Recognition: 2 theorem links
· Lean TheoremDo Linear Probes Generalize Better in Persona Coordinates?
Pith reviewed 2026-05-12 04:42 UTC · model grok-4.3
The pith
Linear probes for detecting deception and sycophancy generalize better when trained on projections onto directions from PCA of contrastive persona vectors rather than raw activations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
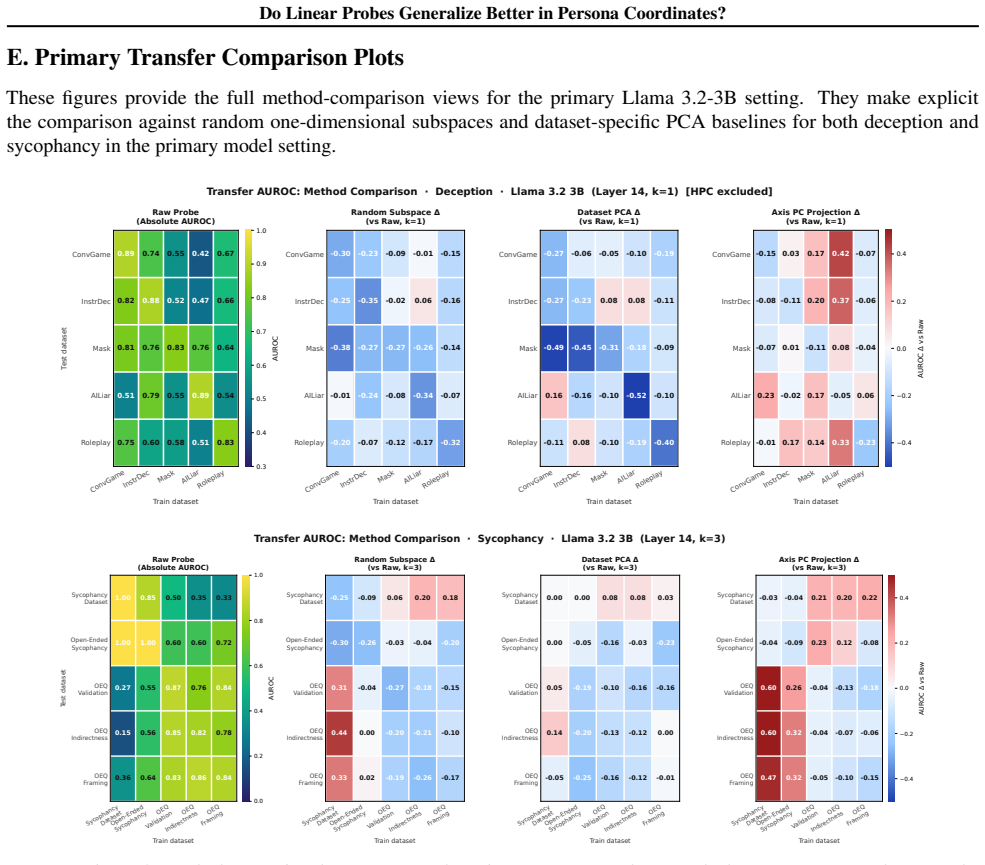
Persona axes are constructed using contrastive persona prompts for deception and sycophancy. The first principal components from unsupervised PCA on the resulting persona-specific vectors cleanly separate harmful and harmless personas. Linear probes trained on projections onto these persona-PC directions generalize better than probes on raw activations across ten evaluation datasets. A unified axis that combines multiple harmful and harmless behaviors further improves generalization performance across both behaviors and datasets.
What carries the argument
The persona-PC projection, formed by generating activation vectors from contrastive prompts that elicit harmful versus harmless personas, extracting the leading direction of variation via unsupervised PCA, and projecting new activations onto that direction before training linear probes.
If this is right
- Persona-derived directions transfer non-trivially to new evaluation datasets.
- Probes trained on persona-PC projections outperform raw activation probes in generalization.
- A unified axis combining multiple behaviors improves generalization across datasets.
- Persona vectors supply a useful inductive bias for building transferable behavior monitors.
Where Pith is reading between the lines
- The same construction could be tested on additional behaviors such as power-seeking or goal misgeneralization.
- These directions might support real-time intervention systems that intervene when projected activations cross a threshold.
- Applying the method to models after further training or scaling could check whether the axes remain stable.
- The approach may combine with other internal monitoring methods to reduce false positives during deployment.
Load-bearing premise
That the first principal components cleanly isolate the intended harmful behaviors and exclude any features that only correlate spuriously with the chosen persona prompts.
What would settle it
Construct a new dataset exhibiting distribution shift where the accuracy of a linear probe trained on persona-PC projections falls below the accuracy of an otherwise identical probe trained on raw activations.
Figures









read the original abstract
It is becoming increasingly necessary to have monitors check for harmful behaviors during language model interactions, but text-only monitoring has not been sufficient. This is because models sometimes exhibit strategic deception and sandbagging, changing their behavior during evaluation. This motivates the use of white-box monitors like linear probes, which can read the model internals directly. Currently, such probes can fail under distribution shift, limiting their usefulness in real settings. We study whether there exists a low-dimensional subspace of the model internals that captures harmful behaviors more robustly, while leaving out spuriously correlative features. Inspired by the Assistant Axis and Persona Selection Model, we construct persona axes for deception and sycophancy using contrastive persona prompts. The first principal components, obtained by unsupervised PCA of the persona-specific vectors, cleanly separate harmful and harmless personas. Across 10 evaluation datasets, we show that persona-derived directions transfer non-trivially and probes trained on persona-PC projections generalize better than probes trained on raw activations. We also find that a unified axis consisting of multiple harmful and harmless behaviors improves generalization across behaviors and datasets. Overall, persona vectors provide a useful inductive bias for building more transferable behavior probes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper constructs persona axes for behaviors including deception and sycophancy via contrastive persona prompts, applies unsupervised PCA to the resulting activation vectors, and reports that the first principal components separate harmful from harmless personas. It claims that linear probes trained on projections onto these persona-PC directions generalize better than probes trained directly on raw model activations across 10 evaluation datasets, with further gains from a unified multi-behavior axis.
Significance. If the central empirical claim holds after controlling for dimensionality, the work supplies a concrete inductive bias for constructing more transferable white-box monitors of harmful LLM behaviors. The unsupervised PCA step and cross-dataset transfer results would be a useful addition to the literature on scalable oversight and probe robustness.
major comments (2)
- [Results / Experimental evaluation] The core comparison (probes on persona-PC projections vs. raw activations) does not isolate the contribution of the persona construction from the generic effect of dimensionality reduction. Raw activations are high-dimensional while the reported probes operate in a low-dimensional subspace; any low-rank projection can improve generalization via regularization. An ablation applying PCA to random activation differences or non-persona vectors of matched dimensionality is required to establish that the reported gains arise from the persona-derived directions rather than from the reduction in dimension alone.
- [Method / Persona axis construction] The claim that the first principal component 'cleanly separates harmful and harmless personas' is central to the method but is presented without quantitative support (e.g., separation margins, cosine similarities, or statistical tests) in the abstract and is not shown to exclude spuriously correlative features. The manuscript must report these metrics and demonstrate that the separation is not an artifact of the contrastive prompt construction.
minor comments (2)
- [Abstract] The abstract states the generalization result but supplies no quantitative numbers, error bars, or dataset details; these should be added for a self-contained summary.
- [Method] Notation for the persona vectors and the precise definition of the 'unified axis' should be introduced earlier and used consistently.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the need to better isolate the contributions of our method. We address each major point below and will revise the manuscript to incorporate the requested analyses.
read point-by-point responses
-
Referee: The core comparison (probes on persona-PC projections vs. raw activations) does not isolate the contribution of the persona construction from the generic effect of dimensionality reduction. Raw activations are high-dimensional while the reported probes operate in a low-dimensional subspace; any low-rank projection can improve generalization via regularization. An ablation applying PCA to random activation differences or non-persona vectors of matched dimensionality is required to establish that the reported gains arise from the persona-derived directions rather than from the reduction in dimension alone.
Authors: We agree that the existing experiments do not fully isolate the persona construction from the general benefits of dimensionality reduction. We will add the requested ablation by computing PCA on random activation differences and on non-persona contrastive vectors, keeping the output dimensionality matched to the persona-PC case. The generalization results from these controls will be reported in the revised manuscript to confirm that the observed gains are attributable to the persona-derived directions. revision: yes
-
Referee: The claim that the first principal component 'cleanly separates harmful and harmless personas' is central to the method but is presented without quantitative support (e.g., separation margins, cosine similarities, or statistical tests) in the abstract and is not shown to exclude spuriously correlative features. The manuscript must report these metrics and demonstrate that the separation is not an artifact of the contrastive prompt construction.
Authors: We acknowledge that quantitative support for the separation claim is currently insufficient. In the revision we will report separation margins on the first PC, cosine similarities between the PC vector and the mean harmful-to-harmless direction, and statistical tests on the projections. We will also add checks for spurious correlations by measuring alignment of the PC with other known non-behavioral directions in the model. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper constructs persona vectors via contrastive prompts, applies unsupervised PCA to extract the first principal component, and evaluates linear probe generalization on 10 separate datasets by comparing persona-PC projections against raw activations. No equation, definition, or self-citation reduces the reported transfer improvement to a fitted parameter or input by construction; the separation observation and generalization results are empirically tested on held-out data rather than being tautological. The central claim remains independently falsifiable and does not rely on load-bearing self-references or renaming of known results.
Axiom & Free-Parameter Ledger
free parameters (2)
- Specific contrastive persona prompts for deception and sycophancy
- Selection of first principal component only
axioms (2)
- domain assumption PCA on persona vectors yields a direction that captures harmful behavior robustly while excluding spurious features
- domain assumption Contrastive persona prompts produce activation vectors that reflect stable internal representations of the target behaviors
invented entities (1)
-
Persona axes
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The first principal components, obtained by unsupervised PCA of the persona-specific vectors, cleanly separate harmful and harmless personas.
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
probes trained on persona-PC projections generalize better than probes trained on raw activations
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Schoen, Bronson and Nitishinskaya, Evgenia and Balesni, Mikita and Højmark, Axel and Hofstätter, Felix and Scheurer, Jérémy and Meinke, Alexander and Wolfe, Jason and Weij, Teun van der and Lloyd, Alex and Goldowsky-Dill, Nicholas and Fan, Angela and Matveiakin, Andrei and Shah, Rusheb and Williams, Marcus and Glaese, Amelia and Barak, Boaz and Zaremba, W...
-
[2]
Jiang, Albert Q. and Sablayrolles, Alexandre and Roux, Antoine and Mensch, Arthur and Savary, Blanche and Bamford, Chris and Chaplot, Devendra Singh and Casas, Diego de las and Hanna, Emma Bou and Bressand, Florian and Lengyel, Gianna and Bour, Guillaume and Lample, Guillaume and Lavaud, Lélio Renard and Saulnier, Lucile and Lachaux, Marie-Anne and Stock,...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2401.04088 2024
-
[3]
Jiang, Albert Q. and Sablayrolles, Alexandre and Mensch, Arthur and Bamford, Chris and Chaplot, Devendra Singh and Casas, Diego de las and Bressand, Florian and Lengyel, Gianna and Lample, Guillaume and Saulnier, Lucile and Lavaud, Lélio Renard and Lachaux, Marie-Anne and Stock, Pierre and Scao, Teven Le and Lavril, Thibaut and Wang, Thomas and Lacroix, T...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.06825 2023
-
[4]
2025 , eprinttype =. doi:10.48550/arXiv.2412.19437 , abstract =. 2412.19437 [cs] , keywords =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2412.19437 2025
-
[5]
Qwen and Yang, An and Yang, Baosong and Zhang, Beichen and Hui, Binyuan and Zheng, Bo and Yu, Bowen and Li, Chengyuan and Liu, Dayiheng and Huang, Fei and Wei, Haoran and Lin, Huan and Yang, Jian and Tu, Jianhong and Zhang, Jianwei and Yang, Jianxin and Yang, Jiaxi and Zhou, Jingren and Lin, Junyang and Dang, Kai and Lu, Keming and Bao, Keqin and Yang, Ke...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2412.15115 2025
-
[6]
Llama 3.2: Revolutionizing Edge AI and Vision (Connect 2024) , author =
work page 2024
-
[7]
Ministral-8B-Instruct-2410 Model Card , author =. 2024 , month = oct, url =
work page 2024
-
[8]
2025 , month = aug # " 13", url =
GPT-5 System Card , author =. 2025 , month = aug # " 13", url =
work page 2025
-
[9]
Hierarchical neural story generation.CoRR, abs/1805.04833, 2018
Fan, Angela and Lewis, Mike and Dauphin, Yann , month = may, year =. Hierarchical. doi:10.48550/arXiv.1805.04833 , abstract =
-
[10]
doi:10.48550/arXiv.2406.18510 , abstract =
Jiang, Liwei and Rao, Kavel and Han, Seungju and Ettinger, Allyson and Brahman, Faeze and Kumar, Sachin and Mireshghallah, Niloofar and Lu, Ximing and Sap, Maarten and Choi, Yejin and Dziri, Nouha , month = jun, year =. doi:10.48550/arXiv.2406.18510 , abstract =
-
[11]
Li, Nathaniel and Pan, Alexander and Gopal, Anjali and Yue, Summer and Berrios, Daniel and Gatti, Alice and Li, Justin D. and Dombrowski, Ann-Kathrin and Goel, Shashwat and Phan, Long and Mukobi, Gabriel and Helm-Burger, Nathan and Lababidi, Rassin and Justen, Lennart and Liu, Andrew B. and Chen, Michael and Barrass, Isabelle and Zhang, Oliver and Zhu, Xi...
-
[12]
Sabotage evaluations for frontier models
Benton, Joe and Wagner, Misha and Christiansen, Eric and Anil, Cem and Perez, Ethan and Srivastav, Jai and Durmus, Esin and Ganguli, Deep and Kravec, Shauna and Shlegeris, Buck and Kaplan, Jared and Karnofsky, Holden and Hubinger, Evan and Grosse, Roger and Bowman, Samuel R. and Duvenaud, David , urldate =. Sabotage Evaluations for Frontier Models , url =...
-
[13]
What makes a convincing argument?
Habernal, Ivan and Gurevych, Iryna , year =. What makes a convincing argument?. Proceedings of the 2016
work page 2016
-
[15]
Kirch, Nathalie and Weisser, Constantin and Field, Severin and Yannakoudakis, Helen and Casper, Stephen , month = may, year =. What. doi:10.48550/arXiv.2411.03343 , abstract =
-
[16]
Jailbroken: How Does LLM Safety Training Fail?
Wei, Alexander and Haghtalab, Nika and Steinhardt, Jacob , month = jul, year =. Jailbroken:. doi:10.48550/arXiv.2307.02483 , abstract =
work page internal anchor Pith review doi:10.48550/arxiv.2307.02483
-
[17]
Enhancing chat language models by scaling high-quality instructional conversations
Ding, Ning and Chen, Yulin and Xu, Bokai and Qin, Yujia and Zheng, Zhi and Hu, Shengding and Liu, Zhiyuan and Sun, Maosong and Zhou, Bowen , month = may, year =. Enhancing. doi:10.48550/arXiv.2305.14233 , abstract =
-
[18]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Bai, Yuntao and Jones, Andy and Ndousse, Kamal and Askell, Amanda and Chen, Anna and DasSarma, Nova and Drain, Dawn and Fort, Stanislav and Ganguli, Deep and Henighan, Tom and Joseph, Nicholas and Kadavath, Saurav and Kernion, Jackson and Conerly, Tom and El-Showk, Sheer and Elhage, Nelson and Hatfield-Dodds, Zac and Hernandez, Danny and Hume, Tristan and...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2204.05862
-
[19]
Sharma, Mrinank and Tong, Meg and Mu, Jesse and Wei, Jerry and Kruthoff, Jorrit and Goodfriend, Scott and Ong, Euan and Peng, Alwin and Agarwal, Raj and Anil, Cem and Askell, Amanda and Bailey, Nathan and Benton, Joe and Bluemke, Emma and Bowman, Samuel R. and Christiansen, Eric and Cunningham, Hoagy and Dau, Andy and Gopal, Anjali and Gilson, Rob and Gra...
-
[20]
Bloom, Joseph and Taylor, Jordan and Kissane, Connor and Black, Sid and merizian and alexdzm and jacoba and Millwood, Ben and Cooney, Alan , month = jul, year =. White
-
[21]
Sharkey, Lee and Chughtai, Bilal and Batson, Joshua and Lindsey, Jack and Wu, Jeff and Bushnaq, Lucius and Goldowsky-Dill, Nicholas and Heimersheim, Stefan and Ortega, Alejandro and Bloom, Joseph and Biderman, Stella and Garriga-Alonso, Adria and Conmy, Arthur and Nanda, Neel and Rumbelow, Jessica and Wattenberg, Martin and Schoots, Nandi and Miller, Jose...
work page internal anchor Pith review doi:10.48550/arxiv.2501.16496
-
[22]
Language models learn to mislead humans via rlhf
Wen, Jiaxin and Zhong, Ruiqi and Khan, Akbir and Perez, Ethan and Steinhardt, Jacob and Huang, Minlie and Bowman, Samuel R. and He, He and Feng, Shi , month = dec, year =. Language. doi:10.48550/arXiv.2409.12822 , abstract =
-
[23]
Chalmers, David J. , month = jan, year =. Propositional. doi:10.48550/arXiv.2501.15740 , abstract =
-
[24]
doi:10.48550/arXiv.2502.14744 , abstract =
Jiang, Yilei and Gao, Xinyan and Peng, Tianshuo and Tan, Yingshui and Zhu, Xiaoyong and Zheng, Bo and Yue, Xiangyu , month = jun, year =. doi:10.48550/arXiv.2502.14744 , abstract =
-
[25]
arXiv preprint arXiv:2507.12691 , year =
Parrack, Avi and Attubato, Carlo Leonardo and Heimersheim, Stefan , month = aug, year =. Benchmarking. doi:10.48550/arXiv.2507.12691 , abstract =
-
[26]
Detecting high-stakes interactions with activation probes
McKenzie, Alex and Pawar, Urja and Blandfort, Phil and Bankes, William and Krueger, David and Lubana, Ekdeep Singh and Krasheninnikov, Dmitrii , month = jun, year =. Detecting. doi:10.48550/arXiv.2506.10805 , abstract =
-
[27]
Investigating task-specific prompts and sparse autoencoders for activation monitoring , url =
Tillman, Henk and Mossing, Dan , month = apr, year =. Investigating task-specific prompts and sparse autoencoders for activation monitoring , url =. doi:10.48550/arXiv.2504.20271 , abstract =
-
[28]
Chan, Yik Siu and Yong, Zheng-Xin and Bach, Stephen H. , month = jul, year =. Can. doi:10.48550/arXiv.2507.12428 , abstract =
-
[29]
Nguyen, Jord and Hoang, Khiem and Attubato, Carlo Leonardo and Hofstätter, Felix , month = jul, year =. Probing and. doi:10.48550/arXiv.2507.01786 , abstract =
-
[30]
Feng, Jiahai and Russell, Stuart and Steinhardt, Jacob , month = dec, year =. Monitoring. doi:10.48550/arXiv.2406.19501 , abstract =
-
[32]
Simple probes can catch sleeper agents , url =
MacDiarmid, Monte and Maxwell, Timothy and Schiefer, Nicholas and Mu, Jesse and Kaplan, Jared and Duvenaud, David and Bowman, Sam and Tamkin, Alex and Perez, Ethan and Sharma, Mrinank and Denison, Carson and Hubinger, Evan , month = apr, year =. Simple probes can catch sleeper agents , url =
-
[33]
What makes a convincing argument?
Habernal, Ivan and Gurevych, Iryna , editor =. What makes a convincing argument?. Proceedings of the 2016. 2016 , pages =. doi:10.18653/v1/D16-1129 , urldate =
-
[34]
Measuring Massive Multitask Language Understanding
Hendrycks, Dan and Burns, Collin and Basart, Steven and Zou, Andy and Mazeika, Mantas and Song, Dawn and Steinhardt, Jacob , month = jan, year =. Measuring. doi:10.48550/arXiv.2009.03300 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2009.03300 2009
-
[35]
Representation Engineering: A Top-Down Approach to AI Transparency
Zou, Andy and Phan, Long and Chen, Sarah and Campbell, James and Guo, Phillip and Ren, Richard and Pan, Alexander and Yin, Xuwang and Mazeika, Mantas and Dombrowski, Ann-Kathrin and Goel, Shashwat and Li, Nathaniel and Byun, Michael J. and Wang, Zifan and Mallen, Alex and Basart, Steven and Koyejo, Sanmi and Song, Dawn and Fredrikson, Matt and Kolter, J. ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.01405
-
[36]
Zhang, Jason and Viteri, Scott , month = mar, year =. Uncovering. doi:10.48550/arXiv.2409.14026 , abstract =
-
[37]
Abdelnabi, Sahar and Salem, Ahmed , month = may, year =. Linear. doi:10.48550/arXiv.2505.14617 , abstract =
-
[38]
Gu, Tianle and Huang, Kexin and Wang, Zongqi and Wang, Yixu and Li, Jie and Yao, Yuanqi and Yao, Yang and Yang, Yujiu and Teng, Yan and Wang, Yingchun , month = jun, year =. Probing the. doi:10.48550/arXiv.2506.16078 , abstract =
-
[39]
Towards Understanding Sycophancy in Language Models
Sharma, Mrinank and Tong, Meg and Korbak, Tomasz and Duvenaud, David and Askell, Amanda and Bowman, Samuel R. and Cheng, Newton and Durmus, Esin and Hatfield-Dodds, Zac and Johnston, Scott R. and Kravec, Shauna and Maxwell, Timothy and McCandlish, Sam and Ndousse, Kamal and Rausch, Oliver and Schiefer, Nicholas and Yan, Da and Zhang, Miranda and Perez, Et...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.13548
-
[40]
Weij, Teun van der and Hofstätter, Felix and Jaffe, Ollie and Brown, Samuel F. and Ward, Francis Rhys , month = feb, year =. doi:10.48550/arXiv.2406.07358 , abstract =
-
[41]
Barkur, Sudarshan Kamath and Schacht, Sigurd and Scholl, Johannes , month = jan, year =. Deception in. doi:10.48550/arXiv.2501.16513 , abstract =
-
[42]
HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal
Mazeika, Mantas and Phan, Long and Yin, Xuwang and Zou, Andy and Wang, Zifan and Mu, Norman and Sakhaee, Elham and Li, Nathaniel and Basart, Steven and Li, Bo and Forsyth, David and Hendrycks, Dan , month = feb, year =. doi:10.48550/arXiv.2402.04249 , keywords =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2402.04249
-
[43]
Lu, Christina and Gallagher, Jack and Michala, Jonathan and Fish, Kyle and Lindsey, Jack , month = jan, year =. The
-
[44]
Ying, Zhuofan Josh and Ravfogel, Shauli and Kriegeskorte, Nikolaus and Hase, Peter , month = feb, year =. The
-
[45]
Shafran, Or and Ronen, Shaked and Fahn, Omri and Ravfogel, Shauli and Geiger, Atticus and Geva, Mor , month = feb, year =. From
-
[46]
Bar-Shalom, Guy and Frasca, Fabrizio and Galron, Yaniv and Ziser, Yftah and Maron, Haggai , month = sep, year =. Beyond
-
[47]
The persona selection model , url =
- [48]
-
[49]
Understanding intermediate layers using linear classifier probes , author=. 2018 , eprint=
work page 2018
-
[50]
Constitutional Classifiers++: Efficient Production-Grade Defenses against Universal Jailbreaks , author=. 2026 , eprint=
work page 2026
-
[51]
Designing and Interpreting Probes with Control Tasks , author=. 2019 , eprint=
work page 2019
-
[52]
Findings of the Association for Computational Linguistics: EMNLP 2022 , address =
Language Models as Agent Models , author =. Findings of the Association for Computational Linguistics: EMNLP 2022 , address =. 2022 , url =
work page 2022
-
[53]
Personas as a Way to Model Truthfulness in Language Models , url =
Joishi, Nitish and Rando, Javier and Saparov, Abulhair and Kim, Najoung and He, He , month = oct, year =. Personas as a Way to Model Truthfulness in Language Models , url =
-
[54]
Emotion concepts and their function in a large language model , url =
-
[55]
Dong, Yurui and Jin, Luozhijie and Yang, Yao and Lu, Bingjie and Yang, Jiaxi and Liu, Zhi , month = feb, year =. Controllable
- [56]
-
[57]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , address =
Personas as a Way to Model Truthfulness in Language Models , author =. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , address =. 2024 , url =
work page 2024
-
[58]
The Persona Selection Model: Why AI Assistants might Behave like Humans , url =
Marks, Samuel and Lindsey, Jack and Olah, Christopher , month = feb, year =. The Persona Selection Model: Why AI Assistants might Behave like Humans , url =
-
[59]
Proceedings of the 41st International Conference on Machine Learning , series =
The Linear Representation Hypothesis and the Geometry of Large Language Models , author =. Proceedings of the 41st International Conference on Machine Learning , series =. 2024 , url =
work page 2024
-
[60]
Findings of the Association for Computational Linguistics: EMNLP 2023 , publisher =
The Internal State of an LLM Knows When It's Lying , author =. Findings of the Association for Computational Linguistics: EMNLP 2023 , publisher =. 2023 , url =
work page 2023
-
[61]
The Eleventh International Conference on Learning Representations , year =
Discovering Latent Knowledge in Language Models Without Supervision , author =. The Eleventh International Conference on Learning Representations , year =
-
[62]
Ryan Greenblatt, Buck Shlegeris, Kshitij Sachan, and Fabien Roger
Goldowsky-Dill, Nicholas and Chughtai, Bilal and Heimersheim, Stefan and Hobbhahn, Marius , month = feb, year =. Detecting Strategic Deception Using Linear Probes , url =. doi:10.48550/arXiv.2502.03407 , publisher =
-
[63]
Building Better Deception Probes Using Targeted Instruction Pairs , url =
Natarajan, Vikram and Jain, Devina and Arora, Shivam and Golechha, Satvik and Bloom, Joseph , month = feb, year =. Building Better Deception Probes Using Targeted Instruction Pairs , url =. doi:10.48550/arXiv.2602.01425 , publisher =
-
[64]
The Twelfth International Conference on Learning Representations , year =
Towards Understanding Sycophancy in Language Models , author =. The Twelfth International Conference on Learning Representations , year =
-
[65]
Scheurer, J. Large Language Models can Strategically Deceive their Users when Put Under Pressure , url =. 2024 , note =. doi:10.48550/arXiv.2311.07590 , publisher =
-
[66]
Emergent Misalignment: Narrow finetuning can produce broadly misaligned LLMs , url =
Betley, Jan and Tan, Daniel and Warncke, Niels and Sztyber-Betley, Anna and Bao, Xuchan and Soto, Mart. Emergent Misalignment: Narrow finetuning can produce broadly misaligned LLMs , url =. 2025 , note =
work page 2025
-
[67]
Pacchiardi, Lorenzo and Chughtai, Bilal and Watanabe, David and Yan, Morgan and McGrath, Thomas and Bowman, Samuel and Hubinger, Evan and Marks, Samuel and Ringer, Sam and Tegmark, Max and others , year =. How to Catch an. 2309.15840 , archivePrefix =
-
[68]
Apollo Deception Detection Dataset Collection , author =. 2024 , howpublished =
work page 2024
-
[69]
Liars' Bench: A Benchmark for Measuring Strategic Deception in
Kretschmar, Marius and Engel, Raphael and Salvatier, John and Roger, Fabian and Korbak, Tomasz and Marks, Samuel and Heimersheim, Stefan and Ringer, Sam and Wen, Minda and others , year =. Liars' Bench: A Benchmark for Measuring Strategic Deception in. 2502.01409 , archivePrefix =
- [70]
- [71]
-
[72]
Steering Llama 2 via Contrastive Activation Addition
Rimsky, Nina and Gabrieli, Noga and Roit, Omri and Nanda, Neel and Ringel, Ziv , year =. Steering. 2312.06681 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[73]
Social Sycophancy: Prototype-Guided Understanding and Prediction of User Alignment in
Cheng, Jiayi and Zhang, Weiran and Xie, Yuezui and Dai, Wenliang and Ding, Ning and Chan, Chi-Min and Chen, Wenli and Yao, Yuan and Qin, Tao and Chen, Zhiyuan and Liu, Tie-Yan , year =. Social Sycophancy: Prototype-Guided Understanding and Prediction of User Alignment in
-
[74]
The Impact of Off-Policy Training Data on Probe Generalisation , author=. 2026 , eprint=
work page 2026
-
[75]
Marks, Samuel and Tegmark, Max , month = oct, year =. The Geometry of Truth: Emergent Linear Structure in Large Language Model Representations of True/False Datasets , url =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.