Recognition: unknown
TriRelVLA: Triadic Relational Structure for Generalizable Embodied Manipulation
Pith reviewed 2026-05-08 14:50 UTC · model grok-4.3
The pith
By modeling explicit triadic relations among objects, hands, and tasks, vision-language-action models generalize manipulation to unseen scenes and objects.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
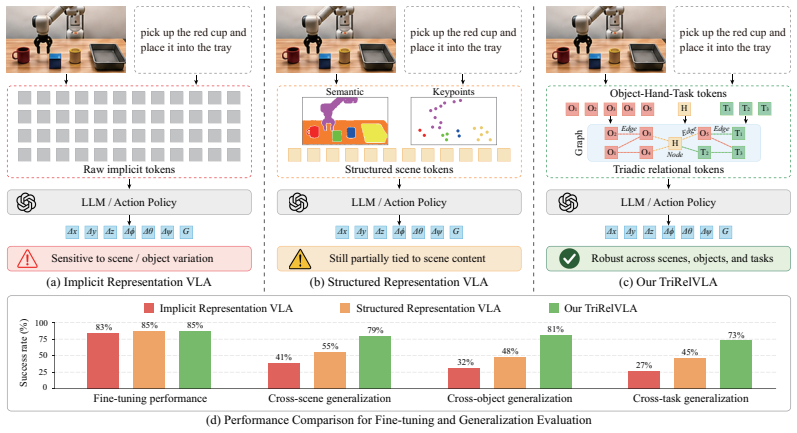
TriRelVLA constructs explicit object-hand-task triadic representations as relational primitives from multimodal inputs, builds a task-grounded relational graph using task-guided cross-attention and a relation-aware graph transformer to model interactions, and performs relation-conditioned action generation by compressing the relational structure into a bottleneck projected into the LLM.
What carries the argument
The object-hand-task triadic relational bottleneck that encodes interactions among task requirements, robot states, and object properties to condition action prediction.
If this is right
- Action prediction becomes less sensitive to visual variations in scenes and objects.
- Models can handle composed tasks not seen in training by recombining relational primitives.
- Fine-tuning on limited real-world data yields strong performance on held-out configurations.
- Transfer improves across different scenes and objects without retraining on new appearances.
Where Pith is reading between the lines
- This relational focus could reduce the amount of training data needed for effective VLA models by supplying useful structure.
- It opens a path to combine these models with high-level planners that reason over relations explicitly.
- Future tests on tasks with heavy physics like pouring or stacking deformable items would check if the abstraction misses important dynamics.
Load-bearing premise
The assumption that triadic object-hand-task relations can be accurately extracted from multimodal inputs and that these relations alone are sufficient to determine successful actions.
What would settle it
A controlled test that alters only object textures, colors, and backgrounds while keeping object positions, hand states, and task goals identical, then checks whether success rates stay high compared to appearance-based baselines.
Figures





read the original abstract
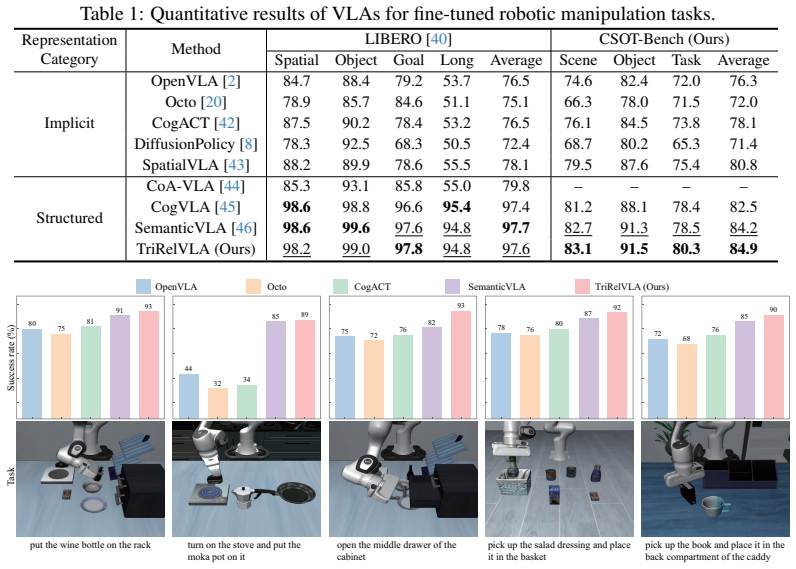
Vision-language-action (VLA) models perform well on training-seen robotic tasks but struggle to generalize to unseen scenes and objects. A key limitation lies in their implicit visual representations, which entangle object appearance, background, and scene layout. This makes policies sensitive to visual variations. Prior work improves transferability through structured intermediate representations that objectify visual content. However, these representations mainly capture scene semantics instead of action-relevant relations. As a result, action prediction remains tied to appearance statistics. We observe that manipulation actions depend on the object-hand-task relational structure, which governs interactions among task requirements, robot states, and object properties. Based on this observation, we propose TriRelVLA, a triadic relational VLA framework for generalizable embodied manipulation. Our approach consists of three components: 1) We construct explicit object-hand-task triadic representations from multimodal inputs as relational primitives. 2) We build a task-grounded relational graph. Task-guided cross-attention forms nodes, and a relation-aware graph transformer models interactions among them. 3) We perform relation-conditioned action generation. The relational structure is compressed into a bottleneck space and projected into the LLM for action prediction. This triadic relational bottleneck reduces reliance on appearance statistics and enables transfer across scenes, objects, and task compositions. We further introduce a real-world robotic dataset for fine-tuning. Experiments show strong performance on fine-tuned tasks and clear gains in cross-scene, cross-object, and cross-task generalization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes TriRelVLA, a vision-language-action framework for robotic manipulation that constructs explicit object-hand-task triadic representations from multimodal inputs, builds a task-grounded relational graph using task-guided cross-attention and a relation-aware graph transformer, and compresses this structure into a bottleneck projected to an LLM for action prediction. The authors introduce a real-world robotic dataset for fine-tuning and claim that this triadic relational bottleneck reduces reliance on appearance statistics, yielding improved performance on fine-tuned tasks and better generalization across scenes, objects, and task compositions.
Significance. If the empirical claims are substantiated, the work could advance generalizable embodied manipulation by replacing implicit visual features with structured relational primitives that better capture action-relevant interactions. The new dataset is a concrete community contribution that could support further benchmarking. However, the significance hinges on whether the triadic structure demonstrably isolates relational factors from appearance and physical dynamics.
major comments (3)
- [Abstract (component 2)] Abstract, component 2 (task-grounded relational graph): The task-guided cross-attention for node formation and the subsequent relation-aware graph transformer are presented without any invariance loss, disentanglement objective, or explicit mechanism to suppress appearance statistics from the upstream vision backbone. This is load-bearing for the central claim that the triadic bottleneck 'reduces reliance on appearance statistics,' because without such a mechanism the reported cross-scene/object/task gains could be artifacts of the fine-tuning dataset rather than the relational structure itself.
- [Abstract (component 3)] Abstract, component 3 (relation-conditioned action generation): The compression of the relational structure into a bottleneck space prior to LLM projection is described at a high level, but the manuscript provides no analysis or ablation showing that this bottleneck preserves (or can recover) unmodeled physical factors such as friction, mass distribution, or contact geometry. The sufficiency assumption—that the extracted triadic nodes plus graph interactions contain everything needed for successful action prediction—is therefore not yet supported and directly affects the generalization claims.
- [Experiments] Experiments section: The reported 'strong performance' and 'clear gains' in cross-scene, cross-object, and cross-task settings lack ablations that isolate the triadic relational bottleneck (e.g., comparing against a version without the graph transformer or without the bottleneck projection). Without these controls, it is impossible to attribute improvements specifically to the proposed triadic structure versus other modeling choices or the new dataset.
minor comments (2)
- [Abstract] The abstract would be strengthened by including at least one quantitative result (e.g., success rate delta or generalization gap) alongside the qualitative claims of 'strong performance' and 'clear gains.'
- Notation for the triadic nodes and the bottleneck projection could be introduced earlier with explicit variable definitions to improve readability of the framework description.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on TriRelVLA. We address each major comment below, providing clarifications on our design choices while committing to revisions that strengthen the empirical support for our claims.
read point-by-point responses
-
Referee: [Abstract (component 2)] Abstract, component 2 (task-grounded relational graph): The task-guided cross-attention for node formation and the subsequent relation-aware graph transformer are presented without any invariance loss, disentanglement objective, or explicit mechanism to suppress appearance statistics from the upstream vision backbone. This is load-bearing for the central claim that the triadic bottleneck 'reduces reliance on appearance statistics,' because without such a mechanism the reported cross-scene/object/task gains could be artifacts of the fine-tuning dataset rather than the relational structure itself.
Authors: We agree that no explicit invariance or disentanglement loss is employed. The task-guided cross-attention constructs nodes by attending to task-relevant features from multimodal inputs, and the relation-aware graph transformer then models explicit interactions among object-hand-task nodes. This architectural choice is intended to prioritize relational structure over raw appearance statistics by construction. However, to more rigorously isolate this effect from dataset-specific factors, we will add an ablation comparing the full model against a variant without the graph transformer in the revised manuscript. revision: yes
-
Referee: [Abstract (component 3)] Abstract, component 3 (relation-conditioned action generation): The compression of the relational structure into a bottleneck space prior to LLM projection is described at a high level, but the manuscript provides no analysis or ablation showing that this bottleneck preserves (or can recover) unmodeled physical factors such as friction, mass distribution, or contact geometry. The sufficiency assumption—that the extracted triadic nodes plus graph interactions contain everything needed for successful action prediction—is therefore not yet supported and directly affects the generalization claims.
Authors: The triadic relational bottleneck is designed to encode action-relevant relations rather than to explicitly model low-level physics; physical factors such as friction and contact dynamics are implicitly captured through end-to-end training on real-world demonstrations and handled by the downstream low-level controller. While we lack a dedicated analysis recovering specific physical parameters from the bottleneck, the framework's strong real-world performance across varied objects and scenes provides empirical support for sufficiency on the evaluated tasks. We will expand the discussion of this assumption and its limitations in the revised version. revision: partial
-
Referee: [Experiments] Experiments section: The reported 'strong performance' and 'clear gains' in cross-scene, cross-object, and cross-task settings lack ablations that isolate the triadic relational bottleneck (e.g., comparing against a version without the graph transformer or without the bottleneck projection). Without these controls, it is impossible to attribute improvements specifically to the proposed triadic structure versus other modeling choices or the new dataset.
Authors: We concur that targeted ablations are necessary to attribute gains specifically to the triadic relational components. The current experiments demonstrate overall improvements, but to isolate the bottleneck and graph transformer, we will include additional ablation studies (e.g., removing the relation-aware graph transformer and the bottleneck projection) in the revised manuscript. revision: yes
Circularity Check
No circularity detected in TriRelVLA framework derivation
full rationale
The paper introduces a novel architecture with three explicit components: construction of object-hand-task triadic nodes via task-guided cross-attention, modeling via relation-aware graph transformer, and compression into a bottleneck projected to an LLM for action prediction. These steps are presented as design choices motivated by an observation about relational structure in manipulation tasks, without any equations, fitted parameters, or derivations that reduce the claimed generalization benefits to self-definitional inputs or prior fitted values by construction. No self-citations are invoked as load-bearing uniqueness theorems, no ansatzes are smuggled, and no known results are merely renamed. The central claims rest on the sufficiency of the proposed relational primitives rather than any internal reduction, rendering the derivation self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Manipulation actions depend on the object-hand-task relational structure which governs interactions among task requirements, robot states, and object properties.
invented entities (3)
-
Explicit object-hand-task triadic representations
no independent evidence
-
Task-grounded relational graph
no independent evidence
-
Relation-conditioned action generation bottleneck
no independent evidence
Reference graph
Works this paper leans on
-
[1]
RT-1: Robotics Transformer for Real-World Control at Scale
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, et al. Rt-1: Robotics transformer for real-world control at scale.arXiv preprint arXiv:2212.06817, 2022
work page internal anchor Pith review arXiv 2022
-
[2]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review arXiv 2024
-
[3]
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
Moo Jin Kim, Chelsea Finn, and Percy Liang. Fine-tuning vision-language-action models: Optimizing speed and success.arXiv preprint arXiv:2502.19645, 2025
work page internal anchor Pith review arXiv 2025
-
[4]
V olumetric environment representation for vision-language navigation
Rui Liu, Wenguan Wang, and Yi Yang. V olumetric environment representation for vision-language navigation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16317–16328, 2024
2024
-
[5]
Vision-and- language navigation via causal learning
Liuyi Wang, Zongtao He, Ronghao Dang, Mengjiao Shen, Chengju Liu, and Qijun Chen. Vision-and- language navigation via causal learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 13139–13150, 2024
2024
-
[6]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al. π0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review arXiv 2024
-
[7]
Rt-2: Vision-language-action models transfer web knowledge to robotic control
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. InConference on Robot Learning, pages 2165–2183. PMLR, 2023
2023
-
[8]
Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
2025
-
[9]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, et al. π0.5: a vision-language-action model with open-world generalization.arXiv preprint arXiv:2504.16054, 2025
work page internal anchor Pith review arXiv 2025
-
[10]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Johan Bjorck, Fernando Castañeda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, et al. Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734, 2025
work page internal anchor Pith review arXiv 2025
-
[11]
arXiv preprint arXiv:2403.03174
Fangchen Liu, Kuan Fang, Pieter Abbeel, and Sergey Levine. Moka: Open-world robotic manipulation through mark-based visual prompting.arXiv preprint arXiv:2403.03174, 2024
-
[12]
Graphcot-vla: A 3d spatial-aware reasoning vision-language-action model for robotic manipulation with ambiguous instructions
Helong Huang, Min Cen, Kai Tan, Xingyue Quan, Guowei Huang, and Hong Zhang. Graphcot-vla: A 3d spatial-aware reasoning vision-language-action model for robotic manipulation with ambiguous instructions. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 18324– 18332, 2026
2026
-
[13]
Object-centric prompt-driven vision-language-action model for robotic manipulation
Xiaoqi Li, Jingyun Xu, Mingxu Zhang, Jiaming Liu, Yan Shen, Iaroslav Ponomarenko, Jiahui Xu, Liang Heng, Siyuan Huang, Shanghang Zhang, et al. Object-centric prompt-driven vision-language-action model for robotic manipulation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 27638–27648, 2025
2025
-
[14]
Manipllm: Embodied multimodal large language model for object-centric robotic manipulation
Xiaoqi Li, Mingxu Zhang, Yiran Geng, Haoran Geng, Yuxing Long, Yan Shen, Renrui Zhang, Jiaming Liu, and Hao Dong. Manipllm: Embodied multimodal large language model for object-centric robotic manipulation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18061–18070, 2024
2024
-
[15]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Llava: Large language and vision assistant. arXiv preprint arXiv:2304.08485, 2023
work page internal anchor Pith review arXiv 2023
-
[16]
Flamingo: a visual language model for few-shot learning.Advances in Neural Information Processing Systems, 35:23716–23732, 2022
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Arthur Mensch, Katie Millican, David Moore, Michael Needham, et al. Flamingo: a visual language model for few-shot learning.Advances in Neural Information Processing Systems, 35:23716–23732, 2022
2022
-
[17]
Improved visual instruction tuning for image-text alignment.arXiv preprint, abs/2310.00067, 2023
Haotian Liu, Pengchuan Zhang, Jianwei Yang, and Lei Zhang. Improved visual instruction tuning for image-text alignment.arXiv preprint, abs/2310.00067, 2023. 10
-
[18]
BLIP-2: Bootstrapping language-image pre- training with frozen image encoders and large language models
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. BLIP-2: Bootstrapping language-image pre- training with frozen image encoders and large language models. InProceedings of the 40th International Conference on Machine Learning, volume 202 ofProceedings of Machine Learning Research, pages 19730–19742. PMLR, 2023
2023
-
[19]
Hanyu Zhou and Gim Hee Lee. Llava-4d: Embedding spatiotemporal prompt into lmms for 4d scene understanding.arXiv preprint arXiv:2505.12253, 2025
-
[20]
Octo: An Open-Source Generalist Robot Policy
Octo Model Team, Dibya Ghosh, Homer Walke, Karl Pertsch, Kevin Black, Oier Mees, Sudeep Dasari, Joey Hejna, Tobias Kreiman, Charles Xu, et al. Octo: An open-source generalist robot policy.arXiv preprint arXiv:2405.12213, 2024
work page internal anchor Pith review arXiv 2024
-
[21]
Hanyu Zhou, Chuanhao Ma, and Gim Hee Lee. Vla-4d: Embedding 4d awareness into vision-language- action models for spatiotemporally coherent robotic manipulation.arXiv preprint arXiv:2511.17199, 2025
-
[22]
ST-$\pi$: Structured SpatioTemporal VLA for Robotic Manipulation
Chuanhao Ma, Hanyu Zhou, Shihan Peng, Yan Li, Tao Gu, and Luxin Yan. St-π: Structured spatiotemporal vla for robotic manipulation.arXiv preprint arXiv:2604.17880, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[23]
DexVLA: Vision-Language Model with Plug-In Diffusion Expert for General Robot Control
Junjie Wen, Yichen Zhu, Jinming Li, Zhibin Tang, Chaomin Shen, and Feifei Feng. Dexvla: Vision- language model with plug-in diffusion expert for general robot control.arXiv preprint arXiv:2502.05855, 2025
work page Pith review arXiv 2025
-
[24]
Yiguo Fan, Pengxiang Ding, Shuanghao Bai, Xinyang Tong, Yuyang Zhu, Hongchao Lu, Fengqi Dai, Wei Zhao, Yang Liu, Siteng Huang, et al. Long-vla: Unleashing long-horizon capability of vision language action model for robot manipulation.arXiv preprint arXiv:2508.19958, 2025
-
[25]
Chatvla: Unified multimodal understanding and robot control with vision-language-action model
Zhongyi Zhou, Yichen Zhu, Minjie Zhu, Junjie Wen, Ning Liu, Zhiyuan Xu, Weibin Meng, Yaxin Peng, Chaomin Shen, Feifei Feng, et al. Chatvla: Unified multimodal understanding and robot control with vision-language-action model. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 5377–5395, 2025
2025
-
[26]
arXiv preprint arXiv:2412.10345 (2024) 13
Ruijie Zheng, Yongyuan Liang, Shuaiyi Huang, Jianfeng Gao, Hal Daumé III, Andrey Kolobov, Furong Huang, and Jianwei Yang. Tracevla: Visual trace prompting enhances spatial-temporal awareness for generalist robotic policies.arXiv preprint arXiv:2412.10345, 2024
-
[27]
Tinyvla: Towards fast, data-efficient vision-language-action models for robotic manipulation.IEEE Robotics and Automation Letters, 2025
Junjie Wen, Yichen Zhu, Jinming Li, Minjie Zhu, Zhibin Tang, Kun Wu, Zhiyuan Xu, Ning Liu, Ran Cheng, Chaomin Shen, et al. Tinyvla: Towards fast, data-efficient vision-language-action models for robotic manipulation.IEEE Robotics and Automation Letters, 2025
2025
-
[28]
Cot-vla: Visual chain-of-thought reasoning for vision-language-action models
Qingqing Zhao, Yao Lu, Moo Jin Kim, Zipeng Fu, Zhuoyang Zhang, Yecheng Wu, Zhaoshuo Li, Qianli Ma, Song Han, Chelsea Finn, et al. Cot-vla: Visual chain-of-thought reasoning for vision-language-action models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 1702–1713, 2025
2025
-
[29]
arXiv preprint arXiv:2508.07650 , year=
Helong Huang, Min Cen, Kai Tan, Xingyue Quan, Guowei Huang, and Hong Zhang. Graphcot-vla: A 3d spatial-aware reasoning vision-language-action model for robotic manipulation with ambiguous instructions.arXiv preprint arXiv:2508.07650, 2025
-
[30]
Attention is all you need.Adv
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Adv. Neural Inform. Process. Syst., 30, 2017
2017
-
[31]
Xiaojian Ma, Weili Nie, Zhiding Yu, Huaizu Jiang, Chaowei Xiao, Yuke Zhu, Song-Chun Zhu, and Anima Anandkumar. Relvit: Concept-guided vision transformer for visual relational reasoning.arXiv preprint arXiv:2204.11167, 2022
-
[32]
Relationlmm: Large multimodal model as open and versatile visual relationship generalist.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
Chi Xie, Shuang Liang, Jie Li, Zhao Zhang, Feng Zhu, Rui Zhao, and Yichen Wei. Relationlmm: Large multimodal model as open and versatile visual relationship generalist.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2025
-
[33]
Structure-clip: Towards scene graph knowledge to enhance multi-modal structured representations
Yufeng Huang, Jiji Tang, Zhuo Chen, Rongsheng Zhang, Xinfeng Zhang, Weijie Chen, Zeng Zhao, Zhou Zhao, Tangjie Lv, Zhipeng Hu, et al. Structure-clip: Towards scene graph knowledge to enhance multi-modal structured representations. InProceedings of the AAAI conference on artificial intelligence, volume 38, pages 2417–2425, 2024
2024
-
[34]
Wenlong Huang, Chen Wang, Yunzhu Li, Ruohan Zhang, and Li Fei-Fei. Rekep: Spatio-temporal reasoning of relational keypoint constraints for robotic manipulation.arXiv preprint arXiv:2409.01652, 2024. 11
-
[35]
Haonan Wang, Hanyu Zhou, Haoyue Liu, and Luxin Yan. 4d-vggt: A general foundation model with spatiotemporal awareness for dynamic scene geometry estimation.arXiv preprint arXiv:2511.18416, 2025
-
[36]
Sigmoid loss for language image pre-training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. InProceedings of the IEEE/CVF international conference on computer vision, pages 11975–11986, 2023
2023
-
[37]
Vggt: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Visual geometry grounded transformer. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5294–5306, 2025
2025
-
[38]
Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0
Abby O’Neill, Abdul Rehman, Abhiram Maddukuri, Abhishek Gupta, Abhishek Padalkar, Abraham Lee, Acorn Pooley, Agrim Gupta, Ajay Mandlekar, Ajinkya Jain, et al. Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 6892–6903. IEEE, 2024
2024
-
[39]
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
Alexander Khazatsky, Karl Pertsch, Suraj Nair, Ashwin Balakrishna, Sudeep Dasari, Siddharth Karamcheti, Soroush Nasiriany, Mohan Kumar Srirama, Lawrence Yunliang Chen, Kirsty Ellis, et al. Droid: A large-scale in-the-wild robot manipulation dataset.arXiv preprint arXiv:2403.12945, 2024
work page internal anchor Pith review arXiv 2024
-
[40]
Libero: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776–44791, 2023
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776–44791, 2023
2023
-
[41]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review arXiv 2025
-
[42]
Qixiu Li, Yaobo Liang, Zeyu Wang, Lin Luo, Xi Chen, Mozheng Liao, Fangyun Wei, Yu Deng, Sicheng Xu, Yizhong Zhang, et al. Cogact: A foundational vision-language-action model for synergizing cognition and action in robotic manipulation.arXiv preprint arXiv:2411.19650, 2024
work page Pith review arXiv 2024
-
[43]
SpatialVLA: Exploring Spatial Representations for Visual-Language-Action Model
Delin Qu, Haoming Song, Qizhi Chen, Yuanqi Yao, Xinyi Ye, Yan Ding, Zhigang Wang, JiaYuan Gu, Bin Zhao, Dong Wang, et al. Spatialvla: Exploring spatial representations for visual-language-action model. arXiv preprint arXiv:2501.15830, 2025
work page internal anchor Pith review arXiv 2025
-
[44]
arXiv preprint arXiv:2412.20451 (2024)
Jinming Li, Yichen Zhu, Zhibin Tang, Junjie Wen, Minjie Zhu, Xiaoyu Liu, Chengmeng Li, Ran Cheng, Yaxin Peng, Yan Peng, et al. Coa-vla: Improving vision-language-action models via visual-textual chain-of-affordance.arXiv preprint arXiv:2412.20451, 2024
-
[45]
Wei Li, Renshan Zhang, Rui Shao, Jie He, and Liqiang Nie. Cogvla: Cognition-aligned vision-language- action model via instruction-driven routing & sparsification.arXiv preprint arXiv:2508.21046, 2025
-
[46]
Seman- ticvla: Semantic-aligned sparsification and enhancement for efficient robotic manipulation
Wei Li, Renshan Zhang, Rui Shao, Zhijian Fang, Kaiwen Zhou, Zhuotao Tian, and Liqiang Nie. Seman- ticvla: Semantic-aligned sparsification and enhancement for efficient robotic manipulation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 18397–18405, 2026
2026
-
[47]
Robomemory: A brain-inspired multi-memory agentic framework for lifelong learning in physical embodied systems
Mingcong Lei, Honghao Cai, Zezhou Cui, Liangchen Tan, Junkun Hong, Gehan Hu, Shuangyu Zhu, Yimou Wu, Shaohan Jiang, Ge Wang, et al. Robomemory: A brain-inspired multi-memory agentic framework for lifelong learning in physical embodied systems. InNeurIPS 2025 Workshop on Space in Vision, Language, and Embodied AI, 2025
2025
-
[48]
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
Michael Ahn, Anthony Brohan, Noah Brown, Yevgen Chebotar, Omar Cortes, Byron David, Chelsea Finn, Chuyuan Fu, Keerthana Gopalakrishnan, Karol Hausman, et al. Do as i can, not as i say: Grounding language in robotic affordances.arXiv preprint arXiv:2204.01691, 2022. 12
work page internal anchor Pith review arXiv 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.