Connecting online criminal behavior with machine learning: Using authorship attribution to analyze and link potential online traffickers
Pith reviewed 2026-05-10 15:24 UTC · model grok-4.3
The pith
People maintain consistent writing and image styles in online ads that machine learning can use to link anonymous accounts across criminal networks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By applying authorship attribution techniques to large collections of online advertisements, the research shows that consistent linguistic and visual patterns persist across accounts used in illegal online markets, enabling the linkage of related profiles and identification of repeated behavior even when offenders attempt to remain anonymous.
What carries the argument
Authorship attribution methods that extract and compare writing styles together with image presentation features from online advertisements to detect stable individual patterns.
If this is right
- Law enforcement can map larger networks by connecting accounts that use similar ad styles across different markets.
- Repeated offender behavior becomes identifiable through pattern matches in writing and images.
- Practical tools can support investigations when paired with the proposed ethical guidelines for privacy and fairness.
Where Pith is reading between the lines
- The same pattern-matching approach could scale to track other forms of online illicit trade beyond trafficking.
- Long-term effectiveness depends on how much offenders alter their styles when aware of such analysis.
- Integration with image metadata analysis might reduce reliance on text alone and lower error rates.
Load-bearing premise
Consistent writing and image patterns in ads are distinctive and stable enough to link accounts accurately in real anonymous online settings without excessive false connections.
What would settle it
A controlled test on known unrelated accounts that produces many false links, or on known accounts from the same individual that fails to connect them due to pattern shifts.
Figures





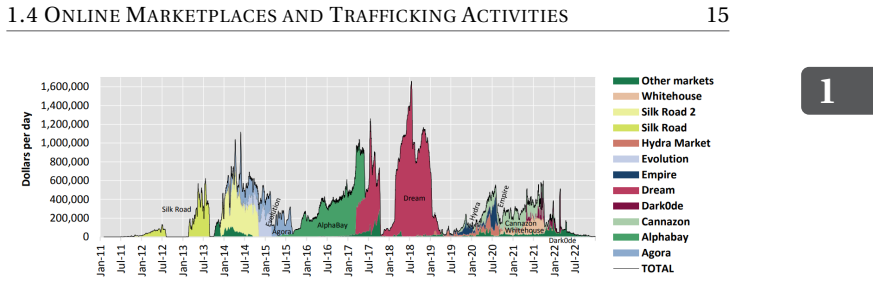






























read the original abstract
This research investigated how online criminal activities can be better understood and connected using data-driven machine learning methods. Many illegal activities, such as human trafficking and illicit trade, have moved to online platforms where offenders hide behind anonymous accounts and frequently change identities. This makes it difficult for authorities to understand how large these networks are and how different online profiles may be linked. The research shows that people tend to maintain consistent patterns in how they write advertisements and present images online, even when they try to stay anonymous. By analysing these patterns across large collections of online advertisements, the research demonstrates how to link related accounts and identify repeated behaviour across illegal online markets. In addition, the research also addresses how such methods should be used responsibly. It proposes clear guidelines to ensure that privacy, fairness, and transparency are respected when these tools are applied. Overall, the research provides practical ways to support law enforcement investigations while emphasising careful and ethical use.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that machine learning-based authorship attribution applied to online advertisements can identify consistent individual patterns in writing style and image presentation, even under anonymity attempts, thereby enabling the linking of accounts involved in criminal activities such as human trafficking and illicit trade across platforms. It further proposes ethical guidelines for responsible deployment of these methods by law enforcement.
Significance. If the empirical results hold with adequate validation, the work could contribute practical stylometric and multimodal techniques to digital forensics for mapping anonymous criminal networks, while the inclusion of responsible-use guidelines addresses important ethical dimensions in applying ML to sensitive data.
major comments (3)
- [Abstract and §4] Abstract and §4 (Evaluation): the central claim that patterns 'demonstrate how to link related accounts' is unsupported by any reported quantitative metrics (e.g., precision-recall on known linked pairs, false-positive rates, or cross-validation results), leaving the distinctiveness of features unverified.
- [§3] §3 (Methods): no description is provided of the specific authorship attribution models, text features (e.g., n-grams, stylometric measures), image features, or how ground-truth linked accounts were obtained, which is load-bearing for assessing whether observed consistency reflects individual identity rather than platform templates or genre.
- [§5] §5 (Results/Discussion): absence of ablation studies separating text vs. image contributions or tests under realistic anonymity perturbations (e.g., paraphrasing, emoji variation) prevents evaluation of whether the linking method generalizes beyond the collected advertisements.
minor comments (2)
- [Abstract] Abstract: the phrasing 'the research demonstrates' and 'the research shows' is repetitive; consolidate to improve conciseness.
- [Throughout] Throughout: ensure consistent terminology for 'authorship attribution' vs. 'stylometric analysis' and define any domain-specific acronyms at first use.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback, which highlights important areas for strengthening the manuscript. We agree that the current version requires additional methodological details, quantitative evaluations, and robustness analyses to better support the claims. We address each major comment below and indicate the planned revisions.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Evaluation): the central claim that patterns 'demonstrate how to link related accounts' is unsupported by any reported quantitative metrics (e.g., precision-recall on known linked pairs, false-positive rates, or cross-validation results), leaving the distinctiveness of features unverified.
Authors: We agree that the abstract and §4 currently lack quantitative metrics to substantiate the linking claims, relying instead on qualitative demonstrations of pattern consistency. This is a valid observation given the exploratory nature of the presented work. In the revised manuscript, we will update the abstract and expand §4 with a new quantitative evaluation subsection. This will include precision, recall, and F1 scores for account linking on subsets with available ground-truth pairs, along with cross-validation results and estimated false-positive rates to verify feature distinctiveness. revision: yes
-
Referee: [§3] §3 (Methods): no description is provided of the specific authorship attribution models, text features (e.g., n-grams, stylometric measures), image features, or how ground-truth linked accounts were obtained, which is load-bearing for assessing whether observed consistency reflects individual identity rather than platform templates or genre.
Authors: We acknowledge the absence of specific methodological details in §3, which limits assessment of whether consistencies arise from individual identity or other factors. We will substantially revise §3 to describe the authorship attribution models (e.g., classifiers using n-gram and stylometric features), the exact text features (character/word n-grams, function words, sentence statistics) and image features (CNN embeddings, visual metadata), and the process for obtaining ground-truth linked accounts via manual cross-referencing and temporal analysis. We will also discuss controls for platform templates and genre effects to address potential confounds. revision: yes
-
Referee: [§5] §5 (Results/Discussion): absence of ablation studies separating text vs. image contributions or tests under realistic anonymity perturbations (e.g., paraphrasing, emoji variation) prevents evaluation of whether the linking method generalizes beyond the collected advertisements.
Authors: We agree that the lack of ablation studies and perturbation tests in §5 restricts evaluation of generalizability. We will revise §5 to include ablation experiments isolating text-only versus image-only contributions to linking performance, reported with appropriate metrics. We will also add robustness tests simulating realistic anonymity attempts, such as paraphrasing and emoji variations, to demonstrate how the method holds under such conditions and to better assess generalization beyond the collected data. revision: yes
Circularity Check
No significant circularity; derivation chain is self-contained
full rationale
The paper describes an applied machine-learning study on authorship attribution for online advertisements without presenting any mathematical derivations, equations, or first-principles results. No steps reduce by construction to fitted inputs, self-definitions, or self-citation chains; the central claims rest on empirical pattern analysis whose validity is independent of the paper's own outputs. The absence of load-bearing predictions or uniqueness theorems imported from prior author work keeps the work non-circular under the stated criteria.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
(Cited on page 127.) Dignum, V . (2019). Responsible artificial intelligence: how to develop and use AI in a responsible way, volume 2156. Springer. (Cited on page 129.) Dimas, G. L., Konrad, R. A., Lee Maass, K., and Trapp, A. C. (2022). Op- erations research and analytics to combat human trafficking: A system- atic review of academic literature. PloS on...
-
[2]
(Cited on pages 93 and 96.) Fjeld, J., Achten, N., Hilligoss, H., Nagy, A., and Srikumar, M. (2020). Prin- cipled artificial intelligence: Mapping consensus in ethical and rights- based approaches to principles for ai. Berkman Klein Center Research Publication, (2020-1). (Cited on pages 22, 128, 129, and 135.) Floridi, L. and Chiriatti, M. (2020). Gpt-3: ...
-
[3]
(Cited on page 94.) Huang, F ., Zhang, X., Zhao, Z., Xu, J., and Li, Z
Springer. (Cited on page 94.) Huang, F ., Zhang, X., Zhao, Z., Xu, J., and Li, Z. (2019). Image–text senti- ment analysis via deep multimodal attentive fusion. Knowledge-Based Systems, 167:26–37. (Cited on page 88.) Huang, G., Liu, Z., van der Maaten, L., and Weinberger, K. Q. (2018). Densely connected convolutional networks. (Cited on page 94.) Huang, M....
-
[4]
(Cited on pages 142 and 143.) Jafariakinabad, F ., Tarnpradab, S., and Hua, K. A. (2019). Syntactic re- current neural network for authorship attribution. (Cited on pages 34 and 127.) 214 R EFERENCES James, P . (2017). Dark net marketplace data (agora 2014-2015). (Cited on page 36.) Jardine, E. (2015). The dark web dilemma: Tor, anonymity and online polic...
-
[5]
International Conference on Computer, Communication and Con- vergence (ICCC 2015). (Cited on page 127.) Prem, E. (2023). From ethical ai frameworks to tools: a review of ap- proaches. AI and Ethics, 3(3):699–716. (Cited on page 129.) Procter, R. N., Rouncefield, M., and Tolmie, P . (2020). Accounts, account- ability and agency for safe and ethical ai. ArX...
-
[6]
(Cited on page 135.) Steck, H., Ekanadham, C., and Kallus, N. (2024). Is cosine-similarity of embeddings really about similarity? In Companion Proceedings of the ACM Web Conference 2024, WWW ’24, page 887–890, New York, NY, USA. Association for Computing Machinery. (Cited on page 24.) REFERENCES 235 Stepin, I., Alonso, J. M., Catala, A., and Pereira-Fariñ...
-
[7]
(Cited on page 149.) REFERENCES 243 Zhang, X., Zhao, J., and LeCun, Y. (2015). Character-level convolutional networks for text classification. Advances in neural information process- ing systems, 28. (Cited on page 127.) Zhang, X., Zhao, J., and LeCun, Y. (2016). Character-level convolutional networks for text classification. (Cited on page 44.) Zhang, Y....
work page 2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.