Recognition: no theorem link
Benchmarking EngGPT2-16B-A3B against Comparable Italian and International Open-source LLMs
Pith reviewed 2026-05-11 03:35 UTC · model grok-4.3
The pith
EngGPT2MoE-16B-A3B matches or exceeds other Italian open-source LLMs on most benchmarks while trailing some top international models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
EngGPT2MoE-16B-A3B performs as well or better than the compared Italian models on international benchmarks and the longest-context RULER setting, exceeds DeepSeek-MoE-16B-Chat on all tests, and when scores are combined across every benchmark shows higher overall performance than other Italian models under evaluation while remaining below certain leading international models.
What carries the argument
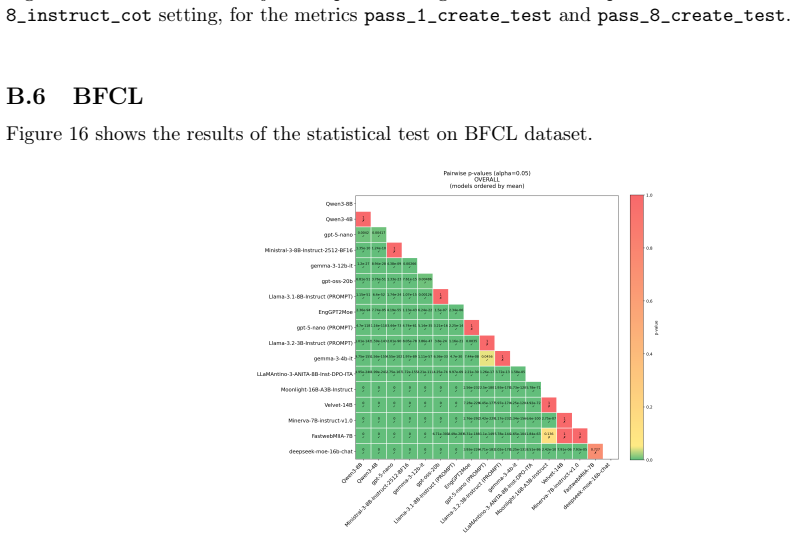
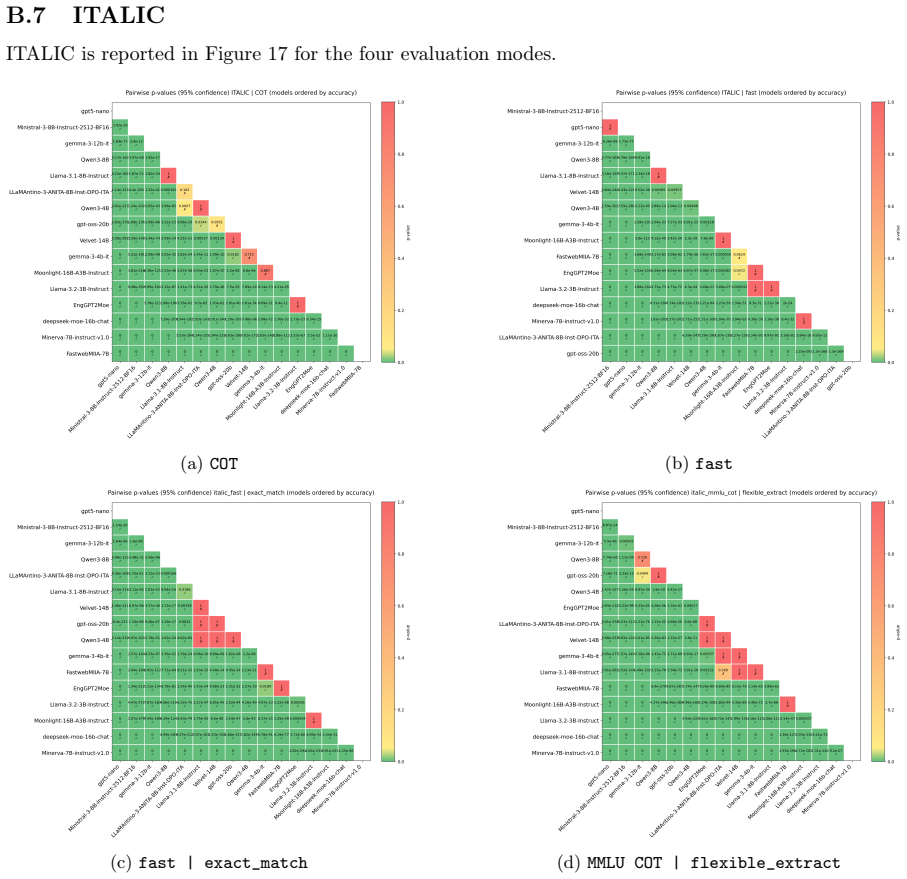
Side-by-side performance comparison of the 16B MoE model against other MoE and dense models on a fixed suite of benchmarks that includes ARC-Challenge, GSM8K, AIME24/25, MMLU, HumanEval, ITALIC, BFCL, and RULER at multiple context lengths.
If this is right
- Native Italian developers gain a stronger open starting point than prior models for further fine-tuning or deployment.
- Mixture-of-Experts scaling at the 16B total / 3B active size can deliver competitive results on both general and language-specific tasks.
- Continued investment in Italian training data and evaluation sets is likely to produce further gains in local model quality.
Where Pith is reading between the lines
- The remaining gap to the strongest international models suggests that larger Italian-specific datasets or longer training runs could close performance differences.
- Repeating the same benchmark protocol on other low-resource languages could test whether the observed pattern of steady local improvement holds more broadly.
- Industry users needing Italian-language capabilities may now prefer this model over earlier open alternatives for production tasks.
Load-bearing premise
The chosen benchmarks and the set of comparison models give a fair, unbiased, and sufficiently complete view of the model's capabilities, especially on Italian-specific tasks and under identical evaluation conditions.
What would settle it
A standardized Italian-language benchmark focused on cultural or idiomatic content where EngGPT2MoE-16B-A3B scores below all the Italian models it currently leads would undermine the claim that it constitutes a step forward.
Figures
















read the original abstract
This report benchmarks the performance of ENGINEERING Ingegneria Informatica S.p.A.'s EngGPT2MoE-16B-A3B LLM, a 16B parameter Mixture of Experts (MoE) model with 3B active parameters. Performance is investigated across a wide variety of representative benchmarks, and is compared against comparably-sized open-source MoE and dense models. In comparison with popular Italian models, namely FastwebMIIA-7B, Minerva-7B, Velvet-14B, and LLaMAntino-3-ANITA-8B, EngGPT2MoE-16B-A3B performs as well or better on international benchmarks: ARC-Challenge, GSM8K, AIME24, AIME25, MMLU, and HumanEval (HE). It achieves the best performance for the longest context setting (32k) of the RULER benchmark. On the Italian benchmark dataset ITALIC, the model performs as well or better than the other models except for Velvet-14B, which outperforms it. Compared with popular MoE models of comparable size, the new model reports higher values than DeepSeek-MoE-16B-Chat on all considered benchmarks. It has higher values than Moonlight-16B-A3B on HE, MMLU, AIME24, AIME25, GSM8K, and the 32k RULER setting, but lower on BFCL and some ARC and ITALIC settings. Finally it has lower values than GPT-OSS-20B on most benchmarks, including HE, MMLU, AIME24, AIME25, GSM8K, ARC, BFCL, and the RULER 32k. When compared with popular dense models, EngGPT2MoE-16B-A3B reports higher values on AIME24 and AIME25 than Llama-3.1-8B-Instruct, Gemma-3-12b-it, and Ministral-3-8BInstruct-2512-BF16, but lower values on ITALIC, BFCL, and RULER with a 32k context. When performance is aggregated across all benchmark metrics, EngGPT2MoE-16B-A3B shows higher performance than the Italian models under evaluation while achieving lower results than some of the most performant international models, in particular GPT-5 nano and Qwen3-8B. Taken together, our findings find the new model to be a step forward for native Italian Large Language Models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript benchmarks EngGPT2MoE-16B-A3B, a 16B-parameter Mixture-of-Experts model with 3B active parameters, against Italian models (FastwebMIIA-7B, Minerva-7B, Velvet-14B, LLaMAntino-3-ANITA-8B) and international open-source models (DeepSeek-MoE-16B-Chat, Moonlight-16B-A3B, GPT-OSS-20B, Llama-3.1-8B-Instruct, Gemma-3-12b-it, Ministral-3-8B-Instruct) on ARC-Challenge, GSM8K, AIME24, AIME25, MMLU, HumanEval, BFCL, RULER (including 32k context), and the Italian ITALIC benchmark. It reports that the new model matches or exceeds the Italian comparators on most international tasks, leads on RULER 32k, trails Velvet-14B on ITALIC, outperforms DeepSeek-MoE on all tasks, is mixed versus Moonlight, trails GPT-OSS-20B on most metrics, and shows mixed results versus dense models, concluding that the model constitutes a step forward for native Italian LLMs.
Significance. If the reported scores reflect standardized evaluation conditions, the work supplies concrete comparative data on a new Italian MoE architecture, documenting relative strengths in mathematical reasoning and long-context handling that could guide subsequent Italian-language model development.
major comments (3)
- [Evaluation section] Evaluation section: The manuscript provides no information on whether benchmark scores for the comparison models were obtained by re-evaluating them inside the same inference harness, using identical prompt templates, few-shot counts, decoding parameters (temperature, top-p), and post-processing as applied to EngGPT2MoE-16B-A3B. Because the abstract and results sections rest the central claim of being “a step forward” entirely on these relative numbers, the absence of this protocol detail is load-bearing.
- [Results section] Results section and associated tables: No error bars, standard deviations, or statistical tests are reported for any per-benchmark or aggregated scores. Claims such as “performs as well or better,” “higher values,” and “higher performance than the Italian models” therefore cannot be assessed for reliability when differences may be within normal run-to-run variation.
- [Results section] Results section: The aggregation procedure used to conclude that EngGPT2MoE-16B-A3B shows “higher performance than the Italian models under evaluation” is not described; it is unclear which subset of metrics is included, how they are normalized or weighted, and whether every model was scored on exactly the same task instances.
minor comments (2)
- [Abstract] Abstract: The title uses “EngGPT2-16B-A3B” while the body consistently uses “EngGPT2MoE-16B-A3B”; a single consistent name would reduce reader confusion.
- [Results section] Results section: The paper would benefit from an explicit limitations paragraph addressing the scope of Italian-specific evaluation (only ITALIC is used) and the reliance on public benchmark scores for some comparators.
Simulated Author's Rebuttal
We thank the referee for their thorough and constructive review. The comments identify important gaps in methodological transparency that we will address in the revision. Below we respond point by point to the major comments.
read point-by-point responses
-
Referee: [Evaluation section] Evaluation section: The manuscript provides no information on whether benchmark scores for the comparison models were obtained by re-evaluating them inside the same inference harness, using identical prompt templates, few-shot counts, decoding parameters (temperature, top-p), and post-processing as applied to EngGPT2MoE-16B-A3B. Because the abstract and results sections rest the central claim of being “a step forward” entirely on these relative numbers, the absence of this protocol detail is load-bearing.
Authors: We agree that explicit documentation of the shared evaluation protocol is necessary to support the comparative claims. All models were evaluated under identical conditions using the EleutherAI lm-evaluation-harness (v0.4.2) with the same prompt templates, few-shot counts, decoding parameters (temperature=0.0 for deterministic generation on most tasks, top-p=1.0), and post-processing scripts. We will add a dedicated paragraph in the Evaluation section describing the full protocol, the exact version of the harness, and confirmation that every comparator was run through this pipeline rather than relying solely on published numbers. revision: yes
-
Referee: [Results section] Results section and associated tables: No error bars, standard deviations, or statistical tests are reported for any per-benchmark or aggregated scores. Claims such as “performs as well or better,” “higher values,” and “higher performance than the Italian models” therefore cannot be assessed for reliability when differences may be within normal run-to-run variation.
Authors: We acknowledge that the absence of variability measures limits the strength of the “as well or better” claims. All reported numbers reflect single runs because of the prohibitive cost of repeated inference across 16B-scale models on the full benchmark suite. In the revision we will add an explicit limitations paragraph stating this constraint, note that performance advantages appear consistently across nine distinct benchmarks, and include any available multi-seed results for the smaller tasks (e.g., GSM8K) where they were obtained. We will also qualify the language in the abstract and results to reflect the single-run nature of the data. revision: partial
-
Referee: [Results section] Results section: The aggregation procedure used to conclude that EngGPT2MoE-16B-A3B shows “higher performance than the Italian models under evaluation” is not described; it is unclear which subset of metrics is included, how they are normalized or weighted, and whether every model was scored on exactly the same task instances.
Authors: We apologize for the missing description. The aggregate comparison was obtained by (i) restricting to the nine tasks evaluated for every model (ARC-Challenge, GSM8K, AIME24, AIME25, MMLU, HumanEval, BFCL, RULER-32k, ITALIC), (ii) min-max normalizing each metric across the Italian models only, and (iii) averaging the normalized scores. All models were scored on identical task instances and splits. We will insert a precise description of this procedure, list the exact metrics, and add an appendix table showing the per-metric normalized values and the final aggregate for transparency. revision: yes
Circularity Check
No circularity: pure empirical benchmarking with external scores
full rationale
The paper contains no derivations, equations, fitted parameters, or self-referential logic. Its claims consist entirely of direct comparisons of benchmark scores (ARC-Challenge, GSM8K, MMLU, ITALIC, RULER, etc.) against other models. These scores are treated as external inputs; the paper performs no internal fitting, prediction, or re-derivation that could reduce a result to its own inputs by construction. Self-citations, if present, are not load-bearing for any central claim. The argument is therefore self-contained as a report of observed performance differences.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Language Models are Few-Shot Learners
Tom Brown et al. “Language Models are Few-Shot Learners”. In:Advances in Neural Information Processing Systems. Ed. by H. Larochelle et al. Vol. 33. Curran Associates, Inc., 2020, pp. 1877– 1901
work page 2020
-
[2]
Ashish Vaswani et al. “Attention is all you need”. In:Advances in neural information processing systems30 (2017)
work page 2017
-
[3]
Advances in machine translation: A comprehensive survey of large language models
Devalla Bhaskar Ganesh et al. “Advances in machine translation: A comprehensive survey of large language models”. In:2025 3rd International Conference on Intelligent Data Communication Tech- nologies and Internet of Things (IDCIoT). IEEE. 2025, pp. 1671–1675
work page 2025
-
[4]
Tear:Improvingllm-basedmachinetranslationwithsystematicself-refinement
ZhaopengFengetal.“Tear:Improvingllm-basedmachinetranslationwithsystematicself-refinement”. In:Findings of the Association for Computational Linguistics: NAACL 2025. 2025, pp. 3922–3938
work page 2025
-
[5]
A survey of large language model agents for question answering
Murong Yue. “A survey of large language model agents for question answering”. In:arXiv preprint arXiv:2503.19213(2025)
-
[6]
arXiv preprint arXiv:2408.12599, 2024
Xun Liang et al. “Controllable text generation for large language models: A survey”. In:arXiv preprint arXiv:2408.12599(2024)
-
[7]
A survey on large language model (llm) security and privacy: The good, the bad, and the ugly
Yifan Yao et al. “A survey on large language model (llm) security and privacy: The good, the bad, and the ugly”. In:High-Confidence Computing4.2 (2024), p. 100211
work page 2024
-
[8]
Small language models: Survey, measurements, and insights.arXiv preprint arXiv:2409.15790, 2024
Zhenyan Lu et al. “Small language models: Survey, measurements, and insights”. In:arXiv preprint arXiv:2409.15790(2024)
-
[9]
Training Compute-Optimal Large Language Models
Jordan Hoffmann et al. “Training compute-optimal large language models”. In:arXiv preprint arXiv:2203.1555610 (2022). 23 Figure 8: Average of the accuracy score of models across the various benchmarks datasets. Each bench- mark contributes equally to the overall average. For each benchmark, the Accuracy score of the model on each metric is first averaged,...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[10]
Finetuned Language Models Are Zero-Shot Learners
JasonWeietal.“Finetunedlanguagemodelsarezero-shotlearners”.In:arXiv preprint arXiv:2109.01652 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[11]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Jason Wei et al. “Chain-of-Thought Prompting Elicits Reasoning in Large Language Models”. In: Advances in Neural Information Processing Systems35 (2022)
work page 2022
-
[12]
Training Language Models to Follow Instructions with Human Feedback
Long Ouyang et al. “Training Language Models to Follow Instructions with Human Feedback”. In: Advances in Neural Information Processing Systems35 (2022)
work page 2022
-
[13]
Scaling instruction-finetuned language models
Hyung Won Chung et al. “Scaling instruction-finetuned language models”. In:Journal of Machine Learning Research25.70 (2024), pp. 1–53
work page 2024
-
[14]
Toolformer: Language models can teach themselves to use tools
Timo Schick et al. “Toolformer: Language models can teach themselves to use tools”. In:Advances in neural information processing systems36 (2023), pp. 68539–68551
work page 2023
-
[15]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Guanzhi Wang et al. “Voyager: An open-ended embodied agent with large language models”. In: arXiv preprint arXiv:2305.16291(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
LongRoPE: Extending LLM Context Window Beyond 2 Million Tokens
Yiran Ding et al. “Longrope: Extending llm context window beyond 2 million tokens”. In:arXiv preprint arXiv:2402.13753(2024)
work page internal anchor Pith review arXiv 2024
-
[17]
Gqa: Training generalized multi-query transformer models from multi-head checkpoints
Joshua Ainslie et al. “Gqa: Training generalized multi-query transformer models from multi-head checkpoints”. In:Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023, pp. 4895–4901
work page 2023
-
[18]
Sliding window attention training for efficient large language models
Zichuan Fu et al. “Sliding window attention training for efficient large language models”. In:arXiv preprint arXiv:2502.18845(2025)
-
[19]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Noam Shazeer et al. “OUTRAGEOUSLY LARGE NEURAL NETWORKS: THE SPARSELY- GATED MIXTURE-OF-EXPERTS LAYER”. In:International Conference on Learning Represen- tations. 2017.doi:1701.06538’
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[20]
Switch Transformers: Scaling to Trillion Param- eter Models with Simple and Efficient Sparsity
William Fedus, Barret Zoph, and Noam Shazeer. “Switch Transformers: Scaling to Trillion Param- eter Models with Simple and Efficient Sparsity”. In:Journal of Machine Learning Research23.120 (2022), pp. 1–39
work page 2022
-
[21]
GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
Dmitry Lepikhin et al. “GShard: Scaling Giant Models with Conditional Computation and Auto- matic Sharding”. In:arXiv preprint arXiv:2006.16668(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[22]
Ciarfaglia et al.EngGPT2: Sovereign, Efficient and Open Intelligence
G. Ciarfaglia et al.EngGPT2: Sovereign, Efficient and Open Intelligence. 2026. arXiv:2603.16430 [cs.CL].url:https://arxiv.org/abs/2603.16430. 24
-
[23]
Minerva LLMs: The First Family of Large Language Models Trained from ScratchonItalianData
Riccardo Orlando et al. “Minerva LLMs: The First Family of Large Language Models Trained from ScratchonItalianData”.In:Proceedings of the Tenth Italian Conference on Computational Linguis- tics (CLiC-it 2024). Ed. by Felice Dell’Orletta et al. Pisa, Italy: CEUR Workshop Proceedings, Dec. 2024, pp. 707–719.isbn: 979-12-210-7060-6.url:https://aclanthology.o...
work page 2024
-
[24]
Advanced natural-based interaction for the italian language: Llamantino-3-anita
Marco Polignano, Pierpaolo Basile, and Giovanni Semeraro. “Advanced natural-based interaction for the italian language: Llamantino-3-anita”. In:Scientific Reports(2026)
work page 2026
-
[25]
An Yang et al. “Qwen3 technical report”. In:arXiv preprint arXiv:2505.09388(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Aaron Grattafiori et al. “The llama 3 herd of models”. In:arXiv preprint arXiv:2407.21783(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Alexander H. Liu et al.Ministral 3. 2026. arXiv:2601.08584 [cs.CL].url:https://arxiv.org/ abs/2601.08584
work page internal anchor Pith review arXiv 2026
-
[28]
Gemma Team et al.Gemma 3 Technical Report. 2025. arXiv:2503.19786 [cs.CL].url:https: //arxiv.org/abs/2503.19786
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Deepseekmoe: Towards ultimate expert specialization in mixture-of-experts lan- guage models
Damai Dai et al. “Deepseekmoe: Towards ultimate expert specialization in mixture-of-experts lan- guage models”. In:Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024, pp. 1280–1297
work page 2024
-
[30]
gpt-oss-120b & gpt-oss-20b Model Card
SandhiniAgarwaletal.“gpt-oss-120b&gpt-oss-20bmodelcard”.In:arXiv preprint arXiv:2508.10925 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Muon is Scalable for LLM Training
Jingyuan Liu et al. “Muon is scalable for llm training”. In:arXiv preprint arXiv:2502.16982(2025)
work page internal anchor Pith review arXiv 2025
-
[32]
Towards Reasoning Era: A Survey of Long Chain-of-Thought for Reasoning Large Language Models
Qiguang Chen et al. “Towards reasoning era: A survey of long chain-of-thought for reasoning large language models”. In:arXiv preprint arXiv:2503.09567(2025)
work page internal anchor Pith review arXiv 2025
-
[33]
Toward large reasoning models: A survey of reinforced reasoning with large language models
Fengli Xu et al. “Toward large reasoning models: A survey of reinforced reasoning with large language models”. In:Patterns6.10 (2025)
work page 2025
-
[34]
Gorilla: Large Language Model Connected with Massive APIs
Shishir G Patil et al. “Gorilla: Large language model connected with massive apis, 2023”. In:URL https://arxiv. org/abs/2305.15334(2023)
work page internal anchor Pith review arXiv 2023
-
[35]
Yifan Song et al. “Restgpt: Connecting large language models with real-world restful apis”. In: arXiv preprint arXiv:2306.06624(2023)
-
[36]
Art of Problem Solving Wiki, accessed July 2025
AIME.2024 AIME I. Art of Problem Solving Wiki, accessed July 2025. 2024.url:https : / / artofproblemsolving.com/wiki/index.php/2024_AIME_I
work page 2024
-
[37]
AIME.2025 AIME I. Art of Problem Solving Wiki. Held February 6, 2025. 2025.url:https: //artofproblemsolving.com/wiki/index.php/2025_AIME_I
work page 2025
-
[38]
Alignbench: Benchmarking chinese alignment of large language models
Xiao Liu et al. “Alignbench: Benchmarking chinese alignment of large language models”. In:Pro- ceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024, pp. 11621–11640
work page 2024
-
[39]
Api-bank: A comprehensive benchmark for tool-augmented llms
Minghao Li et al. “Api-bank: A comprehensive benchmark for tool-augmented llms”. In:Proceedings of the 2023 conference on empirical methods in natural language processing. 2023, pp. 3102–3116
work page 2023
-
[40]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark et al. “Think you have solved question answering? try arc, the ai2 reasoning challenge”. In:arXiv preprint arXiv:1803.05457(2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[41]
Tianle Li et al. “From crowdsourced data to high-quality benchmarks: Arena-hard and benchbuilder pipeline”. In:arXiv preprint arXiv:2406.11939(2024)
-
[42]
Qin Zhu et al. “Autologi: Automated generation of logic puzzles for evaluating reasoning abilities of large language models”. In:arXiv preprint arXiv:2502.16906(2025)
-
[43]
Shishir G Patil et al. “The berkeley function calling leaderboard (bfcl): From tool use to agen- tic evaluation of large language models”. In:Forty-second International Conference on Machine Learning. 2025
work page 2025
-
[44]
C-eval: A multi-level multi-discipline chinese evaluation suite for foundation models
Yuzhen Huang et al. “C-eval: A multi-level multi-discipline chinese evaluation suite for foundation models”. In:Advances in neural information processing systems36 (2023), pp. 62991–63010
work page 2023
-
[45]
ChID: A large-scale Chinese IDiom dataset for cloze test
Chujie Zheng, Minlie Huang, and Aixin Sun. “ChID: A large-scale Chinese IDiom dataset for cloze test”. In:Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019, pp. 778–787. 25
work page 2019
-
[46]
CLUE: A Chinese Language Understanding Evaluation Benchmark
Liang Xu et al. “CLUE: A Chinese Language Understanding Evaluation Benchmark”. In:Pro- ceedings of the 28th International Conference on Computational Linguistics. Ed. by Donia Scott, Nuria Bel, and Chengqing Zong. Barcelona, Spain (Online): International Committee on Compu- tational Linguistics, Dec. 2020, pp. 4762–4772.doi:10.18653/v1/2020.coling-main.41...
-
[47]
Cmmlu: Measuring massive multitask language understanding in chinese
Haonan Li et al. “Cmmlu: Measuring massive multitask language understanding in chinese”. In: Findings of the Association for Computational Linguistics: ACL 2024. 2024, pp. 11260–11285
work page 2024
-
[48]
Shanghaoran Quan et al. “Codeelo: Benchmarking competition-level code generation of llms with human-comparable elo ratings”. In:arXiv preprint arXiv:2501.01257(2025)
-
[49]
DROP: A reading comprehension benchmark requiring discrete reasoning over paragraphs
Dheeru Dua et al. “DROP: A reading comprehension benchmark requiring discrete reasoning over paragraphs”. In:Proceedings of the 2019 Conference of the North American Chapter of the Asso- ciation for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019, pp. 2368–2378
work page 2019
-
[50]
Gorilla: Large language model connected with massive apis
Shishir G Patil et al. “Gorilla: Large language model connected with massive apis”. In:Advances in Neural Information Processing Systems37 (2024), pp. 126544–126565
work page 2024
-
[51]
Gpqa: A graduate-level google-proof q&a benchmark
David Rein et al. “Gpqa: A graduate-level google-proof q&a benchmark”. In:First conference on language modeling. 2024
work page 2024
-
[52]
Training Verifiers to Solve Math Word Problems
KarlCobbeetal.“Trainingverifierstosolvemathwordproblems”.In:arXiv preprint arXiv:2110.14168 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[53]
HealthBench: Evaluating Large Language Models Towards Improved Human Health
Rahul K Arora et al. “Healthbench: Evaluating large language models towards improved human health”. In:arXiv preprint arXiv:2505.08775(2025)
work page internal anchor Pith review arXiv 2025
-
[54]
Hellaswag: Can a machine really finish your sentence?
Rowan Zellers et al. “Hellaswag: Can a machine really finish your sentence?” In:Proceedings of the 57th annual meeting of the association for computational linguistics. 2019, pp. 4791–4800
work page 2019
-
[55]
Long Phan et al. “Humanity’s last exam”. In:arXiv preprint arXiv:2501.14249(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[56]
Evaluating Large Language Models Trained on Code
MarkChenetal.“Evaluatinglargelanguagemodelstrainedoncode”.In:arXiv preprint arXiv:2107.03374 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[57]
Instruction-Following Evaluation for Large Language Models
Jeffrey Zhou et al. “Instruction-following evaluation for large language models”. In:arXiv preprint arXiv:2311.07911(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[58]
arXiv preprint arXiv:2411.19799 , year=
Angelika Romanou et al. “Include: Evaluating multilingual language understanding with regional knowledge”. In:arXiv preprint arXiv:2411.19799(2024)
-
[59]
∞Bench: Extending long context evaluation beyond 100K tokens
Xinrong Zhang et al. “∞Bench: Extending long context evaluation beyond 100K tokens”. In:Pro- ceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024, pp. 15262–15277
work page 2024
-
[60]
LiveBench: A Challenging, Contamination-Limited LLM Benchmark
ColinWhiteetal.“Livebench:Achallenging,contamination-freellmbenchmark”.In:arXiv preprint arXiv:2406.193144 (2024), p. 2
work page internal anchor Pith review arXiv 2024
-
[61]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
Naman Jain et al. “Livecodebench: Holistic and contamination free evaluation of large language models for code”. In:arXiv preprint arXiv:2403.07974(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[62]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks et al. “Measuring mathematical problem solving with the math dataset”. In:arXiv preprint arXiv:2103.03874(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[63]
Hunter Lightman et al. “Let’s verify step by step”. In:The twelfth international conference on learning representations. 2023
work page 2023
-
[64]
Jiawei Liu et al. “Is your code generated by chatgpt really correct? rigorous evaluation of large language models for code generation”. In:Advances in neural information processing systems36 (2023), pp. 21558–21572
work page 2023
-
[65]
Language models are multi- lingual chain-of-thought reasoners,
Freda Shi et al. “Language models are multilingual chain-of-thought reasoners”. In:arXiv preprint arXiv:2210.03057(2022)
-
[66]
P-mmeval: A parallel multilingual multitask benchmark for consistent evalu- ation of llms
Yidan Zhang et al. “P-mmeval: A parallel multilingual multitask benchmark for consistent evalu- ation of llms”. In:Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025, pp. 4809–4836
work page 2025
-
[67]
Measuring Massive Multitask Language Understanding
Dan Hendrycks et al. “Measuring massive multitask language understanding”. In:arXiv preprint arXiv:2009.03300(2020). 26
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[68]
Mmlu-pro: A more robust and challenging multi-task language understanding benchmark
Yubo Wang et al. “Mmlu-pro: A more robust and challenging multi-task language understanding benchmark”. In:Advances in Neural Information Processing Systems37 (2024), pp. 95266–95290
work page 2024
-
[69]
Aryo Pradipta Gema et al. “Are we done with mmlu?” In:Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2025, pp. 5069–5096
work page 2025
-
[70]
arXiv preprint arXiv:2410.15553 , year=
Yun He et al. “Multi-if: Benchmarking llms on multi-turn and multilingual instructions following”. In:arXiv preprint arXiv:2410.15553(2024)
-
[71]
Multipl-e: A scalable and polyglot approach to benchmarking neural code generation
Federico Cassano et al. “Multipl-e: A scalable and polyglot approach to benchmarking neural code generation”. In:IEEE Transactions on Software Engineering49.7 (2023), pp. 3675–3691
work page 2023
-
[72]
Gregory Kamradt. “Llmtest_needleinahaystack”. In:GitHub repository(2023)
work page 2023
-
[73]
Nexusraven: a commercially-permissive language model for func- tion calling
Venkat Krishna Srinivasan et al. “Nexusraven: a commercially-permissive language model for func- tion calling”. In:NeurIPS 2023 Foundation Models for Decision Making Workshop. 2023
work page 2023
-
[74]
The Pile: An 800GB Dataset of Diverse Text for Language Modeling
Leo Gao et al. “The pile: An 800gb dataset of diverse text for language modeling”. In:arXiv preprint arXiv:2101.00027(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[75]
arXiv preprint arXiv:2504.18428 , year=
Yiming Wang et al. “Polymath: Evaluating mathematical reasoning in multilingual contexts”. In: arXiv preprint arXiv:2504.18428(2025)
-
[76]
RULER: What's the Real Context Size of Your Long-Context Language Models?
Cheng-Ping Hsieh et al. “RULER: What’s the real context size of your long-context language models?” In:arXiv preprint arXiv:2404.06654(2024)
work page internal anchor Pith review arXiv 2024
-
[77]
Truthfulqa: Measuring how models mimic hu- man falsehoods
Stephanie Lin, Jacob Hilton, and Owain Evans. “Truthfulqa: Measuring how models mimic hu- man falsehoods”. In:Proceedings of the 60th annual meeting of the association for computational linguistics (volume 1: long papers). 2022, pp. 3214–3252
work page 2022
-
[78]
Winogrande: An adversarial winograd schema challenge at scale
Keisuke Sakaguchi et al. “Winogrande: An adversarial winograd schema challenge at scale”. In: Communications of the ACM64.9 (2021), pp. 99–106
work page 2021
-
[79]
Writingbench: A comprehensive benchmark for generative writing.CoRR, abs/2503.05244,
Yuning Wu et al. “Writingbench: A comprehensive benchmark for generative writing”. In:arXiv preprint arXiv:2503.05244(2025)
-
[80]
Zebralogic: On the scaling limits of llms for logical reasoning
Bill Yuchen Lin et al. “Zebralogic: On the scaling limits of llms for logical reasoning”. In:arXiv preprint arXiv:2502.01100(2025)
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.