Recognition: unknown
RVPO: Risk-Sensitive Alignment via Variance Regularization
Pith reviewed 2026-05-08 14:56 UTC · model grok-4.3
The pith
RVPO shifts multi-reward RLHF from maximizing averages to maximizing consistency across objectives.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By replacing mean aggregation with a LogSumExp operator that penalizes inter-reward variance, RVPO makes the policy optimize for consistent reward achievement, preventing the numerical masking of low-performing constraints by high-performing ones.
What carries the argument
The LogSumExp operator used for advantage aggregation, which serves as a smooth variance penalty to promote risk-sensitive optimization.
Load-bearing premise
That the LogSumExp-based variance penalty will prevent constraint neglect without introducing optimization instabilities or needing heavy hyperparameter tuning across scales and reward configurations.
What would settle it
If a model trained with RVPO still exhibits constraint neglect on a new multi-reward task with conflicting objectives, or if performance degrades due to instability at larger model sizes, the core benefit would be falsified.
Figures





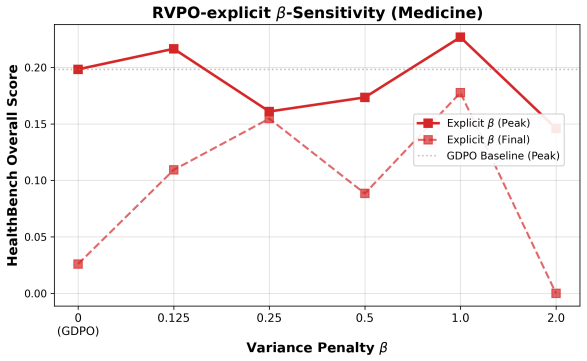
read the original abstract
Current critic-less RLHF methods aggregate multi-objective rewards via an arithmetic mean, leaving them vulnerable to constraint neglect: high-magnitude success in one objective can numerically offset critical failures in others (e.g., safety or formatting), masking low-performing "bottleneck" rewards vital for reliable multi-objective alignment. We propose Reward-Variance Policy Optimization (RVPO), a risk-sensitive framework that penalizes inter-reward variance during advantage aggregation, shifting the objective from "maximize sum" to "maximize consistency." We show via Taylor expansion that a LogSumExp (SoftMin) operator effectively acts as a smooth variance penalty. We evaluate RVPO on rubric-based medical and scientific reasoning with up to 17 concurrent LLM-judged reward signals (Qwen2.5-3B/7B/14B) and on tool-calling with rule-based constraints (Qwen2.5-1.5B/3B). By preventing the model from neglecting difficult constraints to exploit easier objectives, RVPO improves overall scores on HealthBench (0.261 vs. 0.215 for GDPO at 14B, $p < 0.001$) and maintains competitive accuracy on GPQA-Diamond without the late-stage degradation observed in other multi-reward methods, demonstrating that variance regularization mitigates constraint neglect across model scales without sacrificing general capabilities.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Reward-Variance Policy Optimization (RVPO), a critic-less RLHF variant that replaces arithmetic-mean reward aggregation with a LogSumExp (SoftMin) operator in advantage estimation. This is motivated as a risk-sensitive shift from maximizing sum to maximizing consistency, derived via Taylor expansion as a smooth inter-reward variance penalty. The method is evaluated on rubric-based medical/scientific reasoning (HealthBench, GPQA-Diamond) with up to 17 concurrent LLM-judged rewards on Qwen2.5-3B/7B/14B models and on tool-calling with rule-based constraints, reporting improved overall HealthBench scores (0.261 vs. 0.215 for GDPO at 14B, p<0.001) and avoidance of late-stage accuracy degradation.
Significance. If the variance-regularization mechanism proves robust, RVPO offers a lightweight, parameter-light extension to existing multi-reward RLHF pipelines that could reduce constraint neglect in safety-critical domains without requiring critics or additional models. The cross-scale empirical results and statistical significance on HealthBench provide concrete evidence of practical benefit, though the approach's generality hinges on untested assumptions about reward scaling and optimization behavior.
major comments (4)
- [§3.2] §3.2 (Taylor-expansion derivation): The claim that LogSumExp implements a smooth variance penalty rests on a first-order expansion around equal rewards; the paper provides neither the explicit expansion steps, bounds on approximation error for realistic reward deviations, nor sensitivity analysis to the implicit temperature parameter, leaving the justification approximate and the effective penalty strength uncharacterized.
- [§4.1] §4.1 (reward setup): No normalization, scaling, or per-reward statistics are reported for the 17 concurrent LLM-judged signals; because LogSumExp is dominated by the largest-magnitude terms, the operator may penalize magnitude imbalance rather than true variance, which directly undermines the central constraint-neglect mitigation claim.
- [§4.2] §4.2 (baseline comparisons): The reported gains versus GDPO lack matched hyperparameter sweeps, identical training schedules, or ablation isolating the aggregation operator; without these controls it is unclear whether the HealthBench improvement and GPQA-Diamond stability arise from variance regularization or from incidental differences in optimization dynamics.
- [§5] §5 (training dynamics): No monitoring of gradient norms, advantage variance, or per-reward contribution trajectories is presented despite the modified advantage estimator; this omission is material given the potential for LogSumExp to induce excessive conservatism or instability when scaling to 17 signals and 14B models.
minor comments (2)
- [Abstract] The abstract states statistical significance but does not specify the exact test (e.g., number of seeds, paired vs. unpaired) or whether multiple-comparison correction was applied.
- [§4] Figure 2 and 3 captions should explicitly state the number of independent runs and whether error bars represent standard deviation or standard error.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, providing clarifications and committing to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Taylor-expansion derivation): The claim that LogSumExp implements a smooth variance penalty rests on a first-order expansion around equal rewards; the paper provides neither the explicit expansion steps, bounds on approximation error for realistic reward deviations, nor sensitivity analysis to the implicit temperature parameter, leaving the justification approximate and the effective penalty strength uncharacterized.
Authors: We agree the derivation in §3.2 would benefit from explicit detail. The revised manuscript will present the complete first-order Taylor steps from the LogSumExp operator around equal rewards, derive the resulting variance penalty term, supply approximation error bounds calibrated to the observed reward deviations in our experiments (typically within [-3, 3] post-normalization), and include a sensitivity study over the temperature parameter β ∈ [0.1, 10] with corresponding HealthBench and GPQA metrics. This will fully characterize the approximation and effective penalty strength. revision: yes
-
Referee: [§4.1] §4.1 (reward setup): No normalization, scaling, or per-reward statistics are reported for the 17 concurrent LLM-judged signals; because LogSumExp is dominated by the largest-magnitude terms, the operator may penalize magnitude imbalance rather than true variance, which directly undermines the central constraint-neglect mitigation claim.
Authors: We acknowledge that normalization details and per-reward statistics were omitted from §4.1. All 17 signals were independently normalized to zero mean and unit variance before aggregation; the revision will report this procedure together with summary statistics (means, variances, and ranges) for each reward. We will also add an ablation comparing normalized versus raw inputs to confirm that the LogSumExp operator targets inter-reward variance rather than scale differences, directly supporting the constraint-neglect mitigation claim. revision: yes
-
Referee: [§4.2] §4.2 (baseline comparisons): The reported gains versus GDPO lack matched hyperparameter sweeps, identical training schedules, or ablation isolating the aggregation operator; without these controls it is unclear whether the HealthBench improvement and GPQA-Diamond stability arise from variance regularization or from incidental differences in optimization dynamics.
Authors: The original comparisons reused the exact training schedule and base hyperparameters from the GDPO reference, changing only the aggregation operator. To strengthen the evidence, the revision will add a hyperparameter sensitivity sweep on learning rate and batch size, plus an explicit ablation that holds all other factors fixed while swapping arithmetic-mean versus LogSumExp aggregation. These controls will isolate the contribution of variance regularization to the HealthBench gains (0.261 vs. 0.215) and GPQA stability. revision: yes
-
Referee: [§5] §5 (training dynamics): No monitoring of gradient norms, advantage variance, or per-reward contribution trajectories is presented despite the modified advantage estimator; this omission is material given the potential for LogSumExp to induce excessive conservatism or instability when scaling to 17 signals and 14B models.
Authors: We agree that dynamics monitoring is essential for validating stability with the modified estimator. The revised §5 will include new figures tracking gradient norms, advantage variance, and per-reward contribution trajectories throughout training for the 14B HealthBench runs. These plots will show that the LogSumExp estimator maintains stable gradients and balanced contributions without inducing excessive conservatism, even at 17 signals. revision: yes
Circularity Check
No significant circularity in RVPO derivation chain
full rationale
The paper derives the LogSumExp operator's variance-penalty behavior directly via Taylor expansion, a standard independent mathematical technique that does not reduce to the target empirical claims or fitted parameters. Central results compare RVPO against external baselines (GDPO) on HealthBench and GPQA-Diamond without any predictions that are statistically forced by construction or that rely on self-citations for load-bearing uniqueness. No self-definitional loops, ansatzes smuggled via prior work, or renaming of known results are present; the derivation remains self-contained against external benchmarks and assumptions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, et al. DeepSeekMath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review arXiv 2024
-
[2]
GDPO: Group reward-Decoupled Normalization Policy Optimization for Multi-reward RL Optimization
Shih-Yang Liu, Xin Dong, Ximing Lu, Shizhe Diao, Peter Belcak, Mingjie Liu, Min-Hung Chen, Hongxu Yin, Yu-Chiang Frank Wang, Kwang-Ting Cheng, et al. GDPO: Group reward- decoupled normalization policy optimization for multi-reward RL optimization.arXiv preprint arXiv:2601.05242, 2026
work page internal anchor Pith review arXiv 2026
-
[3]
Constrained policy optimization
Joshua Achiam, David Held, Aviv Tamar, and Pieter Abbeel. Constrained policy optimization. InInternational conference on machine learning, pages 22–31. Pmlr, 2017
2017
-
[4]
Safe RLHF: Safe Reinforcement Learning from Human Feedback
Josef Dai, Xuehai Pan, Ruiyang Sun, Jiaming Ji, Xinbo Xu, Mickel Liu, Yizhou Wang, and Yaodong Yang. Safe RLHF: Safe reinforcement learning from human feedback.arXiv preprint arXiv:2310.12773, 2023
work page internal anchor Pith review arXiv 2023
-
[5]
Rewarded soups: towards pareto-optimal align- ment by interpolating weights fine-tuned on diverse rewards.Advances in Neural Information Processing Systems, 36:71095–71134, 2023
Alexandre Rame, Guillaume Couairon, Corentin Dancette, Jean-Baptiste Gaya, Mustafa Shukor, Laure Soulier, and Matthieu Cord. Rewarded soups: towards pareto-optimal align- ment by interpolating weights fine-tuned on diverse rewards.Advances in Neural Information Processing Systems, 36:71095–71134, 2023
2023
-
[6]
Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
2022
-
[7]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. Advances in neural information processing systems, 36:53728–53741, 2023
2023
-
[8]
The accuracy paradox in RLHF: When better reward models don’t yield better language models
Yanjun Chen, Dawei Zhu, Yirong Sun, Xinghao Chen, Wei Zhang, and Xiaoyu Shen. The accuracy paradox in RLHF: When better reward models don’t yield better language models. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 2980–2989, 2024
2024
-
[9]
Juntao Dai, Taiye Chen, Yaodong Yang, Qian Zheng, and Gang Pan. Mitigating re- ward over-optimization in RLHF via behavior-supported regularization.arXiv preprint arXiv:2503.18130, 2025
-
[10]
Scaling laws for reward model overoptimization
Leo Gao, John Schulman, and Jacob Hilton. Scaling laws for reward model overoptimization. InInternational Conference on Machine Learning, pages 10835–10866. PMLR, 2023
2023
-
[11]
SimPO: Simple preference optimization with a reference-free reward.Advances in Neural Information Processing Systems, 37:124198– 124235, 2024
Yu Meng, Mengzhou Xia, and Danqi Chen. SimPO: Simple preference optimization with a reference-free reward.Advances in Neural Information Processing Systems, 37:124198– 124235, 2024
2024
-
[12]
Disentangling length from quality in direct preference optimization
Ryan Park, Rafael Rafailov, Stefano Ermon, and Chelsea Finn. Disentangling length from quality in direct preference optimization. InFindings of the Association for Computational Linguistics: ACL 2024, pages 4998–5017, 2024
2024
-
[13]
ODIN: Disentangled reward mitigates hacking in RLHF.arXiv preprint arXiv:2402.07319, 2024
Lichang Chen, Chen Zhu, Davit Soselia, Jiuhai Chen, Tianyi Zhou, Tom Goldstein, Heng Huang, Mohammad Shoeybi, and Bryan Catanzaro. ODIN: Disentangled reward mitigates hacking in RLHF.arXiv preprint arXiv:2402.07319, 2024. 10
-
[14]
Rubrics as Rewards: Reinforcement Learning Beyond Verifiable Domains
Anisha Gunjal, Anthony Wang, Elaine Lau, Vaskar Nath, Yunzhong He, Bing Liu, and Sean Hendryx. Rubrics as rewards: Reinforcement learning beyond verifiable domains.arXiv preprint arXiv:2507.17746, 2025
work page internal anchor Pith review arXiv 2025
-
[15]
LLM- rubric: A multidimensional, calibrated approach to automated evaluation of natural language texts
Helia Hashemi, Jason Eisner, Corby Rosset, Benjamin Van Durme, and Chris Kedzie. LLM- rubric: A multidimensional, calibrated approach to automated evaluation of natural language texts. InProceedings of the 62nd Annual Meeting of the Association for Computational Lin- guistics (Volume 1: Long Papers), pages 13806–13834, 2024
2024
-
[16]
HelpSteer 2: Open-source dataset for training top-performing reward models.Advances in Neural Information Processing Systems, 37:1474–1501, 2024
Zhilin Wang, Yi Dong, Olivier Delalleau, Jiaqi Zeng, Gerald Shen, Daniel Egert, Jimmy J Zhang, Makesh N Sreedhar, and Oleksii Kuchaiev. HelpSteer 2: Open-source dataset for training top-performing reward models.Advances in Neural Information Processing Systems, 37:1474–1501, 2024
2024
-
[17]
In: NeurIPS (2025),https://arxiv.org/abs/2507.18624
Vijay Viswanathan, Yanchao Sun, Shuang Ma, Xiang Kong, Meng Cao, Graham Neubig, and Tongshuang Wu. Checklists are better than reward models for aligning language models.arXiv preprint arXiv:2507.18624, 2025
-
[18]
Rule based rewards for language model safety.Advances in Neural Information Processing Systems, 37:108877–108901, 2024
Tong Mu, Alec Helyar, Johannes Heidecke, Joshua Achiam, Andrea Vallone, Ian Kivlichan, Molly Lin, Alex Beutel, John Schulman, and Lilian Weng. Rule based rewards for language model safety.Advances in Neural Information Processing Systems, 37:108877–108901, 2024
2024
-
[19]
Xuying Li, Zhuo Li, Yuji Kosuga, and Victor Bian. Optimizing safe and aligned language generation: A multi-objective GRPO approach.arXiv preprint arXiv:2503.21819, 2025
-
[20]
A practical guide to multi-objective reinforcement learning and planning.Au- tonomous Agents and Multi-Agent Systems, 36(1):26, 2022
Conor F Hayes, Roxana R ˘adulescu, Eugenio Bargiacchi, Johan K ¨allstr¨om, Matthew Macfar- lane, Mathieu Reymond, Timothy Verstraeten, Luisa M Zintgraf, Richard Dazeley, Fredrik Heintz, et al. A practical guide to multi-objective reinforcement learning and planning.Au- tonomous Agents and Multi-Agent Systems, 36(1):26, 2022
2022
-
[21]
Multi-objective large language model alignment with hierarchical experts
Zhuo Li, Guodong Du, Weiyang Guo, Yigeng Zhou, Xiucheng Li, Wenya Wang, Fangming Liu, Yequan Wang, Deheng Ye, Min Zhang, et al. Multi-objective large language model align- ment with hierarchical experts.arXiv preprint arXiv:2505.20925, 2025
-
[22]
Kihyun Kim, Jiawei Zhang, Asuman Ozdaglar, and Pablo A Parrilo. Beyond RLHF and NLHF: Population-proportional alignment under an axiomatic framework.arXiv preprint arXiv:2506.05619, 2025
-
[23]
Constrained reinforcement learning has zero duality gap.Advances in Neural Information Processing Sys- tems, 32, 2019
Santiago Paternain, Luiz Chamon, Miguel Calvo-Fullana, and Alejandro Ribeiro. Constrained reinforcement learning has zero duality gap.Advances in Neural Information Processing Sys- tems, 32, 2019
2019
-
[24]
Reward-free alignment for conflicting objectives.arXiv preprint arXiv:2602.02495, 2026
Peter L Chen, Xiaopeng Li, Xi Chen, and Tianyi Lin. Reward-free alignment for conflicting objectives.arXiv preprint arXiv:2602.02495, 2026
-
[25]
Multi-attribute steering of language models via targeted intervention
Duy Nguyen, Archiki Prasad, Elias Stengel-Eskin, and Mohit Bansal. Multi-attribute steering of language models via targeted intervention. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 20619–20634, 2025
2025
-
[26]
Parm: Multi-objective test-time alignment via preference-aware autoregressive reward model
Baijiong Lin, Weisen Jiang, Yuancheng Xu, Hao Chen, and Ying-Cong Chen. PARM: Multi-objective test-time alignment via preference-aware autoregressive reward model.arXiv preprint arXiv:2505.06274, 2025
-
[27]
Back to basics: Revisiting reinforce-style optimiza- tion for learning from human feedback in llms
Arash Ahmadian, Chris Cremer, Matthias Gall ´e, Marzieh Fadaee, Julia Kreutzer, Olivier Pietquin, Ahmet ¨Ust¨un, and Sara Hooker. Back to basics: Revisiting reinforce-style optimiza- tion for learning from human feedback in llms. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 12248–...
2024
-
[28]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025. 11
work page internal anchor Pith review arXiv 2025
-
[29]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. DAPO: An open-source LLM reinforcement learning system at scale.arXiv preprint arXiv:2503.14476, 2025
work page internal anchor Pith review arXiv 2025
-
[30]
Risk-sensitive markov decision processes.Man- agement science, 18(7):356–369, 1972
Ronald A Howard and James E Matheson. Risk-sensitive markov decision processes.Man- agement science, 18(7):356–369, 1972
1972
-
[31]
A tighter problem-dependent regret bound for risk-sensitive reinforcement learning
Xiaoyan Hu and Ho-fung Leung. A tighter problem-dependent regret bound for risk-sensitive reinforcement learning. InInternational Conference on Artificial Intelligence and Statistics, pages 5411–5437. PMLR, 2023
2023
-
[32]
Risk- sensitive deep RL: Variance-constrained actor-critic provably finds globally optimal policy
Han Zhong, Xun Deng, Ethan X Fang, Zhuoran Yang, Zhaoran Wang, and Runze Li. Risk- sensitive deep RL: Variance-constrained actor-critic provably finds globally optimal policy. Journal of the American Statistical Association, pages 1–26, 2025
2025
-
[33]
An alternative softmax operator for reinforcement learning
Kavosh Asadi and Michael L Littman. An alternative softmax operator for reinforcement learning. InInternational Conference on Machine Learning, pages 243–252. PMLR, 2017
2017
-
[34]
ToolRL: Reward is All Tool Learning Needs
Cheng Qian, Emre Can Acikgoz, Qi He, Hongru Wang, Xiusi Chen, Dilek Hakkani-T ¨ur, Gokhan Tur, and Heng Ji. ToolRL: Reward is all tool learning needs.arXiv preprint arXiv:2504.13958, 2025
work page internal anchor Pith review arXiv 2025
-
[35]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, et al. Qwen2.5 technical report.arXiv preprint arXiv:2412.15115, 2024
work page internal anchor Pith review arXiv 2024
-
[36]
HybridFlow: A Flexible and Efficient RLHF Framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework.arXiv preprint arXiv: 2409.19256, 2024
work page internal anchor Pith review arXiv 2024
-
[37]
Patil, Huanzhi Mao, Charlie Cheng-Jie Ji, Fanjia Yan, Vishnu Suresh, Ion Stoica, and Joseph E
Shishir G. Patil, Huanzhi Mao, Charlie Cheng-Jie Ji, Fanjia Yan, Vishnu Suresh, Ion Stoica, and Joseph E. Gonzalez. The Berkeley Function Calling Leaderboard (BFCL): From tool use to agentic evaluation of large language models. InForty-second International Conference on Machine Learning, 2025
2025
-
[38]
HealthBench: Evaluating Large Language Models Towards Improved Human Health
Rahul K Arora, Jason Wei, Rebecca Soskin Hicks, Preston Bowman, Joaquin Qui ˜nonero- Candela, Foivos Tsimpourlas, Michael Sharman, Meghan Shah, Andrea Vallone, Alex Beutel, et al. HealthBench: Evaluating large language models towards improved human health.arXiv preprint arXiv:2505.08775, 2025
work page internal anchor Pith review arXiv 2025
-
[39]
GPQA: A graduate-level Google-proof Q&A benchmark
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R Bowman. GPQA: A graduate-level Google-proof Q&A benchmark. InFirst conference on language modeling, 2024. 12 A Appendix A.1 RVPO Algorithm Algorithm 1 summarizes the full RVPO training procedure, including per-channel Z-normaliz...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.