Recognition: 2 theorem links
· Lean TheoremHierarchical Prompting with Dual LLM Modules for Robotic Task and Motion Planning
Pith reviewed 2026-05-12 01:17 UTC · model grok-4.3
The pith
Dual LLM modules with hierarchical prompting achieve 86% success in robotic task and motion planning tests
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
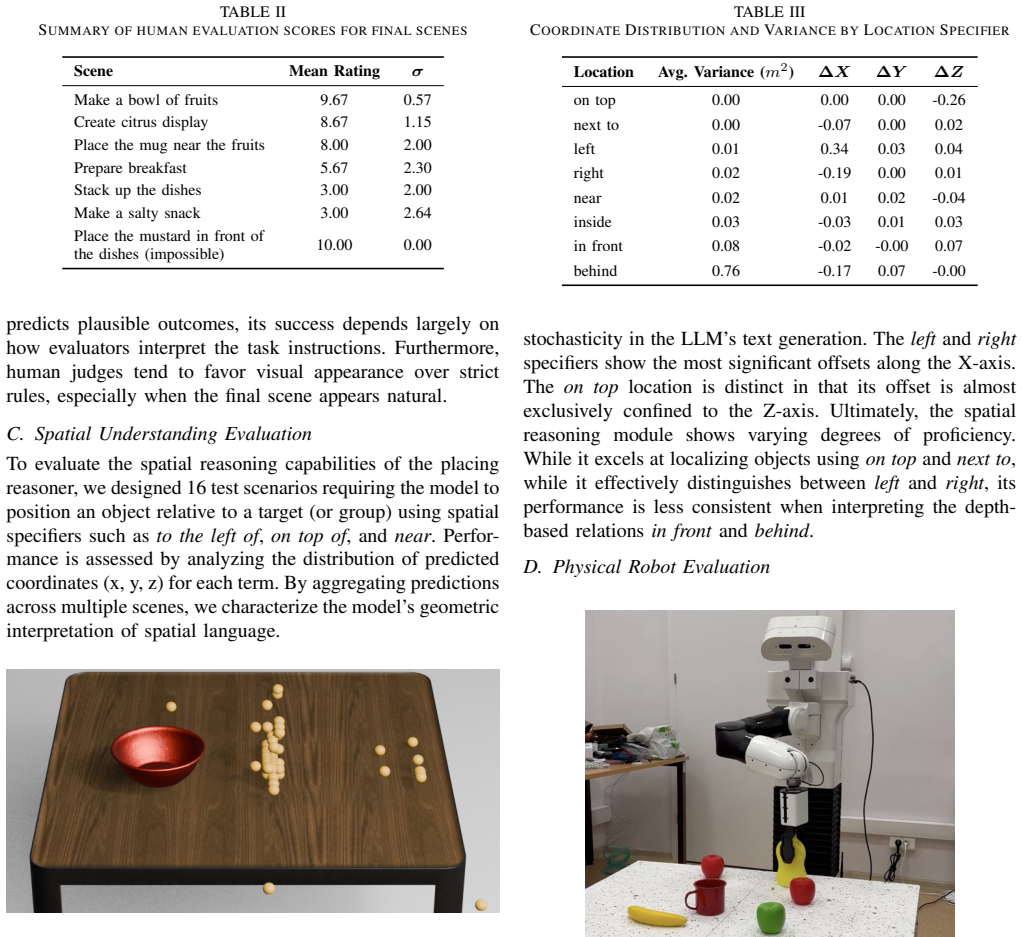
The hierarchical language-driven framework employs a high-level planning agent using ReAct-style prompts to process natural language commands and generate action sequences, interacting with tools for object perception and manipulation, while a separate low-level spatial reasoning sub-module handles 3D reasoning based on object geometry and scene layout for precise placements, integrated with YOLOX-GDRNet for detection and pose estimation, and evaluated to achieve an 86% task success rate in 24 test scenarios ranging from simple spatial commands to high-level instructions and infeasible requests.
What carries the argument
Hierarchical prompting structure with a primary ReAct-style LLM agent for action sequence generation and a separate spatial sub-module for 3D geometric reasoning
If this is right
- The approach supports execution of both basic spatial commands and higher-level instructions through language alone.
- The system can recognize and respond to infeasible requests within the tested range of scenarios.
- Integration of perception tools with the dual LLM modules produces an end-to-end language-to-action pipeline.
- Overall task completion reaches 86 percent across commands of varying complexity.
Where Pith is reading between the lines
- Similar hierarchical splits between planning and detailed spatial modules could be tested in other robot skills such as navigation or assembly.
- Adding execution feedback to adjust spatial outputs in real time might raise success rates beyond the reported level.
- The dual-module design points to a general strategy for limiting LLM errors on physical reasoning by isolating specific subtasks.
Load-bearing premise
The high-level and low-level LLM modules will reliably interpret natural language and 3D geometry without hallucinations or coordination failures in varied real-world conditions.
What would settle it
Running the system on a physical robot across new environments with novel objects, ambiguous phrasing, or changed lighting and measuring whether the success rate drops well below 86 percent would test whether the dual-module reliability holds.
Figures




read the original abstract
We present a hierarchical language-driven framework for robotic task and motion planning to improve natural, intuitive human-robot interaction in service and assistance scenarios. The proposed system employs two large language model (LLM) modules: a high-level planning agent and a low-level spatial reasoning sub-module. The primary agent processes natural language commands and generates action sequences using a ReAct-style prompt, interacting with tools for object perception and manipulation (e.g., pick, place, release). For precise spatial placement, such as interpreting "place the mug next to the plate", a separate sub-prompting module handles 3D reasoning based on object geometry and scene layout. The system integrates YOLOX-GDRNet for object detection and pose estimation, along with a motion execution stub. We evaluated the system in 24 test scenarios, ranging from simple spatial commands to high-level instructions and infeasible requests. The system achieved an overall task success rate of 86%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a hierarchical language-driven framework for robotic task and motion planning that uses two LLM modules: a high-level ReAct-style agent for generating action sequences from natural language commands and a low-level spatial reasoning sub-module for precise 3D placements. The system incorporates YOLOX-GDRNet for object detection and pose estimation, along with a motion execution stub, and reports an overall task success rate of 86% across 24 test scenarios.
Significance. If the reported performance holds under more rigorous testing, the dual-module hierarchical prompting could provide a practical way to handle both high-level task planning and low-level spatial reasoning in service robotics, potentially improving intuitiveness over traditional TAMP methods. The work highlights the potential of LLMs in robotics but requires stronger evidence to establish its advantages.
major comments (4)
- Abstract: The 86% success rate is presented without any baseline comparisons to classical TAMP solvers, other LLM planners, or ablations of the dual-module design, which is necessary to substantiate the claimed improvement in robotic TAMP.
- Abstract: The motion execution is explicitly described as a 'stub,' meaning the success rate measures only high-level planning and perception rather than closed-loop task-and-motion execution, which contradicts the title and central claim of the paper.
- Evaluation section: The evaluation on 24 scenarios lacks statistical details, error analysis, failure-mode breakdown, or breakdown by scenario difficulty, making the 86% figure difficult to interpret or generalize.
- Abstract: No real-robot validation or discussion of robustness to LLM hallucinations in varied real-world conditions is provided, despite the assumption that the high-level ReAct agent and low-level spatial sub-module will reliably interpret natural language and 3D geometry.
minor comments (1)
- Abstract: The range of scenarios from simple spatial commands to infeasible requests is mentioned but not detailed in terms of how infeasible requests are handled or what success means in those cases.
Simulated Author's Rebuttal
We thank the referee for their thorough and constructive review of our manuscript. We have addressed each major comment point by point below, indicating where revisions will be made to the next version of the paper.
read point-by-point responses
-
Referee: Abstract: The 86% success rate is presented without any baseline comparisons to classical TAMP solvers, other LLM planners, or ablations of the dual-module design, which is necessary to substantiate the claimed improvement in robotic TAMP.
Authors: We agree that quantitative baseline comparisons would strengthen the claims of improvement. Our evaluation was designed as a proof-of-concept demonstration of the dual-LLM hierarchical framework across a range of scenarios, including infeasible requests. Full implementation of classical TAMP solvers or extensive ablations would require substantial additional effort beyond the scope of this work. In the revision, we will expand the related work section with a qualitative comparison to existing methods and explicitly note the lack of quantitative baselines as a limitation. revision: partial
-
Referee: Abstract: The motion execution is explicitly described as a 'stub,' meaning the success rate measures only high-level planning and perception rather than closed-loop task-and-motion execution, which contradicts the title and central claim of the paper.
Authors: This observation is correct. The motion execution stub means the 86% figure evaluates the planning, spatial reasoning, and perception pipeline with idealized execution. This modular separation is common in TAMP research to focus on planning contributions. We will revise the abstract, introduction, and evaluation sections to explicitly clarify the scope of the reported success rate and note that the framework is designed to integrate with full motion execution modules. revision: yes
-
Referee: Evaluation section: The evaluation on 24 scenarios lacks statistical details, error analysis, failure-mode breakdown, or breakdown by scenario difficulty, making the 86% figure difficult to interpret or generalize.
Authors: We will revise the evaluation section to include a breakdown of the 24 scenarios by difficulty category (simple spatial, multi-step, infeasible), success rates per category, and a failure-mode analysis of the unsuccessful cases (e.g., perception errors versus planning issues). Basic statistical details will also be added based on re-examination of the existing results. revision: yes
-
Referee: Abstract: No real-robot validation or discussion of robustness to LLM hallucinations in varied real-world conditions is provided, despite the assumption that the high-level ReAct agent and low-level spatial sub-module will reliably interpret natural language and 3D geometry.
Authors: We acknowledge that the current evaluation is limited to the described test scenarios without real-robot experiments. The revision will add a dedicated limitations section discussing assumptions about LLM reliability, potential hallucinations, and robustness issues in real-world settings, along with plans for future real-robot validation. revision: partial
- Real-robot validation and empirical assessment of robustness to LLM hallucinations under varied real-world conditions
Circularity Check
No circularity: empirical system description without derivations or fitted parameters
full rationale
The paper presents a hierarchical LLM framework for robotic TAMP, integrating a ReAct-style high-level planner, a spatial sub-module, YOLOX-GDRNet perception, and a motion execution stub. It reports an 86% success rate across 24 test scenarios as a direct empirical outcome. No equations, parameter fittings, uniqueness theorems, or derivation chains appear in the manuscript. The central claim reduces to measured task completion rates on a fixed scenario set rather than any self-referential reduction of outputs to inputs by construction. This is a standard self-contained empirical systems paper with no load-bearing self-citations or ansatz smuggling.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The proposed system employs two large language model (LLM) modules: a high-level planning agent and a low-level spatial reasoning sub-module... ReAct-style prompt... YOLOX-GDRNet... motion execution stub... 86% task success rate
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
dual-module prompting architecture that decouples high-level task logic from low-level spatial reasoning
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
A survey of communicating robot learning during human-robot interaction,
S. Habibian, A. Alvarez Valdivia, L. H. Blumenschein, and D. P. Losey, “A survey of communicating robot learning during human-robot interaction,”The International Journal of Robotics Research, vol. 44, no. 4, pp. 665–698, 2025
work page 2025
-
[2]
S. Tellex, N. Gopalan, H. Kress-Gazit, and C. Matuszek, “Robots that use language,”Annual Review of Control, Robotics, and Autonomous Systems, vol. 3, no. 1, pp. 25–55, 2020
work page 2020
-
[3]
Tell me dave: Context- sensitive grounding of natural language to manipulation instructions,
D. K. Misra, J. Sung, K. Lee, and A. Saxena, “Tell me dave: Context- sensitive grounding of natural language to manipulation instructions,” The International Journal of Robotics Research, vol. 35, no. 1-3, pp. 281–300, 2016
work page 2016
-
[4]
Robotic Control via Embodied Chain-of-Thought Reasoning
M. Zawalski, W. Chen, K. Pertsch, O. Mees, C. Finn, and S. Levine, “Robotic control via embodied chain-of-thought reasoning,”arXiv preprint arXiv:2407.08693, 2024
work page internal anchor Pith review arXiv 2024
-
[5]
Embodiedgpt: Vision-language pre-training via embodied chain of thought,
Y . Mu, Q. Zhang, M. Hu, W. Wang, M. Ding, J. Jin, B. Wang, J. Dai, Y . Qiao, and P. Luo, “Embodiedgpt: Vision-language pre-training via embodied chain of thought,”Advances in Neural Information Processing Systems, vol. 36, 2024
work page 2024
-
[6]
Alfred: A benchmark for interpreting grounded instructions for everyday tasks,
M. Shridhar, J. Thomason, D. Gordon, Y . Bisk, W. Han, R. Mottaghi, L. Zettlemoyer, and D. Fox, “Alfred: A benchmark for interpreting grounded instructions for everyday tasks,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 10 740–10 749
work page 2020
-
[7]
Assessing the emergent symbolic reasoning abilities of llama large language models,
F. Petruzzellis, A. Testolin, and A. Sperduti, “Assessing the emergent symbolic reasoning abilities of llama large language models,” in International Conference on Artificial Neural Networks. Springer, 2024, pp. 266–276
work page 2024
-
[8]
Chatgpt for robotics: Design principles and model abilities. 2023,
S. Vemprala, R. Bonatti, A. Bucker, and A. Kapoor, “Chatgpt for robotics: Design principles and model abilities. 2023,”Published by Microsoft, 2023
work page 2023
-
[9]
Do as i can, not as i say: Grounding language in robotic affordances,
M. Ahn, A. Brohan, N. Brown, Y . Chebotar, O. Cortes, B. David, C. Finn, C. Fu, K. Gopalakrishnan, K. Hausmanet al., “Do as i can, not as i say: Grounding language in robotic affordances,”Conference on Robot Learning, 2022
work page 2022
-
[10]
ReAct: Synergizing Reasoning and Acting in Language Models
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y . Cao, “React: Synergizing reasoning and acting in language models,”arXiv preprint arXiv:2210.03629, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[11]
Integrated task and motion planning,
C. R. Garrett, R. Chitnis, R. Holladay, B. Kim, T. Silver, L. P. Kaelbling, and T. Lozano-P´erez, “Integrated task and motion planning,” Annual review of control, robotics, and autonomous systems, vol. 4, no. 1, pp. 265–293, 2021
work page 2021
-
[12]
Can an embodied agent find your “cat-shaped mug
V . S. Dorbala, J. F. Mullen, and D. Manocha, “Can an embodied agent find your “cat-shaped mug”? llm-based zero-shot object navigation,” IEEE Robotics and Automation Letters, vol. 9, no. 5, pp. 4083–4090, 2023
work page 2023
-
[13]
Lm-nav: Robotic navigation with large pre-trained models of language, vision, and action,
D. Shah, B. Osi ´nski, S. Levineet al., “Lm-nav: Robotic navigation with large pre-trained models of language, vision, and action,” inConference on robot learning. PMLR, 2023, pp. 492–504
work page 2023
-
[14]
Large language models for robotics: A survey
F. Zeng, W. Gan, Y . Wang, N. Liu, and P. S. Yu, “Large language models for robotics: A survey,”arXiv preprint arXiv:2311.07226, 2023
-
[15]
Chain-of-thought prompting elicits reasoning in large language models,
J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V . Le, D. Zhouet al., “Chain-of-thought prompting elicits reasoning in large language models,”Advances in neural information processing systems, vol. 35, pp. 24 824–24 837, 2022
work page 2022
-
[16]
Training Verifiers to Solve Math Word Problems
K. Cobbe, V . Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Plappert, J. Tworek, J. Hilton, R. Nakanoet al., “Training verifiers to solve math word problems, 2021,”URL https://arxiv. org/abs/2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[17]
Code as policies: Language model programs for embodied control,
J. Liang, W. Huang, F. Xia, P. Xu, K. Hausman, B. Ichter, P. Florence, and A. Zeng, “Code as policies: Language model programs for embodied control,” in2023 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2023, pp. 9493–9500
work page 2023
-
[18]
Rap: Retrieval-augmented planning with contextual memory for multimodal llm agents,
T. Kagaya, T. J. Yuan, Y . Lou, J. Karlekar, S. Pranata, A. Kinose, K. Oguri, F. Wick, and Y . You, “Rap: Retrieval-augmented planning with contextual memory for multimodal llm agents,”arXiv preprint arXiv:2402.03610, 2024
-
[19]
Opex: A component- wise analysis of llm-centric agents in embodied instruction following,
H. Shi, Z. Sun, X. Yuan, M.-A. C ˆot´e, and B. Liu, “Opex: A component- wise analysis of llm-centric agents in embodied instruction following,” arXiv preprint arXiv:2403.03017, 2024
-
[20]
Context-aware planning and environment-aware memory for instruction following embodied agents,
B. Kim, J. Kim, Y . Kim, C. Min, and J. Choi, “Context-aware planning and environment-aware memory for instruction following embodied agents,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 10 936–10 946
work page 2023
-
[21]
Multi-level compositional reasoning for interactive instruction following,
S. Bhambri, B. Kim, and J. Choi, “Multi-level compositional reasoning for interactive instruction following,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 37, no. 1, 2023, pp. 223– 231
work page 2023
-
[22]
Tell and show: Combining multiple modalities to communicate manipulation tasks to a robot,
P. Vanc, R. Skoviera, and K. Stepanova, “Tell and show: Combining multiple modalities to communicate manipulation tasks to a robot,” arXiv preprint arXiv:2404.01702, 2024
-
[23]
Realfred: An embodied instruction following benchmark in photo-realistic envi- ronments,
T. Kim, C. Min, B. Kim, J. Kim, W. Jeung, and J. Choi, “Realfred: An embodied instruction following benchmark in photo-realistic envi- ronments,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 346–364
work page 2024
-
[24]
YOLOX: Exceeding YOLO Series in 2021
Z. Ge, S. Liu, F. Wang, Z. Li, and J. Sun, “Yolox: Exceeding yolo series in 2021,”arXiv preprint arXiv:2107.08430, 2021
work page internal anchor Pith review arXiv 2021
-
[25]
Gdr-net: Geometry- guided direct regression network for monocular 6d object pose esti- mation,
G. Wang, F. Manhardt, F. Tombari, and X. Ji, “Gdr-net: Geometry- guided direct regression network for monocular 6d object pose esti- mation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 16 611–16 621
work page 2021
-
[26]
LangChain, “Agents|LangChain.” [Online]. Available: https: //python.langchain.com/docs/how to/#agents
-
[27]
AIMeta, “Llama 3 model card,” 2024. [Online]. Available: https: //github.com/meta-llama/llama3/blob/main/MODEL CARD.md
work page 2024
-
[28]
React: Synergizing reasoning and acting in language models,
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y . Cao, “React: Synergizing reasoning and acting in language models,” in International Conference on Learning Representations (ICLR), 2023
work page 2023
-
[29]
Prompt a robot to walk with large language models,
Y .-J. Wang, B. Zhang, J. Chen, and K. Sreenath, “Prompt a robot to walk with large language models,”arXiv preprint arXiv:2309.09969, 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.