Recognition: unknown
StarCLR: Contrastive Learning Representation for Astronomical Light Curves
Pith reviewed 2026-05-08 01:27 UTC · model grok-4.3
The pith
A contrastive pretraining method on TESS light curves learns temporal features from overlapping segments and improves variable star classification on TESS, ZTF, and Gaia surveys.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
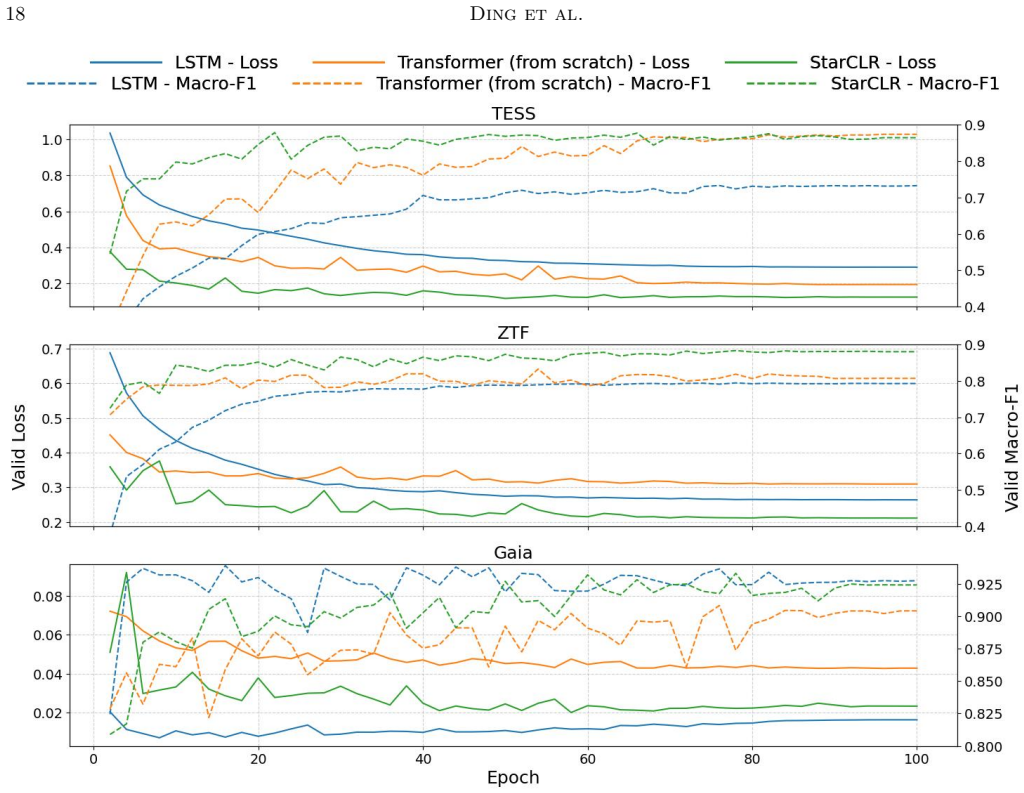
By constructing positive pairs from partially overlapping sub-sequences of light curves, StarCLR learns temporal representations during pretraining on TESS that, after fine-tuning, raise classification accuracy on TESS (18 classes), ZTF (11 classes), and Gaia (24 classes) relative to LSTM and Transformer models trained from scratch, with the clearest advantage appearing on the sparsely sampled ZTF data.
What carries the argument
StarCLR contrastive pretraining framework that builds positive pairs from partially overlapping light-curve sub-sequences to train temporal representations without labels.
If this is right
- StarCLR outperforms LSTM and Transformer baselines on TESS and ZTF classification, with the largest margin on sparsely sampled ZTF light curves.
- On Gaia, which has a broader class space, the pretrained backbone contributes less because performance depends more on astrophysical features.
- Ablation studies confirm that embedding design, pooling strategy, and pretraining settings all affect how much temporal information the representations retain.
- The approach demonstrates that contrastive signals from overlapping segments can transfer across surveys without hand-crafted features.
Where Pith is reading between the lines
- The same overlapping-segment contrastive recipe could be applied to other unevenly sampled time series such as exoplanet transit data or solar flare records.
- Standardized cross-survey benchmarks would make it easier to measure how much the pretrained backbone actually reduces the labeled-data requirement.
- If the learned representations prove stable under changes in cadence and filter, they could serve as a reusable backbone for new surveys that lack large labeled sets.
Load-bearing premise
That positive pairs formed from partially overlapping sub-sequences of light curves supply enough training signal for temporal representations to generalize across surveys that differ in sampling rate, noise properties, and class definitions, without any astrophysical priors or explicit domain adaptation.
What would settle it
A head-to-head experiment on the ZTF variable-star task in which a from-scratch LSTM or Transformer reaches macro-F1 scores equal to or higher than the fine-tuned StarCLR model while using identical training and test splits.
Figures











read the original abstract
With the rapid development of time-domain surveys, the availability of massive light curve data offers new opportunities for studying stellar evolution and variable star classification, while simultaneously posing challenges for feature extraction and modeling. We present StarCLR, a contrastive pretraining framework for large-scale light curves. By constructing positive pairs from partially overlapping sub-sequences, StarCLR encourages the model to learn temporal representations. We pretrain StarCLR on the TESS dataset and fine-tune it for variable star classification on three surveys with distinct observational characteristics, namely TESS (18 types), ZTF (11 types), and Gaia (24 types). StarCLR achieves macro-F1 scores of 84.35%, 87.82%, and 92.73%, and micro-F1 scores of 94.46%, 92.83%, and 99.49%, respectively. Compared with LSTM and Transformer trained from scratch, StarCLR performs better on TESS and ZTF, with the largest gains on sparsely sampled ZTF light curves, demonstrating promising generalization. For Gaia, which involves a broader class space, the evaluation is not directly comparable, and performance is likely influenced by astrophysical features, resulting in a more limited contribution from the pretrained backbone. Systematic ablations on embedding design, pooling strategy, and pretraining settings further indicate that the pretrained representations provide performance gains by capturing informative temporal characteristics of light curves. Looking ahead, with standardized datasets and more diverse labeling schemes, the generalization ability of StarCLR can be further enhanced.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces StarCLR, a contrastive pretraining framework for astronomical light curves. Positive pairs are formed from partially overlapping sub-sequences of TESS data to learn temporal representations; the pretrained encoder is then fine-tuned for variable-star classification on TESS (18 classes), ZTF (11 classes), and Gaia (24 classes). It reports macro-F1 scores of 84.35%, 87.82%, and 92.73% and micro-F1 scores of 94.46%, 92.83%, and 99.49% respectively, outperforming LSTM and Transformer models trained from scratch, with the largest gains on sparsely sampled ZTF light curves. Systematic ablations on embedding design, pooling, and pretraining settings are provided to support that the gains arise from informative temporal features.
Significance. If the central empirical claims hold, the work provides concrete evidence that contrastive pretraining on overlapping light-curve windows can yield transferable representations across surveys with differing cadences and class spaces. The reported F1 margins (especially on ZTF) and the accompanying ablations on embedding/pooling/pretraining choices constitute a useful empirical demonstration that self-supervised methods can leverage large unlabeled time-domain datasets, which is of practical value for upcoming surveys.
major comments (2)
- [Section 3] Section 3 (pretraining framework): The headline claim that contrastive pretraining on TESS-derived overlapping sub-sequences produces survey-agnostic temporal features that transfer to ZTF rests on the assumption that positive-pair construction alone suffices to factor out cadence and gap differences. TESS provides near-continuous high-cadence segments while ZTF is irregular and gapped; without explicit domain-shift diagnostics (e.g., cadence-augmented pretraining or embedding-distance analysis between surveys), it remains possible that the encoder partially memorizes TESS-specific autocorrelation statistics. This assumption is load-bearing for interpreting the largest reported gains on ZTF.
- [Section 4] Section 4 (experiments and results): The performance tables do not report statistical error bars or significance tests on the F1 improvements over the scratch-trained baselines. Given that these margins are central to the generalization narrative, the absence of uncertainty quantification weakens the ability to judge whether the gains are robust rather than within run-to-run variability.
minor comments (2)
- [Abstract and Section 4] The abstract and results section should explicitly cross-reference the specific tables or figures that present the systematic ablations on embedding dimension, pooling strategy, and pretraining settings.
- [Section 4] Additional implementation details for the LSTM and Transformer baselines (exact hyperparameter search ranges, layer counts, and training schedules) would improve reproducibility of the reported comparisons.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments, which highlight important aspects of our pretraining framework and experimental evaluation. We address each major comment below and will revise the manuscript to incorporate additional analysis and statistical reporting as outlined.
read point-by-point responses
-
Referee: [Section 3] Section 3 (pretraining framework): The headline claim that contrastive pretraining on TESS-derived overlapping sub-sequences produces survey-agnostic temporal features that transfer to ZTF rests on the assumption that positive-pair construction alone suffices to factor out cadence and gap differences. TESS provides near-continuous high-cadence segments while ZTF is irregular and gapped; without explicit domain-shift diagnostics (e.g., cadence-augmented pretraining or embedding-distance analysis between surveys), it remains possible that the encoder partially memorizes TESS-specific autocorrelation statistics. This assumption is load-bearing for interpreting the largest reported gains on ZTF.
Authors: We acknowledge the importance of demonstrating that the learned representations are not merely capturing TESS-specific autocorrelation. The systematic ablations on embedding design, pooling strategy, and pretraining settings (Section 4) show that performance gains arise specifically from informative temporal features of light curves. The fact that the largest improvements occur on ZTF—which has markedly different cadence and gap patterns—further supports that the contrastive objective on overlapping subsequences promotes transferable temporal structure rather than survey-specific memorization. To directly address domain shift, we will add an embedding-distance analysis comparing TESS and ZTF representations in the revised manuscript. revision: yes
-
Referee: [Section 4] Section 4 (experiments and results): The performance tables do not report statistical error bars or significance tests on the F1 improvements over the scratch-trained baselines. Given that these margins are central to the generalization narrative, the absence of uncertainty quantification weakens the ability to judge whether the gains are robust rather than within run-to-run variability.
Authors: We agree that uncertainty quantification is necessary to establish the robustness of the reported F1 improvements. In the revised manuscript we will report mean and standard deviation of macro- and micro-F1 scores across multiple independent training runs (five random seeds) for both StarCLR and the scratch-trained baselines. We will also include results of paired statistical significance tests on the observed differences. revision: yes
Circularity Check
No circularity: empirical claims rest on held-out cross-survey benchmarks, not self-referential definitions or fitted inputs.
full rationale
The paper defines its contrastive objective by construction (positive pairs from overlapping subsequences) as an explicit modeling choice, then evaluates via direct F1 comparisons to scratch-trained LSTM/Transformer baselines on separate TESS/ZTF/Gaia test sets. No equations, ablations, or results reduce by the paper's own definitions to quantities already fixed by the inputs or by self-citation chains. The method is self-contained against external benchmarks; the largest reported gains on ZTF are presented as empirical outcomes, not forced by the pretraining construction itself.
Axiom & Free-Parameter Ledger
free parameters (2)
- contrastive temperature
- embedding dimension and pooling strategy
axioms (1)
- domain assumption Partially overlapping sub-sequences of the same light curve share the same underlying stellar variability process
Reference graph
Works this paper leans on
-
[1]
2024, in Proceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating
Ansel, J., Yang, E., He, H., et al. 2024, in Proceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating
2024
-
[2]
Systems, Volume 2, ASPLOS ’24 (New York, NY, USA: Association for Computing Machinery), 929–947, doi: 10.1145/3620665.3640366 Astropy Collaboration, Robitaille, T. P., Tollerud, E. J., et al. 2013, A&A, 558, A33, doi: 10.1051/0004-6361/201322068 28Ding et al. Astropy Collaboration, Price-Whelan, A. M., Sip˝ ocz, B. M., et al. 2018, AJ, 156, 123, doi: 10.3...
-
[3]
Barbara, N. H., Bedding, T. R., Fulcher, B. D., Murphy, S. J., & Van Reeth, T. 2022, MNRAS, 514, 2793, doi: 10.1093/mnras/stac1515
-
[4]
Basri, G., Walkowicz, L. M., Batalha, N., et al. 2011, AJ, 141, 20, doi: 10.1088/0004-6256/141/1/20
-
[5]
Bellm, E. C., Kulkarni, S. R., Graham, M. J., et al. 2019, PASP, 131, 018002, doi: 10.1088/1538-3873/aaecbe
-
[6]
Kepler Planet-Detection Mission: Introduction and First Results.Science2010,327, 977
Borucki, W. J., Koch, D., Basri, G., et al. 2010, Science, 327, 977, doi: 10.1126/science.1185402
-
[7]
Breiman, L. 2001, Machine Learning, 45, 5, doi: 10.1023/A:1010933404324
-
[8]
A Simple Framework for Contrastive Learning of Visual Representations
Chen, T., Kornblith, S., Norouzi, M., & Hinton, G. 2020a, arXiv e-prints, arXiv:2002.05709, doi: 10.48550/arXiv.2002.05709
work page internal anchor Pith review doi:10.48550/arxiv.2002.05709 2002
-
[9]
Chen, X., Wang, S., Deng, L., et al. 2020b, ApJS, 249, 18, doi: 10.3847/1538-4365/ab9cae
-
[10]
Christy, C. T., Jayasinghe, T., Stanek, K. Z., et al. 2023, MNRAS, 519, 5271, doi: 10.1093/mnras/stac3801
-
[11]
Cui, K., Armstrong, D. J., & Feng, F. 2024, ApJS, 274, 29, doi: 10.3847/1538-4365/ad62fd
-
[12]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Devlin, J., Chang, M.-W., Lee, K., & Toutanova, K. 2018, arXiv e-prints, arXiv:1810.04805, doi: 10.48550/arXiv.1810.04805
-
[13]
2025, arXiv e-prints, arXiv:2502.02717, doi: 10.48550/arXiv.2502.02717 —
Donoso-Oliva, C., Becker, I., Protopapas, P., et al. 2025, arXiv e-prints, arXiv:2502.02717, doi: 10.48550/arXiv.2502.02717 —. 2023, A&A, 670, A54, doi: 10.1051/0004-6361/202243928
-
[14]
1996, in Proceedings of the Second International Conference on Knowledge Discovery and Data Mining, KDD’96 (AAAI Press), 226–231
Ester, M., Kriegel, H.-P., Sander, J., & Xu, X. 1996, in Proceedings of the Second International Conference on Knowledge Discovery and Data Mining, KDD’96 (AAAI Press), 226–231
1996
-
[15]
2023, ApJS, 268, 4, doi: 10.3847/1538-4365/acdee5
Fetherolf, T., Pepper, J., Simpson, E., et al. 2023, ApJS, 268, 4, doi: 10.3847/1538-4365/acdee5
-
[16]
Fulcher, B. D., & Jones, N. S. 2017, Cell systems, 5, 527 Gaia Collaboration, Vallenari, A., Brown, A. G. A., et al. 2023, A&A, 674, A1, doi: 10.1051/0004-6361/202243940
-
[17]
Classification of Periodic Variable Stars from TESS
Gao, X., Chen, X., Wang, S., & Liu, J. 2025, ApJS, 276, 57, doi: 10.3847/1538-4365/ad9dd6
-
[18]
2022, Accelerate: Training and inference at scale made simple, efficient and adaptable., https://github.com/huggingface/accelerate
Gugger, S., Debut, L., Wolf, T., et al. 2022, Accelerate: Training and inference at scale made simple, efficient and adaptable., https://github.com/huggingface/accelerate
2022
-
[19]
Harris, C. R., Millman, K. J., van der Walt, S. J., et al. 2020, Nature, 585, 357–362, doi: 10.1038/s41586-020-2649-2
-
[20]
Huang, K.-W., & Koposov, S. E. 2022, MNRAS, 510, 3575, doi: 10.1093/mnras/stab3654
-
[21]
Hunter, J. D. 2007, Computing in Science & Engineering, 9, 90, doi: 10.1109/MCSE.2007.55
-
[22]
The ASAS-SN catalogue of variable stars – II. Uniform classification of 412 000 known variables
Jayasinghe, T., Stanek, K. Z., Kochanek, C. S., et al. 2019, MNRAS, 486, 1907, doi: 10.1093/mnras/stz844
-
[23]
Kochanek, C. S., Shappee, B. J., Stanek, K. Z., et al. 2017, PASP, 129, 104502, doi: 10.1088/1538-3873/aa80d9
-
[24]
Lhoest, Q., Villanova del Moral, A., Jernite, Y., et al. 2021, in Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing: System Demonstrations (Online and Punta Cana, Dominican Republic: Association for Computational Linguistics), 175–184. https://arxiv.org/abs/2109.02846
-
[25]
Lomb, N. R. 1976, Ap&SS, 39, 447, doi: 10.1007/BF00648343
-
[26]
Publications of the Astronomical Society of the Pacific , author =
Masci, F. J., Laher, R. R., Rusholme, B., et al. 2019, PASP, 131, 018003, doi: 10.1088/1538-3873/aae8ac
work page internal anchor Pith review doi:10.1088/1538-3873/aae8ac 2019
-
[27]
UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction
McInnes, L., Healy, J., & Melville, J. 2020, UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction. https://arxiv.org/abs/1802.03426
work page internal anchor Pith review arXiv 2020
-
[28]
McKinney, W. 2010, SciPy 2010, doi: 10.25080/Majora-92bf1922-00a
-
[29]
J., & Peel, D
McLachlan, G. J., & Peel, D. 2000, Finite mixture models (John Wiley & Sons)
2000
-
[30]
2023, arXiv e-prints, arXiv:2308.06404, doi: 10.48550/arXiv.2308.06404
Moreno-Cartagena, D., Cabrera-Vives, G., Protopapas, P., et al. 2023, arXiv e-prints, arXiv:2308.06404, doi: 10.48550/arXiv.2308.06404
-
[31]
2019, OpenAI blog, 1, 9
Radford, A., Wu, J., Child, R., et al. 2019, OpenAI blog, 1, 9
2019
-
[32]
Ricker, G. R., Winn, J. N., Vanderspek, R., et al. 2015, Journal of Astronomical Telescopes, Instruments, and Systems, 1, 014003, doi: 10.1117/1.JATIS.1.1.014003
-
[33]
2023, A&A, 674, A14, doi: 10.1051/0004-6361/202245591
Rimoldini, L., Holl, B., Gavras, P., et al. 2023, A&A, 674, A14, doi: 10.1051/0004-6361/202245591
-
[34]
Rizhko, M., & Bloom, J. S. 2024, arXiv e-prints, arXiv:2411.08842, doi: 10.48550/arXiv.2411.08842
-
[35]
Scargle, J. D. 1982, ApJ, 263, 835, doi: 10.1086/160554
-
[36]
2025, PASP, 137, 044503, doi: 10.1088/1538-3873/adc5a2
Shan, Y., Chen, J., Zhang, Z., et al. 2025, PASP, 137, 044503, doi: 10.1088/1538-3873/adc5a2
-
[37]
Stassun, K. G., Oelkers, R. J., Paegert, M., et al. 2019, AJ, 158, 138, doi: 10.3847/1538-3881/ab3467
-
[38]
K., Soszynski, I., & Poleski, R
Udalski, A., Szymanski, M. K., Soszynski, I., & Poleski, R. 2008, AcA, 58, 69, doi: 10.48550/arXiv.0807.3884
-
[39]
OGLE-IV: Fourth Phase of the Optical Gravitational Lensing Experiment
Udalski, A., Szyma´ nski, M. K., & Szyma´ nski, G. 2015, AcA, 65, 1, doi: 10.48550/arXiv.1504.05966
-
[40]
Vaswani, A., Shazeer, N., Parmar, N., et al. 2023, Attention Is All You Need. https://arxiv.org/abs/1706.03762
work page internal anchor Pith review arXiv 2023
-
[41]
The Astrophysical Journal , author =
Wang, S., & Chen, X. 2019, ApJ, 877, 116, doi: 10.3847/1538-4357/ab1c61 StarCLR: Contrastive Learning Representation for Astronomical Light Curves29
-
[42]
2020, in Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations (Online: Association for Computational Linguistics), 38–45
Wolf, T., Debut, L., Sanh, V., et al. 2020, in Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations (Online: Association for Computational Linguistics), 38–45. https://www.aclweb.org/anthology/2020.emnlp-demos.6
2020
-
[43]
2022, TS2Vec: Towards Universal Representation of Time Series
Yue, Z., Wang, Y., Duan, J., et al. 2022, TS2Vec: Towards Universal Representation of Time Series. https://arxiv.org/abs/2106.10466
-
[44]
2025, arXiv e-prints, arXiv:2504.20290, doi: 10.48550/arXiv.2504.20290 30Ding et al
Zuo, X., Tao, Y., Huang, Y., et al. 2025, arXiv e-prints, arXiv:2504.20290, doi: 10.48550/arXiv.2504.20290 30Ding et al. APPENDIX A.SUPPORTING FIGURES AND TABLES Tables A1 present the detailed per-class classification performance of StarCLR on the TESS, ZTF, and Gaia test sets, including uncertainty estimates from multiple runs. T able A1. Per-class class...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.