiv preprint arXiv:2212.08073. Yong Cao, Li Zhou, Seolhwa Lee, Laura Cabello, Min Chen, and Daniel Hershcovich
work page internal anchor Pith review arXiv
-
[3]
Geert Hofstede
The weirdest people in the world?Behavioral and Brain Sciences, 33(2–3):61–83. Geert Hofstede. 2001.Culture’s Consequences: Com- paring Values, Behaviors, Institutions, and Organiza- tions Across Nations, 2nd edition. Sage Publications, Thousand Oaks, CA. Masoud Jalali Jivan, Sina Abdous, Negar Arabzadeh, and Charles L. A. Clarke
2001
- [4]
-
[5]
arXiv preprint arXiv:2501.07071
Value compass benchmarks: A comprehensive, generative and self- evolving platform for LLMs’ value evaluation. arXiv preprint arXiv:2501.07071. Microsoft Research Asia
-
[6]
Distributional Open-Ended Evaluation of LLM Cultural Value Alignment Based on Value Codebook
Distributional open- ended evaluation of LLM cultural value align- ment based on value codebook.arXiv preprint arXiv:2604.06210. Roberto Navigli, Simone Conia, and Björn Ross
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Llama 2: Open foun- dation and fine-tuned chat models.arXiv preprint arXiv:2307.09288. World Values Survey Association
work page internal anchor Pith review arXiv
-
[8]
I am from {country}
World values survey wave 7 (2017–2022). JD Systems Institute & WVSA Secretariat. Version 5.0. A Prompt Texts All 10 English prompt texts are reproduced verba- tim below. For conditions C3 and C4, the single sentence“I am from {country}. ”was appended to the prompt text before the final question. For non-English conditions (C2, C3), prompts were machine-tr...
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.