Recognition: unknown
Claw-Eval-Live: A Live Agent Benchmark for Evolving Real-World Workflows
Pith reviewed 2026-05-07 05:48 UTC · model grok-4.3
The pith
A live benchmark reveals that even the best LLM agents complete only two-thirds of evolving real-world workflow tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Claw-Eval-Live shows reliable workflow automation remains far from solved: the leading model passes only 66.7 percent of tasks and no model reaches 70 percent. Failures are structured by task family and execution surface, with HR, management, and multi-system business workflows as persistent bottlenecks and local workspace repair comparatively easier but unsaturated. Leaderboard rank alone is insufficient because models with similar pass rates can diverge in overall completion, and task-level discrimination concentrates in a middle band of tasks.
What carries the argument
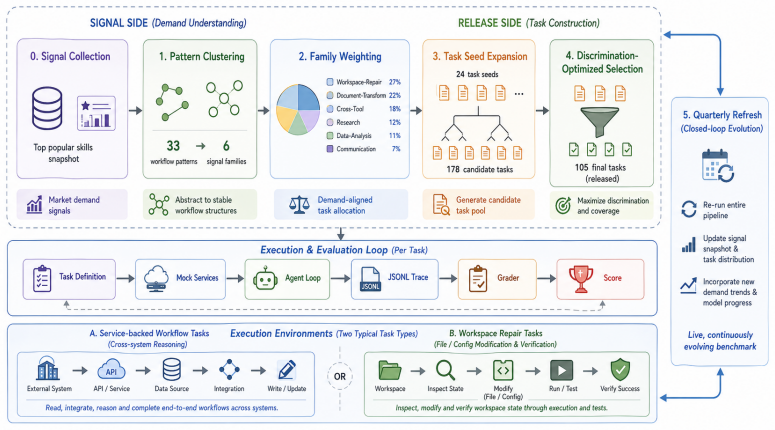
Claw-Eval-Live, which separates a refreshable signal layer updated from public workflow-demand signals such as ClawHub Top-500 skills from a reproducible time-stamped release snapshot materialized with fixed fixtures, services, workspaces, and graders.
If this is right
- Agents must make targeted gains on HR, management, and multi-system coordination tasks to approach reliable automation.
- Evaluation should record execution traces, audit logs, and workspace artifacts rather than grading final responses alone.
- Live benchmarks refreshed from external demand signals can track whether progress keeps pace with changing workflows.
- Models with similar overall pass rates can still differ substantially in completion quality and error patterns.
- Discrimination among models concentrates in a middle band of tasks, so benchmarks gain power by focusing there.
Where Pith is reading between the lines
- Adding dynamic service mutations between releases would test whether agents adapt when external systems change without notice.
- The same live-refresh structure could be applied to other agent domains such as data pipelines or code maintenance to keep evaluations current.
- Correlating failure modes with task-family statistics could guide targeted data collection for training on persistent bottlenecks.
- Releasing the full execution traces publicly would let the community develop finer-grained diagnostics beyond binary pass rates.
Load-bearing premise
Tasks constructed from public workflow-demand signals and materialized with fixed fixtures, services, and workspaces accurately represent evolving real-world workflow demands, and the mixed deterministic checks plus structured LLM judging reliably identify successful execution.
What would settle it
A new model that passes more than 90 percent of tasks across two successive releases while human raters judge the task set as unrepresentative of common workplace demands would falsify the claim that reliable automation is far from solved.
Figures





read the original abstract
LLM agents are expected to complete end-to-end units of work across software tools, business services, and local workspaces. Yet many agent benchmarks freeze a curated task set at release time and grade mainly the final response, making it difficult to evaluate agents against evolving workflow demand or verify whether a task was executed. We introduce Claw-Eval-Live, a live benchmark for workflow agents that separates a refreshable signal layer, updated across releases from public workflow-demand signals, from a reproducible, time-stamped release snapshot. Each release is constructed from public workflow-demand signals, with ClawHub Top-500 skills used in the current release, and materialized as controlled tasks with fixed fixtures, services, workspaces, and graders. For grading, Claw-Eval-Live records execution traces, audit logs, service state, and post-run workspace artifacts, using deterministic checks when evidence is sufficient and structured LLM judging only for semantic dimensions. The release contains 105 tasks spanning controlled business services and local workspace repair, and evaluates 13 frontier models under a shared public pass rule. Experiments reveal that reliable workflow automation remains far from solved: the leading model passes only 66.7% of tasks and no model reaches 70%. Failures are structured by task family and execution surface, with HR, management, and multi-system business workflows as persistent bottlenecks and local workspace repair comparatively easier but unsaturated. Leaderboard rank alone is insufficient because models with similar pass rates can diverge in overall completion, and task-level discrimination concentrates in a middle band of tasks. Claw-Eval-Live suggests that workflow-agent evaluation should be grounded twice, in fresh external demand and in verifiable agent action.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Claw-Eval-Live, a live benchmark for LLM workflow agents that decouples a refreshable public signal layer (ClawHub Top-500 skills) from a time-stamped, reproducible snapshot. It materializes 105 tasks across controlled business services and local workspaces, records execution traces and artifacts, and applies mixed deterministic/LLM grading. Evaluation of 13 frontier models shows a maximum pass rate of 66.7% with none exceeding 70%, structured failures concentrated in HR, management, and multi-system workflows, and argues that leaderboard rank is insufficient while evaluation must be grounded in fresh external demand and verifiable actions.
Significance. If the task construction and grading validity hold, the results would establish that reliable end-to-end workflow automation remains unsolved for frontier models, with clear bottlenecks in complex business processes. The live, trace-based design with mixed grading offers a concrete advance over static final-answer benchmarks and could steer the field toward more reproducible and adaptive evaluation practices.
major comments (3)
- [§3] §3 (Task Construction and Materialization): The central performance claims (66.7% ceiling, family-level bottlenecks) depend on the 105 tasks accurately proxying evolving real-world workflow demand. The manuscript freezes public signals into tasks with fixed fixtures, services, and workspaces for reproducibility, but provides no validation study, exclusion criteria, or comparison against live deployment variability, API drift, or cross-system noise. This assumption is load-bearing for interpreting the reported pass rates and the conclusion that automation is far from solved.
- [§4.2] §4.2 (Grading and Labeling): Grading combines deterministic checks with structured LLM judging for semantic dimensions, yet the manuscript reports no human agreement rates, judge calibration data, inter-rater reliability, or error analysis on the LLM component. Absent these, label noise could systematically inflate or deflate pass rates and distort the identified bottlenecks in HR and management families.
- [§5] §5 (Experimental Results): The key quantitative claims (leading model at 66.7%, no model above 70%, task-family discrimination) are presented without statistical error bars, confidence intervals, or sensitivity analysis over the 105-task set. This omission weakens assessment of whether observed differences between models or the middle-band task discrimination are robust.
minor comments (2)
- [Abstract / §3] The abstract and §3 refer to 'ClawHub Top-500 skills' without stating the precise selection, filtering, or refresh protocol; a short subsection or appendix table listing the skill categories and update cadence would improve reproducibility.
- [§5] Figure or table showing per-model completion metrics beyond raw pass rate (to support the claim that similar pass rates can diverge in overall completion) is referenced but not described in detail; ensure the relevant table is clearly captioned and cross-referenced.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and outline revisions to improve the manuscript's rigor.
read point-by-point responses
-
Referee: [§3] §3 (Task Construction and Materialization): The central performance claims (66.7% ceiling, family-level bottlenecks) depend on the 105 tasks accurately proxying evolving real-world workflow demand. The manuscript freezes public signals into tasks with fixed fixtures, services, and workspaces for reproducibility, but provides no validation study, exclusion criteria, or comparison against live deployment variability, API drift, or cross-system noise. This assumption is load-bearing for interpreting the reported pass rates and the conclusion that automation is far from solved.
Authors: We appreciate the emphasis on validating task representativeness. The benchmark design sources tasks from the refreshable public ClawHub Top-500 signals and materializes them into fixed, time-stamped snapshots precisely to support reproducible evaluation of verifiable actions. Task selection followed the public skill ranking with instantiation rules that ensure deterministic fixtures and observable outcomes. While a dedicated live-deployment comparison study was not performed (as it would conflict with the reproducibility goal), we will revise §3 to add explicit exclusion criteria (e.g., skills lacking clear post-execution artifacts or requiring unavailable external accounts) and a new limitations paragraph discussing API drift and cross-system variability. This preserves the core contribution while clarifying the proxy nature of the 105-task set. revision: partial
-
Referee: [§4.2] §4.2 (Grading and Labeling): Grading combines deterministic checks with structured LLM judging for semantic dimensions, yet the manuscript reports no human agreement rates, judge calibration data, inter-rater reliability, or error analysis on the LLM component. Absent these, label noise could systematically inflate or deflate pass rates and distort the identified bottlenecks in HR and management families.
Authors: We agree that quantitative validation of the LLM judging component strengthens confidence in the labels. The manuscript already restricts LLM judging to semantic dimensions only after deterministic checks are exhausted, using fixed structured prompts. To directly address the concern, we will add to §4.2 a human agreement study on a stratified sample of 25 tasks (including HR and management families), reporting inter-rater reliability (Cohen's kappa) between two human annotators and the LLM judge, plus calibration notes and a brief error analysis of disagreements. These results will be included in the revised version. revision: yes
-
Referee: [§5] §5 (Experimental Results): The key quantitative claims (leading model at 66.7%, no model above 70%, task-family discrimination) are presented without statistical error bars, confidence intervals, or sensitivity analysis over the 105-task set. This omission weakens assessment of whether observed differences between models or the middle-band task discrimination are robust.
Authors: We thank the referee for noting the missing statistical support. Pass rates are reported as direct proportions on the fixed 105-task release. In revision we will augment §5 with bootstrap 95% confidence intervals for overall and per-family pass rates, plus a sensitivity analysis consisting of 1,000 random 80% subsamples of the task set to assess stability of model ordering and bottleneck identification. These additions will quantify the robustness of the 66.7% ceiling and family-level patterns. revision: yes
Circularity Check
No circularity: purely empirical benchmark from external signals
full rationale
The paper constructs and evaluates a live benchmark by materializing tasks from public ClawHub Top-500 skills into fixed, reproducible environments with deterministic checks and LLM judging where needed. Central results (leading model at 66.7% pass rate, family-level failure patterns) are direct empirical measurements on the 105-task release snapshot. No equations, fitted parameters, predictions derived from the same data, or self-referential derivations appear. The work relies on external public workflow-demand signals rather than any internal ansatz or uniqueness theorem. This is a standard empirical benchmark paper whose claims rest on observable execution traces and audit logs, not on any reduction to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Public workflow-demand signals such as ClawHub Top-500 skills provide a representative and refreshable source for constructing realistic tasks.
Forward citations
Cited by 1 Pith paper
-
LITMUS: Benchmarking Behavioral Jailbreaks of LLM Agents in Real OS Environments
LITMUS is the first benchmark using semantic-physical dual verification and OS state rollback to measure behavioral jailbreaks in LLM agents, revealing that even strong models execute 40%+ of high-risk operations and ...
Reference graph
Works this paper leans on
-
[1]
Claude code.https://www.anthropic.com/product/claude-code, 2025
Anthropic. Claude code.https://www.anthropic.com/product/claude-code, 2025
2025
-
[2]
Program Synthesis with Large Language Models
J. Austin, A. Odena, M. Nye, M. Bosma, H. Michalewski, D. Dohan, E. Jiang, C. Cai, M. Terry, Q. Le, and C. Sutton. Program synthesis with large language models.arXiv preprint arXiv:2108.07732, 2021
work page internal anchor Pith review arXiv 2021
-
[3]
M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. d. O. Pinto, J. Kaplan, H. Edwards, Y . Burda, N. Joseph, G. Brockman, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review arXiv 2021
-
[4]
The BrowserGym ecosystem for web agent research.arXiv preprint arXiv:2412.05467,
D. Chezelles, T. Le Sellier, S. O. Shayegan, L. K. Jang, X. H. Lu, O. Yoran, D. Kong, F. F. Xu, S. Reddy, Q. Cappart, et al. The browsergym ecosystem for web agent research.arXiv preprint arXiv:2412.05467, 2024
-
[5]
G. Deng, Z. Chen, Z. Yu, H. Fan, Y . Liu, Y . Yang, D. Parikh, R. Kannan, L. Cong, M. Wang, Q. Zhang, V . Prasanna, X. Tang, and X. Wang. Evoclaw: Evaluating ai agents on continuous software evolution, 2026
2026
- [6]
-
[7]
S. Ding, X. Dai, L. Xing, S. Ding, Z. Liu, J. Yang, P. Yang, Z. Zhang, X. Wei, Y . Ma, H. Duan, J. Shao, J. Wang, D. Lin, K. Chen, and Y . Zang. Wildclawbench, 2026. Official benchmark site and GitHub repository for an in-the-wild OpenClaw agent benchmark
2026
-
[8]
WorkArena: How Capable Are Web Agents at Solving Common Knowledge Work Tasks?
A. Drouin, M. Gasse, M. Caccia, I. H. Laradji, M. Del Verme, T. Marty, L. Boisvert, M. Thakkar, Q. Cappart, D. Vazquez, et al. Workarena: How capable are web agents at solving common knowledge work tasks?arXiv preprint arXiv:2403.07718, 2024
work page internal anchor Pith review arXiv 2024
-
[9]
El Hattami, M
A. El Hattami, M. Thakkar, and N. Chapados. Webarena verified.arXiv preprint, 2025. Systematic review of evaluation issues in WebArena tasks
2025
- [10]
-
[11]
A. Gu, B. Roziere, H. Leather, A. Solar-Lezama, G. Synnaeve, and S. Wang. CRUXEval: A benchmark for code reasoning, understanding and execution.arXiv preprint arXiv:2401.03065, 2024. 12
work page internal anchor Pith review arXiv 2024
-
[12]
S. Hong, M. Zhuge, J. Chen, X. Zheng, Y . Cheng, C. Zhang, J. Wang, Z. Wang, S. K. S. Yau, Z. Lin, et al. Metagpt: Meta programming for a multi-agent collaborative framework. In International Conference on Learning Representations, 2024
2024
-
[13]
Researchclawbench: Evaluating ai agents for automated research from re- discovery to new-discovery, 2026
InternScience. Researchclawbench: Evaluating ai agents for automated research from re- discovery to new-discovery, 2026. Official benchmark collection, repository, and leaderboard
2026
-
[14]
N. Jain, K. Han, A. Gu, W.-D. Li, F. Yan, T. Zhang, S. Wang, A. Solar-Lezama, K. Sen, and I. Stoica. Livecodebench: Holistic and contamination free evaluation of large language models for code, 2024
2024
-
[15]
C. E. Jimenez, J. Yang, A. Wettig, S. Yao, K. Pei, O. Press, and K. Narasimhan. Swe-bench: Can language models resolve real-world github issues?arXiv preprint arXiv:2310.06770, 2024
work page internal anchor Pith review arXiv 2024
-
[16]
Pinchbench: Benchmarking LLM models as OpenClaw coding agents
Kilo AI. Pinchbench: Benchmarking LLM models as OpenClaw coding agents. https: //github.com/pinchbench/skill, 2026. Benchmark repository
2026
-
[17]
J. Y . Koh, R. Lo, L. Jang, V . Duvvur, M. C. Lim, P.-Y . Huang, G. Neubig, S. Zhou, R. Salakhutdi- nov, and D. Fried. Visualwebarena: Evaluating multimodal agents on realistic visual web tasks. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, 2024
2024
-
[18]
Y . Lai, C. Li, Y . Wang, T. Zhang, R. Zhong, L. Zettlemoyer, W.-t. Yih, D. Fried, S. Wang, and T. Yu. DS-1000: A natural and reliable benchmark for data science code generation. In International Conference on Machine Learning, pages 18319–18345, 2023
2023
- [19]
- [20]
- [21]
- [22]
-
[23]
X. Liu, H. Yu, H. Zhang, Y . Xu, X. Lei, H. Lai, Y . Gu, H. Ding, K. Men, K. Yang, S. Zhang, X. Deng, A. Zeng, Z. Du, C. Zhang, S. Shen, T. Zhang, Y . Su, H. Sun, M. Huang, Y . Dong, and J. Tang. Agentbench: Evaluating llms as agents. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[24]
MacDiarmid, B
M. MacDiarmid, B. Wright, J. Uesato, J. Benton, I. Kutasov, I. Price, M. Bouscal, S. R. Bowman, T. Bricken, A. Cloud, et al. Natural emergent misalignment from reward hacking in production RL, 2025
2025
-
[25]
W. Merrill, P. Shaw, N. Carlini, K. Li, H. Raj, E. Bercovich, F. Shi, D. Shin, T. Walshe, B. Buchanan, et al. Terminal-bench: Benchmarking agents on hard, realistic tasks in command line interfaces.arXiv preprint arXiv:2602.03221, 2026
-
[26]
Mialon, C
G. Mialon, C. Fourrier, C. Swift, T. Wolf, Y . LeCun, and T. Scialom. GAIA: A benchmark for general AI assistants. InInternational Conference on Learning Representations, 2024
2024
-
[27]
Hermes agent
NousResearch. Hermes agent. https://github.com/NousResearch/hermes-agent,
-
[28]
Codex.https://openai.com/codex, 2026
OpenAI. Codex.https://openai.com/codex, 2026
2026
-
[29]
Openclaw
OpenClaw. Openclaw. https://github.com/openclaw/openclaw, 2026. GitHub reposi- tory. 13
2026
- [30]
-
[31]
S. G. Patil, T. Zhang, X. Wang, and J. E. Gonzalez. Gorilla: Large language model connected with massive APIs.arXiv preprint arXiv:2305.15334, 2023
work page internal anchor Pith review arXiv 2023
- [32]
-
[33]
Y . Qin, S. Liang, Y . Ye, K. Zhu, L. Yan, Y . Lu, Y . Lin, X. Cong, X. Tang, B. Qian, et al. Toolllm: Facilitating large language models to master 16000+ real-world APIs.arXiv preprint arXiv:2307.16789, 2023
work page internal anchor Pith review arXiv 2023
-
[34]
AndroidWorld: A Dynamic Benchmarking Environment for Autonomous Agents
C. Rawles, S. Clinckemaillie, Y . Chang, J. Waltz, G. Lau, M. Fair, A. Li, W. Bishop, W. Li, F. Campbell-Ajala, et al. Androidworld: A dynamic benchmarking environment for autonomous agents.arXiv preprint arXiv:2405.14573, 2024
work page internal anchor Pith review arXiv 2024
-
[35]
Y . Ruan, H. Dong, A. Wang, S. Pitis, Y . Zhou, J. Ba, Y . Dubois, C. J. Maddison, and T. Hashimoto. Identifying the risks of LM agents with an LM-emulated sandbox.arXiv preprint arXiv:2309.15817, 2023
work page internal anchor Pith review arXiv 2023
-
[36]
Schick, J
T. Schick, J. Dwivedi-Yu, R. Dessi, R. Raileanu, M. Lomeli, E. Hambro, L. Zettlemoyer, N. Cancedda, and T. Scialom. Toolformer: Language models can teach themselves to use tools. InAdvances in Neural Information Processing Systems, 2023
2023
-
[37]
Y . Shen, K. Song, X. Tan, D. Li, W. Lu, and Y . Zhuang. Hugginggpt: Solving AI tasks with chatgpt and its friends in hugging face. InAdvances in Neural Information Processing Systems, 2023
2023
-
[38]
V on Arx, L
S. V on Arx, L. Chan, et al. Recent frontier models are reward hacking.https://metr.org/ blog/2025-06-05-recent-reward-hacking/, 2025
2025
-
[39]
X. Wang, B. Li, Y . Song, F. F. Xu, X. Tang, M. Zhuge, J. Pan, Y . Song, B. Li, J. Singh, et al. Openhands: An open platform for AI software developers as generalist agents.arXiv preprint arXiv:2407.16741, 2024
work page internal anchor Pith review arXiv 2024
-
[40]
X. Wang, Z. Wang, J. Liu, Y . Chen, L. Yuan, H. Peng, and H. Ji. MINT: Evaluating LLMs in multi-turn interaction with tools and language feedback. InInternational Conference on Learning Representations, 2024
2024
- [41]
-
[42]
Q. Wu, G. Bansal, J. Zhang, Y . Wu, B. Li, E. Zhu, L. Jiang, X. Zhang, S. Zhang, J. Liu, et al. Autogen: Enabling next-gen LLM applications via multi-agent conversation. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, 2024
2024
-
[43]
T. Xie, D. Zhang, J. Chen, X. Li, S. Zhao, R. Cao, T. J. Hua, Z. Cheng, D. Shin, F. Lei, et al. Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments. InAdvances in Neural Information Processing Systems, 2024
2024
-
[44]
Xiong, Y
W. Xiong, Y . Song, X. Zhao, W. Wu, X. Wang, K. Wang, C. Li, W. Peng, and S. Li. Watch every step! LLM agent learning via iterative step-level process refinement. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 1556–1572, 2024
2024
-
[45]
F. F. Xu, Y . Song, B. Li, Y . Tang, K. Jain, M. Bao, Z. Z. Wang, X. Zhou, Z. Guo, M. Cao, et al. Theagentcompany: Benchmarking LLM agents on consequential real world tasks. InAdvances in Neural Information Processing Systems, Datasets and Benchmarks Track, 2025
2025
-
[46]
T. Xue, W. Qi, T. Shi, C. H. Song, B. Gou, D. Song, H. Sun, and Y . Su. An illusion of progress? assessing the current state of web agents. InConference on Language Modeling, 2025. 14
2025
-
[47]
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y . Cao. React: Synergizing rea- soning and acting in language models. InInternational Conference on Learning Representations, 2023
2023
-
[48]
S. Yao, N. Shinn, P. Razavi, and K. Narasimhan. τ-bench: A benchmark for tool-agent-user interaction in real-world domains.arXiv preprint arXiv:2406.12045, 2024
work page internal anchor Pith review arXiv 2024
-
[49]
B. Ye, R. Li, Q. Yang, Y . Liu, L. Yao, H. Lv, Z. Xie, C. An, L. Li, L. Kong, et al. Claw-eval: Toward trustworthy evaluation of autonomous agents, 2026
2026
-
[50]
Yoran, S
O. Yoran, S. J. Amouyal, C. Malaviya, B. Bogin, O. Press, and J. Berant. Assistantbench: Can web agents solve realistic and time-consuming tasks? InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 8938–8968, 2024
2024
-
[51]
T. Yuan, Z. He, L. Dong, Y . Wang, R. Zhao, T. Xia, L. Xu, B. Zhou, F. Li, Z. Zhang, et al. R-judge: Benchmarking safety risk awareness for LLM agents. InFindings of the Association for Computational Linguistics: EMNLP, 2024
2024
-
[52]
Zhang, Y
Y . Zhang, Y . Wang, Y . Zhu, P. Du, J. Miao, X. Lu, W. Xu, Y . Hao, S. Cai, X. Wang, H. Zhang, X. Wu, Y . Lu, M. Lei, K. Zou, H. Yin, P. Nie, L. Chen, D. Jiang, W. Chen, and K. R. Allen. Clawbench: Can ai agents complete everyday online tasks?, 2026
2026
-
[53]
Agent-SafetyBench: Evaluating the Safety of LLM Agents
Z. Zhang, L. Lei, L. Wu, R. Sun, Y . Huang, C. Long, X. Liu, X. Lei, J. Tang, and M. Huang. Agent-safetybench: Evaluating the safety of LLM agents.arXiv preprint arXiv:2412.14470, 2024
work page internal anchor Pith review arXiv 2024
-
[54]
S. Zhou, F. F. Xu, H. Zhu, X. Zhou, R. Lo, A. Sridhar, X. Cheng, T. Ou, Y . Bisk, D. Fried, et al. Webarena: A realistic web environment for building autonomous agents.arXiv preprint arXiv:2307.13854, 2023. 15 A Supplementary Figures and Tables This appendix collects construction- and setup-reference material that accompanies the main text. Figure 6 gives...
work page internal anchor Pith review arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.