Recognition: 2 theorem links
· Lean TheoremTracing Uncertainty in Language Model "Reasoning"
Pith reviewed 2026-05-11 02:16 UTC · model grok-4.3
The pith
Uncertainty profiles from language model reasoning traces predict whether the final answer is correct.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
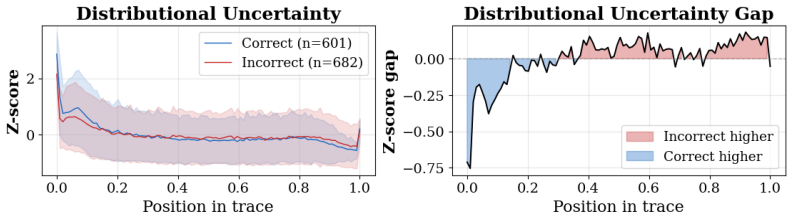
Across five language models on GSM8K and ProntoQA, uncertainty trace profiles predict whether a reasoning trace yields a correct final answer with AUROC up to 0.807, and reach AUROC 0.801 from only the initial segment of the trace.
What carries the argument
Uncertainty trace profile: a compact set of features that describe the shape of the uncertainty signal across the tokens of a generated reasoning trace, including its slope and linearity.
If this is right
- Correct and incorrect traces exhibit qualitatively different uncertainty dynamics, with correct ones showing steeper and less linear decline.
- Predictive accuracy remains high when profiles are computed from only the first few hundred tokens, enabling early detection of likely errors.
- The method supplies a decision-making-under-uncertainty view of the generative process that underlies chain-of-thought reasoning.
- The same profile features distinguish success across multiple models and both arithmetic and logical reasoning datasets.
Where Pith is reading between the lines
- Early profile-based detection could support generation-time interventions that stop or redirect a trace once its uncertainty shape signals probable failure.
- The approach may extend to tasks outside math and logic if the same uncertainty-shape features continue to separate successful from unsuccessful generations.
- Training objectives that encourage steeper uncertainty decline might increase the fraction of traces that reach correct answers.
Load-bearing premise
The uncertainty values read from token probabilities during generation meaningfully track the quality of the underlying reasoning rather than just surface patterns in token production.
What would settle it
A controlled test in which the uncertainty signal is replaced by random values or by statistics unrelated to model confidence, after which the AUROC for predicting trace correctness falls to chance level.
Figures




read the original abstract
Language model (LM) "reasoning", commonly described as Chain-of-Thought or test-time scaling, often improves benchmark performance, but the dynamics underlying this process remain poorly understood. We study these dynamics through the lens of uncertainty quantification by treating the "reasoning" traces, the intermediate token sequences generated by LMs, as evolving model states. We summarize each trace by an uncertainty trace profile: a small set of features describing the shape of the uncertainty signal over its trace, such as its slope and linearity. We find that across five LMs evaluated on GSM8K and ProntoQA, these profiles predict whether a trace yields a correct final answer with AUROC up to 0.807, improving markedly on recent related work. We reach AUROC 0.801 using only the first few hundred tokens of full traces, suggesting that errors can be detected early in the generation. A detailed comparison of correct and incorrect traces further reveals qualitatively distinct uncertainty profiles, with correct traces showing a steeper and less linear decline in uncertainty. Together, the results suggest that our method, grounded in decision-making under uncertainty, provides a principled lens for studying the generative process underlying LM "reasoning".
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes summarizing LM reasoning traces (e.g., Chain-of-Thought) via uncertainty trace profiles—compact features such as slope and linearity of the per-token uncertainty signal—and shows that these profiles predict final-answer correctness on GSM8K and ProntoQA across five models, reaching AUROC 0.807 (and 0.801 from the first few hundred tokens). It further reports qualitative differences, with correct traces exhibiting steeper and less linear uncertainty decline, and frames the approach as a principled lens from decision-making under uncertainty.
Significance. If the uncertainty profiles are shown to capture reasoning dynamics rather than surface token statistics, the work would provide a concrete, early-detection method for analyzing and potentially intervening in LM reasoning processes, improving on recent related work with falsifiable AUROC metrics on standard benchmarks. The early-token result and qualitative profile distinctions are potentially actionable for test-time scaling.
major comments (3)
- [Method] The method section does not provide explicit equations or pseudocode for per-token uncertainty computation (e.g., whether it is negative log-probability, entropy, or another measure) or for extracting slope/linearity features from the trace; without these, it is impossible to determine whether the reported AUROC reflects reasoning quality or merely correlates with token rarity, length, or local predictability.
- [Experiments] No ablations or statistical controls are presented for surface statistics (sequence length, average token probability, or n-gram rarity) that could drive the uncertainty profiles; this is load-bearing for the central claim because the skeptic concern—that profiles proxy generation surface properties rather than reasoning dynamics—is consistent with the reported early-detection AUROC of 0.801 and the qualitative differences.
- [Results] The qualitative comparison of correct vs. incorrect traces (steeper, less linear decline) lacks quantitative effect sizes, confidence intervals, or hypothesis tests; without these, the claim that the profiles are “qualitatively distinct” cannot be assessed for robustness against the same surface-statistic confound.
minor comments (2)
- [Introduction] The abstract and introduction use “reasoning” in quotes but do not define the term operationally (e.g., whether it includes only GSM8K-style arithmetic or also ProntoQA); a brief operational definition would improve clarity.
- [Results] Table or figure captions for the AUROC results should explicitly state the number of traces per model/benchmark and any multiple-testing correction applied.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The comments correctly identify areas where greater explicitness and controls would strengthen the manuscript. We address each major comment below and will incorporate revisions to improve methodological clarity, add necessary controls, and provide quantitative support for the claims.
read point-by-point responses
-
Referee: [Method] The method section does not provide explicit equations or pseudocode for per-token uncertainty computation (e.g., whether it is negative log-probability, entropy, or another measure) or for extracting slope/linearity features from the trace; without these, it is impossible to determine whether the reported AUROC reflects reasoning quality or merely correlates with token rarity, length, or local predictability.
Authors: We agree that the current description lacks the precision needed for full reproducibility and to evaluate potential confounds. Per-token uncertainty is defined as the negative log-probability of the generated token. Slope is the coefficient from ordinary least-squares regression of uncertainty against token position within the trace; linearity is the corresponding R-squared value. In the revised manuscript we will insert the explicit equations, a short derivation of the profile features, and pseudocode for the end-to-end extraction pipeline. These additions will make clear that the features emphasize the temporal shape of the uncertainty signal rather than its absolute level. revision: yes
-
Referee: [Experiments] No ablations or statistical controls are presented for surface statistics (sequence length, average token probability, or n-gram rarity) that could drive the uncertainty profiles; this is load-bearing for the central claim because the skeptic concern—that profiles proxy generation surface properties rather than reasoning dynamics—is consistent with the reported early-detection AUROC of 0.801 and the qualitative differences.
Authors: We recognize that the absence of such controls leaves open the possibility that the reported AUROCs partly reflect surface statistics. In the revision we will add a dedicated ablation subsection that (i) reports partial correlations between profile features and correctness after regressing out length and mean token probability, (ii) evaluates AUROC on the residuals of a linear model that predicts correctness from length, average probability, and n-gram rarity alone, and (iii) compares the full profile-based classifier against a baseline using only those surface features. Results will be shown for both complete traces and the early-token regime. Should the profile features retain substantial predictive power after these controls, the reasoning-dynamics interpretation will be reinforced; otherwise the claims will be appropriately qualified. revision: yes
-
Referee: [Results] The qualitative comparison of correct vs. incorrect traces (steeper, less linear decline) lacks quantitative effect sizes, confidence intervals, or hypothesis tests; without these, the claim that the profiles are “qualitatively distinct” cannot be assessed for robustness against the same surface-statistic confound.
Authors: We concur that qualitative statements require quantitative backing. The revised results section will include a table reporting, for each model and dataset, the mean slope and mean linearity (with standard deviations) separately for correct and incorrect traces. We will also provide 95 % confidence intervals around the differences and the results of two-sample t-tests (or non-parametric equivalents if normality assumptions are violated). These statistics will be presented together with the existing qualitative description so that readers can judge the magnitude and reliability of the observed distinctions while remaining mindful of possible surface-statistic confounds. revision: yes
Circularity Check
No circularity: empirical feature-based prediction of correctness
full rationale
The paper computes per-token uncertainty from model probabilities, derives summary features (slope, linearity) of the resulting trace, and trains a classifier to predict an independent binary label (final answer correct/incorrect) on GSM8K and ProntoQA. This is a standard supervised evaluation whose reported AUROC values are obtained from held-out data rather than by algebraic reduction or self-referential definition. No load-bearing self-citations, uniqueness theorems, or ansatzes are invoked to force the central result; the method remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Token-level uncertainty (entropy or similar) reflects the model's evolving internal state during reasoning
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We summarize each trace by an uncertainty trace profile: a small set of features describing the shape of the uncertainty signal over its trace, such as its slope and linearity... correct traces showing a steeper and less linear decline in uncertainty.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We treat the generated CoT of an LM as an evolving state of the model; a state which can be more or less certain... uncertainty trace profile is strongly predictive of final answer correctness
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
I. Arcuschin, J. Janiak, R. Krzyzanowski, S. Rajamanoharan, N. Nanda, and A. Conmy. Chain- of-Thought Reasoning In The Wild Is Not Always Faithful, Mar. 2025
work page 2025
-
[2]
C. Blundell, J. Cornebise, K. Kavukcuoglu, and D. Wierstra. Weight Uncertainty in Neural Net- works. In Proceedings of the 32nd International Conference on Machine Learning, volume 37 of Proceedings of Machine Learning Research, pages 1613–1622. PMLR, June 2015
work page 2015
-
[3]
X. Chen, R. Aksitov, U. Alon, J. Ren, K. Xiao, P. Yin, S. Prakash, C. Sutton, X. Wang, and D. Zhou. Universal Self-Consistency for Large Language Model Generation, Nov. 2023
work page 2023
-
[4]
Y . Chen, J. Benton, A. Radhakrishnan, J. Uesato, C. Denison, J. Schulman, A. Somani, P. Hase, M. Wagner, F. Roger, V . Mikulik, S. Bowman, J. Leike, J. Kaplan, and E. Perez. Reasoning Models Don’t Always Say What They Think, May 2025
work page 2025
- [5]
-
[6]
doi: https://doi.org/10.1016/j.strusafe.2008.06.020
A. Der Kiureghian and O. Ditlevsen. Aleatory or epistemic? Does it matter? Structural Safety, 31(2):105–112, 2009. ISSN 0167-4730. doi: 10.1016/j.strusafe.2008.06.020. Risk Acceptance and Risk Communication
-
[7]
S. M. Downes, P. Forber, and A. Grzankowski. LLMs are not just next token predictors.Inquiry: An Interdisciplinary Journal of Philosophy, Jan. 2025. doi: 10.1080/0020174X.2024.2446240. Published online 12 January 2025
-
[8]
Y . Fu, X. Wang, Y . Tian, and J. Zhao. Deep Think with Confidence, Aug. 2025
work page 2025
-
[9]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughan, et al. The Llama 3 Herd of Models, Nov. 2024. Author list truncated; full author list available at the arXiv page
work page 2024
-
[10]
N. Grünefeld, J. Frellsen, and C. Hardmeier. An Isotropic Approach to Efficient Uncertainty Quantification with Gradient Norms, Mar. 2026
work page 2026
-
[11]
D. Guo, D. Yang, H. Zhang, J. Song, P. Wang, Q. Zhu, R. Xu, R. Zhang, S. Ma, X. Bi, et al. DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning. Nature, 645 (8081):633–638, Sept. 2025. ISSN 1476-4687. doi: 10.1038/s41586-025-09422-z. Author list truncated for brevity; see Nature publication for full list
-
[12]
B. Højer. On the Notion that Language Models Reason. In 1st Workshop on Epistemic Intelligence in Machine Learning (EIML), EurIPS 2025, 2025. doi: 10.48550/arXiv.2511.11810
-
[13]
B. Højer, O. Jarvis, and S. Heinrich. Improving Reasoning Performance in Large Language Mod- els via Representation Engineering. In The Thirteenth International Conference on Learning Representations. OpenReview, 2025. doi: 10.48550/arXiv.2504.19483
-
[14]
S. C. Hora. Aleatory and epistemic uncertainty in probability elicitation with an example from hazardous waste management. Reliability Engineering & System Safety, 54(2):217–223, 1996. ISSN 0951-8320. doi: 10.1016/S0951-8320(96)00077-4. Treatment of Aleatory and Epistemic Uncertainty
-
[15]
Towards reasoning in large language models: A survey
J. Huang and K. C.-C. Chang. Towards Reasoning in Large Language Models: A Survey. In A. Rogers, J. Boyd-Graber, and N. Okazaki, editors, Findings of the Association for Computa- tional Linguistics: ACL 2023, pages 1049–1065, Toronto, Canada, July 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023.findings-acl.67. 10
-
[16]
E. Hüllermeier and W. Waegeman. Aleatoric and epistemic uncertainty in machine learning: An introduction to concepts and methods. Machine Learning, 110(3):457–506, Mar. 2021. ISSN 1573-0565. doi: 10.1007/s10994-021-05946-3
-
[17]
S. Kambhampati, K. Valmeekam, S. Bhambri, V . Palod, L. Saldyt, K. Stechly, S. R. Sami- neni, D. Kalwar, and U. Biswas. Position: Stop Anthropomorphizing Intermediate Tokens as Reasoning/Thinking Traces!, Apr. 2025
work page 2025
-
[18]
Z. Kang, X. Zhao, and D. Song. Scalable Best-of-N Selection for Large Language Models via Self-Certainty. In The Thirty-Ninth Annual Conference on Neural Information Processing Systems, 2025. doi: 10.48550/arXiv.2502.18581
-
[19]
T. Kojima, S. S. Gu, M. Reid, Y . Matsuo, and Y . Iwasawa. Large Language Models are Zero- Shot Reasoners. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors, Advances in Neural Information Processing Systems, volume 35, pages 22199–22213. Curran Associates, Inc., 2022
work page 2022
-
[20]
T. Lanham, A. Chen, A. Radhakrishnan, B. Steiner, C. Denison, D. Hernandez, D. Li, E. Durmus, E. Hubinger, J. Kernion, K. Lukoši¯ut˙e, K. Nguyen, N. Cheng, N. Joseph, N. Schiefer, O. Rausch, R. Larson, S. McCandlish, S. Kundu, S. Kadavath, S. Yang, T. Henighan, T. Maxwell, T. Telleen- Lawton, T. Hume, Z. Hatfield-Dodds, J. Kaplan, J. Brauner, S. R. Bowman...
work page 2023
-
[21]
Z. Ling, Y . Fang, X. Li, Z. Huang, M. Lee, R. Memisevic, and H. Su. Deductive Verification of Chain-of-Thought Reasoning. In Advances in Neural Information Processing Systems , volume 36. Curran Associates, Inc., 2023. doi: 10.48550/arXiv.2306.03872
-
[22]
Z. Liu, C. Chen, W. Li, P. Qi, T. Pang, C. Du, W. S. Lee, and M. Lin. Understanding R1-Zero- Like Training: A Critical Perspective. In Conference on Language Modeling (COLM), 2025. doi: 10.48550/arXiv.2503.20783
-
[23]
D. J. C. MacKay. A Practical Bayesian Framework for Backpropagation Networks. Neural Computation, 4(3):448–472, May 1992. ISSN 0899-7667. doi: 10.1162/neco.1992.4.3.448
-
[24]
GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models
I. Mirzadeh, K. Alizadeh, H. Shahrokhi, O. Tuzel, S. Bengio, and M. Farajtabar. GSM- Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models. In The Thirteenth International Conference on Learning Representations, 2025. doi: 10.48550/arXiv.2410.05229
-
[25]
P. Mondorf and B. Plank. Comparing Inferential Strategies of Humans and Large Language Models in Deductive Reasoning. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9370–9402, Bangkok, Thailand,
-
[26]
doi: 10.18653/v1/2024.acl-long.508
Association for Computational Linguistics. doi: 10.18653/v1/2024.acl-long.508
-
[27]
N. Muennighoff, Z. Yang, W. Shi, X. L. Li, L. Fei-Fei, H. Hajishirzi, L. Zettlemoyer, P. Liang, E. Candès, and T. Hashimoto. S1: Simple test-time scaling. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages 20275–20321, Suzhou, China, 2025. Association for Computational Linguistics
work page 2025
-
[28]
R. M. Neal. Bayesian Learning for Neural Networks, volume 118. Springer Science & Business Media, 2012
work page 2012
-
[29]
M. Nye, A. J. Andreassen, G. Gur-Ari, H. Michalewski, J. Austin, D. Bieber, D. Dohan, A. Lewkowycz, M. Bosma, D. Luan, C. Sutton, and A. Odena. Show Your Work: Scratchpads for Intermediate Computation with Language Models, Nov. 2021
work page 2021
-
[30]
Y . Sale, P. Hofman, L. Wimmer, E. Hüllermeier, and T. Nagler. Second-Order Uncertainty Quantification: Variance-Based Measures, Dec. 2023
work page 2023
-
[31]
Y . Sale, P. Hofman, T. Löhr, L. Wimmer, T. Nagler, and E. Hüllermeier. Label-wise Aleatoric and Epistemic Uncertainty Quantification. In Proceedings of the Fortieth Conference on Uncertainty in Artificial Intelligence, volume 244 of Proceedings of Machine Learning Research, pages 3159–3179. PMLR, July 2024. 11
work page 2024
-
[32]
S. R. Samineni, D. Kalwar, K. Valmeekam, K. Stechly, and S. Kambhampati. RL in Name Only? Analyzing the Structural Assumptions in RL post-training for LLMs. In NeurIPS 2025 Workshop on Bridging Language, Agent, and World Models for Reasoning and Planning (LAW), 2025. doi: 10.48550/arXiv.2505.13697. Also accepted at NeurIPS 2025 Workshop on Foundations of ...
-
[33]
A. Saparov and H. He. Language Models Are Greedy Reasoners: A Systematic Formal Analysis of Chain-of-Thought, 2023. URL https://arxiv.org/abs/2210.01240. Published at ICLR 2023
- [34]
-
[35]
L. Smith and Y . Gal. Understanding Measures of Uncertainty for Adversarial Example Detec- tion. In A. Globerson and R. Silva, editors, Proceedings of the Thirty-Fourth Conference on Uncertainty in Artificial Intelligence, UAI 2018, Monterey, California, USA, August 6-10, 2018, pages 560–569. AUAI Press, 2018
work page 2018
-
[36]
Chain of Thoughtlessness? An Analysis of CoT in Planning
K. Stechly, K. Valmeekam, and S. Kambhampati. Chain of Thoughtlessness? An Analysis of CoT in Planning. In Advances in Neural Information Processing Systems, volume 37. Curran Associates, Inc., 2024. doi: 10.48550/arXiv.2405.04776
-
[37]
K. Stechly, K. Valmeekam, A. Gundawar, V . Palod, and S. Kambhampati. Beyond Semantics: The Unreasonable Effectiveness of Reasonless Intermediate Tokens. InThe Thirty-Ninth Annual Conference on Neural Information Processing Systems, 2025. doi: 10.48550/arXiv.2505.13775
- [38]
- [39]
-
[40]
URL https://www.science.org/doi/10
A. Tversky and D. Kahneman. Judgment under Uncertainty: Heuristics and Biases: Biases in judgments reveal some heuristics of thinking under uncertainty. Science, 185(4157):1124–1131, Sept. 1974. ISSN 0036-8075, 1095-9203. doi: 10.1126/science.185.4157.1124
-
[41]
A. Tversky and D. Kahneman. The Framing of Decisions and the Psychology of Choice. Science, 211(4481):453–458, 1981. doi: 10.1126/science.7455683
-
[42]
A. Tversky and D. Kahneman. Rational Choice and the Framing of Decisions. The Journal of Business, 59(4):S251–S278, 1986. ISSN 0021-9398
work page 1986
-
[43]
X. Wang, J. Wei, D. Schuurmans, Q. V . Le, E. H. Chi, S. Narang, A. Chowdhery, and D. Zhou. Self-Consistency Improves Chain of Thought Reasoning in Language Models. In The Eleventh International Conference on Learning Representations, 2023. doi: 10.48550/arXiv.2203.11171
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2203.11171 2023
-
[44]
J. Wei, X. Wang, D. Schuurmans, M. Bosma, B. Ichter, F. Xia, E. Chi, Q. Le, and D. Zhou. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors, Advances in Neural Information Processing Systems, volume 35, pages 24824–24837. Curran Associates, Inc., 2022
work page 2022
-
[45]
L. Wimmer, Y . Sale, P. Hofman, B. Bischl, and E. Hüllermeier. Quantifying Aleatoric and Epistemic Uncertainty in Machine Learning: Are Conditional Entropy and Mutual Information Appropriate Measures? In R. J. Evans and I. Shpitser, editors, Proceedings of the Thirty-Ninth Conference on Uncertainty in Artificial Intelligence, volume 216 of Proceedings of ...
-
[46]
A. Yang, B. Yang, B. Hui, B. Zheng, B. Yu, C. Zhou, C. Li, C. Li, D. Liu, F. Huang, et al. Qwen2 Technical Report, Sept. 2024. Author list truncated; full author list available at the arXiv page. 12
work page 2024
-
[47]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv, et al. Qwen3 Technical Report, May 2025. Author list truncated; full author list available at the arXiv page
work page 2025
- [48]
-
[49]
Z. Zhao, Y . Koishekenov, X. Yang, N. Murray, and N. Cancedda. Verifying Chain-of-Thought Reasoning via Its Computational Graph. In The Fourteenth International Conference on Learning Representations, 2026. doi: 10.48550/arXiv.2510.09312. Accepted as Oral. 13 A Intuitions for the Uncertainty Types The three uncertainty types defined in subsection 2.2 can ...
-
[50]
and a near-tied two-way contest (Case 3) both produce high committal uncertainty, but only Case 14 2 also produces high entropy. The same low-entropy reading can therefore correspond to confident commitment (Case 1) or to a near-tied two-way contest (Case 3), and only committal uncertainty distinguishes them. B Extracting the Final Answer, ˆy Computing an...
-
[51]
A regex-based extractor attempts to pull a final answer from the answer portion of each generation
contains_answer check. A regex-based extractor attempts to pull a final answer from the answer portion of each generation. Generations for which extraction fails are dropped
-
[52]
LLM correctness re-evaluation. For samples whose extracted answer differs from the reference under the regex matcher, we query an LLM auditor (gpt-5-2025-08-07) to re- evaluate correctness under a more lenient semantic match (e.g., 0.5 vs 1/2, mathematically equivalent expressions). When the auditor confirms correctness, we flip is_correct to True; otherw...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.